

Глава двадцать первая. Анализ данных: методы исследования



До сих пор при обсуждении анализа данных мы интересовались, главным образом, проверкой значимости различий, возникающих при разных условиях исследования, будь то различие между каким-то выборочным результатом и предполагаемым состоянием генеральной совокупности, или различие между двумя и более выборочными результатами. Однако достаточно часто исследователь должен определить, имеет ли место какая-то связь между двумя или более переменными, и если да, то каковы ее степень и функциональная форма.
Обычно мы пытаемся предсказать значение одной переменной (например, потребление какого-то конкретного продукта семьей) на базе одной или более других переменных (например, дохода и количества членов семьи). Переменная, значение которой необходимо предсказать, называется зависимой (результативной) или переменной-критерием. Переменные, которые дают основу для построения предсказания, называются независимыми или переменными-предикторами.
Простой регрессионный и корреляционный анализ
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Статистический метод, используемый для измерения степени близости взаимосвязи между двумя или более сопоставимыми по интервалу переменными к линейной.
РЕГРЕССИОННЫЙ АНАЛИЗ
Статистический метод, используемый для построения уравнения, которое соотносит единственную переменную-критерий с одной или более переменными-предикторами; когда рассматривается одна переменная-предиктор, имеет место простой регрессионный анализ, тогда как во множественном регрессионном анализе участвует две или более переменных-предикторов.
Регрессионный анализ и корреляционный анализ находят широкое применение в маркетинговых исследованиях, когда изучается взаимосвязь двух и более переменных. Хотя в использовании эти два определения зачастую взаимно заменяют друг друга, существует различие в целях их применения. В корреляционном анализе измеряется близость взаимосвязи двух или более переменных. Самой техникой этого приема рассматривается совместная вариация двух мер, ни одну из которых экспериментатор не ограничивает. С другой стороны, регрессионный анализ используется для вывода уравнения, которое связывает переменную-критерий с одной или более переменными-предикторами. В нем рассматривается распределение частот переменной-критерия при сохранении переменных-предикторов постоянными на различных уровнях.
В отношении корреляционного анализа следует обратить внимание на различие между понятиями корреляции и причинности. Использование в корреляционном анализе терминов «зависимые переменные» (критерии) и «независимые переменные» (предикторы) берет свое начало от описания функциональных математических связей и никоим образом не связано с наличием зависимости одной переменной от другой в смысле причинной обусловленности. Например, в то время как статистические приемы могут показывать определенную корреляцию между высоким доходом и тенденцией к проведению зимних отпусков на Карибских островах, будет ошибкой предполагать, что обладание высоким доходом является причиной того, что соответствующее лицо направляется на юг, как только столбик термометра устремляется вниз.
В корреляционном анализе, как и в любой другой математической процедуре, нет ничего такого, что могло бы использоваться для установления причинной обусловленности. Все, чего можно добиться в результате использования всех этих процедур, — это установить меру (степень) связи или корреляции между переменными. Выводы о причинности должны получаться сами собой из основополагающих знаний и теорий, касающихся самого исследуемого явления. Никакая математика не в состоянии обеспечить какой-либо способ их получения. В исследовательском окне 21.1 бывший директор подразделения маркетинговых исследований General Mills убеждает исследователей вглядываться в то, что лежит за хаосом данных, сбору которых они отдают всю свою энергию, и рассматривать те теории, которые способны объяснить маркетинговые вопросы. Без них применение математики бессмысленно.
Предмет регрессионного и корреляционного анализа лучше всего обсуждать на конкретных примерах. Поэтому рассмотрим изготовителя шариковых ручек Click, известного в национальном масштабе, который заинтересован в исследовании эффективности маркетинговых усилий своей фирмы. Компания использует оптовых торговцев для распределения продукции Click и в дополнение к их усилиям прибегает к персональным продажам и коротким рекламным телероликам. Компания планирует использовать в качестве меры оценки эффективности ежегодный объем продаж по территориям. Эти данные и информация о количестве торговых представителей, обслуживающих территорию, всегда готовы для обработки и находятся в регистрационных файлах компании. Другие характеристики, которые изготовитель считает возможным связать с объемом продаж, — короткие телеролики, и эффективность оптовиков определить труднее. Чтобы получить информацию по телевизионной рекламе на территории, исследователи должны проанализировать графики показа роликов и изучить охват территории телевизионным каналом, что позволит определить, каких именно регионов может достигать каждая передача. Эффективность деятельности оптовиков требует установления их рейтингов по ряду критериев и расчета совокупного рейтинга. В нем 4 означает выдающуюся эффективность, 3 — хорошую, 2 — среднего уровня и 1 — слабую. Учитывая время и затраты, не обходимые для генерирования этих характеристик рекламы и распределения продукции, компания решила анализировать только определенную выборку из общего числа торговых территорий. Данные случайным образом определенной выборки объемом 40 территорий представлены в таблице 21.1.

Влияние каждой структурной переменной маркетинга на объем продаж можно исследовать несколькими способами. Один, самый очевидный, состоит просто в графическом представлении объема продаж как функции от каждой переменной.

Пристальное рассмотрение рубрик А и В позволяет также утверждать, что можно было бы суммировать взаимосвязь объемов продаж с каждой переменной-предиктором, проведя прямую линию по точкам данных. Один из способов генерирования этой взаимосвязи объемов продаж и либо показов телевизионной рекламы, либо числа торговых представителей может быть реализован «на глазок», т. е. как бы визуальным прочерчиванием прямой линии по точкам графиков. Такая линия будет представлять собой линию «средней» взаимосвязи. Она покажет среднее значение переменной-критерия, а именно продаж, при заданных значениях каждой переменной-предиктора, т. е. показов рекламного ролика или числа торговых представителей. Затем можно было бы входить в график, скажем, с определенным количеством показов рекламы по региональному телевидению и считывать с него ожидаемый средний уровень продаж на этой территории. Трудность графического подхода заключается в том, что для описания взаимосвязи два аналитика могут построить разные линии. Такое упрощение неминуемо приводит к возникновению вопроса о том, какая из линий более корректна или лучше соответствует данным.
Альтернативный
подход состоит в установлении
математического соответствия между
линией и данным. Общее уравнение прямой
линии
![]() ,
где
,
где
![]() —
точка пересечения с осью Y
и
—
точка пересечения с осью Y
и
![]() — коэффициент
наклона прямой. В случае, когда Y
— это объем
продаж, а
— коэффициент
наклона прямой. В случае, когда Y
— это объем
продаж, а
![]() — количество показов рекламы, уравнение
будет записано как
— количество показов рекламы, уравнение
будет записано как
![]() тогда как для взаимосвязи объема продаж
Y
и числа торговых представителей
тогда как для взаимосвязи объема продаж
Y
и числа торговых представителей
![]() оно может
быть записано как
оно может
быть записано как
![]() ,
где подстрочные индексы определяют
соответствующие переменные-предикторы.
В записанном виде каждая из этих моделей
называется детерминистической моделью.
Если б и в установлены, то единственное
в своем роде значение Y,
причем без допуска на ошибку, определяется
подстановкой в уравнение какого-то
значения переменной-предиктора.
,
где подстрочные индексы определяют
соответствующие переменные-предикторы.
В записанном виде каждая из этих моделей
называется детерминистической моделью.
Если б и в установлены, то единственное
в своем роде значение Y,
причем без допуска на ошибку, определяется
подстановкой в уравнение какого-то
значения переменной-предиктора.
Когда проводится исследование социальных явлений, нулевая ошибка представляет собой исключительную редкость, если вообще возможна. Следовательно, вместо детерминистической модели мы могли бы предложить вероятностную модель и принять какие-то допущения об ошибке. Например, поработаем с взаимосвязью объемов продаж и количеством показов телевизионной рекламы, рассмотрев модель
![]()
где
![]() — уровень продаж
на i-й
территории,
— уровень продаж
на i-й
территории,
![]() — уровень
рекламы на i-й
территории и
— уровень
рекламы на i-й
территории и
![]() — ошибка, ассоциируемая с i-м
блоком наблюдений. Это та форма модели,
которая используется для регрессионного
анализа. Понятие ошибки является
неотъемлемой частью модели. Она несет
в себе отражение несостоятельности
включения в модель любых факторов,
представляет в модели объективность
того, что в поведении человека есть
элемент непредсказуемости, а средства
измерения заведомо несут в себе ошибки.
Вероятностная модель позволяет учесть
то обстоятельство, что при заданном
— ошибка, ассоциируемая с i-м
блоком наблюдений. Это та форма модели,
которая используется для регрессионного
анализа. Понятие ошибки является
неотъемлемой частью модели. Она несет
в себе отражение несостоятельности
включения в модель любых факторов,
представляет в модели объективность
того, что в поведении человека есть
элемент непредсказуемости, а средства
измерения заведомо несут в себе ошибки.
Вероятностная модель позволяет учесть
то обстоятельство, что при заданном
![]() значение
значение
![]() определяется не единственным образом.
Скорее, при заданном
определяется не единственным образом.
Скорее, при заданном
![]() определенность заключается лишь в том,
что получаемая величина является
«средним значением» Y.
Можно ожидать флуктуации конкретных
значений выше и ниже этого среднего
значения.
определенность заключается лишь в том,
что получаемая величина является
«средним значением» Y.
Можно ожидать флуктуации конкретных
значений выше и ниже этого среднего
значения.
Для получения
математического решения, позволяющего
определить линию наилучшего приближения
в вероятностной модели, требуется
принять определенные допущения
относительно распределения величины
ошибки. Линию наилучшего приближения
можно определить целым рядом способов.
Типовой способ состоит в подборе таких
членов уравнения линии, которые
минимизируют сумму квадратов отклонений
от прямой линии (решение по методу
наименьших квадратов). Предположим, что
линия представляет оцениваемое уравнение.
Используя знак вставки (^) для указания
оцениваемого значения, ошибку i-го
наблюдения определим как разность между
фактическим значением Y,
т. е.
![]() ,
и оцениваемым значением Y,
т. е.
,
и оцениваемым значением Y,
т. е.
![]() ,
,
![]() ,.
Решение по методу наименьших квадратов
базируется на том, что сумма этих
возведенных в квадрат ошибок должна
быть как можно меньше, т.е. необходимо
минимизировать
,.
Решение по методу наименьших квадратов
базируется на том, что сумма этих
возведенных в квадрат ошибок должна
быть как можно меньше, т.е. необходимо
минимизировать
![]()
Выборочные оценки
![]() и
и![]() ,
истинных параметров генеральной
совокупности
,
истинных параметров генеральной
совокупности
![]() ,
и
,
и
![]() ,
определяются таким образом, чтобы это
условие удовлетворялось.
,
определяются таким образом, чтобы это
условие удовлетворялось.
В решении по методу наименьших квадратов принимается три упрощающих допущения относительно члена уравнения, определяющего ошибку:
1. Среднее ошибки равно нулю.
2. Разброс ошибки является константой и не зависит от значений переменной-предиктора.
3. Значения ошибки независимы одно от другого.
Данные допущения
позволяют решать уравнения с целью
получения надежных оценок параметров
генеральной совокупности, т. е. точки
пересечения
![]() ,
и наклона
,
и наклона
![]() ,
вручную, хотя более целесообразно
использовать для этого компьютер.
,
вручную, хотя более целесообразно
использовать для этого компьютер.
Если бы мы
использовали данные табл. 21.1 по объемам
продаж (Y)
и количеству показов телевизионной
рекламы в месяц (![]() ),
то оценка для
),
то оценка для
![]() ,
составила бы 135,4, а для
,
составила бы 135,4, а для
![]() —25,3.
Наклон линии задается значением
—25,3.
Наклон линии задается значением
![]() .
Значение 25,3 для
.
Значение 25,3 для
![]() ,
предполагает, что при каждом дополнительном
показе по телевизору рекламного ролика
объем торговли возрастает на 25 300
долларов. Как отмечалось ранее, эта
оценка истинного состояния генеральной
совокупности базируется на нашей
конкретной выборке из 40 наблюдений.
Другая выборка, несомненно, могла бы
дать иную оценку. Более того, мы еще даже
не задавались вопросом, статистически
значим этот результат или его появление
носит случайный характер. Тем не менее
это наиболее важный элемент информации,
который помогает в определении того,
стоят ли затраты на рекламу оцениваемого
торгового оборота. Оценка параметра
пересечения
,
предполагает, что при каждом дополнительном
показе по телевизору рекламного ролика
объем торговли возрастает на 25 300
долларов. Как отмечалось ранее, эта
оценка истинного состояния генеральной
совокупности базируется на нашей
конкретной выборке из 40 наблюдений.
Другая выборка, несомненно, могла бы
дать иную оценку. Более того, мы еще даже
не задавались вопросом, статистически
значим этот результат или его появление
носит случайный характер. Тем не менее
это наиболее важный элемент информации,
который помогает в определении того,
стоят ли затраты на рекламу оцениваемого
торгового оборота. Оценка параметра
пересечения
![]() =135,4;
этот параметр показывает, в какой точке
линия пересекает ось Y,
поскольку оно представляет оцениваемое
значениеY,
когда переменная-предиктор равна нулю.
=135,4;
этот параметр показывает, в какой точке
линия пересекает ось Y,
поскольку оно представляет оцениваемое
значениеY,
когда переменная-предиктор равна нулю.
СТАНДАРТНАЯ ОШИБКА ОЦЕНКИ
Изучение рис. 21.3 позволяет заметить, что, хотя линия и выглядит хорошо соответствующей точкам, разброс около нее самих точек остается прежним. Согласие измеряется величиной этих отклонений. Мы можем рассчитать количественную меру разброса точек около прямой линии во многом тем же способом, каким рассчитываем стандартное отклонение распределения частот.
Так же как выборочное
среднее является оценкой истинного
среднего генеральной совокупности,
задание линии уравнением
![]() ,
представляет собой оценку истинной
линии регрессии
,
представляет собой оценку истинной
линии регрессии
![]() .
Рассмотрим разброс случайной ошибки
.
Рассмотрим разброс случайной ошибки
![]() около истинной
линии регрессии, т. е.
около истинной
линии регрессии, т. е.
![]() или
или
![]() .
Когда разброс генеральной совокупности
.
Когда разброс генеральной совокупности
![]() неизвестен, несмещенная оценка задается
квадратом выборочного стандартного
отклонения
неизвестен, несмещенная оценка задается
квадратом выборочного стандартного
отклонения
![]() ,
,
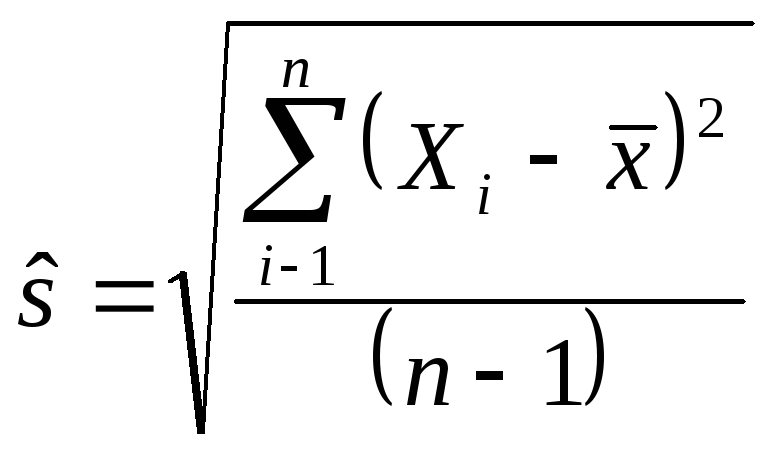
Точно так же пусть
![]() будет несмещенной оценкой разброса
генеральной совокупности около линии
регрессии
будет несмещенной оценкой разброса
генеральной совокупности около линии
регрессии
![]() .
Теперь можно показать, что выборочная
оценка разброса около линии регрессии
связана с суммой квадратов ошибок; она
равна
.
Теперь можно показать, что выборочная
оценка разброса около линии регрессии
связана с суммой квадратов ошибок; она
равна
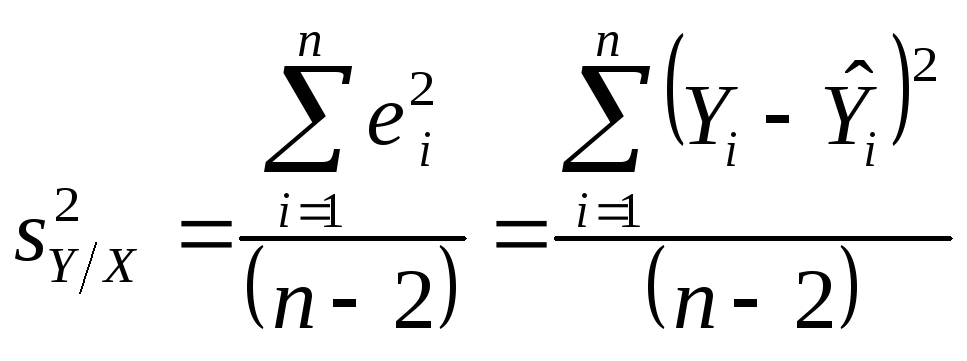
где п
— и на этот
раз объем выборки, а![]() - величина несмещенной оценки
- величина несмещенной оценки
![]() ,
причем
,
причем
![]() и
и
![]() — наблюденное и оценочное значение Y
для i-го
наблюдения соответственно. Квадратный
корень из определяемой приведенным
выше уравнением
— наблюденное и оценочное значение Y
для i-го
наблюдения соответственно. Квадратный
корень из определяемой приведенным
выше уравнением
![]() часто называют стандартной ошибкой
оценки, хотя более содержателен термин
стандартный
разброс регрессии.
часто называют стандартной ошибкой
оценки, хотя более содержателен термин
стандартный
разброс регрессии.
СТАНДАРТНАЯ ОШИБКА ОЦЕНКИ
Термин, используемый в регрессионном анализе для указания абсолютной величины вариации переменной-критерия, которая остается «необъясненной», или не поддается расчету с помощью регрессионного уравнения.
В интерпретации
стандартной ошибки регрессии прослеживаются
параллели с интерпретацией стандартного
отклонения. Рассмотрим значение
![]() .
Стандартная ошибка оценки означает,
что для любого такого значения
.
Стандартная ошибка оценки означает,
что для любого такого значения
![]() числа показов рекламы по телевидению
числа показов рекламы по телевидению
![]() .
(объем продаж) имеет тенденцию к разбросу
около соответствующего
.
(объем продаж) имеет тенденцию к разбросу
около соответствующего
![]() — точки
линии — при стандартном отклонении,
равном стандартной ошибке оценки. Более
того, эта вариация около прямой линии
остается одной и той же по всей ее длине.
Сама точка линии, арифметическое среднее,
с изменением
— точки
линии — при стандартном отклонении,
равном стандартной ошибке оценки. Более
того, эта вариация около прямой линии
остается одной и той же по всей ее длине.
Сама точка линии, арифметическое среднее,
с изменением
![]() меняется, но распределение значений
меняется, но распределение значений
![]() остается при изменении числа показов
рекламных роликов неизменным. Необходимо
заметить, что предположение о постоянстве
остается при изменении числа показов
рекламных роликов неизменным. Необходимо
заметить, что предположение о постоянстве
![]() вне зависимости от
вне зависимости от
![]() фактически задает параллельные
ограничительные полосы около линии
регрессии.
фактически задает параллельные
ограничительные полосы около линии
регрессии.
Чем меньше
стандартная ошибка оценки, тем лучше
линия согласуется с данными. Для линии,
связывающей объем продаж с числом показа
рекламы по телевидению,
![]() =59,6.
=59,6.
ПРЕДПОЛОЖЕНИЯ О КОЭФФИЦИЕНТЕ НАКЛОНА
Ранее мы рассчитали,
что значение коэффициента наклона
![]() ,
равно 25,3. Тогда мы еще не поднимали
вопрос о том, статистически значим ли
этот результат или его появление носит
случайный характер. Чтобы разобраться
с этим вопросом, необходимо принять
некоторое дополнительное допущение, а
именно допущение того, что ошибки
распределяются по нормальному закону,
а не равномерно, как предполагалось
выше. Прежде чем продолжать обсуждение,
подчеркнем, что оценки по методу
наименьших квадратов параметров
генеральной совокупности являются
наилучшими, линейными, несмещенными
оценками истинных параметров генеральной
совокупности вне зависимости от формы
распределения члена уравнения прямой
линии, определяющего ошибку. Все, что
необходимо, — удовлетворение ранее
перечисленных допущений. Это следует
из теоремы Гаусса-Маркова. Только если
мы желаем сделать статистические
предположения о коэффициентах регрессии,
возникает необходимость в допущении о
нормальном распределении ошибок. Можно
показать, что если
,
равно 25,3. Тогда мы еще не поднимали
вопрос о том, статистически значим ли
этот результат или его появление носит
случайный характер. Чтобы разобраться
с этим вопросом, необходимо принять
некоторое дополнительное допущение, а
именно допущение того, что ошибки
распределяются по нормальному закону,
а не равномерно, как предполагалось
выше. Прежде чем продолжать обсуждение,
подчеркнем, что оценки по методу
наименьших квадратов параметров
генеральной совокупности являются
наилучшими, линейными, несмещенными
оценками истинных параметров генеральной
совокупности вне зависимости от формы
распределения члена уравнения прямой
линии, определяющего ошибку. Все, что
необходимо, — удовлетворение ранее
перечисленных допущений. Это следует
из теоремы Гаусса-Маркова. Только если
мы желаем сделать статистические
предположения о коэффициентах регрессии,
возникает необходимость в допущении о
нормальном распределении ошибок. Можно
показать, что если
![]() является нормально распределенной
случайной переменной, то
является нормально распределенной
случайной переменной, то
![]() ,
также распределен нормально. То есть
если бы мы брали повторяющиеся выборки
из нашей генеральной совокупности
торговых территорий и рассчитывали
,
также распределен нормально. То есть
если бы мы брали повторяющиеся выборки
из нашей генеральной совокупности
торговых территорий и рассчитывали
![]() для каждой выборки, то распределение
этих оценок оказалось бы нормальным и
центрированным около истинного параметра
для каждой выборки, то распределение
этих оценок оказалось бы нормальным и
центрированным около истинного параметра
![]() генеральной совокупности. Далее можно
показать, что разброс распределения
генеральной совокупности. Далее можно
показать, что разброс распределения
![]() или
или
![]() равен
равен
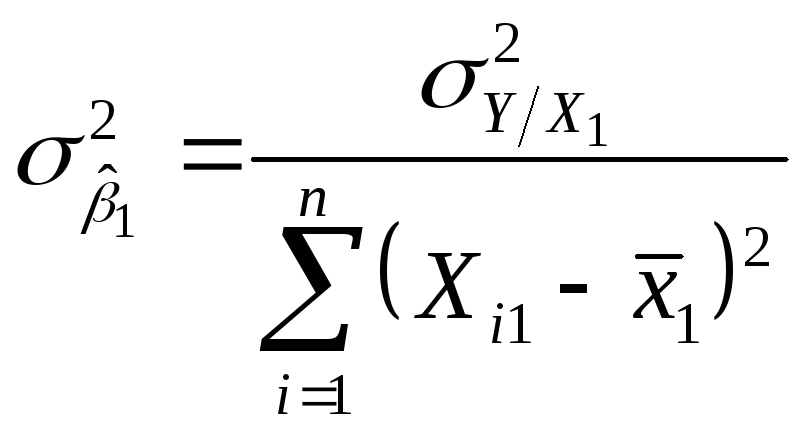
Поскольку
![]() для генеральной совокупности неизвестен,
неизвестно и значение
для генеральной совокупности неизвестен,
неизвестно и значение![]() ,
которое необходимо оценить. Оценка,
обозначаемая как
,
которое необходимо оценить. Оценка,
обозначаемая как
![]() ,
получается в результате подстановки
стандартной ошибки оценки
,
получается в результате подстановки
стандартной ошибки оценки
![]() вместо
вместо
![]() :
:
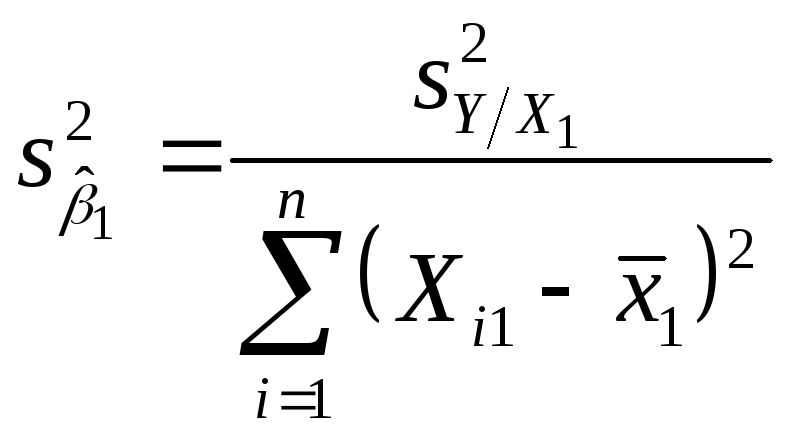
С этого момента
ситуация выглядит следующим образом.
При заданном допущении о нормальном
распределении ошибок получаем, что
![]() ,
также распределяется по нормальному
закону при среднем значении
,
также распределяется по нормальному
закону при среднем значении
![]() ,
и оценкой неизвестного разброса
,
и оценкой неизвестного разброса
![]() .
Поскольку вариация распределения
выборки неизвестна, мы вынуждены
использовать какую-то процедуру, подобную
той, которую применяли, делая предположение
о среднем при неизвестном разбросе
генеральной совокупности. К проверке
значимости
.
Поскольку вариация распределения
выборки неизвестна, мы вынуждены
использовать какую-то процедуру, подобную
той, которую применяли, делая предположение
о среднем при неизвестном разбросе
генеральной совокупности. К проверке
значимости
![]() .
предъявляются такие же требования.
Нулевая гипотеза состоит в том, что
между переменными нет линейной связи,
тогда как альтернативной гипотезой
предполагается, что линейная связь
существует, т. е.
.
предъявляются такие же требования.
Нулевая гипотеза состоит в том, что
между переменными нет линейной связи,
тогда как альтернативной гипотезой
предполагается, что линейная связь
существует, т. е.
![]()
Статистикой
проверки является
![]()
т. е. разность коэффициента наклона, оцененного с помощью выборки, и коэффициента наклона в соответствии с гипотезой, поделенная на стандартную ошибку оценки, которая имеет t-распределение при п - 2 степенях свободы. В нашем примере
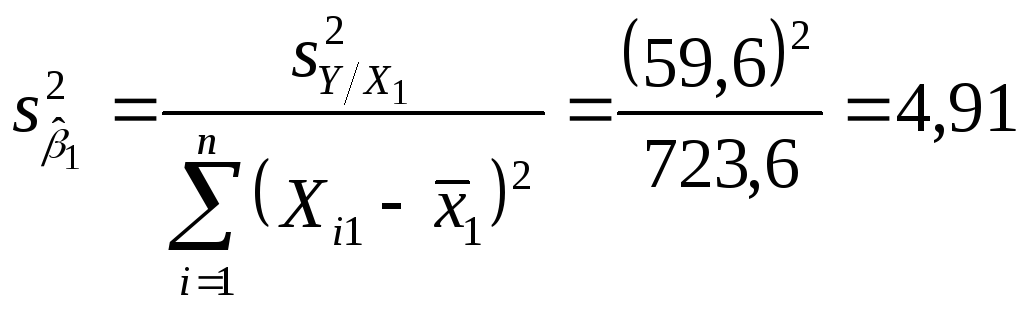
![]()
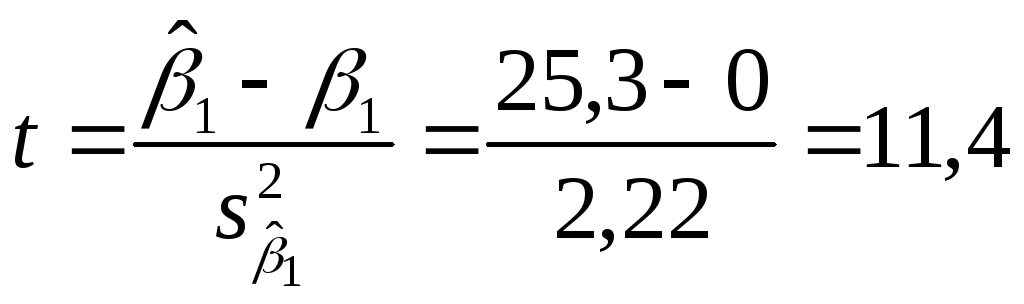
Для уровня значимости
0,05 табличное значение t
при
![]() степенях свободы составляет 2,02. Так как
расчетное t
превышает его критическое значение,
нулевая гипотеза отвергается;
степенях свободы составляет 2,02. Так как
расчетное t
превышает его критическое значение,
нулевая гипотеза отвергается;
![]() существенно отличается от нуля, что
гарантирует приемлемость допущения о
линейности связи между объемом продаж
и числом показов рекламы по телевидению.
Это вовсе не означает, что истинная
связь между продажами и интенсивностью
телевизионной рекламы обязательно
линейна. Речь идет лишь о том, что Y
(объем продажи) меняется с изменением
существенно отличается от нуля, что
гарантирует приемлемость допущения о
линейности связи между объемом продаж
и числом показов рекламы по телевидению.
Это вовсе не означает, что истинная
связь между продажами и интенсивностью
телевизионной рекламы обязательно
линейна. Речь идет лишь о том, что Y
(объем продажи) меняется с изменением
![]() (числом показов рекламного ролика на
телевидении) и что мы можем получить
лучшее предсказание Y,
используя
(числом показов рекламного ролика на
телевидении) и что мы можем получить
лучшее предсказание Y,
используя
![]() и линейное уравнение, чем если бы просто
игнорировали
и линейное уравнение, чем если бы просто
игнорировали
![]() .
.
Что мы имеем, если
нулевая гипотеза не отвергается? Как
уже отмечалось,
![]() ,
— это наклон предполагаемой линии в
регионе наблюдения, который показывает
линейное изменение Y
на единицу изменения
,
— это наклон предполагаемой линии в
регионе наблюдения, который показывает
линейное изменение Y
на единицу изменения
![]() ,.
Если бы мы не отвергли нулевую гипотезу
о том, что значение
,.
Если бы мы не отвергли нулевую гипотезу
о том, что значение
![]() равно нулю, это не означало бы отсутствия
связи между Y
и
равно нулю, это не означало бы отсутствия
связи между Y
и
![]() .
Существуют две возможности. Во-первых,
не отвергая неверную нулевую гипотезу,
мы можем просто совершить ошибку второго
рода. Во-вторых, не исключено существование
между Y
и
.
Существуют две возможности. Во-первых,
не отвергая неверную нулевую гипотезу,
мы можем просто совершить ошибку второго
рода. Во-вторых, не исключено существование
между Y
и
![]() какой-то нелинейной связи, а мы просто
выбрали неправильную модель для описания
этой реальной ситуации.
какой-то нелинейной связи, а мы просто
выбрали неправильную модель для описания
этой реальной ситуации.
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ
Термин, используемый в регрессионном анализе для указания степени близости зависимости между переменной-критерием и переменной-предиктором к линейной.
До сих пор нас
заботила функциональная взаимосвязь
Y
и X
Допустим, что нам небезынтересна и
степень линейности взаимосвязи между
Y
и X..
Этот интерес приводит к понятию
коэффициента корреляции. При рассмотрении
корреляционной модели принимается два
дополнительных допущения. Во-первых,
предполагается, что
![]() .
тоже случайная переменная. Выборочное
наблюдение дает значения и
.
тоже случайная переменная. Выборочное
наблюдение дает значения и
![]() и
и
![]() .
Во-вторых, предполагается, что наблюдения
берутся из двумерного нормального
распределения, т. е. такого, в котором и
переменная X
и переменная Y
распределены нормально.
.
Во-вторых, предполагается, что наблюдения
берутся из двумерного нормального
распределения, т. е. такого, в котором и
переменная X
и переменная Y
распределены нормально.
Итак, рассмотрим
выборку объемом п
наблюдении из двумерного нормального
распределения. Пусть р
представляет
степень линейности взаимосвязи этих
двух переменных в генеральной совокупности.
Пусть r
представляет выборочную оценку р.
Предположим, что выборка из п
наблюдений дает разброс точек и рассмотрим
четыре квадранта, образуемых осями при
значениях координат
![]() и
и
![]() .
.
Будем рассматривать
отклонения от этих двух секущих линий.
Возьмем любую точку Р
с координатами (![]() ,
,![]() .)
и определим отклонения
.)
и определим отклонения
![]() ,
,
![]()
где строчными
буквами обозначено отклонение от
среднего. Произведение
![]()
![]() :
:
• положительно для всех точек квадранта I;
• отрицательно для всех точек квадранта II; '
• положительно для всех точек квадранта III;
• отрицательно для всех точек квадранта IV. Из этого следует, что
![]()
можно использовать в качестве меры линейности зависимости между переменными X и Y, так как
• если связь положительна, и большинство точек лежит в квадрантах I и III, то
![]()
имеет тенденцию быть положительной;
• когда связь отрицательна, и большинство точек лежит в квадрантах II и IV,
![]()
обладает тенденцией быть отрицательной;
• если никакой связи между Х и Y нет, точки будут разбросаны по всем четырем квадрантам, и
![]()
будет иметь тенденцию оставаться небольшой. Однако у величины
![]()
как у меры линейности зависимости между Х и Y, есть два недостатка. Первый — она может произвольно увеличиваться при добавлении дополнительных наблюдений, т. е. в результате увеличения объема выборки. Второй, она также может подвергаться произвольному воздействию изменения единиц измерения каждой переменной или обоих, например при переходе от футов к дюймам. От этих недостатков можно избавиться, сделав меру силы линейной связи, безразмерной величиной и поделив ее на п. В результате получается пирсониан, или коэффициент корреляции
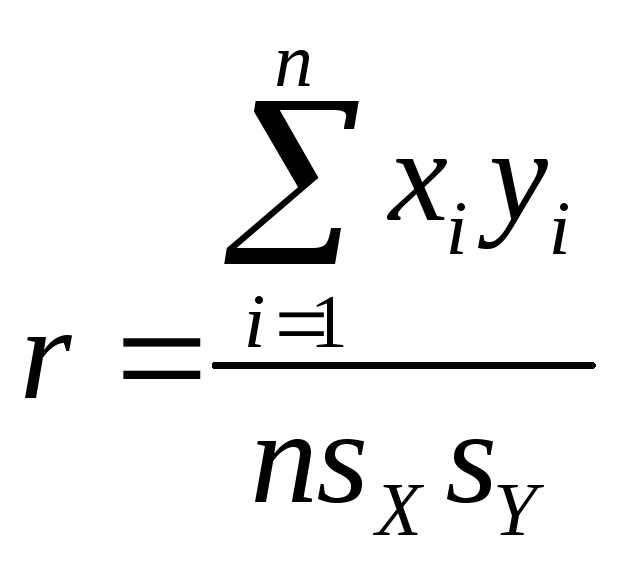
где
![]() .
— это стандартное отклонение переменной
X,
а
.
— это стандартное отклонение переменной
X,
а
![]() — стандартное
отклонение переменной Y.
— стандартное
отклонение переменной Y.
Коэффициент
корреляции, рассчитанный по выборочным
данным, является оценкой параметра р
генеральной совокупности, и часть работы
исследователя состоит в том, чтобы
использовать r
для проверки гипотезы, касающейся р.
Нет никакой необходимости пояснять это
на нашем подручном примере, так как
проверка нулевой гипотезы
![]() эквивалентна проверке нулевой гипотезы
эквивалентна проверке нулевой гипотезы
![]() .
Поскольку мы уже выполнили проверку
последней гипотезы, можем не сомневаться,
что выборочное доказательство приведет
к отказу от гипотезы об отсутствии
линейной связи между объемом продаж и
числом показа рекламы по телевидению,
т. е. гипотеза
.
Поскольку мы уже выполнили проверку
последней гипотезы, можем не сомневаться,
что выборочное доказательство приведет
к отказу от гипотезы об отсутствии
линейной связи между объемом продаж и
числом показа рекламы по телевидению,
т. е. гипотеза
![]() будет отвергнута.
будет отвергнута.
КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ
Термин, используемый в регрессионном анализе для указания относительной доли суммарной вариации переменной-критерия, которая может быть объяснена или принята в расчет с помощью аппроксимирующего регрессионного уравнения.
Коэффициент корреляции может меняться от -1 до +1. Полная положительная корреляция, при которой любое увеличение Х точно определяет увеличение Y, дает коэффициент +1. Полная отрицательная корреляция, когда любое увеличение Х в точности сопровождается уменьшением Y, дает коэффициент -1. Изучение диаграмм позволит получить правильное представление о величине коэффициента корреляции, ассоциируемого с конкретной степенью разброса. Квадрат коэффициента корреляции — это коэффициент детерминации. С помощью несложных алгебраических преобразований можно показать, что он равен
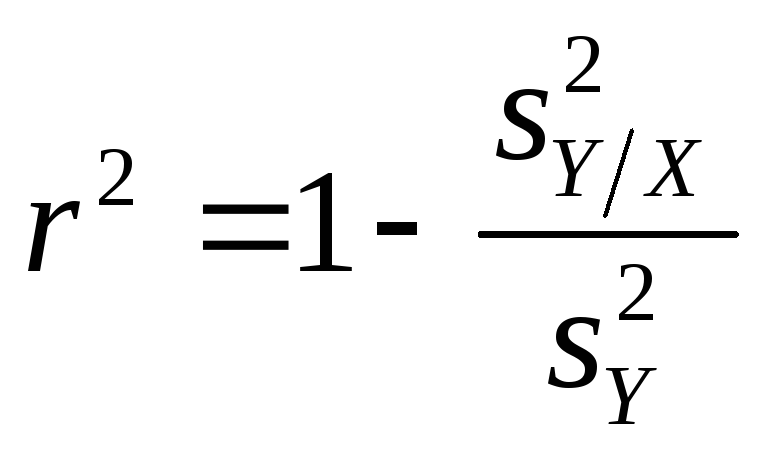
т. е.
![]() =1
минус стандартная ошибка оценки в
квадрате, поделенная на разброс
переменной-критерия в выборке. В условиях
отсутствия влияния переменной-предиктора
наилучшей оценкой переменной-критерия
будет выборочное среднее. Если имеет
место низкая вариация объемов продаж
от территории к территории, выборочное
среднее будет хорошей оценкой ожидаемого
объема продаж на любой территории.
Однако при высокой степени вариаций
хорошая оценка превращается в плохую.
Итак, разброс объема продажа
=1
минус стандартная ошибка оценки в
квадрате, поделенная на разброс
переменной-критерия в выборке. В условиях
отсутствия влияния переменной-предиктора
наилучшей оценкой переменной-критерия
будет выборочное среднее. Если имеет
место низкая вариация объемов продаж
от территории к территории, выборочное
среднее будет хорошей оценкой ожидаемого
объема продаж на любой территории.
Однако при высокой степени вариаций
хорошая оценка превращается в плохую.
Итак, разброс объема продажа
![]() является мерой «плохого качества»
подобной оценочной процедуры. Некоторого
улучшения оценок территориальных
объемов продажи можно добиться введением
ковариации X.
Это зависит от того, насколько хорошо
уравнение согласуется с данными.
Поскольку
является мерой «плохого качества»
подобной оценочной процедуры. Некоторого
улучшения оценок территориальных
объемов продажи можно добиться введением
ковариации X.
Это зависит от того, насколько хорошо
уравнение согласуется с данными.
Поскольку
![]() измеряет разброс точек около линии
регрессии,
измеряет разброс точек около линии
регрессии,
![]() можно считать
мерой «плохого качества» оценочной
процедуры, которой в расчет принимается
ковариация. Далее, если значение
можно считать
мерой «плохого качества» оценочной
процедуры, которой в расчет принимается
ковариация. Далее, если значение
![]() мало по сравнению со значением
мало по сравнению со значением
![]() ,
о введении ковариации через уравнение
регрессии можно говорить как о существенном
улучшении предсказаний переменной-критерия,
т. е. объемов продаж. Следовательно, если
,
о введении ковариации через уравнение
регрессии можно говорить как о существенном
улучшении предсказаний переменной-критерия,
т. е. объемов продаж. Следовательно, если
![]() примерно равно
примерно равно
![]() ,
то введение ковариации Х
можно считать не способствующим улучшению
предсказаний по Y.
Таким образом, отношение
,
то введение ковариации Х
можно считать не способствующим улучшению
предсказаний по Y.
Таким образом, отношение
![]() можно рассматривать в качестве отношения
вариации, оставшейся необъясненной с
помощью линий регрессии, к суммарной
вариации, т. е.
можно рассматривать в качестве отношения
вариации, оставшейся необъясненной с
помощью линий регрессии, к суммарной
вариации, т. е.
![]()
Правую часть этого уравнения можно преобразовать в простую дробь:
![]()
Если из суммарной вариации вычесть необъясненную, останется «объясненная вариация», т. е. вариация Y, которая принимается в расчет или объясняется введением X. Итак, коэффициент детерминации можно считать определяемым равенством
![]()
где, как мы понимаем,
суммарная вариация измеряется вариацией
Y.
Для примера с объемом продаж и числом
показов рекламы по телевидению
![]() =0,77
это означает, что 77% вариации объемов
продажи от территории к территории
принимается в расчет или может быть
объяснено вариацией числа показов
рекламы на территориях. Следовательно,
мы лучше справимся с работой оценки
объема продаж на территории, если примем
во внимание телевизионную рекламу, чем
в случае игнорирования рекламы.
=0,77
это означает, что 77% вариации объемов
продажи от территории к территории
принимается в расчет или может быть
объяснено вариацией числа показов
рекламы на территориях. Следовательно,
мы лучше справимся с работой оценки
объема продаж на территории, если примем
во внимание телевизионную рекламу, чем
в случае игнорирования рекламы.