

6.15. Библиографические и исторические сведения
Литература по обучению без учителя и группировкам так обширна и рассеяна среди различных областей науки, что предлагаемый список можно рассматривать как случайную выборку. К счастью, некоторые из источников имеют обширную библиографию, что облегчает нашу задачу. Исторически дата первых источников восходит по меньшей мере к 1894 году, когда Карл Пирсон использовал выборки для определения параметров смеси двух нормальных плотностей одной переменной. Предполагая точное знание значений плотности смеси, Дёч (1936) использовал преобразование Фурье для разложения нормальных смесей. Меджисси (1961) распространил этот подход на другие классы смесей, в процессе решения поставив задачу идентифицируемости. Тэйчер (1961, 1963) и затем Якович и Спреджинс (1968) продемонстрировали идентифицируемость нескольких семейств смесей, причем последние авторы показали эквивалентность идентифицируемости и линейной независимости плотности компонент.
Фразы «обучение без учителя» или «самообучение» обычно относятся к определению параметров плотностей компонент по выборкам, извлеченным из смеси плотностей. Спреджинс (1966) и Купер (1969) дают ценный обзор этой области, а ее связь с последовательным байесовским обучением дана Ковером (1969). Некоторые из этих работ достаточно общие, в первую очередь касающиеся теоретических возможностей. Например, Стейнат (1968) показывает, как метод Дёча можно применить для изучения многомерных нормальных смесей и многомерных смесей Бернулли, а Якович (1970) демонстрирует возможность распознавания практически любой идентифицируемой смеси.
Удивительно мало работ касаются оценок по максимуму правдоподобия. Хесселблад (1966) вывел формулы максимума правдоподобия для оценки параметров нормальных смесей в случае одной переменной. Дей (1969) вывел формулы для случая многомерной матрицы равных ковариаций и указал на существование вырожденных решений с общими нормальными смесями. Наш подход к случаю многих переменных основан непосредственно на исключительно доступной статье Вольфа (1970), который также вывел формулы для многомерных смесей Бернулли. Формулировка байесовского подхода к обучению без учителя обычно приписывается Дэйли (1962); более общие формулировки с тех пор были даны несколькими авторами (см. Хилборн и Лейниотис, 1968). Дэйли отметил экспоненциальный рост оптимальной системы и необходимость приближенных решений. Обзор Спреджинса дает ссылки на литературу по аппроксимациям на основе принятия решений, написанную до 1966 г., ссылки на последующие работы можно найти у Патрика, Костелло и Мондса (1970). Приближенные решения были получены с помощью гистограмм (Патрик и Хенкок, 1966), квантованных параметров (Фрелик, 1967) и рандомизированных решений (Агреула, 1970).
Мы не упомянули все способы, которые можно применить для оценки неизвестных параметров. В частности, мы не рассмотрели испытанных временем и надежных методов, использующих моменты выборок, в первую очередь из-за того, что ситуация становится довольно сложной, когда в смеси имеется больше двух компонент. Однако некоторые интересные решения для особых случаев были получены Дэвидом и Полем Куперами (1964) и усовершенствованы далее Полем Купером (1967). Из-за медленной сходимости мы не упомянули об использовании стохастической аппроксимации; заинтересованному читателю можно рекомендовать статью Янга и Коралуппи (1970).
Первоначально по группировке была проделана большая работа в биологических науках при изучении численной таксономии. Здесь основной интерес вызвала иерархическая группировка. Монография Сокаля и Снифа (1963) является отличным источником библиографии по этой литературе. Психологи и социологи также внесли вклад в группировку, хотя они обычно заинтересованы в группировке признаков, а не в группировке выборок (Трайон, 1939, и Трайон и Бейли, 1970). Появление вычислительных машин сделало кластерный анализ практической наукой и вызвало распространение литературы во многие области науки. Хорошо известная работа Болла (1965) дает исчерпывающий обзор этих работ и широко рекомендуется. Взгляды Болла имеют большое влияние на нашу разработку этой темы. Мы также воспользовались диссертацией Линга (1971), в которой приведен список трудов из 140 названий. Обзоры Большева (1961) и Дорофеюка (1971) дают обширную биб-. лиографию советской литературы по разбиению на группы.
Сокаль и Сниф (1963) и Болл (1965) приводят много используемых мер подобия и функций критериев. Стивене (1968) осветил вопросы масштабов измерения, критериев инвариантности и необходимых статистических операций, а Ватанабе (1969) разработал фундаментальные философские проблемы, касающиеся группировки. Критика группировки Флешом и Зубином (1969) указывает на неприятные последствия небрежности в этих вопросах.
Джонс (1968) приписывает Торндайку (1953) первенство в использовании критерия по сумме квадратов ошибок, который часто появляется в литературе. Инвариантные критерии, о которых мы говорили, были выведены Фридманом и Рубином (1967), указавшими, что эти критерии связаны со следовым критерием Хотеллинга и F-соотношением в классической статистике. Фукунага и Кунц (1970) показали, что эти критерии дают одинаковые оптимальные разделения в случае двух групп. Из критериев, которых мы не упоминали, критерий «сцепления» Ватанабе (1969, гл. 8) представляет особый интерес, так как он учитывает не только меру подобия между парами.
В тексте мы привели основные этапы ряда стандартных программ оптимизации и группировки. Эти описания были намеренно упрощены, так как даже более строгие и полные описания, имеющиеся в литературе, не всегда упоминают о разрешении неоднозначностей или об исключении случайных «всплесков». Алгоритм Изоданные Болла и Холла (1967) отличается от нашего упрощенного описания в основном расщеплением групп, имеющих слишком большую изменчивость внутри группы, и слиянием групп, которые имеют слишком малую изменчивость между группами. Наше описание элементарной процедуры минимальных квадратичных ошибок получено на основе неопубликованной программы для ЭВМ, написанной Р. Синглтоном и У. Каутцом в Станфордском исследовательском институте в 1965 г. Эта процедура тесно связана с адаптивной последовательной процедурой Себестьяна (1962) и так называемой процедурой k-средних, свойства сходимости которой изучались Маккуином (1967). Интересные применения этой процедуры к распознаванию символов описаны Эндрюсом, Атрубином и Ху (1968) и Кейзи и Надь (1968).
Сокаль и Сниф (1963) приводят список ранних работ по иерархическому группированию, и Вишарт (1969) дает обширную библиографию источников по процедурам единственной связи, ближайшего соседа, полных связей, дальнего соседа, минимальной квадратичной ошибки и других. Ланс и Вильяме (1967) показывают, как можно получить большинство из этих процедур путем уточнения различными способами общей функции расстояния; кроме этого, они дают библиографию основных работ по делимым иерархическим группировкам. Связь между процедурами единственной связи и минимальным покрывающим деревом была показана Говером и Россом (1969), которые рекомендовали простой, эффективный алгоритм для нахождения минимального покрывающего дерева, предложенного Примом (1957). Эквивалентность между иерархической группировкой и функцией расстояния, удовлетворяющей ультраметрическому неравенству, показана Джонсоном (1967).
Большинство статей о группировках явно или неявно принимает критерий минимальной дисперсии. Вишарт (1969) указал на серьезные ограничения, присущие этому подходу, и в качестве альтернативы предложил процедуру, напоминающую оценку методом kn ближайших соседей моды плотности смеси. Методы минимальной дисперсии подвергались критике также со стороны Лина (1971) и Цаня (1971), причем оба они предлагали для группировки использовать теорию графов. Работа Цаня, хотя и предназначенная для данных любой размерности, была мотивирована желанием найти математическую процедуру, которая группирует множество данных в двух измерениях наиболее естественно для глаза. (Хэрэлик и Келли (1969) и Хэрэлик и Динштейн (1971) также рассматривают операции обработки изображений как процедуры группировок. Эта точка зрения применима ко многим процедурам, описанным в части II этой книги.)
Большинство ранних работ по методам теории графов было сделано для целей информационного поиска. Августсон и Минкер (1970) считают, что впервые теорию графов к группировке применил Куне (1959). Они же дают экспериментальное сравнение некоторых методов теории графов, предназначенных для целей информационного поиска, и обширную библиографию работ в этой области. Интересно, что среди статей с ориентацией на теорию графов мы находим три, рассматривающие статистические тесты для оценки значимости групп,— это статьи Боннера (1964), Хартигана (1967) и Лина (1971). Холл, Теппинг и Болл (1971) вычислили, как сумма квадратов ошибок изменяется в зависимости от размерности данных и предполагаемого числа групп для однородных данных, и предложили эти распределения в качестве полезного стандарта для сравнения. Вольф (1970) предлагает тест для оценки значимости групп, основанный на предполагаемом распределении хи-квадрат для логарифмической функции правдоподобия.
Грин и Кармон (1970), чья ценная монография о многомерном масштабировании содержит обширную библиографию, прослеживают происхождение многомерного масштабирования до статьи Ри-чардсона (1938). Недавно возникший интерес к этой теме был стимулирован двумя разработками — неметрическим многомерным масштабированием и применением графических устройств ЭВМ. Неметрический подход, разработанный Шепардом (1962) и развитый Крускалом (1964а), хорошо подходит для многих задач психологии и социологии. Вычислительные аспекты минимизации критерия Jтоп при ограничениях на монотонность детально описаны Крускалом (19646). Колверт (1968) использует модификацию критерия Ше-парда для обеспечения двумерного отображения на ЭВМ многомерных данных. Более простой для вычислений критерий Jef был предложен и использован Саммоном (1969) для отображения данных при диалоговом режиме анализа.
Интерес к человеко-машинным системам возник частично из-за трудностей определения функций критериев и процедур группировок, которые приводят к желаемым результатам.
Матсон и Дамман (1965) одни из первых предложили человеко-машинное решение этой задачи. Широкие возможности диалоговых систем хорошо описаны Боллом и Холлом (1970) в статье о системе PROMENADE. Другие хорошо известные системы — ВС TRY (Трайон и Бейли, 1966, 1970), SARF (Стэнли, Лендэрис и Найноу, 1967), INTERSPACE (Патрик, 1969) и OLPARS (Саммон, 1970).
Ни автоматические, ни человеко-машинные системы для распознавания образов не могут избежать проблем, связанных с большой размерностью данных. Были предложены различные процедуры уменьшения размерности путем либо отбора наилучшего подмножества имеющихся признаков, либо получения комбинаций признаков (обычно линейных). Для избежания серьезных вычислительных проблем большинство из этих процедур использует некоторый критерий, отличный от критерия вероятности ошибки при выборе. Например, Миллер (1962) использовал критерий tr 5^5д, Льюис (1962) — критерий энтропии, а Мерилл и Грин (1963) использовали критерий дивергенции. В некоторых случаях можно ограничить вероятность ошибки более легко вычисляемыми функциями, но окончательной проверкой все! да является реальное функционирование. В тексте мы ограничились простой процедурой Кинга (1967), выбрав ее прежде всего из-за ее близкой связи с группировкой. Отличное представление математических методов уменьшения размерности дано Мейзелом (1972).
СПИСОК ЛИТЕРАТУРЫ
Августсон, Минкер (Augustson J. G., Minker J.)
An analysis of some graph theoretical cluster techniques, /. ACM, 17, 571—588
(October 1970).
Агреула (Agrawala А. К.)
Learning with a probabilistic teacher, IEEE Trans. Inform. Theory, IT-16, 373—379 (July 1970).
Болл (Ball G. H.)
Data analysis in the social sciences: what about the details?, Proc. FJCC, pp.533—
560 (Spartan Books, Washington, D. C, 1965). Болл, Холл (Ball G. H., Hall D. J).
A clustering technique for summarizing multivariatc data. Behavioral Science, 12.
153—155 (March 1967).
Болл, Холл (Ball G. H., Hall D. J.)
Some implications of interactive graphic computer systems for data analysis and
statistics, Technometric, 12, 17—31 (Ferbuary 1970).
Большев Л. H.
Уточнение неравенства Крамера — Рао, Теор. вер. ч ее применение, 6,
№ 3, 319—326 (1961).
Боннер (Bonner R. E.)
On some clustering techniques, IBM Journal, 8, 22—32 (January 1964).
Ватанабе (Watanabe M. S.)
Knowing and Guessing (John Wiley, New York, 1969).
Вишарт (Wishart D.)
Mode analysis: a generalization of nearest neighbor which reduces chaining effects,
in Numerical Taxonomv, pp. 282—308, A. J. Cole, ed. (Academic Press, London
and New York, 1969).
Вольф (Wolfe J. H.)
Pattern clustering bv multivariate inixtu -lalvsis, Miillivariate Behavioral
Research, 5, 329—350 (July 1970).
Говер и Росс (Gower J. С., Ross G. J. S.)
Minimum spanning trees and single linkage cluster analysis, Appl. Statistics
18, № 1, 54—64 (1969).
Грин, Кармон (Green P. E., Carmone F. J.)
Multidimensional Scaling and Related Techniques in Marketing Analysis (Allyi
and Bacon, Boston, Mass., 1970).
Дей (Day N. E.)
Estimating the components of a mixture of normal distributions, Biometrika,
56, 463—474 (December 1969).
Дёч (Doetsch G.)
Zerlegung einer Funktion in Gausche Fehlerkurven und zeitliche Zuruckverfol-
gung eines Temperaturzustandes, Mathematische Zeiischrift, 41, 283—318
(1936). Джонс (Jones К. L.)
Problems of grouping individuals and the method of modality, Behavioral Science, 13, 496—511 (November 1968).
Джонсон (Johnson S. С.)
Hierarchical clustering schemes, Psychometrika, 32, 241—254 (September 1967). Дорофеюк А. А.
Алгоритмы автоматической классификации, Автоматика и телемеханика,
32, 1928—1958 (Декабрь, 1971).
Дэйли (Daly R. F.)
The adaptive binary-detection problem on the real line, Technical Report 2003—
3, Stanford University, Stanford, Calif. (February 1962).
Кейзи, Надь (Casey R. G., Nagy G.)
An autonomous reading machine, IEEE Trans. Сотр., С-17, 492—503 (May
1968).
Кинг (King В. F.)
Stepwise clustering procedures, J. American Statistical Assn., 62, 86—101
(March 1967).
Ковер (Cover Т. М.)
Learning in pattern recognition, in Methodologies of Pattern Recognition,
pp. 111—132, S. Watanabe, ed. (Academic Press, New York, 1969).
Колверт (Calvert Т. W.)
Projections of multidimensional data for use in man computer graphics, Proc.
FJCC, pp. 227—231 (Thompson Book Co., Washington, D. C., 1968). ,
Крускал (Kruskal J. B.)
Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis, Psychometrika, 29, 1—27 (March 1964a).
Крускал (Kruskal J. B.)
Nonmetric multidimensional scaling: a numerical method, Psychometriku,
29, 115—129 (June 1964b).
Кунc (Kuhns J. L.)
Mathematical analysis of correlation clusters, in Word correlation and automaticindexing, Progress Report №2, С 82—OU1, Ramo-Wooldridge Corporation, Canoga Park, Calif. (December 1959).
Купер Д., Купер П. (Cooper D. В., Cooper P. W.)
Nonsupervised adaptive signal detection and pattern recognition, Information and Control, 7, 416—444 (September 1964).
Лин (Ling R. F.)
Cluster Analysis, Technical Report № 18, Department of Statistics, Yale University, New Haven, Conn. (January 1971).
Льюис (Lewis P. M.)
The characteristic selection problem in recognition system?, /RE Trans. Info. Theory, IT-8, 171—178 (February 1962).
Маккуин (MacQueen J.)
Some methods for classification and analysis of multivariate observations, in Proc. Fifth Berkeley Symposium on Math. Stat. and Prob., I, 281—297, L. M. LeCam and J. Neyman, eds. (University of California Press, Berkeley and Los Angeles, Calif., 1967).
Матсон, Даммон (Mattson R. L., Dammann J. E.)
A technique for detecting and coding subclasses in pattern recognition problems,
IBM Journal, 9, 294—302 (July 1965).
Меджисси (Medgyessy P.)
Decomposition of Superpositions of Distribution Functions (Plenum Press, New
York, 1961).
Мейзел (Meisel W. S.)
Computer-Oriented Approaches to Pattern Recognition (Academic Press, New
York and London, 1972).
Мерилл, Грин (Marill Т., Green D. M.)
On the effectiveness of receptors in recognition systems, IEEE Trans. Info.
Theory, IT-9, 11—17 (January 1963).
Миллер (Miller R. G.)
Statistical prediction by discriminant analysis, Meteorological Monographs, 4,
25 (October 1962).
Патрик (Patrick E. A.)
(Interspace) Interactive system for pattern analysis, classification, and enhancement, paper presented at the Computers and Communications Conference,
Rome, N. Y. (September 1969).
Патрик, Костелло, Мондс (Patrick E. A., Costello J. P., Monds F. C.)
Decision directed estimation of a two class decision boundary, IEEE Trans.
Сотр., С-19, 197—205 (March 1970).
Патрик, Хенкок (Patrick E. A., Hancock J. C.)
Nonsupervised sequential classification and recognition of patterns, IEEE
Trans. Info. Theory, IT-12, 362—372 (July 1966).
Пирсон (Pearson К.)
Contributions to the mathematical theory of evolution. Philosophical Transactions of the Roval Society of London, 185, 71—110 (1894).
Прим (Prim R. C.) "
Shortest connection networks and some generalizations. Bell System Technical
Journal, 36, 1389—1401 (November 1957).
Ричардсон (Richardson M. W.)
Multidimensional psychophysics, Psychological Bulletin, 35, 659—660 (1938).
Саммон (Sammon J. W., Jr.)
A nonlinear mapping for data structure analysis, JEEE Trans. Сотр., C-18,
401—409 (May 1969).
Саммон (Sanimon J. W., Jr.)
Interactive pattern analysis and classification, IEEE Trans. Сотр., С-19, 594—
616 (July 1970). Себестьян (Sebestven G. S.)
Pattern recognition by an adaptive process of sample set construction, IRE Trans.
Info. Theory, IT-8, S82—S91 (September 1962).
Сокаль, Сниф (Sokal R. R., Sneath P. H. A.)
Principles of Numerical Taxonomy (W. H. Freeman, San Francisco, Calif., 1963).
Спреджинс (Spragins J.)
Learning without a teacher, IEEE Trails. Info. Theory, IT-12, 223—240 (April 1966).
Стейнат (Stanat D. F.)
Unsupervised learning of mixtures of probability functions, in Pattern Recognition, pp. 357—389, L. Kanal, ed. (Thompson "Book Co., Washington, D. C., 1968).
Стивенc (Stevens S. S.)
Measurement, statistics, and the schemapiric view. Science, 161, 849—856 (30 August 1968).
Стэнли, Лендэрис, Найноу (Stanley G. L., Lendaris G. G., Nienow W. C.)
Pattern Recognition Program, Technical Report 567—16, AC Electronics Defense Research Laboratories, Santa Barbara, Calif. (1967).
Торндайк (Thorndike R. L.)
Who belongs in the family? Psychometrika, 18, 267—276 (1953).
Трайон (Tryon R. C.)
Cluster Analysis (Edwards Brothers, Ann Arbor, Mich., 1939).
Трайон, Бейли (Tryon R. C., Bailey D. E.)
The ВС TRY computer system of cluster and factor analysis, Multivariafe Behavioral Research, 1, 95—111 (January 1966).
Трайон, Бейли (Tryon R. С., Bailey D. E.)
Cluster Analysis (McGraw-Hill, New York, 1970).
Тэйчер (Teicher H.)
Identifiability of mixtures, Ann. Math. Stat., 32, 244—248 (March 1961).
Тэйчер (Teicher H.)
Identifiability of finite mixtures, Ann. Math. Stat., 34, 1265—1269 (December 1963).
Флеш, Зубин (Fleiss J. L., Zubin J.)
On the methods and theory of clustering, Multivariafe Behavioral Research, 4, 235—250 (April 1969).
Фрелик (Fralick S. C.)
Learning to recognize patterns without a teacher, IEEE Trans. Info. Theory, IT-13, 57—64 (January 1967).
Фридман, Рубин (Friedman H. P., Rubin J.)
On some invariant criteria for grouping data, J. American Statistical Assn., 62, 1159—1178 (December 1967).
Фукунага, Кунц (Fukunaga К., Koontz W. L. G.)
A criterion and an algorithm for grouping data, IEEE Trans. Сотр., С-19, 917— 923 (October 1970),
Хартиган (Hartigan J. A.)
Representation of similarity matrices by trees, J. American Statistical Assn., 62, 1140—1158 (December 1967).
Хесселблад (Hasselblad V.)
Estimation of parameters for a mixture of normal distributions, Technometrics, 8, 431—444 (August 1966).
Хилборн, Лейниотис (Hillborn С. G., Jr., Lainiotis D. G.)
Optimal unsupervised learning multicategory dependent hypotheses pattern recognition, IEEE Trans. Info. Theory, IT-14, 468—470 (May 1968).
Холл, Теппинг, Болл (Hall D. J., Tepping В., Ball G. H.)
Theoretical and experimental clustering characteristics for multivariate random and structured data, in Applications of cluster analysis to Bureau of the Census data. Final Report, Contract Cco-9312, SRI Project 7600, Stanford Research Institute, Menio Park, Calif. (1970).
Хэрэлик, Динштейн (Haralick R. M., Dinstein I.)
An iterative clustering procedure, IEEE Transactions on Sys., Man, and Cyb., SMC-1, 275—289 (July 1971).
Хэрэлик, Келли (Haralick R. M., Kelly G. L.)
Pattern recognition with measurement space and spatial clustering for multiple images, Proc. IEEE, 57, 654—665 (April 1969).
Цань (Zahn С. Т.)
Graph-theoretical methods for detecting and describing gestalt clusters, IEEE Trans. Сотр., С-20, 68—86 (January 1971).
Шепард (Shepard R. N.)
The analysis oi proximities: multidimensional scaling with an unknown distance function, Psychometrika, 27, 125—139, 219—246 (1962).
Эндрюс, Атрубин, Ху (Andrews D. R., Atrubin A. J., Hu K. C.)
The IBM 1975 Optical Page Reader. Part 3: Recognition logic development, IBM Journal, 12, 334—371 (September 1968).
Якович (Yakowitz S. J.)
Unsupervised learning and the identification of finite mixtures, IEEE Trans. Info. Theory, IT-16, 330—338 (May 1970).
Якович, Спреджинс (Yakowitz S. J., Spragins J. D.)
On the identifiability of finite mixtures, Ann. Math. Stat., 39, 209—214 (February 1968).
Янг, Коралуппи (Young Т. Y., Coraluppi G.)
Stochastic estimation of a mixture of normal density functions using an information criterion, IEEE Trans. Info. Theory, IT-16, 258—263 (May 1970).
Задачи
1![]() .
Предположим, что у может принимать
значения 0,1,
..., т
и что P(x|)
смесь с
биномиальных распределений
.
Предположим, что у может принимать
значения 0,1,
..., т
и что P(x|)
смесь с
биномиальных распределений
Предполагая, что априорные вероятности известны, объясните, почему эта смесь неидентифицируема, если m<c. Как изменится ответ, если априорные вероятности тоже неизвестны?
2. Пусть х — двоичный вектор и Р(х|) — смесь из с многомерных распределений Бернулли:
![]()
![]() где
где
а![]() )
Покажите, что
)
Покажите, что
б![]() )
Используя общее уравнение оценки по
максимуму правдоподобия, покажите, что
оценка по максимуму правдоподобия ,-
дляi;
должна удовлетворять:
)
Используя общее уравнение оценки по
максимуму правдоподобия, покажите, что
оценка по максимуму правдоподобия ,-
дляi;
должна удовлетворять:
3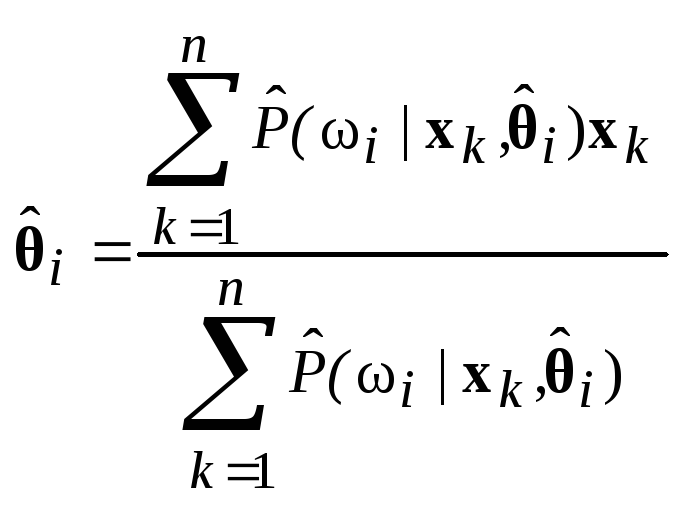 .
Рассмотрим одномерную нормальную смесь
.
Рассмотрим одномерную нормальную смесь
![]()
Напишите
программу для ЭВМ, которая использует
общее уравнение максимального
правдоподобия из п.
6.4.3 для
итерационной оценки неизвестных
средних, дисперсий и априорных
вероятностей. Используя эту программу,
найдите оценки по максимуму правдоподобия
этих параметров для данных из табл.
6.1. (Ответ:
![]() 1=—2,404,
1=—2,404,
![]() 2=
1,491,
2=
1,491,
![]() 1=0,577,
1=0,577,
![]() 2=-1,338,
2=-1,338,
![]() (1)=0,268,
(1)=0,268,
![]() (2)=0,732.)
(2)=0,732.)
4 .
Пусть р(х|)
— нормальная
плотность смеси из с компонент с р(х|i
)
~ N(ii2I).
Используя результаты разд.
6.3, покажите,
что оценка по максимуму правдоподобия
для i2
должна удовлетворять соотношению
.
Пусть р(х|)
— нормальная
плотность смеси из с компонент с р(х|i
)
~ N(ii2I).
Используя результаты разд.
6.3, покажите,
что оценка по максимуму правдоподобия
для i2
должна удовлетворять соотношению
где
![]() i
P(i
|xk
i
P(i
|xk
![]() i)
заданы уравнениями
(15) и
(17)
соответственно.
i)
заданы уравнениями
(15) и
(17)
соответственно.
5. Вывод уравнений для оценки по максимуму правдоподобия параметров плотности смеси был сделан при предположении, что параметры в каждой плотности компонент функционально независимы. Вместо этого предположим, что
г![]()
![]() де
к
— параметр,
который появляется в некоторых плотностях
компонент. Пусть
/ —
логарифмическая функция правдоподобия
для п
выборок. Покажите, что
де
к
— параметр,
который появляется в некоторых плотностях
компонент. Пусть
/ —
логарифмическая функция правдоподобия
для п
выборок. Покажите, что
г![]() де
де
6. Пусть р(х|i i) ~ N(i), где —общая матрица ковариаций для с плотностей компонент. Пусть рq — pq-й элемент , рq — pq-й элемент -1, xp(k) — p элемент xk и p(i) — p - й элемент i.
а![]() )
Покажите, что
)
Покажите, что
б![]() )
Используя этот результат и результат
задачи
5, покажите,
что оценка по максимуму правдоподобия
для
должна удовлетворять
)
Используя этот результат и результат
задачи
5, покажите,
что оценка по максимуму правдоподобия
для
должна удовлетворять
где
![]() i
и
i
и
![]() i,-
— оценки
по максимуму правдоподобия, данные
уравнениями
(14) и
(15) в тексте.
i,-
— оценки
по максимуму правдоподобия, данные
уравнениями
(14) и
(15) в тексте.
1Если данные в табл. 6.1разбить на классы, получим результирующие средние выборокт1=-2,176ит2= 1,684.Таким образом, оценки по максимуму правдоподобия для обучения без учителя близки к оценкам по максимуму правдоподобия для обучения с учителем.
2В этой главе мы назовем и опишем различные итерационные процедуры как программы для ЭВМ. Все эти процедуры действительно были запрограммированы, часто с различными дополнительными элементами, такими, как разрешение неоднозначности, избежание состояний «ловушки» и обеспечения особых условий окончания работы. Таким образом, мы включили слово «базовые» в название, чтобы подчеркнуть, что наш интерес ограничивается только объяснением основных понятий.
3Процедура «Базовые Изоданные», описанная в п. 6.4.4,в сущности является процедурой принятия решения этого типа.
4Эти фундаментальные соображения относятся не только к группировкам. Они появляются, например, когда для неизвестной плотности вероятности выбрана параметрическая форма. В задачах группировки они проявляются более четко.
5Эти два множества данных хорошо известны по разным причинам. Рис. 6.11 показывает два из четырех измерений, сделанных Е. Андерсоном на 150выборках трех видов ириса. Эти данные были использованы Р. А. Фишером в его классическом труде о дискриминантном анализе (Фишер, 1936)и с тех пор стали излюбленным примером для иллюстрации процедур группировки. Рис. 6.12хорошо известен в астрономии как диаграмма Герцшпрунга —Рассела, которая привела к делению звезд на такие классы, как гиганты, сверхгиганты, звезды главной последовательности и белые карлики. Она была использована Форджи и затем Вишартом для иллюстрации ограничений в простых процедурах группировки.
6Это следует из того факта, что рангSiне может превышать ni-1, и, таким образом, рангSWне может превышать ∑ (ni-1)= n-c. Конечно, если ограничены только подпространством меньшей размерности, возможно получить в качествеSW вырожденную матрицу, даже еслиn-c≥d. В таких случаях нужно использовать какую-либо процедуру уменьшения размерности, прежде чем применять критерий на основе определителя (разд. 6.14.).
7Другой инвариантный критерии
![]()
Однако, поскольку его значение обычно равно нулю, он мало полезен.
8Читателю, которому нравятся комбинаторные задачи, доставит удовольствие показать, что существует точно
![]()
разделений пэлементов наснепустых подмножеств (Феллер В., Введение в теорию вероятностей и ее приложения, М., «Мир», 1964).Еслип>>с,последний член наиболее существен.
9В литературе результирующую процедуру часто называют алгоритмомближайшего соседаили алгоритмомминимума.Если алгоритм заканчивается, когда расстояние между ближайшими группами превышает произвольный порог, его называют алгоритмомединичной связи.
10Хотя мы не будем широко использовать теорию графов, однако предполагается, что читатель в общих чертах знаком с этой теорией. Ясная, четкая трактовка дана в книге О. Оре, Графы и их применение, М., «Мир», 1965.
11В литературе результирующую процедуру часто называют алгоритмоммаксимумаилидальнего соседа.Если он заканчивается, когда расстояние между двумя ближайшими группами превышает произвольный порог, его называют алгоритмомполных связей.
12 Вторую частную производную также легко вычислить, так что можно использовать алгоритм Ньютона. Заметим, что при уi,=уj, единичный вектор от уi, до уj не определен. Если возникает такая ситуация, то (уi,-уj,) dij может быть заменен любым единичным вектором.
13Этот пример взят из статьи Саммона (J.W.Sammon.Jr.) ьЛ nonlinear mapping for data structure analysis», IEEE Trails. Сотр.,С-18, 401— 409 (May1.969).
14Целью анализа главных компонент (известного в литературе по теории связи как разложение Кархунена—Лоэва) является нахождение представления в пространстве меньшей размерности, учитывающего дисперсии признаков. Целью факторного анализа является нахождение представления в пространстве меньшей размерности, учитывающего корреляции между признаками. Для более глубокого ознакомления см. книги Kendall M. G., Stuart A. «The advanced theory of statistics», v. 3, ch. 43 (Hafner, New York, 1966) или Harman H. H. «Modern factor analysis» (University of Chicago Press, Chicago and London, 2nd ed.,