

7. Кодирование с минимальной избыточностью, алгоритм Шеннонна Фано.
Кодированием называется запись информации в виде сообщения и переход от одной формы записи информации к другой, содержащей ту же самую информацию.
Кодом называется правило, описывающее отображение одного набора знаков в другой набор знаков, а также множество образов при этом отображении.
Множество кодов делят на две большие группы: равномерные (код, в котором все кодовые слова состоят из одинакового количества символов кодового алфавита) и неравномерные (коды, в которых присутствуют кодовые слова разной длины).
Первая теорема Шеннона: сообщение произвольного источника информации z с энтропией H(z) всегда можно закодировать последовательностями в алфавите B, состоящем из M символов так, что средняя длина кодового слова будет сколь угодно близкой к величине lmin=H(z)/log2M, но не меньше ее. Для оценивания оптимальности кода используют коэффициент оптимальности кода: kопт=lmin/lср.
Условие Фано (принцип префиксности): для того, чтобы неравномерный код был однозначно и правильно декодируем, достаточно при его построении обеспечить выполнение следующего условия: никакое кодовое слово не должно быть началом никакого другого кодового слова.
Объемом информации называется количество переданной информации, рассчитанное относительно вторичного (кодового) алфавита. Объем информации (в единицах измерения по основанию М) равен числу М-ичных символов в закодированном тексте.
объем информации не может быть меньше, чем количество информации.
Избыточностью кода L при кодировании алфавита А некоторым фиксированным кодом в алфавите В назовем превышение средней Длины кодового слова в этом коде над минимально возможной
L =lср-H
(A)/log2M
=lср-H
(A)/log2M
Средняя длина кодового слова lСр
г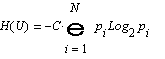 де
N - количество символов исходного
алфавита, М –количество символов
закодированного алфавита p1,
p2,
…, pN
- вероятности появления символов
исходного алфавита, l1,l2,...
,lN
– длины кодовых слов, С – константа.
де
N - количество символов исходного
алфавита, М –количество символов
закодированного алфавита p1,
p2,
…, pN
- вероятности появления символов
исходного алфавита, l1,l2,...
,lN
– длины кодовых слов, С – константа.
Энтропия отражает степень неопределенности состояния системы и одновременно является количественной мерой информации.
Оптимальными кодами будем называть коды безызбыточные или с избыточностью, близкой к 0.
Метод Шеннона-Фано состоит в том, что кодируемые символы (буквы или комбинации букв) разделяются на две приблизительно равновероятные группы: для первой группы символов на первом месте комбинации ставится 0, для второй группы — 1. Далее каждая группа снова делится на две приблизительно равновероятные подгруппы и т.д.
Шаг 1. Символы исходного алфавита упорядочиваются по невозрастанию вероятностей. В результате получаем последовательность (ai1, ai2, . . .., ain ).
В этой последовательности для всех j = 1,2,..., N - 1 выполняется соотношение р(aij) >= p(aij+1).
Шаг 2. Переменной-счетчику t присваивается значение 1:t:=1.
Шаг 3. Рассматриваемую последовательность разбиваем на М групп, не меняя порядка следования символов так, чтобы суммарные вероятности символов в каждой группе были примерно одинаковы и максимально близки к 1/М. Получаем совокупность подпоследовательностей G1,G2,...,gm g1 = (ai1,ai2...,aik1),
Шаг4. Формируем t-й символ кодовых слов. Всем символам из последовательности G, приписываем символ bs,s=l,2,...,M.
Шаг 5. Переменная-счетчик увеличивается на 1: t := t + 1.
Шаг 6. Просматриваем все группы-подпоследовательности.
Если некоторая группа G, состоит из одного символа aj, то для этого aj процесс построения кодового слова считается законченным.
Для каждой из этих групп, содержащих по 2 и более символов, выполняем действия, соответствующие шагу 3 и 4- В результате получаем очередные 1-е символы кодовых слов.
После просмотра всех групп, осуществляется переход к шагу 5.
Процесс работы алгоритма заканчивается, когда все группы будут содержать ровно по одному символу исходного алфавита.
Код Фано
Вход: Р:array[1..n] of real; - массив вероятностей появления букв в сообщении, упорядоченный по невозрастанию.
Выход: C: array[1..n,1..L]:of 0..1-массив элементарных кодов.
Fano (1,n,0) вызов рекурсивной процедуры
Вход: b – индекс начала обрабатываемой части массива Р;
е – индекс конца обрабатываемой части массива Р;
к – длинна уже построенных кодов в обрабатываемой части массива С.
Выход: заполненный массив С
If e>b then
K:=k+1; (место для очередного разряда в коде)
M:=Med(b,e); (деление массива на две части)
For i from b to e do
C[i,k]:=i>m; (в первой части – 0, а во второй – 1)
End;
Fano(b,m,k); (обработка первой части)
Fano(m+1,e,k); (обработка второй части)
End;
Функция Med находит медиану указанной части массива P[b..e], т.е. определяет такой индекс m (m<=m<e), при которой сумма элементов P[b..e] наиболее близка к сумме элементов P[m+1..e]
Вход: b – индекс начала обрабатываемой части массива Р;
е – индекс конца обрабатываемой части массива Р;
Выход: m – индекс медианы.
Sb:=0; (сумма элементов первой части)
For i from b to e-1 do
Sb:=Sb+P[i]; (вначале все кроме последнего)
End;
Se:=P[e]; (сумма элементов второй части)
M:=e; (начинаем искать медиану с конца)
Repeat
D:=Sb-Se; (разность сумм первой и второй части)
M:=m-1; (сдвигаем границу медианы вниз)
Sb:=Sb-P[m];
Se:=Se+P[m];
Until |Sb-Se|>=d;
Return m