

Одномерные распределения вероятностей
Распределение вероятностей действительной случайной величины задается ее функцией распределения
![]() .
.
Числовые характеристики
одномерных распределений вероятностей
Математическое ожидание (среднее значение, центр распределения) случайной величины вычисляется через интеграл Стильтьеса
![]() .
.
Пусть имеется
конечная выборка
![]() .
Выборочное среднее
.
Выборочное среднее
![]()
является
несмещенной состоятельной и эффективной
оценкой математического ожидания
![]() .
.
Дисперсия
![]() случайной величины
определяется по формуле
случайной величины
определяется по формуле
![]() .
.
Выборочная дисперсия
![]()
является
смещенной, состоятельной и эффективной
оценкой дисперсии
.
Величина
![]() является несмещенной, состоятельной и
эффективной оценкой дисперсии.
является несмещенной, состоятельной и
эффективной оценкой дисперсии.
Многомерные распределения вероятностей
Если случайное
событие описывается упорядоченным
набором действительных чисел
![]() ,
то этот набор представляет значение
,
то этот набор представляет значение
![]() -мерной
случайной величины
-мерной
случайной величины
![]() .
.
Функция распределения -мерной случайной величины определяется так
![]() .
.
Обозначим через
![]() - конечную выборку значений
-мерной
случайной величины
.
Здесь
- конечную выборку значений
-мерной
случайной величины
.
Здесь
![]() .
.
Числовые характеристики
многомерных распределений вероятностей
Математическое
ожидание (среднее значение, центр
распределения)
![]() -й
компоненты
-й
компоненты
![]() случайной величины
вычисляется через
-мерный
интеграл Стильтьеса
случайной величины
вычисляется через
-мерный
интеграл Стильтьеса
![]() .
.
Выборочное среднее
![]()
является
несмещенной состоятельной и эффективной
оценкой математического ожидания
![]() .
.
Ковариация
![]() -й
и
-й
компонент вычисляется по формуле
-й
и
-й
компонент вычисляется по формуле
![]() ,
,
дисперсия
-й
компоненты
![]() ,
корреляция
-й
и
-й
компонент -
,
корреляция
-й
и
-й
компонент -
![]() .
.
Выборочными оценками являются:
выборочная ковариация -й и -й компонент -
![]() ,
,
выборочная дисперсия -й компоненты -
![]() ,
,
Выборочная корреляция -й и -й компонент -
![]() .
.
Учебное задание 1. Построение однофакторной линейной эконометрической модели
![]() (1.1)
(1.1)
по
методу наименьших квадратов, вычисление
коэффициента детерминации модели
![]() и построение доверительного интервала
для коэффициента
и построение доверительного интервала
для коэффициента
![]() построенной модели.
построенной модели.
Зависимость (1.1) строится на основе следующей логической модели^
Зависимая переменная |
Фактор |
Y |
X |
Исходные данные
t – номер наблюдения |
Массив Х (Х – объясняющий фактор) |
Массив У (У – зависимая переменная) |
(1) |
1 |
2 |
(2) |
2 |
5 |
(3) |
3 |
5 |
(4) |
4 |
6 |
(5) |
3 |
4 |
(6) |
6 |
7 |
(7) |
2 |
3 |
(8) |
7 |
7 |
(9) |
1 |
3 |
Задание выполняется с использованием стандартных функций EXCEL.
Процесс выполнения задания разделен на 10 шагов.
Шаг 1. Вычисление средних значений.
Для вычисления средних используется стандартная функция СРЗНАЧ(Арг), которая размещена в разделе: Статистические. В качестве аргумента используется адрес массива данных, среднее значение которых надо подсчитать. Адрес массива задается по правилам EXCEL. Например, если массив х размещен в ячейках начиная с адреса А1 и заканчивая адресом А9, то параметр Арг в функции СРЗНАЧ имеет вид: Арг=А1:А9. Выберите ячейку, в которой будете размещать среднее значение, и разместите в ней следующий текст: =СРЗНАЧ(Арг) . После нажатия клавиши ENTER в этой ячейке должно появиться число 3,222222222.
|
|
|
Средние значения |
3,222222222 |
4,66666667 |
Шаг
2. Вычисление ковариационной матрицы
![]() .
.
Для вычисления каждого элемента ковариационной матрицы используется стандартная функция КОВАР(Арг1; Арг2), которая размещена в разделе: Статистические. У этой функции два аргумента, разделенные символом ; (точка с запятой). Арг1 и Арг2 – это адреса массивов, ковариацию между которыми Вы хотите вычислить. Если в некоторой ячейке Вы размещаете текст: = КОВАР(Арг1; Арг2), то после нажатия клавиши ENTER в этой ячейке должно появиться число, равное ковариации массивов с адресами Арг1 и Арг2.
Элементы ковариационной матрицы должны размещаться в виде квадратной таблицы, в ячейках которой стоят числа:
=КОВАР(Х;Х) |
=КОВАР(Х;У) |
=КОВАР(У;Х) |
=КОВАР(У;У) |
Здесь через Х обозначен адрес массива Х, через У – адрес массива У.
В результате выполнения Шага 2 должна появиться таблица:
3,950617284 |
3,07407407 |
3,074074074 |
2,88888889 |
Шаг
3. Вычисление обратной матрицы
![]() .
.
Для вычисления используется стандартная функция МОБР(Арг), размещенная в разделе: Математические. Здесь аргументом является адрес ковариационной матрицы. Адрес ковариационной матрицы задается по следующему правилу. Пишется адрес верхней левой ячейки матрицы, ставится двоеточие и затем – адрес нижней правой ячейки матрицы. Например, если ковариационная матрица размещена в ячейках с адресами:
А5 |
В5 |
А6 |
В6 |
то параметр Арг равен А5:В6.
Обратная матрица размешается на площадке такого же размера, что и ковариационная матрица. Элементы обратной матрицы имеют следующие обозначения:
|
|
|
|
Обратная матрица вычисляется с помощью блочной команды по следующей методике.
Засвечивается площадка, на которой будет размещена обратная матрица и которая совпадает по размерам с ковариационной матрицей.
Вызывается функция МОБР.
В качестве параметра Арг указывается адрес ковариационной матрицы.
Одновременным нажатием трех клавиш: CTRL+SHIFT+ENTER дается команда на одновременное вычисление всех элементов обратной матрицы .
В результате выполнения Шага 3 в засвеченной площадке должна появиться таблица:
1,471698113 |
-1,5660377 |
-1,566037736 |
2,01257862 |
Шаг
4. Вычисление коэффициента
![]() модели.
модели.
Предположим, что обратная матрица размещена в ячейках с адресами:
А15 |
В15 |
А16 |
В16 |
Если в выбранной ячейке разместить формулу: =-А16/В16 , то после нажатия клавиши ENTER в этой ячейке должно появиться число: 0,778125, равное оценке коэффициента а построенной модели.
Шаг 5. Вычисление значений оцененного ряда.
![]() -й
элемент массива
-й
элемент массива
![]() вычисляется по формуле
,
которая программируется в каждой ячейке
массива
по правилам табличного процессора
EXCEL.
В результате выполнения шага 5 в ячейках
размещения массива
должны появиться приведенные ниже числа
вычисляется по формуле
,
которая программируется в каждой ячейке
массива
по правилам табличного процессора
EXCEL.
В результате выполнения шага 5 в ячейках
размещения массива
должны появиться приведенные ниже числа
t |
Массив
|
Массив
|
Оценка |
|
|
1 |
2 |
2,9375 |
|
|
2 |
5 |
3,715625 |
|
|
3 |
5 |
4,49375 |
|
|
4 |
6 |
5,271875 |
|
|
3 |
4 |
4,49375 |
|
|
6 |
7 |
6,828125 |
|
|
2 |
3 |
3,715625 |
|
|
7 |
7 |
7,60625 |
|
|
1 |
3 |
2,9375 |
|
Шаг 6. Вычисление остатков построенной модели.
Остатки
модели
![]() вычисляются по формуле:
вычисляются по формуле:
![]() .
В результате программирования этой
формулы в каждой ячейке размещения
массива остатков должна появиться
таблица
.
В результате программирования этой
формулы в каждой ячейке размещения
массива остатков должна появиться
таблица
t |
Массив |
Массив |
Оценка |
Остатки |
|
1 |
2 |
2,9375 |
-0,9375 |
|
2 |
5 |
3,715625 |
1,284375 |
|
3 |
5 |
4,49375 |
0,50625 |
|
4 |
6 |
5,271875 |
0,728125 |
|
3 |
4 |
4,49375 |
-0,49375 |
|
6 |
7 |
6,828125 |
0,171875 |
|
2 |
3 |
3,715625 |
-0,715625 |
|
7 |
7 |
7,60625 |
-0,60625 |
|
1 |
3 |
2,9375 |
0,0625 |
Шаг
7. Вычисление коэффициента детерминации
 .
.
Вычисляем
дисперсию ряда
![]() с использованием стандартной функции
ДИСПР(Арг). Для этого в выбранную ячейку
размещаем текст =ДИСПР(Арг) , где
параметр Арг является адресом массива
.
После нажатия клавиши ENTER,
в этой ячейке должно появиться число
2,392013889. Затем в другой выбранной ячейке
вычисляем дисперсию ряда
с использованием стандартной функции
ДИСПР(Арг). Для этого в выбранную ячейку
размещаем текст =ДИСПР(Арг) , где
параметр Арг является адресом массива
.
После нажатия клавиши ENTER,
в этой ячейке должно появиться число
2,392013889. Затем в другой выбранной ячейке
вычисляем дисперсию ряда
![]() .
В ней также размещаем текст =ДИСПР(Арг)
, но только в этом случае параметр
Арг является адресом массива
.
После нажатия клавиши ENTER,
в этой ячейке должно появиться число
2,888888889. Затем в третьей выбранной ячейке
вычисляем коэффициент детерминации
путем деления числа 2,392013889 на число
2,888888889. После введения формулы деления
и нажатия клавиши ENTER,
в этой ячейке должно появиться число
0,828004808, которое и является коэффициентом
детерминации.
.
В ней также размещаем текст =ДИСПР(Арг)
, но только в этом случае параметр
Арг является адресом массива
.
После нажатия клавиши ENTER,
в этой ячейке должно появиться число
2,888888889. Затем в третьей выбранной ячейке
вычисляем коэффициент детерминации
путем деления числа 2,392013889 на число
2,888888889. После введения формулы деления
и нажатия клавиши ENTER,
в этой ячейке должно появиться число
0,828004808, которое и является коэффициентом
детерминации.
Шаг
8. Вычисление t-статистики
для коэффициента а
по формуле
 .(1.2)
.(1.2)
Отдельно вычисляем
![]() =1,98761598 =КОРЕНЬ(ДИСПР(Арг1))
=1,98761598 =КОРЕНЬ(ДИСПР(Арг1))
![]() =1,699673171 =КОРЕНЬ(ДИСПР(Арг2))
=1,699673171 =КОРЕНЬ(ДИСПР(Арг2))
![]() =2,645751311 =КОРЕНЬ(7)
=2,645751311 =КОРЕНЬ(7)
![]() =0,909947695 =КОРРЕЛ(Арг1;Арг2)
=0,909947695 =КОРРЕЛ(Арг1;Арг2)
![]() =0,414723031 =КОРЕНЬ(1-0,909947695^2)
=0,414723031 =КОРЕНЬ(1-0,909947695^2)
Окончательно получаем
![]() =5,805067788
=5,805067788
Шаг
9. Вычисляем границу критической области
![]()
Для этого в выбранной ячейке размещаем стандартную функцию
=СТЬЮДРАСПРОБР(Вероятность = 0,01 Степеней свободы – 7)
После нажатия клавиши ENTER, в этой ячейке получится число
3,499480954
Это и есть значение параметра .
Шаг
10. Построение доверительного интервала
![]() по формулам
по формулам
![]() ,
,
![]() .
.
В результате получаем
![]() =0,309046306,
=0,309046306,
![]() =1,247203694.
=1,247203694.
Вывод. Так как точка 0 не принадлежит интервалу , то по критерию Стьюдента на уровне значимости 0.01 зависимость ряда от ряда признается значимой и положительной.
Задание выполнено полностью.
Контрольные вопросы.
Как вычисляется ковариационная матрица: поэлементно или с помощью блочной команды?
Как вычисляется обратная матрица: поэлементно или с помощью блочной команды?
Как вычисляется оцененный ряд: поэлементно или с помощью блочной команды?
Учебное задание 2. Построение многофакторных эконометрических моделей.
Даны три ряда:
X |
Y |
Z |
1 |
2 |
7 |
2 |
5 |
6 |
3 |
5 |
4 |
4 |
6 |
5 |
3 |
4 |
6 |
6 |
3 |
6 |
2 |
3 |
9 |
7 |
7 |
1 |
1 |
9 |
4 |
По методу наименьших квадратов построить математические зависимости для каждой из трех логических моделей
|
Зависимая переменная |
Влияющие факторы |
Формула для вычисления оценки |
Логическая модель №1 |
X |
Y, Z |
|
Логическая модель №2 |
Y |
X, Z |
|
Логическая модель №3 |
Z |
X, Y |
|
Для модели с наибольшим коэффициентом детерминации построить графики зависимой переменной, оцененного ряда и остатков.
Задание выполняется с использованием стандартных функций EXCEL.
Процесс выполнения задания разделен на 8 шагов.
Шаг 1. Вычисление средних значений.
Для вычисления средних используется стандартная функция СРЗНАЧ(Арг). Этот шаг аналогичен шагу 1 в задании 1. В результате выполнения шага 1 должны появиться три числа:
|
|
|
|
Средние значения |
3,222222222 |
4,888888889 |
5,333333333 |
Шаг 2. Вычисление ковариационной матрицы .
Для вычисления, как и в задании 1, используется стандартная функция КОВАР(Арг1;Арг2).
При вычислении элементов ковариационной матрицы схему задания аргументов Арг1 и Арг2 в функции КОВАР определим таблицей 2.1.
Табл. 2.1.
X |
X |
X;Z |
Y;X |
Y;Y |
Y;Z |
Z;X |
Z;Y |
Z;Z |
 ;X
;X ;Y
;Y
Опишем методику определения порядка следования массивов в ковариационной матрице.
Стрелкой на таблице 2.1 указана главная диагональ матрицы. На главной диагонали стоят три элемента:
КОВАР(Х;Х) – первый элемент (обозначен для сокращения Х;Х);
КОВАР(Y;Y) – второй элемент;
КОВАР(Z;Z) – третий элемент.
В
соответствии с этим порядком, массив Х
считается первым в ковариационной
матрице
,
массив Y
– вторым, массив Z
– третьим. Порядок следования массивов
в ковариационной матрице обозначается
![]() ,
а сама ковариационная матрица -
,
а сама ковариационная матрица -
![]() .
.
В результате выполнения шага 2 должна появиться следующая ковариационная матрица:
3,950617284 |
0,358024691 |
-2,2962963 |
0,358024691 |
4,320987654 |
-3,18518519 |
-2,296296296 |
-3,18518519 |
4,444444444 |
Шаг 3. Вычисление обратной матрицы .
Для вычисления используется стандартная функция МОБР(Арг). Методика полностью повторяет методику третьего шага задания 1.
Обратная матрица размешается на площадке такого же размера, что и ковариационная матрица. Элементы обратной матрицы имеют следующие обозначения:
|
|
|
|
|
|
|
|
|
Обратная матрица вычисляется с помощью блочной команды по стандартной методике.
Засвечивается площадка, на которой будет размещена обратная матрица и которая совпадает по размерам с ковариационной матрицей.
Вызывается функция МОБР.
В качестве параметра Арг указывается адрес ковариационной матрицы.
Одновременным нажатием трех клавиш: CTRL+SHIFT+ENTER дается команда на одновременное вычисление всех элементов обратной матрицы .
В результате выполнения Шага 3 в засвеченной площадке должна появиться таблица:
0,512626785 |
0,323845995 |
0,496946802 |
0,323845995 |
0,695197682 |
0,665545436 |
0,496946802 |
0,665545436 |
0,958730077 |
Шаг
4. Вычисление коэффициентов
![]() математических моделей.
математических моделей.
Табл. 2.2.
|
Зависимая переменная |
Влияющие факторы |
Формулы для вычисления коэфф-тов |
Значения коэффициентов |
Логическая модель №1 |
X |
Y, Z |
|
-0,63174 -0,96941 |
Логическая модель №2 |
Y |
X, Z |
|
-0,46583 -0,95735 |
Логическая модель №3 |
Z |
X, Y |
|
-0,51834 -0,69419 |
Правило
№1. В соответствии со схемой построения
ковариационной матрицы
![]() ,
зависимой переменной первой логической
модели является первый ряд
,
зависимой переменной первой логической
модели является первый ряд
![]() (в порядке использования при вычислении
ковариационной матрицы), следовательно
коэффициенты
(в порядке использования при вычислении
ковариационной матрицы), следовательно
коэффициенты
![]() первой модели вычисляются по первой
строке обратной матрицы по формулам
,
.
первой модели вычисляются по первой
строке обратной матрицы по формулам
,
.
Правило
№2. В соответствии со схемой построения
ковариационной матрицы
,
зависимой переменной второй логической
модели является второй ряд
![]() (в порядке использования при вычислении
ковариационной матрицы), следовательно
коэффициенты
(в порядке использования при вычислении
ковариационной матрицы), следовательно
коэффициенты
![]() второй модели вычисляются по второй
строке обратной матрицы по формулам
,
второй модели вычисляются по второй
строке обратной матрицы по формулам
,
![]() .
.
Правило
№3. В соответствии со схемой построения
ковариационной матрицы
,
зависимой переменной третьей логической
модели является третий ряд
![]() (в порядке использования при вычислении
ковариационной матрицы), следовательно
коэффициенты
(в порядке использования при вычислении
ковариационной матрицы), следовательно
коэффициенты
![]() третьей модели вычисляются по третьей
строке обратной матрицы по формулам
,
.
третьей модели вычисляются по третьей
строке обратной матрицы по формулам
,
.
Шаг 5. Вычисление оценок по каждой из трех моделей.
Вычисление оцененного ряда выполняется программированием формулы вычисления оценки для вычисления каждого элемента этого ряда. В результате выполнения шага 5 должны появиться три оцененных ряда.
|
|
|
Оцененные ряды |
||
X |
У |
Z |
|
|
|
1 |
2 |
7 |
3,431557 |
4,328495 |
8,4906485 |
2 |
5 |
6 |
2,505754 |
4,820009 |
5,8897255 |
3 |
5 |
4 |
4,444579 |
6,26887 |
5,3713869 |
4 |
6 |
5 |
2,843428 |
4,84569 |
4,1588535 |
3 |
4 |
6 |
3,137492 |
4,354176 |
6,0655817 |
6 |
3 |
6 |
3,769231 |
2,956677 |
5,2047607 |
2 |
3 |
9 |
0,860993 |
1,947968 |
7,2781151 |
7 |
7 |
1 |
6,08934 |
7,277579 |
1,9096429 |
1 |
9 |
4 |
1,917626 |
7,200536 |
3,6312849 |
Шаг 6. Вычисление остатков.
В результате программирования формул вычисления остатков в каждой ячейке должны появиться три ряда остатков.
|
|
|
Оцененные ряды |
Остатки |
||||
X |
У |
Z |
по модели №1 |
по модели №2 |
по модели №3 |
|
|
|
1 |
2 |
7 |
3,431557 |
4,328495 |
8,4906485 |
-2,43156 |
-2,32849 |
-1,49065 |
2 |
5 |
6 |
2,505754 |
4,820009 |
5,8897255 |
-0,50575 |
0,179991 |
0,110274 |
3 |
5 |
4 |
4,444579 |
6,26887 |
5,3713869 |
-1,44458 |
-1,26887 |
-1,37139 |
4 |
6 |
5 |
2,843428 |
4,84569 |
4,1588535 |
1,156572 |
1,15431 |
0,841146 |
3 |
4 |
6 |
3,137492 |
4,354176 |
6,0655817 |
-0,13749 |
-0,35418 |
-0,06558 |
6 |
3 |
6 |
3,769231 |
2,956677 |
5,2047607 |
2,230769 |
0,043323 |
0,795239 |
2 |
3 |
9 |
0,860993 |
1,947968 |
7,2781151 |
1,139007 |
1,052032 |
1,721885 |
7 |
7 |
1 |
6,08934 |
7,277579 |
1,9096429 |
0,91066 |
-0,27758 |
-0,90964 |
1 |
9 |
4 |
1,917626 |
7,200536 |
3,6312849 |
-0,91763 |
1,799464 |
0,368715 |
Шаг 7. Вычисление коэффициентов детерминации.
|
Зависимая переменная |
Влияющие факторы |
Формулы для вычисления коэфф-тов детерминации |
Значения коэфф-тов детерминации |
Логическая модель №1 |
X |
Y, Z |
|
0,50622 |
Логическая модель №2 |
Y |
X, Z |
|
0,667104
|
Логическая модель №3 |
Z |
X, Y |
|
0,765315
|
Вывод. Наибольший коэффициент детерминации в модели №3.
Шаг 8. Строим графики исходного ряда зависимой переменной, оцененного ряда и остатков для модели №3.
В результате выполнения шага 8 должен появиться рисунок

Задание выполнено полностью.
Контрольные вопросы.
Напишите вычислительные схемы для вычисления следующих ковариационных матриц:
 ,
,
 ,
,
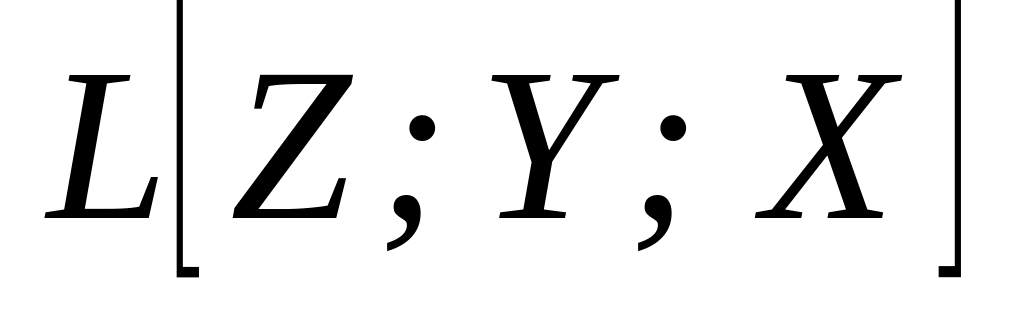 .
.Напишите формулы вычисления коэффициентов для первой логической модели по ковариационной матрице .
Учебное задание 3.
Построение доверительного интервала для коэффициента а множественной регрессии
![]() (3.1)
(3.1)
с использованием 5%-го критерия Стьюдента.
Даны четыре ряда:
X |
У |
Z |
w |
1 |
22 |
16 |
15 |
3 |
8 |
3 |
10 |
5 |
3 |
5 |
7 |
8 |
5 |
12 |
11 |
17 |
1 |
2 |
3 |
5 |
0 |
5 |
7 |
15 |
16 |
0 |
2 |
Выполнение
данного задания разделено на 10 шагов.
На шагах 1-4 вычисляются коэффициенты
![]() зависимости (3.1).
зависимости (3.1).
Предварительный анализ. Математическая модель (3.1) построена на основе следующей логической модели
Зависимая переменная |
Факторы |
W |
X, Y, Z |
Шаг 1. Вычисление средних.
В результате выполнения шага 1 должны появиться числа
|
|
|
|
|
Средние значения |
7,71428571 |
7,85714286 |
6,1428571 |
7,857143 |
Шаг
2. Построение ковариационной матрицы
![]() .
.
При
вычислении элементов ковариационной
матрицы схема выбора аргументов функции
КОВАР определена формулой
![]() и имеет следующий вид:
и имеет следующий вид:
XX |
XY |
XZ |
XW |
YX |
YY |
YZ |
YW |
ZX |
ZY |
ZZ |
ZW |
WX |
WY |
WZ |
WW |
В результате выполнения шага 2 должна появиться матрица
31,6326531 |
-9,4693878 |
-18,10204 |
-20,0408 |
-9,46938776 |
58,122449 |
16,44898 |
12,69388 |
-18,1020408 |
16,4489796 |
28,408163 |
20,02041 |
-20,0408163 |
12,6938776 |
20,020408 |
17,83673 |
Шаг 3. Вычисление обратной матрицы.
В результате выполнения шага 3 должна появиться матрица
0,17673119 |
-0,0115861 |
-0,126459 |
0,348756 |
-0,01158607 |
0,02147526 |
0,00061 |
-0,02899 |
-0,1264586 |
0,00060998 |
0,2617764 |
-0,43634 |
0,34875566 |
-0,0289857 |
-0,436344 |
0,958307 |
в которой элементы будем обозначать следующим образом
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Шаг 4. Вычисление коэффициентов зависимости (3.1).
Правило
№4. Поскольку в заданной логической
модели зависимой переменной является
четвертый столбец (![]() )
, то коэффициенты
будут вычисляться по четвертой строке
обратной матрицы по формулам:
)
, то коэффициенты
будут вычисляться по четвертой строке
обратной матрицы по формулам:
![]() ,
,
![]() ,
,
![]() .
.
Шаг
5. Вычисление коэффициентов
![]() первой вспомогательной зависимости
первой вспомогательной зависимости
![]() ,
которая строится по следующей логической
модели
,
которая строится по следующей логической
модели
Зависимая переменная |
Факторы |
Х |
Y, Z |
Строится
ковариационная матрица
![]() ,
при вычислении элементов которой
аргументы функции КОВАР задаются по
следующей схеме
,
при вычислении элементов которой
аргументы функции КОВАР задаются по
следующей схеме
Y;Y |
Y;Z |
Y;X |
Z;Y |
Z;Z |
Z;X |
X;Y |
X;Z |
X;X |
В результате получается матрица
58,1224 |
16,4489796 |
-9,4693878 |
16,449 |
28,4081633 |
-18,102041 |
-9,4694 |
-18,1020408 |
31,6326531 |
По ней вычисляется обратная матрица
0,0206 |
-0,01258802 |
-0,0010373 |
-0,0126 |
0,06309705 |
0,03233951 |
-0,001 |
0,03233951 |
0,04980892 |
со стандартным обозначением элементов.
В соответствии с заданной схемой построения ковариационной матрицы зависимой переменной рассматриваемой логической модели является третий столбец (в порядке использования при вычислении ковариационной матрицы), следовательно коэффициенты вычисляются по третьей строке обратной матрицы (по правилу №3):
![]() ,
,
![]() .
.
Шаг 6. Вычисление оцененного ряда и остатков первой вспомогательной модели.
Оцененный
ряд вычисляется по формуле
,
остатки – по формуле
![]()
В результате получаем
|
Остатки
|
1,608865143 |
-0,60886514 |
9,757828272 |
-6,75782827 |
8,355154792 |
-3,35515479 |
3,851906914 |
4,148093086 |
10,26131689 |
6,73868311 |
8,292676437 |
-3,29267644 |
11,87225155 |
3,127748448 |
Шаг
7. Вычисление коэффициентов
![]() второй вспомогательной зависимости
второй вспомогательной зависимости
![]() ,
которая строится по следующей логической
модели
,
которая строится по следующей логической
модели
Зависимая переменная |
Факторы |
W |
Y, Z |
Строится
ковариационная матрица
![]() ,
при вычислении элементов которой
аргументы функции КОВАР задаются по
следующей схеме
,
при вычислении элементов которой
аргументы функции КОВАР задаются по
следующей схеме
Y;Y |
Y;Z |
Y;W |
Z;Y |
Z;Z |
Z;W |
W;Y |
W;Z |
W;W |
В результате получается матрица
58,12244898 |
16,44897959 |
12,69387755 |
16,44897959 |
28,40816327 |
20,02040816 |
12,69387755 |
20,02040816 |
17,83673469 |
По ней вычисляется обратная матрица
0,020715705 |
-0,007680342 |
-0,006122144 |
-0,007680342 |
0,171289983 |
-0,186794395 |
-0,006122144 |
-0,186794395 |
0,270083838 |
со стандартным обозначением элементов.
В соответствии с заданной схемой построения ковариационной матрицы зависимой переменной рассматриваемой логической модели является третий столбец (в порядке использования при вычислении ковариационной матрицы), следовательно коэффициенты вычисляются по третьей строке обратной матрицы (правило №3):
![]() ,
,
![]() .
.
Шаг 8. Вычисление оцененного ряда и остатков второй вспомогательной модели.
Оцененный
ряд вычисляется по формуле
,
остатки – по формуле
![]()
В результате получаем
|
Остатки
|
14,99508806 |
0,00491194 |
5,686729738 |
4,313270262 |
6,956624572 |
0,043375428 |
11,84327406 |
-0,843274063 |
4,836440427 |
-1,836440427 |
6,888621869 |
0,111378131 |
3,79322127 |
-1,79322127 |
Шаг
9. Вычисление
-статистики
по остаткам вспомогательных зависимостей
и границы критической области
![]() .
.
 .(3.2)
.(3.2)
Отдельно вычисляем
![]() =4,48070591 =КОРЕНЬ(ДИСПР(Арг1))
=4,48070591 =КОРЕНЬ(ДИСПР(Арг1))
![]() =1,92420218 =КОРЕНЬ(ДИСПР(Арг2))
=1,92420218 =КОРЕНЬ(ДИСПР(Арг2))
![]() =2,236067977 =КОРЕНЬ(5)
=2,236067977 =КОРЕНЬ(5)
![]() =-0,8474466 =КОРРЕЛ(Арг1;Арг2)
=-0,8474466 =КОРРЕЛ(Арг1;Арг2)
![]() =0,530880721 =КОРЕНЬ(1-
=0,530880721 =КОРЕНЬ(1-![]() ^2)
^2)
Окончательно получаем
![]() =-3,5694423
=-3,5694423
Вычисляем
границу критической области
![]() .
.
Шаг 10. Построение доверительного интервала по формулам
, .
В результате получаем
= -0,6260168, = -0,101841.
Вывод.
Так как точка 0 не принадлежит интервалу
,
то по критерию Стьюдента на уровне
значимости 0.05 зависимость ряда
![]() от ряда
признается значимой и отрицательной.
от ряда
признается значимой и отрицательной.
Задание выполнено полностью.
Контрольные вопросы и задачи.
Самостоятельно опишите методику построения доверительного интервала для коэффициента
 .
.Самостоятельно опишите методику построения доверительного интервала для коэффициента
 .
.
Учебное задание 4. Статистическое исследование ряда Х на автокорреляцию. Задание содержит решение следующих задач:
проверка ряда на автокорреляцию
построение модели линейного тренда
проверка остатков тренда на автокорреляцию
построение модели авторегрессии первого порядка
проверка остатков авторегрессионной модели на автокорреляцию
Выполнение этого задания разделено на 5 шагов.
Задан ряд:
|
1 |
4 |
3 |
7 |
6 |
5 |
9 |
9 |
7 |
8 |
8 |
9 |
14 |
12 |
13 |
13 |
Шаг 1. Проверка ряда на автокорреляцию.
Для
этого строится ряд первых разностей
![]() (или ряд приростов) ряда
в каждом наблюдении, начиная со второго.
Ряд первых разностей
(или ряд приростов) ряда
в каждом наблюдении, начиная со второго.
Ряд первых разностей
![]() показывает, на сколько изменилось
значение наблюдаемого параметра
в
-м
наблюдении по сравнению с предыдущим
наблюдением.
показывает, на сколько изменилось
значение наблюдаемого параметра
в
-м
наблюдении по сравнению с предыдущим
наблюдением.
|
|
1 |
|
4 |
3 |
3 |
-1 |
7 |
4 |
6 |
-1 |
5 |
-1 |
9 |
4 |
9 |
0 |
7 |
-2 |
8 |
1 |
8 |
0 |
9 |
1 |
14 |
5 |
12 |
-2 |
13 |
1 |
13 |
0 |
Затем вычисляется статистика Дарбина-Уотсона. Приближенно ее будем вычислять по следующей формуле:
 .
.
Из
таблицы значений констант Дарбина-Уотсона
![]() и
и
![]() на 5%-м уровне значимости с одним влияющим
фактором при Т=16 находим
на 5%-м уровне значимости с одним влияющим
фактором при Т=16 находим
![]() ,
,
![]() .
.
Вывод.
Так как
![]() ,
то делаем вывод о наличии в ряде
положительной автокорреляции.
,
то делаем вывод о наличии в ряде
положительной автокорреляции.
Проверка ряда на автокорреляцию закончена.
Шаг 2. Попытка избавиться от автокорреляции с помощью построения модели линейного тренда.
Построение
модели линейного тренда
![]() .
Логическая модель имеет вид:
.
Логическая модель имеет вид:
Зависимая переменная |
Фактор |
|
|
|
|
1 |
1 |
4 |
2 |
3 |
3 |
7 |
4 |
6 |
5 |
5 |
6 |
9 |
7 |
9 |
8 |
7 |
9 |
8 |
10 |
8 |
11 |
9 |
12 |
14 |
13 |
12 |
14 |
13 |
15 |
13 |
16 |
Вычисляем средние значения:
|
|
8 |
8,5 |
Строим
ковариационную матрицу
![]() .
.
13,125 |
15,3125 |
15,3125 |
21,25 |
Вычисляем обратную
0,47824 |
-0,3446 |
-0,34462 |
0,29538 |
Так
как зависимой переменной является
первый столбец, то вычисляем коэффициент
по правилу №1
![]() .
Вычисляем оцененный ряд и остатки.
.
Вычисляем оцененный ряд и остатки.
|
|
2,59559 |
-1,595588 |
3,31618 |
0,6838235 |
4,03676 |
-1,036765 |
4,75735 |
2,2426471 |
5,47794 |
0,5220588 |
6,19853 |
-1,198529 |
6,91912 |
2,0808824 |
7,63971 |
1,3602941 |
8,36029 |
-1,360294 |
9,08088 |
-1,080882 |
9,80147 |
-1,801471 |
10,5221 |
-1,522059 |
11,2426 |
2,7573529 |
11,9632 |
0,0367647 |
12,6838 |
0,3161765 |
13,4044 |
-0,404412 |
Шаг
3. Проверяем остатки
на автокорреляцию, повторив процедуру
шага №1 с заменой ряда
на остатки
![]() .
.
|
|
-1,595588 |
|
0,6838235 |
2,2794 |
-1,036765 |
-1,721 |
2,2426471 |
3,2794 |
0,5220588 |
-1,721 |
-1,198529 |
-1,721 |
2,0808824 |
3,2794 |
1,3602941 |
-0,721 |
-1,360294 |
-2,721 |
-1,080882 |
0,2794 |
-1,801471 |
-0,721 |
-1,522059 |
0,2794 |
2,7573529 |
4,2794 |
0,0367647 |
-2,721 |
0,3161765 |
0,2794 |
-0,404412 |
-0,721 |
Строим ряд первых разностей , вычисляем статистику Дарбина-Уотсона
 .
.
Из
таблицы значений констант Дарбина-Уотсона
и
на 5%-м уровне значимости с двумя влияющими
факторами при Т=16 находим
![]() ,
,
![]() .
.
Вывод.
Так как
![]() и
и
![]() ,
то делаем вывод об отсутствии в ряде
автокорреляции.
,
то делаем вывод об отсутствии в ряде
автокорреляции.
Заключение. Модель линейного тренда позволяет избавиться от автокорреляции ряда .
Шаг
4. Попытка избавиться от автокорреляции
построением авторегрессионной модели
![]() .
Здесь через
.
Здесь через
![]() обозначено среднее ряда
,
а через
обозначено среднее ряда
,
а через
![]() - среднее ряда
- среднее ряда
![]() .
.
По
ряду
строим ряд
по следующему правилу. Результатом
-го
наблюдения ряда
является результат
![]() -го
наблюдения ряда
.
-го
наблюдения ряда
.
|
|
1 |
|
4 |
1 |
3 |
4 |
7 |
3 |
6 |
7 |
5 |
6 |
9 |
5 |
9 |
9 |
7 |
9 |
8 |
7 |
8 |
8 |
9 |
8 |
14 |
9 |
12 |
14 |
13 |
12 |
13 |
13 |
Первое наблюдение оказывается неполным. Отбрасываем его.
|
|
4 |
1 |
3 |
4 |
7 |
3 |
6 |
7 |
5 |
6 |
9 |
5 |
9 |
9 |
7 |
9 |
8 |
7 |
8 |
8 |
9 |
8 |
14 |
9 |
12 |
14 |
13 |
12 |
13 |
13 |
По выравненным таким образом столбцам строим авторегрессионную модель. Здесь зависимая переменная , влияющий фактор - .
Вычисляем средние.
|
|
8,46667 |
7,666667 |
Строим
ковариационную матрицу
![]() .
.
10,5156 |
9,02222 |
9,02222 |
12,2222 |
Строим обратную
0,25937 |
-0,1915 |
-0,19146 |
0,22315 |
Вычисляем
коэффициент
также по правилу №1
![]() ,
поскольку зависимой переменной является
первый ряд. Теперь строим оцененный ряд
и остатки.
,
поскольку зависимой переменной является
первый ряд. Теперь строим оцененный ряд
и остатки.
|
|
3,5454545 |
0,4545455 |
5,76 |
-2,76 |
5,0218182 |
1,9781818 |
7,9745455 |
-1,974545 |
7,2363636 |
-2,236364 |
6,4981818 |
2,5018182 |
9,4509091 |
-0,450909 |
9,4509091 |
-2,450909 |
7,9745455 |
0,0254545 |
8,7127273 |
-0,712727 |
8,7127273 |
0,2872727 |
9,4509091 |
4,5490909 |
13,141818 |
-1,141818 |
11,665455 |
1,3345455 |
12,403636 |
0,5963636 |
Шаг
5. Проверяем остатки на автокорреляцию
по методике шага 1. По остаткам
![]() строим ряд первых разностей
строим ряд первых разностей
|
|
0,4545455 |
|
-2,76 |
-3,214545 |
1,9781818 |
4,7381818 |
-1,974545 |
-3,952727 |
-2,236364 |
-0,261818 |
2,5018182 |
4,7381818 |
-0,450909 |
-2,952727 |
-2,450909 |
-2 |
0,0254545 |
2,4763636 |
-0,712727 |
-0,738182 |
0,2872727 |
1 |
4,5490909 |
4,2618182 |
-1,141818 |
-5,690909 |
1,3345455 |
2,4763636 |
0,5963636 |
-0,738182 |
и вычисляем статистику Дарбина-Уотсона также, как это было сделано в шаге 1 и в шаге 3.

Из
таблицы значений констант Дарбина-Уотсона
и
на 5%-м уровне значимости с двумя влияющими
факторами при Т=15 находим
![]() ,
.
,
.
Вывод.
Так как
![]() и
и
![]() ,
то делаем вывод, что статистика
Дарбина-Уотсона попала в зону
неопределенности. Нельзя утверждать,
что автокорреляция остатков
отсутствует.
,
то делаем вывод, что статистика
Дарбина-Уотсона попала в зону
неопределенности. Нельзя утверждать,
что автокорреляция остатков
отсутствует.
Заключение. Модель авторегрессии первого порядка не позволяет избавиться от автокорреляции ряда .
Задание выполнено полностью.
Учебное
задание 5.
Построение нелинейной зависимости ВВП
(![]() )
от инвестиций (
)
от инвестиций (![]() )
и доходов населения (
)
и доходов населения (![]() )
по статистическим данным РФ за период:
декабрь 1993 – сентябрь 1998 гг. Зависимость
будем искать в виде
)
по статистическим данным РФ за период:
декабрь 1993 – сентябрь 1998 гг. Зависимость
будем искать в виде
![]() .(5.1)
.(5.1)
Для
построения этой зависимости нам надо
найти коэффициенты
![]() .
.
Исходные ряды:
|
|
|
|
|
Инвестиции |
Доходы насел |
ВВП |
Period |
tn Rb |
R bln |
tn Rb |
дек 1993 |
2,548 |
17669,36203 |
30,9 |
янв 1994 |
2,137 |
14060,3 |
27,5 |
фев 1994 |
2,671 |
17947,9 |
29,2 |
мар 1994 |
3,739 |
21400,8 |
30,9 |
апр 1994 |
3,343 |
23524,6 |
37,6 |
май 1994 |
3,761 |
23006,3 |
42,9 |
июн 1994 |
4,855 |
27077,7 |
49,8 |
июл 1994 |
5,538 |
29768,1 |
52,4 |
авг 1994 |
5,040 |
32764,1 |
56,1 |
сен 1994 |
5,434 |
35514,7 |
59,5 |
окт 1994 |
6,694 |
38200 |
66,1 |
ноя 1994 |
5,444 |
41035,5 |
73,7 |
дек 1994 |
7,111 |
56600 |
85,0 |
янв 1995 |
5,600 |
45300 |
75,0 |
фев 1995 |
7,000 |
51200 |
82,0 |
мар 1995 |
9,800 |
60300 |
99,0 |
апр 1995 |
8,900 |
65700 |
108,0 |
май 1995 |
11,300 |
71700 |
121,0 |
июн 1995 |
13,900 |
79200 |
133,0 |
июл 1995 |
15,700 |
81100 |
144,0 |
авг 1995 |
14,800 |
85600 |
154,0 |
сен 1995 |
16,400 |
90400 |
165,0 |
окт 1995 |
16,300 |
95600 |
167,0 |
ноя 1995 |
16,100 |
101000 |
165,0 |
дек 1995 |
17,600 |
115200 |
172,0 |
янв 1996 |
11,600 |
94100 |
147,7 |
фев 1996 |
13,700 |
100700 |
150,3 |
мар 1996 |
16,900 |
108100 |
168,2 |
апр 1996 |
16,400 |
113900 |
174,8 |
май 1996 |
17,800 |
106800 |
169,4 |
июн 1996 |
21,200 |
115900 |
180,8 |
июл 1996 |
22,100 |
116000 |
188,2 |
авг 1996 |
20,500 |
116700 |
199,6 |
сен 1996 |
22,200 |
113300 |
201,3 |
окт 1996 |
20,700 |
120700 |
205,3 |
ноя 1996 |
21,000 |
120900 |
197,7 |
дек 1996 |
21,700 |
147400 |
216,9 |
янв 1997 |
14,000 |
118300 |
172,1 |
фев 1997 |
15,800 |
120600 |
175,0 |
мар 1997 |
18,300 |
125800 |
193,8 |
апр 1997 |
16,700 |
136400 |
201,2 |
май 1997 |
18,800 |
127300 |
203,2 |
июн 1997 |
22,200 |
141400 |
210,6 |
июл 1997 |
23,700 |
139400 |
219,1 |
авг 1997 |
22,200 |
135600 |
237,9 |
сен 1997 |
23,800 |
132900 |
248,8 |
окт 1997 |
22,500 |
141000 |
240,0 |
ноя 1997 |
22,200 |
137800 |
226,0 |
дек 1997 |
22,400 |
186800 |
258,7 |
янв 1998 |
13,300 |
117100 |
185,9 |
фев 1998 |
15,300 |
123100 |
182,1 |
мар 1998 |
18,500 |
126200 |
197,6 |
апр 1998 |
17,600 |
136500 |
205,0 |
май 1998 |
19,200 |
123900 |
205,9 |
июн 1998 |
23,100 |
127500 |
207,4 |
июл 1998 |
24,200 |
131300 |
214,1 |
авг 1998 |
22,100 |
130600 |
226,1 |
сен 1998 |
23,400 |
147400 |
257,0 |
Выполнение задания разделено на 4 шага.
Шаг 1. Построение рядов логарифмов.
Номер наблюдения |
|
|
|
1 |
0,935309 |
9,779587 |
3,430756 |
2 |
0,759403 |
9,551111 |
3,314186 |
3 |
0,982453 |
9,795228 |
3,374169 |
4 |
1,318818 |
9,971184 |
3,430756 |
5 |
1,206869 |
10,0658 |
3,627004 |
6 |
1,324685 |
10,04352 |
3,758872 |
7 |
1,580009 |
10,20647 |
3,908015 |
8 |
1,711633 |
10,30119 |
3,958907 |
|
|
|
|
|
|
|
|
55 |
3,139833 |
11,75587 |
5,334649 |
56 |
3,186353 |
11,78524 |
5,366443 |
57 |
3,095578 |
11,77989 |
5,420977 |
58 |
3,152736 |
11,90091 |
5,549076 |
Ряды
логарифмов вычисляются поэлементно
через исходные ряды
![]() .
Здесь в таблице размещены только начало
и конец каждого столбца. Вы же должны
рассчитать все элементы (58 штук) каждого
столбца.
.
Здесь в таблице размещены только начало
и конец каждого столбца. Вы же должны
рассчитать все элементы (58 штук) каждого
столбца.
Шаг 2. Построение эконометрической зависимости
![]() .
.
Здесь применяется логическая модель
Зависимя переменная |
Факторы |
|
, |
1. Находим средние
|
|
|
2,519001 |
11,2935 |
4,877542 |
2.
Вычисляем ковариационную матрицу
![]() .
.
Получаем
0,448774 |
0,431864 |
0,417939 |
0,431864 |
0,434344 |
0,414743 |
0,417939 |
0,414743 |
0,400806 |
3. Вычисляем обратную
77,53305 |
9,102168 |
-90,2661 |
9,102168 |
194,1667 |
-210,41 |
-90,2661 |
-210,41 |
314,3464 |
4.
Поскольку зависимой переменной является
третий столбец, вычисляем коэффициенты
![]() по правилу №3:
по правилу №3:
![]() ,
,
![]() .
.
Строим
оцененный ряд логарифмов
![]() ,
поэлементно вычисляемый по формуле
(длина ряда – 58 чисел) и вычисляем
коэффициент детерминации
,
поэлементно вычисляемый по формуле
(длина ряда – 58 чисел) и вычисляем
коэффициент детерминации
 .
.
Шаг
3. Построение оцененного ряда
и ряда остатков
![]() .
.
Коэффициенты
и
уже найдены на шаге 2. Коэффициент
![]() вычисляется по формуле
вычисляется по формуле
![]() .
Теперь вычисляется оцененный ряд
и остатки
.
В итоге должна получиться таблица
(середину которой мы тоже здесь сокращаем,
но Вам надо вычислить каждый из 58
элементов).
.
Теперь вычисляется оцененный ряд
и остатки
.
В итоге должна получиться таблица
(середину которой мы тоже здесь сокращаем,
но Вам надо вычислить каждый из 58
элементов).
Номер наблюдения |
|
|
|
1 |
30,9 |
30,2479378 |
0,652062 |
2 |
27,5 |
24,6797534 |
2,820247 |
3 |
29,2 |
30,9828884 |
-1,78289 |
4 |
30,9 |
38,3901455 |
-7,49015 |
5 |
37,6 |
39,6062675 |
-2,00627 |
6 |
42,9 |
40,3627194 |
2,537281 |
7 |
49,8 |
48,4382984 |
1,361702 |
8 |
52,4 |
53,597017 |
-1,19702 |
|
|
|
|
|
|
|
|
55 |
207,4 |
213,8569 |
-6,4569 |
56 |
214,1 |
221,0355 |
-6,93553 |
57 |
226,1 |
214,5792 |
11,5208 |
58 |
257,0 |
236,5339 |
20,46609 |
Шаг 4. Строим графики

Задание выполнено полностью.
Учебное задание 6.
Анализ качественных признаков с использованием метода фиктивных переменных.
Задача. Проведено анкетирование по одному вопросу, на который требуется дать ответ «Да» или «Нет». Вопрос отпечатан на листах разного цвета: красного, синего и зеленого. Листы тщательно перемешаны. После подсчета голосов случайным образом из результатов голосования были выбраны 58 опросных листов.Результатом наблюдения является регистрация двух параметров: цвет опросного листа (К-С-З) и вариант ответа (Д-Н). Получена следующая выборка:
Номер наблюдения |
Цвет листа |
Вариант ответа |
|
|
|
1 |
К |
Д |
2 |
С |
Д |
3 |
З |
Н |
4 |
С |
Д |
5 |
К |
Д |
6 |
К |
Д |
7 |
З |
Н |
8 |
С |
Д |
9 |
К |
Н |
10 |
С |
Н |
11 |
С |
Д |
12 |
З |
Н |
13 |
К |
Н |
14 |
К |
Н |
15 |
З |
Н |
16 |
С |
Д |
17 |
З |
Н |
18 |
З |
Н |
19 |
К |
Н |
20 |
К |
Д |
21 |
К |
Д |
22 |
С |
Н |
23 |
З |
Д |
24 |
С |
Д |
25 |
С |
Д |
26 |
З |
Н |
27 |
С |
Д |
28 |
С |
Н |
29 |
К |
Д |
30 |
З |
Д |
31 |
К |
Н |
32 |
С |
Д |
33 |
К |
Н |
34 |
К |
Н |
35 |
З |
Д |
36 |
С |
Д |
37 |
К |
Н |
38 |
К |
Д |
39 |
З |
Н |
40 |
З |
Д |
41 |
С |
Н |
42 |
З |
Д |
43 |
К |
Д |
44 |
С |
Н |
45 |
К |
Д |
46 |
З |
Н |
47 |
К |
Н |
48 |
С |
Д |
49 |
С |
Н |
50 |
З |
Д |
51 |
З |
Д |
52 |
З |
Д |
53 |
К |
Н |
54 |
С |
Д |
55 |
К |
Н |
56 |
К |
Н |
57 |
З |
Д |
58 |
С |
Н |
Требуется:
1. Построить фиктивные переменные: «К», «С», «З», «Д», «Н»
2. Найти корреляцию ответа «Да» с каждым из цветов опросного листа
3. Найти корреляцию ответа «Нет» с каждым из цветов опросного листа
4. По логической модели
Зависимая переменная |
Факторы |
||
Фиктивная «Д» |
Фиктивная «К» |
Фиктивная «С» |
Фиктивная «З» |
4а) рассчитать факторную нагрузку на каждый фактор
4б) проверить факторы на мультиколлинеарность
Выполнение задания разделено на 5 шагов.
Шаг 1. Построение фиктивных переменных: «К», «С», «З», «Д», «Н»
Для построения фиктивных используется стандартная функция
=ЕСЛИ(Логическое выражение;Значение если ИСТИНА;Значение если ЛОЖЬ)
Построение Фиктивной «К».
Предположим, что массив: Цвет листа размещен в ячейках А1:А58, и фиктивную мы хотим размещать в столбце С1:С58.
Для поэлементного вычисления массива: Фиктивная «К» в ячейку С1 вставляем выражение
=ЕСЛИ(А1=”К”;1;0)
и копируем эту формулу на весь массив. Примечание. Чтобы функция выполнила правильные вычисления, в записанном выражении надо аккуратно отслеживать регистры клавиатуры: в адресе А1 буква А пишется в английском регистре, буква “К” – в том регистре, в котором Вами задана исходная таблица результатов наблюдений. Если это был русский регистр, то и буква “К” должна быть в русском регистре.
В результате выполнения шага 1, должна появиться таблица (которую мы здесь помещаем в сокращении)
Номер наблюдения |
Фиктивная «К» |
Фиктивная «С» |
Фиктивная «З» |
Фиктивная «Д» |
Фиктивная «Н» |
1 |
1 |
0 |
0 |
1 |
0 |
2 |
0 |
1 |
0 |
1 |
0 |
3 |
0 |
0 |
1 |
0 |
1 |
4 |
0 |
1 |
0 |
1 |
0 |
5 |
1 |
0 |
0 |
1 |
0 |
6 |
1 |
0 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
55 |
1 |
0 |
0 |
0 |
1 |
56 |
1 |
0 |
0 |
0 |
1 |
57 |
0 |
0 |
1 |
1 |
0 |
58 |
0 |
1 |
0 |
0 |
1 |
Шаг 2. Найти корреляцию ответа «Да» с каждым из цветов опросного листа. Для вычисления корреляции используется функция
=КОРРЕЛ(Арг1;Арг2)
Для вычисления корреляции между Фиктивной «К» и Фиктивной «Д» надо в Арг1 задать адрес массива: Фиктивная «К», а в Арг2 – адрес массива: Фиктивная «Д».
В результате выполнения шага 2 должна появиться таблица
Фиктивная «К» |
Фиктивная «С» |
Фиктивная «З» |
-0,133682206 |
0,159706 |
-0,023146 |
Анализ полученной таблицы показывает, что наиболее сильное отрицательное влияние на ответ «Да» оказывал красный цвет опросного листа. Положительная корреляционная связь с ответом «Да» у синего цвета.
Шаг 3. Найти корреляцию ответа «Нет» с каждым из цветов опросного листа. Этот шаг выполняется аналогично шагу 2 и служит для закрепления навыков вычисления корреляции.
В результате выполнения шага 3 должна получиться таблица
Фиктивная «К» |
Фиктивная «С» |
Фиктивная «З» |
0,133682206 |
-0,159706 |
0,023146 |
Анализ этой таблицы проведите самостоятельно.
Шаг 4а. Для расчета факторной нагрузки выполняем следующую последовательность действий
4а.1. Строим ковариационную матрицу
![]() .
.
Должна получиться следующая таблица
0,23097503 |
-0,118608799 |
-0,112366 |
-0,032105 |
-0,118608799 |
0,220273484 |
-0,101665 |
0,037455 |
-0,112366231 |
-0,101664685 |
0,214031 |
-0,005351 |
-0,032104637 |
0,03745541 |
-0,005351 |
0,249703 |
4а.2. Строим обратную. Должна получиться следующая таблица
3,60288E+15 |
3,60288E+15 |
3,6E+15 |
1,274031 |
3,60288E+15 |
3,60288E+15 |
3,6E+15 |
0,436822 |
3,60288E+15 |
3,60288E+15 |
3,6E+15 |
0,979457 |
1,325581395 |
0,488372093 |
1,031008 |
4,124031 |
4а.3. Вычисляем коэффициенты факторной нагрузки. Поскольку зависимая переменная, в соответствии с выбранной логической моделью, стоит в ковариационной матрице на четвертом месте, то для вычисления коэффициентов факторной нагрузки применяем правило №4
![]() ,
,
![]() ,
,
![]() .
.
Шаг 4б. Проверка факторов на мультиколлинеарность.
Строим ковариационную матрицу факторов
![]() .
.
Получаем
0,23097503 |
-0,118608799 |
-0,112366 |
-0,118608799 |
0,220273484 |
-0,101665 |
-0,112366231 |
-0,101664685 |
0,214031 |
Вычисляем определитель полученной матрицы. Для этого используем функцию
=МОПРЕД(Арг)
из раздела: математические.
В качестве параметра Арг вставляем адрес ковариационной матрицы
. В итоге получаем
Определитель = |
0,00000000000000001021672 |
Заключение.
Точность вычислений в пакете EXCEL
при 32-разрядном доступе к памяти не
превосходит числа
![]() .
Вычисленный определитель равен
.
Вычисленный определитель равен
![]() ,
что меньше допустимой ошибки вычислений.
Следовательно, в данной модели присутствует
мультиколлинеарность факторов.
,
что меньше допустимой ошибки вычислений.
Следовательно, в данной модели присутствует
мультиколлинеарность факторов.
Задание выполнено полностью.