

6.5.2. Обучение вектору параметров
Используя правило Байеса, можем написать
г![]() де
независимость выборок приводит к
де
независимость выборок приводит к
С![]() другой стороны, обозначив через
Xn
множество п
выборок, мы можем записать соотношение
(20) в
рекуррентной форме
другой стороны, обозначив через
Xn
множество п
выборок, мы можем записать соотношение
(20) в
рекуррентной форме
Э
 то
основные соотношения для байесовского
обучения без учителя. Уравнение
(20)
подчеркивает связь между байесовским
решением и решением по максимуму
правдоподобия. Если p()
существенно равномерна в области, где
имеется пик у p(X
|),
то у p(|X)
имеется пик
в том же самом месте. Если имеется только
один существенный пик при
=
то
основные соотношения для байесовского
обучения без учителя. Уравнение
(20)
подчеркивает связь между байесовским
решением и решением по максимуму
правдоподобия. Если p()
существенно равномерна в области, где
имеется пик у p(X
|),
то у p(|X)
имеется пик
в том же самом месте. Если имеется только
один существенный пик при
=![]() и этот пик очень острый, то соотношения
(19) и
(18) дают
и этот пик очень острый, то соотношения
(19) и
(18) дают
То есть эти условия оправдывают использование оценки по максимуму правдоподобия, используя ее в качестве истинного значения при создании байесовского классификатора.
Естественно, если плотность р() была получена при обучении с учителем с использованием большого множества помеченных выборок, она будет далека от равномерной и это решающим образом повлияет на p(|Xn), когда n мало. Соотношение (22) показывает, как при наблюдении дополнительных непомеченных выборок изменяется наше мнение об истинном значении и особое значение приобретают идеи модернизации и обучения. Если плотность смеси p(х|) идентифицируема, то с каждой дополнительной выборкой p(|Xn)становится все более острой, и при достаточно общих условиях можно показать, что p(|Xn) сходится (по вероятности) к дельта-функции Дирака с центром в истинном значении . Таким образом, даже если мы не знаем класса выборок, идентифицируемость дает нам возможность узнать вектор неизвестных параметров и вместе с этим узнать плотности компонент p(x|i,).
Тогда это и есть формальное байесовское решение задачи обучения без учителя. В ретроспективе тот факт, что обучение без учителя параметрам плотности смеси тождественно обучению с учителем параметрам плотности компонент, не является удивительным. Действительно, если плотность компонент сама по себе является смесью, то тогда действительно не будет существенной разницы между этими двумя задачами.
Однако существуют значительные различия между обучениями с учителем и без учителя. Одно из главных различий касается вопроса идентифицируемости. При обучении с учителем отсутствие идентифицируемости просто означает, что вместо получения единственного вектора параметров мы получаем эквивалентный класс векторов параметров. Однако, поскольку все это приводит к той же плотности компонент, отсутствие идентифицируемости не представляет теоретических трудностей. При обучении без учителя отсутствие идентифицируемости представляет более серьезные трудности. Когда нельзя определить единственным образом, смесь нельзя разложить на ее истинные компоненты. Таким образом, в то время как p(x|Xn)может все еще сходиться к р(х), величина p(x|i ,Xn), описываемая выражением (19), в общем ре сойдется к p(x|i), т. е. существует теоретический барьер в обучении.
Д![]() ругая
серьезная проблема для обучения без
учителя
— это
вычислительная сложность. При обучении
с учителем возможность нахождения
достаточной статистики дает возможность
получить решения, которые решаются как
аналитическими, так и численными
методами. При обучении без учителя
нельзя забывать, что выборки получены
из плотности смеси
ругая
серьезная проблема для обучения без
учителя
— это
вычислительная сложность. При обучении
с учителем возможность нахождения
достаточной статистики дает возможность
получить решения, которые решаются как
аналитическими, так и численными
методами. При обучении без учителя
нельзя забывать, что выборки получены
из плотности смеси
и поэтому остается мало надежды найти простые точные решения для p(|X). Такие решения связаны с существованием простой достаточной статистики, и теорема факторизации требует возможностипредставления р(X|) следующим образом:
Н![]() о
по формулам
(21) и
(1) имеем
о
по формулам
(21) и
(1) имеем
Т аким
образом,р(X|)
есть сумма сn
произведений плотностей компонент.
Каждое слагаемое суммы можно
интерпретировать как общую вероятность
получения выборок x1,
. .
., xn
с определенными метками, причем сумма
охватывает все возможные способы пометки
выборок. Ясно, что это приводит к общей
смеси
и всех х,
и нельзя ожидать простой факторизации.
Исключением является случай, когда
плотности компонент не перекрываются,
так что, как только в
изменяется один член, плотность смеси
не равна нулю. В этом случае р(X|)
есть произведение п
ненулевых членов и может обладать
простой достаточной статистикой. Однако,
поскольку здесь допускается возможность
определения класса любой выборки, это
сводит задачу к обучению с учителем и,
таким образом, не является существенным
исключением.
аким
образом,р(X|)
есть сумма сn
произведений плотностей компонент.
Каждое слагаемое суммы можно
интерпретировать как общую вероятность
получения выборок x1,
. .
., xn
с определенными метками, причем сумма
охватывает все возможные способы пометки
выборок. Ясно, что это приводит к общей
смеси
и всех х,
и нельзя ожидать простой факторизации.
Исключением является случай, когда
плотности компонент не перекрываются,
так что, как только в
изменяется один член, плотность смеси
не равна нулю. В этом случае р(X|)
есть произведение п
ненулевых членов и может обладать
простой достаточной статистикой. Однако,
поскольку здесь допускается возможность
определения класса любой выборки, это
сводит задачу к обучению с учителем и,
таким образом, не является существенным
исключением.
Д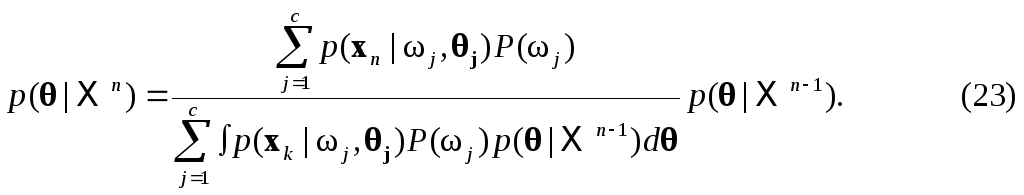 ругой
способ сравнения обучения с учителем
и без учителя состоит в подстановке
плотности смесир(xn|)
в
(22) и
получении
ругой
способ сравнения обучения с учителем
и без учителя состоит в подстановке
плотности смесир(xn|)
в
(22) и
получении
Если мы рассматриваем особый случай, где P(1)=1, а все остальные априорные вероятности равны нулю, соответствующий случаю обучения с учителем, в котором все выборки из класса 1, то формула (23) упрощается до
С![]() равним
уравнения
(23) и
(24), чтобы
увидеть, как дополнительная выборка
изменяет нашу оценку
.
В каждом случае мы можем пренебречь
знаменателем, который не зависит от
.
Таким образом, единственное значительное
различие состоит в том, что в случае
обучения с учителем мы умножаем априорную
плотность для
на плотность компоненты р(xn|1,1),
в то время как в случае обучения без
учителя мы умножаем на плотность смеси
равним
уравнения
(23) и
(24), чтобы
увидеть, как дополнительная выборка
изменяет нашу оценку
.
В каждом случае мы можем пренебречь
знаменателем, который не зависит от
.
Таким образом, единственное значительное
различие состоит в том, что в случае
обучения с учителем мы умножаем априорную
плотность для
на плотность компоненты р(xn|1,1),
в то время как в случае обучения без
учителя мы умножаем на плотность смеси
![]() Предполагая,
что выборка действительно принадлежит
классу
1, мы видим,
что незнание принадлежности какому-либо
классу в случае обучения без учителя
приводит к уменьшению влияния хn
на изменение
.
Поскольку хn
может принадлежать любому из с
классов, мы не можем использовать
его с полной эффективностью для изменения
компонент (компоненты)
,
связанных с каким-нибудь классом. Более
того, это влияние мы должны распределить
на различные классы в соответствии
с вероятностью каждого класса.
Предполагая,
что выборка действительно принадлежит
классу
1, мы видим,
что незнание принадлежности какому-либо
классу в случае обучения без учителя
приводит к уменьшению влияния хn
на изменение
.
Поскольку хn
может принадлежать любому из с
классов, мы не можем использовать
его с полной эффективностью для изменения
компонент (компоненты)
,
связанных с каким-нибудь классом. Более
того, это влияние мы должны распределить
на различные классы в соответствии
с вероятностью каждого класса.