

ЛР «Методы сжатия изображений»
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ АВИАЦИОННЫЙ ИНСТИТУТ
(ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ)
Кафедра информационных технологий
УТВЕРЖДАЮ
Зав. кафедрой 308
______________Шаронов А.В.
« »_________________2003 г.
Лабораторная работа
«Методы сжатия изображений»
по курсу
«Обработка аудио- и видеоинформации»
2-е издание
Работу составили:
доц., к.т.н Максимов Н.А.
аспирант Журавлёв Ю.А.
Москва
2003
Цель работы.
Изучение алгоритмов сжатия изображений и получение практических навыков программирования.
Порядок выполнения работы.
Изучение теоретической части.
Ответы на контрольные вопросы.
Изучение инструкций по выполнению задания.
Выполнение практической части.
Теоретическая часть.
Сжатие (компрессия) данных – широко распространенный приём не только в практике обработки изображений, но и в области хранения и передачи информации вообще. Его смысл заключается в уменьшении объёма, физически занимаемого информацией. Помимо экономии рабочего пространства носителя информации (например, жесткого диска), применение сжатия позволяет сократить время передачи данных по каналам связи (например, в сети Internet).
В данной работе сжатие будет рассматриваться применительно к изображениям.
Изображения и их структура
Изображения бывают двух основных типов: растровые и векторные.
Растровое изображение представляет собой двумерный массив (матрицу) пикселей (точек) определенного цвета. Совокупность всего множества пикселей и формирует изображение. Общее число пикселей может быть очень большим: изображение размером 800х600 пикселей, в зависимости от цветового разрешения, может занимать от 0,5 до 1,5 Мб.
Данные векторного изображения содержат не элементы изображения, а их математическое описание. В результате векторные изображения занимают, как правило, намного меньше места. Поэтому компактный способ представления информации изначально заложен в векторный формат хранения изображений и сжатие таких данных будет иметь очень малый эффект. Стоит, однако, отметить, что векторным форматом не могут быть представлены сложные изображения, такие как, например, фотографические снимки.
Рассмотрим структуру файла растрового изображения на примере широко известного формата BMP(см. рис. 1).
Заголовок файла – 14 байт
Заголовок растра – 40 байт
Палитра - 1024 байта
Растровые данные
Рис . 1 Структура BMP-файла
Заголовок файла содержит идентификатор BMP- файла, его общий размер, а также зарезервированные поля.
Заголовок растра содержит основные характеристики изображения: ширину, высоту, цветовое разрешение, общий размер растровых данных, их положение относительно начала всего файла и некоторые другие характеристики.
Если цветовое разрешение указано 4 или 8 бит на пиксел, то BMP-изображение всегда содержит палитру (соответственно 16 или 256 цветов). Каждый цвет обозначается тройкой RGB (интенсивности красного(R), зеленого(G) и синего(B) основных цветов) плюс один резервный канал. Поэтому палитра 256-цветного изображения будет занимать (3+1)*256=1024 байта.
Если же цветовое разрешение составляет 15, 16, 24 или 32 бита на пиксел, то палитра не используется, и растровые данные непосредственно (в виде троек RGB или BGR) задают цвет каждого пикселя.
Растровые данные организованы в файле построчно, причем если число байт в строке не кратно четырём, то в конец добавляются дополнительные байты. Часто строки в файле располагаются в обратном порядке, т.е. сначала идет самая нижняя строка изображения, затем предпоследняя и т. д.
При сжатии файла изображения, заголовки и палитра обычно переписываются в выходной файл без изменения – кодированию подвергаются только сами растровые данные.
Классификация методов сжатия
Степень эффективности сжатия характеризуется коэффициентом сжатия, который показывет отношение объема исходных данных к объёму сжатых данных:
![]() ; (1)
; (1)
Если
![]() >1,
то сжатие считается эффективным.
>1,
то сжатие считается эффективным.
Сжатие возможно благодаря информационной избыточности данных: т.е. одну и ту же информацию можно представить более компактными способами.
Избыточность может быть двух типов: статистическая и визуальная. Статистическая избыточность возникает из-за того, что данные, как правило, не представляют собой набор случайных байтов информации, а коррелированы между собой и, следовательно, обладают предсказуемостью.
Визуальная избыточность связана с особенностями физиологического восприятия информации человеком. Она позволяет отбросить некоторую, незначительную для восприятия часть данных, достигая тем самым значительной степени сжатия.
Таким образом, сжатие может быть без потерь и с потерями качества. Сжатие без потерь означает, что закодированные данные после распаковки будут иметь неизменный первоначальный вид. Соответственно сжатие с потерями предполагает внесение некоторых необратимых изменений в исходные данные. Все методы сжатия, основанные на статистической избыточности используют кодирование без потерь, в то время как использование визуальной избыточности почти всегда приводят к потерям. Однако чаще всего эти потери не заметны «на глаз» при просмотре изображения.
Все алгоритмы сжатия по соотношению времени на кодирование данных и на их распаковку делятся на симметричные и несимметричные.
Симметричные алгоритмы сжатия требуют одинаковое время на кодирование и распаковку данных. Несимметричные алгоритмы сжатия тратят больше времени на кодирование данных, чем на их распаковку.
В настоящее время разработано большое количество различных алгоритмов сжатия изображений: от самых простых (коэффициент сжатия k=1,12) до самых изощрённых, обеспечивающих k30. Стоит отметить, что более сложные схемы сжатия часто используют комбинацию более простых алгоритмов для достижения максимального эффекта.
Алгоритм группового кодирования
Этот алгоритм (известный в англоязычной литературе как RLE – Run Length Encoding) является самым простым и, как следствие, самым быстрым и нетребовательным к ресурсам ЭВМ.
Его идея предельно проста: если во входном потоке данных встречаются повторяющиеся группы символов (байтов), то в выходной (сжатый) поток записываются лишь число символов в группе и сам повторяющийся символ. Таким образом, сжатые данные будут представлять собой набор 2-х байтовых пакетов (т.н. REP-записей), в 1-м байте которых записывается число повторений данного символа в группе, а во 2-м хранится сам повторяющийся символ. Например, последовательность
AAAAAAAAbbbbbCCCCCCC
будет закодирована как
8A5b7C
Так как исходная строка занимала 20 байт, а кодированная – 6 байт, то в результате достигается коэффициент сжатия k3,3.
Примечание: при вычислении коэффициента сжатия в алгоритмах RLE и LZW(см. далее) принять, что любой символ исходных данных, а также счётчик числа повторений (в RLE) и номер ссылки из словаря (в LZW) занимают ровно 1 байт.
На рис.2 приведен стандартный алгоритм группового кодирования.
Однако степень сжатия алгоритма RLE сильно зависит от вида исходных данных: если среди них нет больших групп одинаковых символов, то эффект сжатия будет обратным.
Для устранения этого негативного эффекта обычно используется следующий приём. Такие «неудобные» последовательности кодируют специальным пакетом, состоящим из 3-х из частей: в 1-ю часть записывается счетчик повторений, равный 0; во 2-ю – число символов в группе и, наконец, - сами несжатые данные (их называют литеральной группой). Такая оптимизация несколько усложняет алгоритм группового кодирования (нужно каким-то образом отыскивать литеральные группы), но зато позволяет избежать эффекта «обратного сжатия».
Пример
Исходная строка символов
AbCdEEEEE (9 байт)
после кодирования без учёта литеральных групп примет вид
1A1b1C1d5E (10 байт),
а после кодирования с учётом литеральных групп
04AbCd5E (8 байт).

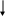
Счетчик повторений символов nRep
=1
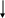

Чтение символа А


Да

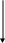


Нет



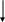
Да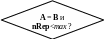


Нет






Рис. 2. Блок-схема алгоритма RLE (без учёта литеральных групп)
Очевидно, критерием целесообразности использования литеральных групп для некоторого набора из n символов, принадлежащих исходному потоку данных, является выполнение условия n+2 N, где N – число байт, получившихся при стандартном RLE-кодировании того же набора символов ( в предыдущем примере для набора AbCd это условие примет вид 4+2 8, следовательно, есть эффект от кодирования литеральной группы).
В другом варианте кодирования литеральных групп пакет состоит из 2-х частей: в 1-ю часть записывается число символов в группе (127); во 2-ю – несжатые данные. При распаковке пакеты литеральных групп отличают от обычных по старшему биту первого байта пакета: если он установлен в 0 – значит это счетчик повторений (диапазон 1-127), если в 1 – то это количество символов в литеральной группе (диапазон 2-127).
Тот или иной вариант оказывается более оптимальным в различных случаях. Например, если в потоке входных данных есть много больших групп одинаковых символов (около 255) и мало групп неодинаковых, то эффективнее использовать 3-х байтовую схему кодирования литеральных групп. В противном случае предпочтительнее использовать 2-х байтовую схему.
Алгоритм сжатия LZW
Данный алгоритм, созданный в 1984 году Терри Уэлчем, является модификацией метода сжатия LZ, который впервые разработали А.Лемпель и Я.Зив в 1977 году. Первые буквы фамилий ученых, принявших участие в создании алгоритма, дали ему название LZW.
LZW относится к группе словарных методов сжатия, которые разбивают входной поток данных на слова. Словом называется последовательность символов (байт). Совокупность всех слов называется словарем, в котором каждое слово содержится под своим номером (индексом, ссылкой). В выходной поток записываются только ссылки. Эффект сжатия возникает за счет того, что длина ссылок, как правило, меньше и длины слов. Словарь формируется итеративно, по ходу работы алгоритма сжатия/распаковки.
Алгоритм LZW является симметричным, причем основное время затрачивается на составление словаря. Этот метод особенно хорош для сжатия изображений с пиксельной глубиной до 8 бит/пиксель, содержащих много коротких пиксельных групп. Для таких изображений LZW обычно более эффективен, чем алгоритм группового кодирования RLE, причем эффективность сжатия тем выше, чем длиннее поток входных данных, т.е. чем больше изображение.
Рассмотрим подробнее схему работы алгоритма. Априорно считается, что словарь уже содержит N однобуквенных слов, где N – количество символов в алфавите. Алфавитом называется множество всех возможных символов, которые могут встретиться во входном потоке данных. Выбираем очередной символ из входного потока: если в словаре есть слова, начинающиеся с него, то выбираем следующий символ. Так повторяем до тех пор, пока не окажется, что образовавшегося нет в словаре. Тогда набранная комбинация представима в виде «W+c», где W - слово из словаря, с – отличающийся символ. В выходной (сжатый) поток записывается только номер слова W, а набор новой комбинации начинается с символа с.
Ниже представлено подробное описание алгоритма LZW.
[1] Инициализация словаря символами алфавита;
[2] Слово W = <пусто>;
[3] c = <следующий символ в потоке данных>;
[4] Входит ли слово Wc в словарь?
Да: W=Wc;
Переход к шагу [3].
Нет: Добавить Wс в словарь;
Записать номер слова W в выходной поток.
[5] Есть ли ещё символы во входном потоке?
Да: Переход к шагу [3];
Нет: Завершение работы алгоритма.
Пример
Сжать методом LZW цепочку символов
a b b a a b b a a b a b b a a a a b a a b b a
Инициализируем словарь символами а и b, так как другие символы в цепочке не встречаются. Берём первый символ из входного потока – а. Есть ли это слово (пока односимвольное) в словаре? Есть, тогда берём следующий символ из потока – b и присоединяем его к текущему слову, т.е. к а. Есть ли получившееся слово ab в словаре? Нет, тогда добавляем его в словарь, а в выходной поток записываем номер слова а. Теперь набор новой комбинации начинается с символа b. Берём следующий (третий) символ из входного потока – b и добавляем его к текущему слову – b. Есть ли слово bb в словаре? Нет - добавляем его в словарь, а в выходной поток записываем номер слова b, и т. д. В результате получаем следующий словарь:
a | b| b | a | a b | b a | a b | a b b | a a | a a | b a a | b b | a
0 1 1 0 2 4 2 6 5 5 7 3 0
номер слова |
слово |
номер слова |
слово |
0 |
a |
7 |
baa |
1 |
b |
8 |
aba |
2 |
ab |
9 |
abba |
3 |
bb |
10 |
aaa |
4 |
ba |
11 |
aab |
5 |
aa |
12 |
baab |
6 |
abb |
13 |
bba |
и сжатый выходной поток, состоящий только из ссылок (номеров слов):
0 1 1 0 2 4 2 6 5 5 7 3 0
Если предположить, что входной поток был байтовым, и на каждую ссылку отводится тоже один байт, то получаем коэффициент сжатия k=23/131.7
Примечание: при расчёте коэффициента сжатия для алгоритма LZW не учитывается размер самого словаря, поскольку при распаковке сжатых данных словарь составляется динамически по аналогичной схеме.
В
реальных программах сжатия алгоритм
LZW
редко применяется в чистом виде. Это
связано с преодолением некоторых
практических трудностей при реализации.
Одна из них связана с тем, что словарь
имеет ограниченный размер, так как под
код ссылки отводиться некое фиксированное
количество бит. Например, если ссылка
кодируется одним байтом, то словарь
может вместить максимум
![]() различных
слов. Следовательно, существует риск
переполнения, поэтому фиксированный
размер словаря снижает эффективность
сжатия. Для решения этой проблемы на
практике применяют различные стратегии
ведения словаря. В целях повышения
скорости работы алгоритма применяют
также оптимизацию поиска слов с
использованием древовидной структуры
словаря или хеш-таблиц. Кроме этого, для
достижения максимального сжатия,
выходной поток алгоритма LZW
кодируется одним из статистических
методов, например кодом
Хаффмана.
Такая схема сжатия используется в широко
известных архиваторах RAR
и ZIP.
различных
слов. Следовательно, существует риск
переполнения, поэтому фиксированный
размер словаря снижает эффективность
сжатия. Для решения этой проблемы на
практике применяют различные стратегии
ведения словаря. В целях повышения
скорости работы алгоритма применяют
также оптимизацию поиска слов с
использованием древовидной структуры
словаря или хеш-таблиц. Кроме этого, для
достижения максимального сжатия,
выходной поток алгоритма LZW
кодируется одним из статистических
методов, например кодом
Хаффмана.
Такая схема сжатия используется в широко
известных архиваторах RAR
и ZIP.
Алгоритм сжатия с использованием кодов Хаффмана
Данный алгоритм (далее для краткости - алгоритм Хаффмана) был разработан в 1952 году и относится к группе статистических методов сжатия. Статистические методы используют различные приёмы для того, чтобы наиболее часто встречающимся символам соответствовали более короткие коды. При этом каждый код однозначно соответствует конкретному символу. Например, в тексте на русском языке буква а встречается гораздо чаще, чем буква ы, поэтому имеет смысл присвоить букве а более короткий код. Соответственно выходной поток этих методов является бит-ориентированным, т.е. не форматированным по границам байтов. Статистические методы работают медленнее словарных, но достигают, как правило, более высокой степени сжатия. Они используют три основных модели для набора статистики (определения вероятностей символов):
неадаптивную;
полуадаптивную;
адаптивную.
В неадаптивных моделях вероятности всех символов алфавита определены заранее. Эта модель обычно применяется только при сжатии текстовых файлов. В полуадаптивных моделях входные данные обрабатываются за 2 прохода: 1-й – для подсчёта вероятностей, 2-й – собственно для сжатия. Эта модель может применяться для сжатия не очень больших изображений. Адаптивные модели вычисляют и корректируют вероятности символов в процессе сжатия, т.е. «на лету». Модели последнего типа сложнее предыдущих, зато являются более универсальными и часто дают наилучшее сжатие.
Рассмотрим кодирование по Хаффману более подробно. Предположим, что вероятности (их заменят частоты) всех символов алфавита уже подсчитаны одним из вышеописанных способов. Тогда:
Выписываем в ряд все символы алфавита в порядке убывания вероятноcтей (частоты) их появления в потоке данных (для удобства построения дерева);
Объединяем два символа с наименьшими вероятностями в новый составной символ, вероятность которого определяется как сумма вероятностей составляющих его символов. Последовательно повторяем эту операцию до образования единственного составного символа (корня). В результате получается дерево символов, каждый узел которого имеет суммарную вероятность всех объединённых им узлов.
Прослеживаем путь от каждого листа дерева к корню, помечая направление движения к каждому узлу (например, вверх/направо –1, вниз/налево - 0). При этом не важен конкретный вид разметки «ветвей» дерева (т.е. помечать направление вверх/направо –1, вниз/налево – 0, или наоборот), но важно придерживаться выбранного способа разметки ко всем «ветвям» дерева.
Получившиеся двоичные комбинации, записанные от конца к началу и формируют коды Хаффмана.
Полученный коэффициент сжатия подсчитывается по следующей формуле
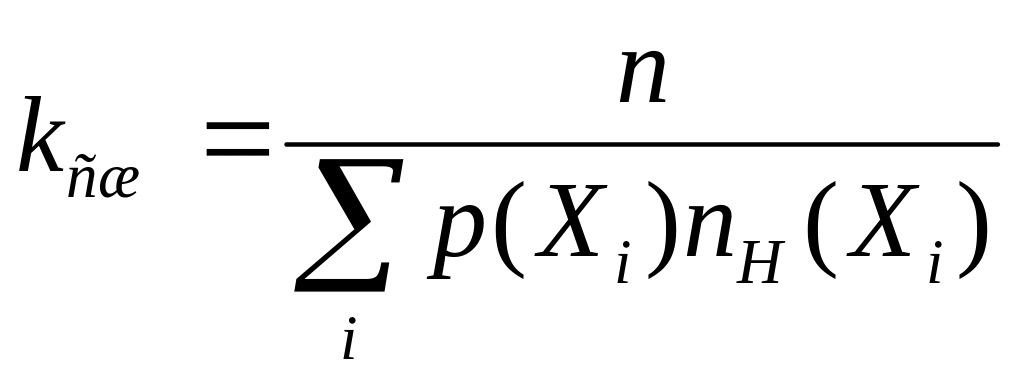 ,
(2)
,
(2)
где
n – количество бит, необходимое для кодирования символов алфавита фиксированным числом разрядов;
![]() -
вероятность (частота) повторения символа
-
вероятность (частота) повторения символа
![]() во входном потоке;
во входном потоке;
![]() -
количество бит в коде Хаффмана для
символа
.
-
количество бит в коде Хаффмана для
символа
.
Коды Хаффмана никогда не увеличивают, а чаще всего наоборот, уменьшают среднюю длину кодовых слов для символов в цепочке данных. Поэтому сжатие с применением кодов Хаффмана, всегда имеет коэффициент 1 , причём знак равенства получается только в том случае, когда вероятности всех символов во входном потоке одинаковы.
Пример кодирования по Хаффману приведен на рис. 3.
Примечание:
1) для удобства расчётов при выполнении практической части, дробное значение частоты символа можно заменить целым числом появлений данного символа в цепочке, поэтому в корне дерева получится не 1 (сумма частот), а значение, равное длине цепочки. В этом случае коэффициент сжатия рассчитывается по формуле
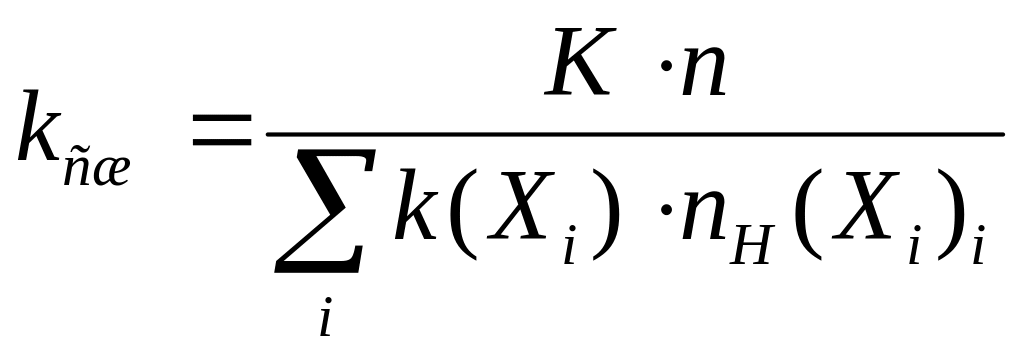 , (3)
, (3)
где
K – общее количество символов во входном потоке;
![]() – количество
символов
– количество
символов
![]() во
входном потоке.
во
входном потоке.
2) частоты появления символов в примере расположены не по убыванию исключительно ради наглядности внешнего вида «дерева», т.к. в противном случае ветви пересекались бы между собой. Несмотря на то, что коды Хаффмана в обоих случаях могут отличаться, это не имеет значения, поскольку сохранится свойство однозначности кодов Хаффмана, т.е. ни один из кодов не совпадет с начальными битами другого, более длинного кода.
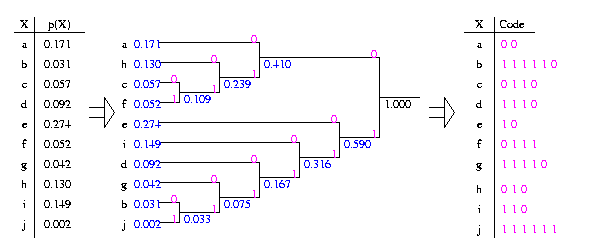
Рис.3. Пример кодирования по Хаффману.
Если предположить, что входной поток символов был байт-ориентированным, то n=8. Тогда коэффициент сжатия
![]()
Если
считать входной поток символов
бит-ориентированным с равным количеством
бит под каждый символ, то n=4
(т.к. для кодирования 10 различных символов
a-j
требуется
![]() разряда). В этом случае
будет означать выигрыш, полученный от
применения кодов Хаффмана по сравнению
с кодами фиксированной, минимально
необходимой битовой размерности. В этом
случае
разряда). В этом случае
будет означать выигрыш, полученный от
применения кодов Хаффмана по сравнению
с кодами фиксированной, минимально
необходимой битовой размерности. В этом
случае
![]()
Кодирование по Хаффману может использоваться при сжатии изображений как самостоятельно, так и в составе других алгоритмов сжатия, например LZW и JPEG (это наиболее эффективное его применение).
Алгоритм сжатия JPEG
Этот алгоритм появился в конце 1980-х гг. в результате долгих исследований группы специалистов, что и дало ему название JPEG – Joint Photographic Experts Group, т.е. объёдиненная группа экспертов по фотографии. Являясь алгоритмом сжатия с потерями, JPEG даёт очень высокий коэффициент сжатия. Для сложных изображений - до 10 (без заметного ухудшения качества) и более (с заметным ухудшением качества). Для сравнительно простых изображений, имеющих большие области одинакового цвета, коэффициент сжатия может достигать 20-25.
Используя волновую природу света, JPEG представляет изображение как суперпозицию множества гармоник световых волн разных частот. При этом основную энергию несут низкочастотные гармоники, в то время как высокочастотные могут быть отброшены без заметного ухудшения качества изображения. При этом имеется возможность регулировать этот частотный порог, меняя тем самым степень сжатия.
Алгоритм JPEG включает четыре основных этапа:
Предварительная подготовка изображения;
Дискретное косинусное преобразование;
Квантование;
Вторичное сжатие.
На 1-м этапе цветное RGB-изображение разделяется на три цветовых плоскости (красную, зеленую и синюю). Затем каждая плоскость разбивается на квадратные участки размером 8x8 пикселей и далее кодируется отдельно.
Примечание. Для достижения лучшего сжатия изображение может переводиться (хотя и не обязательно) в другую цветовую модель – YUV, где Y – яркость, U и V – цветоразностные компоненты:
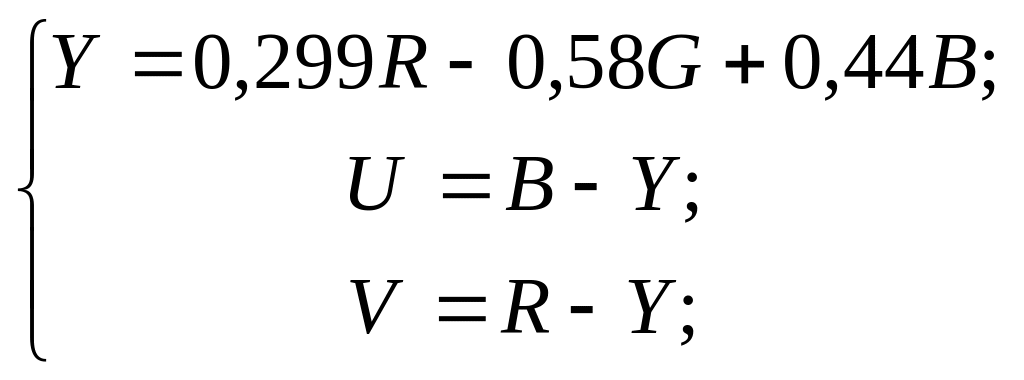 (4)
(4)
После этого матрицы, соответствующие плоскостям U и V подвергаются прореживанию (субдискретизации) путем выбрасывания каждой второй строки и столбца. Это и позволяет получить дополнительный эффект сжатия при использовании цветовой модели YUV.
Основным этапом работы алгоритма является дискретное косинусное преобразование (ДКП), представляющее собой разновидность преобразования Фурье. Оно позволяет переходить от пространственного представления изображения к его спектральному представлению и обратно. Другими словами, фрагмент изображения после ДКП представляет собой двумерный частотный спектр в вертикальном и горизонтальном направлениях. При этом в левом верхнем углу матрицы располагаются коэффициенты низкочастотных гармоник, величина которых обычно больше остальных.
Пусть матрица блока изображения обозначается IMG =[8х8]. Проведём её нормализацию, вычитая из каждого её элемента 128. Дискретное косинусное преобразование осуществляется по формуле
![]() (5)
(5)
где
![]()
![]() (6)
(6)
N=8, i=0..7, j=0..7.
На этапе квантования сначала вычисляется матрица квантования по следующей формуле
![]() ,
(7)
,
(7)
i,j =0..7
где q – коэффициент качества, регулирующий степень сжатия.
Затем каждое число в матрице RES нужно разделить на соответствующий элемент в матрице Q. В результате получится некоторая матрица A, у всех элементов которой необходимо отбросить дробные части. В итоге матрица A будет содержать много нулевых элементов, преимущественно в правой нижней части.
На этапе вторичного сжатия элементы матрицы А пакуются максимально компактным образом. Для достижения максимального эффекта сжатия применяется предварительное Z-упорядочивание элементов матрицы A(8x8) в линейный вектор A(64x1), выполняемое по следующей схеме:
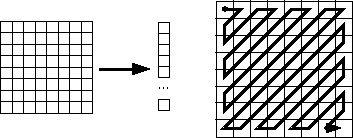
+----+----+----+----+----+----+----+----+
| 1 | 2 | 6 | 7 | 15 | 16 | 28 | 29 |
+----+----+----+----+----+----+----+----+
| 3 | 5 | 8 | 14 | 17 | 27 | 30 | 43 |
+----+----+----+----+----+----+----+----+
| 4 | 9 | 13 | 18 | 26 | 31 | 42 | 44 |
+----+----+----+----+----+----+----+----+
| 10 | 12 | 19 | 25 | 32 | 41 | 45 | 54 |
+----+----+----+----+----+----+----+----+
| 11 | 20 | 24 | 33 | 40 | 46 | 53 | 55 |
+----+----+----+----+----+----+----+----+
| 21 | 23 | 34 | 39 | 47 | 52 | 56 | 61 |
+----+----+----+----+----+----+----+----+
| 22 | 35 | 38 | 48 | 51 | 57 | 60 | 62 |
+----+----+----+----+----+----+----+----+
| 36 | 37 | 49 | 50 | 58 | 59 | 63 | 64 |
+----+----+----+----+----+----+----+----+
Самым распространенным методом вторичного сжатия является сжатие с применением кодов Хаффмана. В полученном векторе А первый элемент (с индексом 0) называется DC коэффициентом. Он пропорционален средней яркости блока и обычно намного больше других элементов вектора. Остальные 63 элемента вектора называются AC коэффициентами, они пропорциональны интенсивности цветовых переходов в блоке. DC и AC коэффициенты кодируются по-разному, но по схожим принципам.
Код для DC коэффициента состоит из полей РАЗМЕР (число бит, необходимых для представления значения) и ЗНАЧЕНИЕ (биты самого значения).
Код для AC коэффициента состоит из полей ПРОПУСК (количество предшествующих нулевых AC коэффициентов), РАЗМЕР (число бит, необходимых для представления значения) и ЗНАЧЕНИЕ (биты самого значения).
Поле ЗНАЧЕНИЕ для обоих типов коэффициентов кодируется идентичным способом в соответствии с табл.1.
Для DC коэффициента поле РАЗМЕР кодируется в соответствии с табл. 2.
Для АC коэффициента поля ПРОПУСК и РАЗМЕР рассматриваются как один составной символ вида (ПРОПУСК, РАЗМЕР), который кодируется в соответствии с табл. 3. Причем символ (0,0) называется признаком конца блока и означает, что с текущего места и до конца вектор содержит только нулевые AC коэффициенты.
Таблица 1. Кодирование поля ЗНАЧЕНИЕ в DC и AC коэффициентах
Поле ЗНАЧЕНИЕ в DC и AC коэффициентах |
||
Величина (значение)
|
Число бит |
Биты (в выходном потоке) |
0 |
0 |
- |
-1,1 |
1 |
0,1 |
-3,-2, 2, 3 |
2 |
00,01,10,11 |
-7,-6,-5,-4, 4, 5, 6, 7 |
3 |
000,001,010,011,100,101,110,111 |
-15..-8, 8..15 |
4 |
0000..0111,1000..1111 |
-31..-16, 16..31 |
5 |
00000..01111,10000..11111 |
-63..-32, 32..63 |
6 |
000000..011111,100000..111111 |
-127..-64, 64..127 |
7 |
0000000..1111111 |
-255..-128, 128..255 |
8 |
00000000..11111111 |
-511..256, 256..511 |
9 |
000000000..111111111 |
-1023..-512, 512..1023 |
10 |
0000000000..1111111111 |
-2047..-1024, 1024..2047 |
11 |
00000000000..11111111111 |
-4095..2048, 2048..4095 |
12 |
000000000000..111111111111 |
-8191..-4096, 4096..8191 |
13 |
0000000000000..1111111111111 |
-16383..-8192, 8192..16383 |
14 |
00000000000000..11111111111111 |
-32767..-16384, 16384..32767 |
15 |
000000000000000..111111111111111 |
Таблица 2. Коды Хаффмана для поля РАЗМЕР в DC коэффициентах
Поле РАЗМЕР в DC коэффициенте |
||
Десятичный вид
|
Двоичный вид |
Код Хаффмана |
0 |
0000 |
00 |
1 |
0001 |
010 |
2 |
0010 |
011 |
3 |
0011 |
100 |
4 |
0100 |
101 |
5 |
0101 |
110 |
6 |
0110 |
1110 |
7 |
0111 |
11110 |
8 |
1000 |
111110 |
9 |
1001 |
1111110 |
10 |
1010 |
11111110 |
11 |
1011 |
111111110 |
Таблица 3. Коды Хаффмана для составного символа в AC коэффициентах
Составной символ = (ПРОПУСК, РАЗМЕР) для АC коэффициентов |
|
(ПРОПУСК, РАЗМЕР)
|
Код Хаффмана |
[конец блока]=(0,0) |
1010 |
(0,1) |
00 |
(0,2) |
01 |
(0,3) |
100 |
(0,4) |
1011 |
(0,5) |
11010 |
(0,6) |
1111000 |
(0,7) |
11111000 |
(1,1) |
1100 |
(1,2) |
11011 |
(1,3) |
1111001 |
(1,4) |
111110110 |
(2,1) |
11100 |
(2,2) |
11111001 |
(3,1) |
111010 |
(3,2) |
111110111 |
(4,1) |
111011 |
(5,1) |
1111010 |
(6,1) |
1111011 |
(7,1) |
11111010 |
(8,1) |
1111110000 |
(9,1) |
1111110001 |
Полученные биты кодовых значений DC и AC коэффициентов записываются в выходной поток, и JPEG переходит к сжатию следующего блока данных, и т.д. Распаковка сжатых данных из полученного битового потока и восстановление изображения осуществляется в строго обратном порядке.
Пример
Блок 8x8 (фрагмент) исходного изображения (размер 64*8=512 бит)
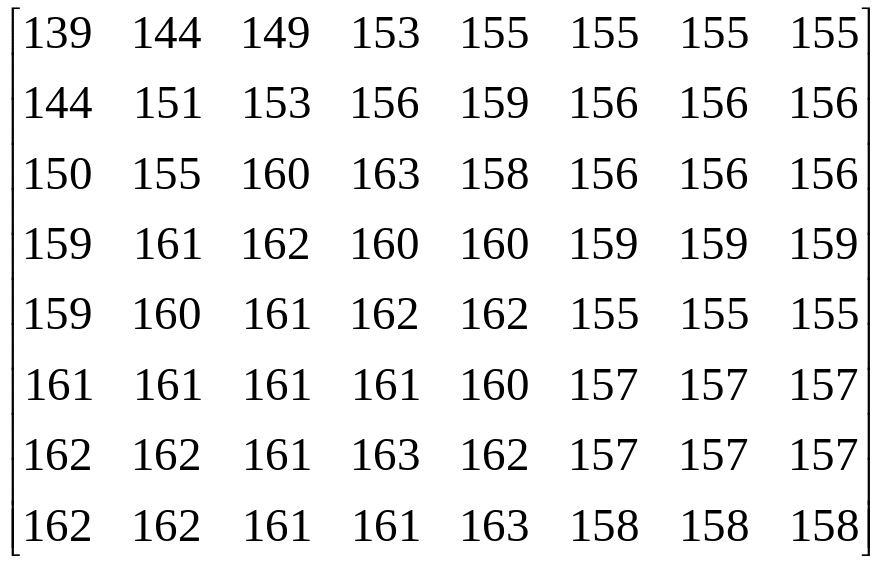
Матрица DCT коэффициентов

Матрица квантованных DCT коэффициентов
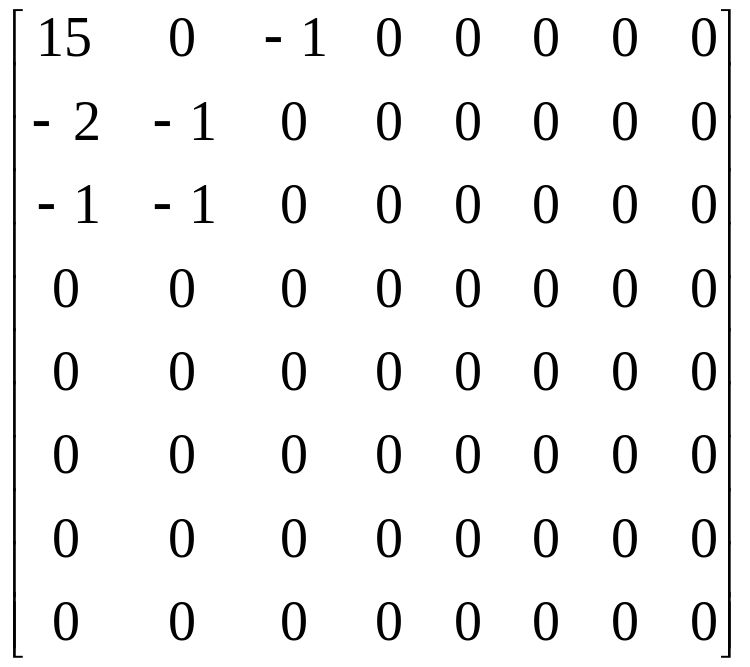
Кодовая последовательность в десятичном виде
(2)(3) (1,2)(-2) (0,1)(-1) (0,1)(-1) (0,1)(-1) (2,1)(-1) (0,0)
Кодовая последовательность в двоичном виде с учетом кодов Хаффмана
(011)(11) (11011)(01) (00)(0) (00)(0) (00)(0) (11100)(0) (1010)
Результирующая битовая последовательность (31 бит)
0111111011010000000001110001010
Коэффициент
сжатия
![]()
Контрольные вопросы
В чем отличие растровых и векторных форматов хранения данных ?
Что такое палитра и в каких случаях она применяется ?
Что такое информационная избыточность и каких видов она бывает ?
В каких случаях коэффициент сжатия оказывается меньше единицы?
Что необходимо для эффективного сжатия по алгоритму LZW ?
Может ли кодирование по Хаффману дать
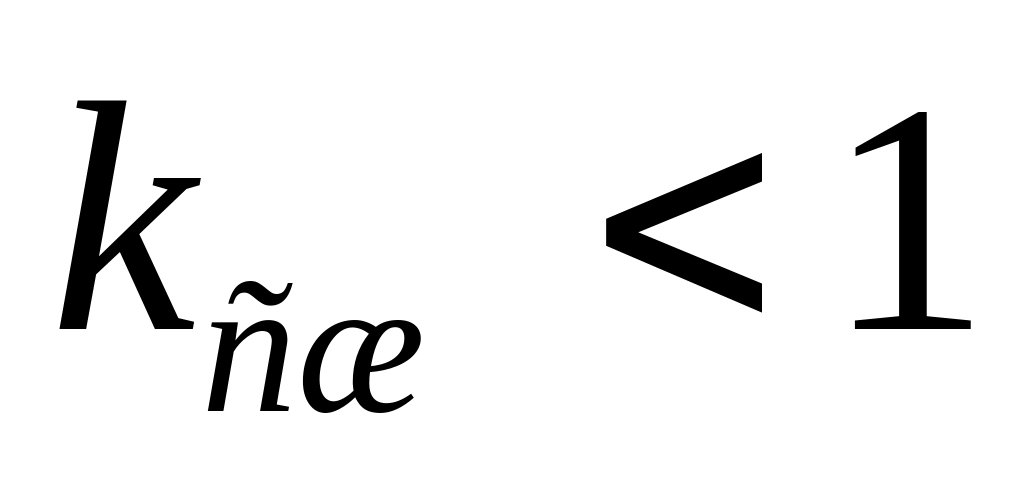 ? Почему ?
? Почему ?Чем объясняется высокая степень сжатия, которую обеспечивает алгоритм JPEG?