

связь, основанная на возможности применения предмета или использовании его свойств.
1. Структура лексико-семантического собрания терминов – алфавитный список дескрипторов с их словарными статьями. Элементарной структурной единицей данного раздела тезауруса является словарная статья дескриптора, которая строится по алфавитно-структурному принципу.
Структура словарной статьи: Заглавный дескриптор ИВ упорядоченное по алфавиту множество условных синонимов данного заглавного дескриптора, образующее вместе с ним класс условной эквивалентности; РД упорядоченное по алфавиту множество всех дескрипторов, выражающих родовое понятие, стоящих на самом верхнем уровне иерархии; ВД упорядоченное по алфавиту множество всех дескрипторов, выражающих видовое понятие; АД упорядоченное по алфавиту множество дескрипторов, связанных отношениями семантической близости с заглавным дескриптором. Пример. Информационно-поисковый язык ИВ: - РД: языки (искусственные) ВД: дескрипторный ИПЯ АД: ИПС (часть-целое)
2. Систематический указатель дескрипторов В этой части тезауруса отражены те отрасли науки и техники, по которым можно производить поиск информации с той или иной глубиной и детализацией. Необходимость систематического указателя (СУ) как составной части тезауруса обусловлена тем, что он даёт наглядное представление об общем состоянии терминологии в той или иной области знаний, позволяет построить стройную терминологическую модель. Указатель имеет 3-хступенчатую структуру (дескрипторные области, дескрипторные группы, дескрипторы) и включает следующие части: -- пронумерованный алфавитный список дескрипторных областей; Пример.
01 Авиация 02 Автобронетанковая техника 03 Артиллерия … 33 Ядерная физика и техника
-- пронумерованный алфавитный список дескрипторных областей с входящими в них дескрипторными группами;
Пример.
01 Авиация 0101 Авиационные конструкции 0102 Аэродинамика … 33 Ядерная физика и техника
3301 Детекторы ионизирующих излучений 3302 Изотопы …
-- пронумерованный алфавитный список дескрипторных групп с входящими в них дескрипторами.
Пример.
0101 Авиационные конструкции
Бомбовые отсеки
Винты вертолета
…
Всего – 33 дескрипторные области; - 302 группы (в каждой области от 2 до 23 групп)
3. Указатель иерархических отношений
В
качестве основных входов этого указателя
выбираются только те заглавные
дескрипторы, которые не имеют родовых
дескрипторов, т.е. стоят на верхней
ступеньке иерархического дерева.
Каждый
заглавный дескриптор приводится со
своими видовыми дескрипторами.
Уровни
подчинения в иерархическом дереве
обозначены в указателе точками. Каждый
видовой дескриптор располагается под
родовым со сдвигом вправо на одну точку.
Количество точек показывает сколько
родовых дескрипторов имеется у видового
в данном семействе дескрипторов.
Пример.


Пермутационный указатель. Его структура ПУ является входом в тезаурус.
ИПС . . . . . информационно информационно-поисковая система . . . . поисковая информационно-поисковая система
. . . . система информационно-поисковая система
Необходимость ПУ вызвана преобладанием терминов-словосочетаний (74 %), некомпетентностью пользователей, отсутствием единообразием в терминологии (ЭВМ). Каждый термин появляется столько раз, сколько в нём компонентов. И даёт возможность пользователю найти термин по любому компоненту. Недостаток – большой объем.
Практические рекомендации для составления пс Анализ содержания документов и выявления ключевых слов
На первом этапе составления ПОДа проводится анализ его содержания и выявление КС. Анализ содержания документов в процессе индексирования ведется в определенной последовательности по единой схеме. Схема позволяет унифицировать форму описания документа КСми, что способствует повышению эффективности работы ИПС. Согласно принятой схеме выявление КС осуществляется по следующим смысловым аспектам:
предмет(или тема) исследования.
сторона, с которой исследуется предмет или его свойство; признаки и закономерности предмета.
область применения или использования предмета.
вид исследования свойств предмета.
конкретный метод исследования.
методика проведения исследования и специальное оборудование, используемое для изучения предмета и его свойств исследования.
условия, в которых проведены исследования свойств предмета.
Конкретно (по всем пунктам):
применительно к документам по научно-технической тематике в качестве предмета исследования могут выступать: общие или частные понятия, а также любые материальные объекты: устройства, образцы техники, виды и системы вооружения и т.д.
в качестве наиболее часто встречающихся сторон исследования предмета выступают производства, эксплуатация, автоматизация, стоимость, применение, технические требования и т.д. Данный смысловой аспект отвечает на вопрос: с какой точки зрения предмет представляет интерес в процессе исследования.
областью применения предмета могут быть: любой другой предмет или вся его предметная область, отрасли хозяйства, различные военные операции и т.д.
в качестве видов исследования выступают: теоретические расчёты, лабораторные исследования, стендовые испытания и т.д.
+ 6 методы и методика исследования могут быть: математические, сравнительно-исторические и т.д. Специальное оборудование, используемое в процессе исследования, представлено чаще различными установками , тренажерами, стендами, приборно-измерительным оборудованием, ЭВМ и т. д.
7. Условиями, характеризующими процесс исследования, могут быть: время и место (н-р, зима, лето, под водой); географические условия и условия местности (Арктика, тропики, пустыня); физические условия (температура, радиация); а также химические, биологические и др. условия.
Приведенные 7 смысловых аспектов характерны для: содержания научно-технических документов, отражающих результаты научных исследований, конструкторских разработок, испытаний. Они обладают наибольшей информационной емкостью, т.к. содержат основную семантическую информацию, представленную в документе.
Они составляю 7 элементов формализованной модели свернутого содержания документа, т.е. ПОДа. В соответствии с этими смысловыми аспектами осуществляется выбор КС в процессе анализа содержания документа. Первые три смысловые аспекта отражают информацию, касающуюся предмета исследования, остальные характеризуют сам процесс исследования. Составление ПОД начинается с выявления КС из заголовка (затем из текста). В процессе выбора КС необходимо придерживаться следующих правил:
отражению КС-ами подлежит лишь та информация, которая действительно имеется в документе и ясно выражена.
составление списка КС ни в коей мере не связыв. с вероятным наличием или отсутствие каких-либо дескрипторов в тезаурусе или с каким-либо предположением о характер возможных запросов.
в качестве КС, выраженных отдельными словами ЕЯ, как правило используются только имена существительные. Если в каче6стве КС кроме сущ. необходимо использовать и другие КС, то их следует объединить в словосочетания вокруг соответств. существительного.
элементы словосочетания ЕЯ, используемые в качестве КС выписываются в той же последовательности, что и в документе. Н-Р, «нелинейные дифференциальные уравнения», а не «дифференциальные уравнения нелинейные».
словосочетания, отражающие принятые технические термины, выписываются как одно КС. Н-р, температурный коэффициент радиоактивности.
ПРОБЛЕМА АВТОМАТИЧЕСКОГО РЕФЕРИРОВАНИЯ ТЕКСТА
Реферат – вторичный документ, в котором кратко излагаются результаты исследований, приведенных в первичных документах (статьях, монографиях).
РЕФЕРАТ – один из важнейших источников информации (как вторичный документ). Но появление реферата происходит через 3-4 месяца после публикации первичного документа. За это время информация из первичного документа устаревает. Следовательно, проблема в том, чтобы сократить срок между выходом первичного документа и выходом реферата. Сократить можно лишь поручив процедуру составления реферата ЭВМ. А поручить это ЭВМ можно только в том случае, если мы её (процедуру) формализуем.
Формализованное реферирование - извлечение из текста первоисточника на основе заранее сформулированных правил предложений, характеризующих основное содержание этого текста. Набор таких предложений образует реферат-экстракт. На основе формального реферирования, выполненного человеком, складываются методы машинного реферирования, т.е. составления квазирефератов (составленных ЭВМ). ЭВМ с помощью определённого набора семантических и лингвистических правил выбирает ключевые фразы из исходного текста. В настоящее время есть несколько методов автоматического реферирования:
статистические методы.
логико-математические методы.
лингвистические методы.
Одним из ЛИНГВИСТИЧЕСКИХ является метод «словесных клише». СУТЬ: экстрагирование (выбор из тестов первичных документов отдельных информативных и метаинформативных фраз с помощью «словесных клише»).
Информативные фразы составляют содержательную часть текста. В них выражены фактические сведения (в том числе графики, формулы) или концептуальное осмысление этих фактических сведений. Метаинфомративные фразы характеризуют тему документов в целом либо отдельные его фрагменты, т.е. содержательные аспекты. Совокупность метаинформативных фраз образует аннотацию, а информативных фраз – реферат (условное деление).
Для практической реализации идеи, заложенной в методе «словесных клише», были разработаны два «инструментария» - лексический аппарат экстрагирования и методика экстрагирования.
Алгоритм.
Лексический аппарат – список словесных клише, который состоит из трёх подсписков: маркеров, индикаторов, коннекторов.
МАРКЕР – элемент словесного клише (слова или словосочетания), однозначно обозначающий тот или иной аспект первичного документа.
Н-р: аспект1(выделены по каждой тематике)-целевая установка достаточно часто и точно характеризуется такими маркерами: цель, целью является и т.п.
Аспект2 – предполагаемый вариант решения – характеризуется такими маркерами: предполагаемый…основан…, в работе предлагается…
Аспект3 – особенность предлагаемого варианта решения: особенностью является.., особенность ..заключается…
В результате анализ первичных документов маркеры выявляются и систематизируются в специальных словарях, ТЕЗАУРУСАХ,
Тезаурус является основным документом формализованного реферирования, где содержится около 600 маркеров, лексических сопровождений и их синонимов.
Как правило, маркеры состоят из 2-х частей: ядерного слова и лексического сопровождения. Каждое из них может иметь свой класс синонимов. Ядерные слова, встречающиеся в тексте без зафиксированного в словаре лексического сопровождения, маркера не образуют, т.е. являются лжемаркерами.
СТРУКТУРА ТЕЗАУРУСА
В тезаурусе в алфавитном порядке перечислены ядерные элементы маркеров (помета-Я.), лексическое сопровождение ядра (Л.С.), их синонимы(С.) и отсылки от синонимов к ядерным словам (см.), (а.- аспект),ядерные элементы выделены курсивом, жирным. {ПП- аспекты (постановка проблемы), ПВР – аспекты (предлагаемый вариант решения), ЦЦ – аспекты (целевая установка), Р – результат}
Например: фрагмент тезауруса (словарная статья).
Актуальность а.(ПП)
Л.С. – делать, иметь, представлять, являться.
Анализ см. я. Результаты а. (Р.)
Анализироваться см. я. Предлагаться а. (ПВР)
ИНДИКАТОРЫ – в отличие от маркеров, не привязаны жестко к определённому аспекту содержания первичного документа: они указывают на предложения, которым автор придаёт особое значение (Н-р, -следует подчеркнуть, - необходимо отметить) или в которых автор подводит итог какого-то фрагмента или изложения: (Н-р, итак, таким образом, следовательно).
КОННЕКТОРЫ – в отличие от маркеров и индикаторов, непосредственно выделяющих то предложение, в которое они входят, коннекторы служат для выделения предложений так или иначе связанных с маркированными. Можно выделить два типа коннекторов:
1.- указательные и личные местоимения (это, эти, он). Т.е. слова-заместители, вхождения которых в маркированные предложения лишают его смысловой значимости и требует включение в реферат-экстракт предложения, содержащего замещаемое слово. («шаг назад», коннекторы типа Х(«икс»)).
2. – слова и выражения, говорящие о том, что предложение, в которое они входят, уточняет, конкретизирует содержание маркированного предложения (Н-р, при этом, например, в частности). Эти коннекторы используются для выделения предложений, следующих за маркированными («шаг вперед» - процедура типа Y («игрек»)).
Примеры поисковых систем
1. ИПС Пусто-непусто-4 [документальная, с языком дескрипторного типа без грамматики]
Материал: ИПЯ предназначен для поиска информации в массиве рефератов по электротехнике
Описание языка(структура): ИПЯ построен на базе слов ЕЯ. Слова ЕЯ, отобранные для построения ИПЯ, объединились в классы условной эквивалентности. Каждому классу ставилось в однозначное соответствие некоторое число- дескриптор. Одно из слов выделяется и используется в качестве обозначения всего класса и оно (как и число) считается дескриптором , т.е. мы устранили синонимию. Например: новый, новинка, усовершенствование, модернизация, патент, патентуется , предлагается, разработан, разработанный - класс условной эквивалентности. Эти слова являются эквивалентными по действию в данном классе. Д – «модернизация» Слова, отобранные для включения в дескрипторный словарь, располагаются по алфавиту и против каждого слова выписываются дескриптор как вербальный, так и числовой.
Слова-омонимы встречались в словаре столько раз, сколько значений они имели в сфере действия данной системы.( например: «защита» имела два дескриптора: 1- защита (от перегрузки)-25; 2- защита (предохранитель)-80.), т.е. мы устранили омонимию.
Термины-словосочетания – выделены в отдельны список. (Н-р: «прибор для измерения напряжения» - 146). В П-нП4 были зафиксированы следующие виды отношений между дескрипторами: базисные -отношения подчинения. Они имеют транзитивный характер и частично упорядочивают дескрипторы ИПЯ. Базисные отношения приблизительно совпадают с отношениями «от общего к частному», поэтому их называют отношениями подчинения. Пример фиксации отношений:
|769свойства
|
_____ |153 данные
* * * *
692 (размер) 54 (вес)
КРИТЕРИИ СМЫСЛОВОГО СООТВЕТСТВИЯ (КСС)[логический]
КСС выражен в терминах пустоты-непустоты 4-х множеств (Поэтому П-нП4):
М(i)1- Мн-во дескрипторов документа, совпадающих с каким-либо дескриптором запроса.
М(i)2- Мно-во д-в документа, стоящих выше (но не обязательно непосредственно выше), хотя бы одного из дескрипторов запроса.
М(i)3 – Мно-во д-в, стоящих ниже (не обяз.непосредств.) хотя бы одного из д-в запроса.
М(i)4- Мно-во д-в ЗАПРОСА, не сравнимых ни с одним из дескрипторов докуметнтов ( в смыслах отношения , упорядочивающего мн-во д-в).
Критери выдачи может быть представлен следующей таблицей, в которой документы, подлежащие выдаче, разбиваются на 4 эшелона: (П-пусто, Н-непусто). Каждому из мн-в М1-4 поставлено в соответствие некотороечисло Мi, которое определяется следующим образом Мi=(0-если Мi-П, 1 –если Мi=Н),
Где i= 1,2,3,4.
№ эшелона |
М1 |
М2 |
М3 |
М4 |
1 |
н п п |
п п п |
п н н |
п п п |
2 |
Н |
н |
н |
п |
3 |
н п |
н н |
н н |
п п |
4 |
п |
н |
п |
п |
Тогда для любой пары ПОД-ПОЗ можно составить 16 4-хразрядных двоичных чисел, каждое из которых будет характеризовать степень смыслового соответствия между документом и инф. запросом из этих 16 двоичных чисел (а они есть номера соотв. классов документов) были выбраны числа 0010, 0100, 0110, 1000, 1010, 1100, 1110, которые обозначают классы предположительно содержащие больше релевантных документов, чем нерелевантных. Эти числа были сгруппированы в таблицу:
№ эшелона |
М1 |
М2 |
М3 |
М4 |
1(да) |
1 0 1 |
0 0 0 |
0 1 1 |
0 0 0 |
2(да) |
1 |
1 |
1 |
0 |
3(может быть) |
1 0 |
1 1 |
0 1 |
0 0 |
4(может быть) |
0 |
1 |
0 |
0 |
В этой таблице эшелоны так пронумерованы, чтобы вероятность выдачи искомых док-в была максимальной в 1-м эшелоне и минимальной в последнем, а вероятность выдачи нерелевантных д-в (поисковый шум) минимальна в 1-м эшелоне и максимальна в последнем.
Это даёт возможность пользователю определить, какие эшелоны д-в он хочет получить. Если его не беспокоит потеря некоторой части инф. и он хочет не тратить время на дополнительный просмотр и получить основную инф., он может ограничиться 1-м эшелоном. Там будут, как правило, документы, содержащие нужную инф-ю. Если же он заинтересован в получении исчерпывающей инф. и ради этого готов мириться с получением ненужных д-в, то он может запросить 2,3,4 эшелоны.
2.ИПС «БИТ» [документальная, язык смысловых кодов с грамматикой]
Разработана группой сотрудников Института кибернетики Украины под руководством Скороходько Е.Ф. На базе рефератов в области радиоэлектроники и вычислительной техники. Язык системы построен на основе следующих предположений: Структура ИПЯ должна как можно точнее отражать стр-ру инф-ии о явлениях внешнего мира. Любая инф. может быть передана с помощью комбинаций предметов и отношений. Если язык ПС будет располагать средствами для передачи этих компонентов инф., то с его помощью можно будет передавать смысл документов с требуемой точностью.
Структура языка. ИПЯ оперирует единицами 3-х видов: 1-термины ‘Х’;2-релатемы ‘R’; 3-предложения. Термины - это знаки, передающие номинативную информацию, т.е. обозначающие предметы. Релатемы – это знаки, передающие релятивную функцию, т.е. обозначающие отношения(или свойства). Предложения – это знаки, передающие семантическую инф-ю, т.е. описывающие ситуацию.
Грамматика языка делится на две части:
грамматика образования производных единиц.
грамматика тождественных преобразований единиц.
1-ая состоит из правил образования терминов, релатем и предложений.
2-ая состоит из правил тождественных преобразований терминов, релатем и предложений. Эта грамматикаслужит для выявления синонимичных выражений на ЕЯ и приведения всех вариантов записей к одной при сотсавлении ПОДов и ПОЗов.
Существует три операции построения предложений:
а) операция образования простых предложений, которая сводится к соединению 2-х терминов релатемой: XRX.
б) операция присоединения термина. Состоит в том, что в предложении при помощи релатем включается новый термин.
в) синтаксическая операция «склеивания» (2 простых предложения соединяются при помощи релатем в 1 сложное).
Структура языка
1.Алфавит языка включает символы X и R с индексами+ различные символы: ( ), ^, 1..0, ,.
2. Лексика а) термины заданы списком (базовые термины – из списка), каждый термин имеет 2 индекса – верхний и нижний. Н-р: Х0001. Верхний – 0- обозначает, что данный термин из списка базовых терминов (термины с индексами1,2,3-производные). Нижний – порядковый номер данного термина в списке базовых терминов (или в списке производных терминов).
Н-р: Х0001- базовый – «большая величина»; Х0003 – «вакуум»; Х0146- «электрон».
3. Логика системы (релатема, отношения).
Релатемы заданы списком (обозначают отношения). Имеют только нижний индекс. R001-обозначает «быть элементом класса». R003- обозначает «быть субъектом»; R045-обозначает «быть равным»; R047-обозначает «быть больше»; R003 – «не быть субъектом».
Из базовых терминов и релатем строятся коды, или производные термины.{язык RX-кодов= ИПЯ «Бит»} Пример: [Х040-«мощность», Х127-«увеличение». R011 – «иметь объект» ] R001 Х127R011Х040 – «увеличение мощности»
Этот код является термином, причём у него есть развернутый вид, или свёртка- Х1167. «Свёртка» удобна из-за краткости, а «развёртка», когда надо установить смысловые связи между терминами.
Смысловой код (семантический) может быть в виде свёртки, развёртки, а также: графический способ (в виде дерева, вершины которого сопоставлены с классами предметов (обозн. символами Х), а дуги – отношениями, которые обозначаются символами R. Вершина дерева, соответствует свёртке, а всё остальное – развёртка.
Как осуществить перевод с ея на ипя?
3 этапа:
документ предоставляется в виде перечня терминов.
для каждого термина в словаре находят соответствующий термин ИПЯ.
найденные в словаре термины комбинируют с соответствующими терминами, образуя термины более высокого порядка.
В ИПЯ «БИТ» используются три формы представления терминов: 1- формальная; 2- графическая (в виде дерева); 3- табличная.
Преимущества: 1- наиболее компактная; 2- наглядная; 3- удобная при машинной обработке информации.
Правила Интерпретации (перевода) заданы словарём семантических кодов.
Основные параметры языка:
Тип – язык смысловых кодов с грамматикой.
Способ кодирования – алфавит ИПЯ включает символы X и R с цифровыми индексами, скобки, и др. знаки.
Аппарат парадигматики: термины и релатемы, которые являются основным механизмом как парадигматических, так и синтагматических отношений. Н-р: одни R чаще используются для передачи парадигматических связей, другие- синтагматических. Пример: R «быть подклассом» или R «быть частью» употребляются в парадигматике ,а R «быть субъектом» или R «быть результатом» - в синтагматике.
аппарат синтагматики: помимо релатем для указания связей между терминами употребляются знаки скобок, конъюнкции - дизъюнкции и др.
3.Ипс «синтол» [документальная, синтагматический язык с грамматикой]
(Франция). Задача авторов- разработка ИПС на основе ЕЯ для любой предметной области (эксперимент был проведён на следующих отраслях: психология, физиология, этнография). В результате была получена система, в котрой для записи информации были использованы 2 оси отношений (парадигмат. и синтагмат.). Причём парадигмат. ось не зависит от синтагмат. организации. Синтагматическая организация выражает отношения, которые объединяют слова в какой-нибудь цепочке (т.е. связи слов в данном тексте) в соответствии с правилами данного языка . В основу синтагм.отн-й положены некоторые общие логические категории, не связанные с синтагматическими категориями ЕЯ. Это отношения типа : причинно-следственные, сравнения; сопоставления, отношения предмета к действию, действия к объекту, принадлежности и включения.
Авторы подчёркивают, что избранная синтагматическая система является минимальной системой необходимых отношений, при которой для множества понятий научной литературы имеют место различные ситуации, образуемые этими понятиями в их отношении друг с другом.
I. Синтагматическая организация «синтола».
1) Система главных отношений.
Выражениями языка Синтол являются синтагмы, т.е. два слова, принадлежащие словарю Синтола и объединённые одним из отношений, входящих в систему отношений данного языка. С-ма отношений состоит из 4-х отношений:1) предикативные(1); 2) ассоциативные (2); 3) консекуативные (3); координативные (4).
2) Морфология Синтола. (формальные категории). Каждый термин словаря Синтола должен быть отнесён к одной из 4-х формальных категорий: предикаты (Р); существенность (Е); состояние (S); действия (А).
3) Ориентация отношений (грамматика)
П еречисленные главные отношения Синтола (4) не являются симметричными: между двумя терминами одно и то же отношение может давать две разных синтагмы. Н-р: забастовка, вызванная экономическим кризисом; экономический кризис, вызванный забастовкой. Отношения нужно ориентировать, т.е. указывать направление стрелки от одного термина Синтола к другому. Н-р: Роль печени в обмене сахара: печень(Е)-(2) обмен веществ (А)-(2) сахар (Е)
4) Синтаксические операторы
Система 4-х главных отношений оказывается недостаточной для интерпретации некоторых отношений. Поэтому она была дополнена некоторым числом синтаксических операторов. Их добавляют к одному из терминов синтагмы, роль которого они уточняют. Этот термин и оператор образуют предикативную синтагму, т.к. операторы в Синтоле относят к формальной категории предикатов.
Операторы ассоциативного отношения
инструментальный; op.inst;
местный ; op.loc;
цели; op.but;
признака; op. signe.
О ни обозначают одну из перечисленных функций, которую выполняет один термин синртагмы по отношению к другому, когда эта функция не может быть выведена из самой природы терминов. Н-р: благоссловение(А)- (2) вода(Е)
5) Тематика
На тематическом уровне получает выражение различная тематическая дополнительная спецификация, которую необходимо добавить к синтагматическому анализу, чтобы точнее перевести содержание документа. Каждый документ должен быть схарактезирован по рубрикам:
Тема. 2.Объект. 3. Место. 4. Время. 5.Жанр.
Фразы синтола, состоящие из синтагм, не выявляют главный предмет исследования переводимого документа. Н-р: документ 1)нервная депрессия, её лечение сном. Документ 2)различная методика проведения сна для лечения нервных болезней. Синтагма одна у обоих документов: лечение сном:
Л ечение
сном – (2) нервные болезни
ечение
сном – (2) нервные болезни
Но предмет исследования документа 1) – нервные болезни, а документа 2) – методика. Чтобы избежать этого недостатка, указывают главную тему документа в рубрике Тема.
В рубрике Объект содержится перечисление объектов, о которых идет речь. Н-р: в текстах по экспериментальной физиологии это подопытное животное; в других – это группы людей, физиологические характеристики людей.
В рубрике Место и Время содержатся географические и исторические характеристики фактов, которые излагаються в документах.
В рубрике Жанр указывается в какой форме обрабатывается автором материал исследование. Н-р: историческое исследование, эксперимент, популярное изложение.
II.Парадигматическая организация (словарь)
Словарь делится на различные поля, соответствующие различным областям науки
III. Поиск информации
1. Операции ВАРИАЦИИ (составление ПОДов)
Язык Синтола в силу своей универсальности дает возможность автоматически повышать или сокращать степень семантической точности текстов. Каждое представление документа с различной степенью точности и подробности является особым «состоянием» одной и той же системы Синтола. Варьировать точность анализа и переходить от одного состояния анализа к другому позволяют операции вариации, которые определяются следующими Состояниями:
в результате анализа остаются только термины словаря и исключаются всякие отношения между ними ( как язык дескрипторного типа).
анализ документа содержит только указание тематики
получают несколько улучшенный анализ, комбинируя тематику и КС-ва : С3=С2+С1;
к предыдущим данным анализа добавляется не интерпретированный синтаксис, а именно: между двумя словами указывают наличие или отсутствие связи без детализации;
полученные в С4 синтагмы получают «интерпретацию»; для каждой указывают одно из 4-х главных отношений синтола;
некоторые отношения С получают уточнения посредством операторов.
2. Операции МОДУЛЯЦИИ (составление ПОЗов)
Модуляции – это трансформации, которые применяются к формулировке запросов в С., чтобы ограничить или увеличить число ответов.
ДЕФОКУСИРОВКА – затрагивает тему;
Генерализация - ----- слова –цепочки;
Альтерация (медиация) --- отношения цепочки;
Вычленение (синтагма целиком – 6-е состояние).
ВЫВОДЫ (Синтол):
1) Универсален, т.к. примененный синтаксис не зависит от словаря данной научной области, т.к. в основе отношений лежат общелогические категории:
-причинно-следственные отношения;
ассоциативные ;
сравнения;
сопоставления.
2) Универсален, т.к. можно варьировать сложность синтаксиса при составлении ПОДов, исходя из различных потребностей (операция вариации (состояния)). Операции модуляци позволяют получить наряду с одним ответом на запрос целую серию дополнительных ответов (узких и широких).
Ипс аидос (ппп) [документально-фактографическая, с грамматикой]
(Пакет прикладных программ – ППП)- Аидос разработан в Германии
Составные части:
Основная – тезаурус;
систематический рубрикатор \систематика\
Профиль группы фактов;
1) Тезаурус
Тезаурус в ИПС АИДОС используется как средство для классификации информации, индексирования, накопления фонда и поиска.
ТЕЗАУРУС – список наименований понятий. Н-р: дескрипторы (нормированные) и условные синонимы (ненормированные., недескрипторы)
Дескриптор – ключевое слово, определяющее класс условной эквивалентности, в который включены условные эквивалентные и близкие по смыслу слова. Ими могут быть: специальная терминология используемой области знаний, названия приборов, устройств, числа(сроки) и нотации рубрикатора. В группе условной эквивалентности понятий дескриптором является одно из них. Остальные – условные синонимы – вводятся в тезаурус в качестве синонимов с указанием ссылок на выделенный дескриптор. Между понятиями зафиксированы парадигматические отношения, а именно : иерархии, ассоциации, эквивалентности (синонимии).
1. Иерархические отношения.
Каждые дескриптор может быть связан с выше стоящим дескриптором (старший дескриптор) и нижестоящим дескриптором (подчиненным, младшим). Иерархические отношения понимаются как родо-видовые отношения. ОБОЗНАЧЕНИЯ:
Д – дескриптор;
О – старший дескриптор;
У – младший дескриптор;
S – синонимы;
А – ассоциативный дескриптор.
Пример: Д – информационный поиск в диалоговом режиме;
О – информационный поиск;
У – пакетный информационный поиск.
2. Ассоциативные отношения. Выступают: часть-целое; причинно-следственные; противоположность; сходство (по форме, функции); пространственные и временные следования. Пример: Д- охрана окружающей среды; А – государственная культура.
3. Эквивалентности (синонимии). Синонимы: собственно синонимы; абсолютные (относительные); сокращённая форма (аббревиатура); иностранные термины.
счетно-решающее устройство
S – вычислитель;
S- компьютер;
S – устройство обработки информации.
(С) Д – ЭВМ
С
 тарший
дескриптор
тарший
дескриптор


 Дескриптор
ассоциативный д-р
Дескриптор
ассоциативный д-р






2) Систематика – систематическое разбиение специальной области на рубрики. Использование с.р. даёт существенное преимущество, т.к. информация может быть найдена не только с помощью дескриптора, но и по нотациям разбиения, которые заносятся в тезаурус. Благодаря с.р. можно упорядочить библиографию, каталог и релевантную информацию. Систематика состоит из нотаций и словесных наименований к ним (вербальных обозначений).
Нотация (код) |
Словесное наименование нотаций |
С 242.41 |
Физико-технические основы. |
3) ПГФ – средство классификации фактографической информации. ПГФ позволяет построить фактографическую систему, гарантирующую целенаправленный сбор и поиск фактографической информации, рациональную группировку фактического материала, что является важным при поиске фактографической инф-ции в больших массивах данных, дальнейшую переработку некоторых фактов в новую уплотнённую информацию.
ПГФ – совокупность описаний групп фактографических данных, которые по содержанию признаков охватывают потребность в информации. ПГФ строится из некоторого количества групп фактов. В свою очередь они разбиваются по признакам. Н-р: 1) группа фактов – наименования признака 1, наименование признака 2 и т.д.; 2) группа фактов – наименование признаков 1, 2 …; n) группа - ….
Каждая группа фактов состоит из
1. нотаций (кодов) группы фактов и признаков, входящих в её состав;
2. наименований группы фактов и её признаков;
3. числа, указывающего на количество наименований-признаков.
4.из ссылки на другие профили, имеющие смысловую взаимосвязь с данной группой (до 9 знаков).
нотация |
наименование |
Количество |
Ссылки |
050.00
-\\-.01 -\\-.02 -\\-.03 -\\-.04 -\\-.05 … -\\-.17 -\\-.18 |
Накопители на магнитных лентах (Признаки): Предприятие-изготовитель Модель Страна-изготовитель Цена -\\-
тип скорость |
6 |
003231
|
Критерий выдачи(кв)
Логика, с помощью которой осуществляется поиск информации.
К критериям выдачи мы относим прежде всего операторы булевой алгебры. В основе стратегии поиска лежит булева алгебра. Признаки поиска логически связываются между собой следующими видами связок:
+ * #
И ИЛИ НЕ
^ v -
Для расширения возможностей информационного поиска используется синтаксические указатели, т. е. указатели роли и связи, а так же расширенные с помощью синтаксических указателей виды конъюктивных связей. +Ц, +Д, +У - элементы грамматики данной системы.
Синтаксические указатели (роли и связи).
При описании содержания документа посредством дескрипторов и их синонимов можно образовывать так называемые цепочки дескрипторов, которые содержат логически взаимосвязанные признаки. Синтаксический указатель состоит из двух частей:
1)номер цепочки, в которой стоит дескриптор ( номер - это указатель связи)
2)позиционный номер дескриптора в цепочке, т. е. номер позиции в цепочке(указатель рода).
ПОЗ- список ключевых слов (здесь цепочка дескрипторов).
Логические связи.
(Конъюктивные).
" ^ " двух терминов обозначает (т.е. имеет выражение): Т1 +Т2 - в поисковом образе документа должен присутствовать как термин Т1 ,так и термин Т2 , совместное присутствие этих терминов обеспечивает релевантность рассматриваемого документа.
"Т1 * Т2" - если в ПОЗе имеется такая запись, то в ПОДе релевантными документами будут все документы, которые содержат либо Т1, либо Т2, либо оба термина. "#Т1" - использование этой связки требует, чтобы последующий термин отсутствовал в документе.
Например:
Нужно найти все документы главной темой которых являются "ИПС".Фонд документов может быть организован либо на магнитных лентах, либо на магнитных текстах. Искомые документы могут быть на любом языке кроме японского.
("ИПС" и "фонд документов" и ("МЛ" или "МД") и (не "японский язык").
(ИПС + фонд документов + (МЛ*МД)) + (#ЯЯ).
1)Соединение поисковых признаков посредством связки +Ц - обеспечивает релевантность только тех документов, которые содержат все требуемые признаки в одной и той же дескрипторной цепочке, независимо от того, в какой позиции они в этой цепочке располагаются.
2)Связка "+Р" - соединение поисковых признаков посредством этой связки обеспечивает релевантность тех документов, которые содержат все признаки одной и той же дескрипторной цепочки, и позиции которых граничат друг с другом в возрастающей последовательности.
3)Связка"+У" - соединение поисковых признаков посредством связки"+У" обеспечивает релевантность только тех документов, которые содержат все дескрипторы в одной и той же дескрипторной цепочке, а номера позиций которых являются возрастающими друг к другу.
Например, поисковый образ запроса «ИП» (Ц 01, 01) + «ИС» (02)
Это выражение требует, чтобы в ПОДе ключевое слово «информационный поиск» стояло в первой цепочке и в первой позиции, а ключевое слово «информационная система» – в той же цепочке, но во второй позиции.
Если при поиске в к.-л. Документу обнаружиться подобное расположение этих терминов, то такой документ будет удовлетворять требованиям релевантности.
Существующим расширением выдачи являются операторы значения
Р(=) М(<) MБ(<>) Б(>) МР(<=) БР(>=). За основу сравнения берется термин в запросе.
Документ является релевантным, если сравниваемое выражение равно выражению в запросе. Для расширения возможностей информационного поиска в системе «АИДОС» используется:
1) иерархия тезауруса путем включения в поиск к термину поиска ассоциативного поиска, выше стоящего и ниже стоящего дескриптора;
2) синтаксические указатели;
3) частичное сравнение (ЧС)
Суть (ЧС): дополнительно к термину запроса включаются в процессе поиска все ключевые слова, которые в начале слова имеют ту же комбинацию символов, что и в поисковом термине. Сравнение осуществляется по длине термина, указанного в запросе.
Дополнительно полученные таким образом поисковые термины связываются с помощью «V» с поисковым термином из запроса.
Запрос: ЕС (Единосистема)
С указанием проведения частичного сравнения
Дополнительно к этому дескриптору в поиск включаются все дескрипторы, которые имеют одинаковую начальную комбинацию символов.
В результате: ЕС+ЕС10+ЕС1022+ЕС20+ЕС30 (марки компьютеров)
Частичное сравнение удобно использовать в тех случаях, когда пользователя интересует информация, содержащая любые признаки определенного вида, но он не знает, какие более глубокие деления этого вида имеются в тезаурусе. При информационном поиске реализация частичного сравнения заключается в следующем: сравнивается отдельное высказывание, начиная с первого, с комбинацией символов поискового признака. Если комбинация символов, указанная в запросе, совпадает с информацией документа, то этот документ принимается в качестве релевантного.

Сравнение
4) скользящее сравнение
При скользящем сравнении отдельное высказывание документа сравнивается с комбинацией символов поискового признака, согласно его длине. Если в любой части документа находится такая же комбинация символов, то документ считается релевантным.
Для усиления критерия выдачи в «АИДОС» можно использовать библиографические характеристики документов, такие как имена авторов, название журналов, год публикации, язык документа, издательство, степень секретности.
В «АИДОС» используются специальные методы поиска информации:
1) пакетный запрос (режим «ретро»)
2) режим ИРИ (избирательное распространение информации)
3) запрос в режиме диалога
1. Пакетный запрос – этот вид поиска удобно применять там, где запрашивающему нужно получить как можно более исчерпывающую информацию определенного содержания, и он не желает проводить поиск во всем фонде документов. В результате: сколько вопросов, столько и ответов.
2. ИРИ – особый вид пакетного запроса. Он может быть использован для того, чтобы периодически доставлять пользователю новейшую релевантную информацию по мере ее поступления. Для этого в памяти системы постоянно храниться профиль, то есть профильный запрос пользователя, который периодически сравнивается со всеми вновь вводимыми и накапливаемыми в системе документами.
3. Диалоговый режим служит для оперативного получения информации. Когда краткосрочно возникающая информационная потребность возникает, которая может быть удовлетворена путем прямой связи пользователя с компьютером. Таким образом, диалог целесообразно применять, если речь идет о быстром получении специальной информации.
Система «smart»
Возглавлял группу разработчиков G.Salton. «Salton’s Magical Automatic Retriever of Text» = SMART (Современная система поиска текстов Селтона).
Это полностью автоматизированная система. Разработана в Гарвардском Университете. Эта система обрабатывает тексты документов и запросов, выраженных на ЕЯ. Система обладает набором средств для анализа содержания текстов документов с разных точек зрения. Все эти средства позволяют осуществлять поиск таким образом, что поисковые запросы, на которые получают неудовлетворительные ответы обрабатываются снова при несколько измененных условиях. Результат новой выдачи анализируется, и в зависимости от необходимости производят дальнейшие изменения запросов до тех пор, пока не будет получена требуемая информация.
Анализ документов
С точки зрения принципов анализа документов представляют интерес следующие средства, заложенные в системе «SMART»:
1. Система разделения английских слов на основы и аффиксы, которая может быть использована для сокращения вводимых текстов до основ слов.
2. Словарь синонимов – тезаурус, используемый для замены значащих слов номерами понятий, каждый из которых представляет класс основ слов близких по смыслу.
3. Иерархическая структура понятий, включенных в тезаурус, которая дает возможность для любого номера понятия найти их «родителя» (то есть подчиняющее или родовое понятие), «сыновей» (то есть подчиненное или видовое понятие) и «братьев» (понятия, стоящие на одном уровне), а также множество возможных перекрестных ссылок.
4. Структура для анализа документов
Методы статистических ассоциаций, применяемые для расчета коэффициентов подобия между словами, основами слов лил понятиями, и базирующиеся на принципе совместной встречаемости этих элементов в предложениях документа или в документах фонда.
5. Методы статистического анализа, позволяющие распознать и использовать в качестве характеристик содержания документа словосочетания, состоящие из нескольких слов или понятий, связанных между собой определенными синтаксическими связями.
6. Методы статистического распознавания словосочетаний, которые используются подобно предшествующим методам синтаксического анализа на основе предварительно созданного словаря словосочетаний, но при этом не осуществляется контроль правильности синтаксических связей между элементами словосочетаний.
7. Корреляционные способы сопоставления документов и запросов, использующие целый ряд корреляционных методов при сравнении анализируемых документов и запросов.
Стратегия поиска
Введенные в память ЭВМ документы обрабатываются без какого-либо предварительного ручного анализа путем использования целого ряда методов автоматического анализа текстов. В результате производится идентификация документов, которые в наибольшей степени соответствуют данному запросу. В системе «SMART» также используется метод автоматической модификации запроса, известный как релевантная обратная связь. При этом методе пользователю предоставляется некоторая предварительная выдача и он отмечает одну часть выдачи как полезную, а другую как бесполезную. Затем система автоматически изменяет поисковый запрос, увеличивая вес тех терминов в запросе, которые содержались в отмеченном множестве релевантных документов, одновременно уменьшается вес тех терминов запроса, которые содержались в нерелевантном множестве документов. Этот процесс сдвигает «вектор запроса» таким образом, чтобы он теснее примыкал к подмножеству релевантных документов, удаляясь от нерелевантного подмножества. Здесь работает КСС с весовыми коэффициентами. Для уменьшения числа необходимых сравнений между документами и запросами в данной системе были образованы группы взаимосвязанных документов на основе алгоритма автоматического сравнения документов. Для каждой группы документов выбирается общий соответствующий им «вектор группы» и запрос сначала сравнивается только с этими векторами групп, а затем запрос сравнивается только с теми отдельными документами, вектор группы которых показал высокое совпадение с запросом(ПОЗом).
Анализ языка
Трудности, возникающие при передаче содержания документа:
1) слова, которые выполняют синтаксические функции, но непосредственно не способствуют определению информационного содержания документа, должны быть исключены. Например: союзы, предлоги…
2) синонимы нужно распознавать
3) новые слова использовать в нескольких различных значениях в зависимости от контекста.
Military base – военная база
Lamp base – цоколь лампы
4) в ЕЯ часто применяются косвенные ссылки, когда местоимения или собирательные имена существительные используются для отсылки к словам, ранее упомянутым в тексте. Идентификация таких слов часто вызывает трудности.
5) между словами могут существовать отношения, которые в тексте содержаться не явно, но могут быть выведены из контекста или из других ранее проанализированных текстов.
6) значения многих слов могут изменяться или даже создаются новые слова
Например: милимикросекунда = наносекунда
Любая система анализа содержания текстов должна включать методы последовательной нормализации языка. Один из наиболее эффективных путей обеспечения такой нормализации связан с соответствующим образом построенными словарями.
1) Словарь отрицаний (Стоп-словарь)
Содержит термины, использование которых запрещено для целей анализа содержания.
2) Тезаурус (словарь синонимов), который для каждого входа словаря определяет одну или больше синонимичных категорий или классов понятий.
3) Словарь словосочетаний, которые используются для определения наиболее часто встречающихся комбинаций слов (называемых словосочетаниями). Такой словарь может повысить эффективность анализа содержания документов, выделяя для идентификации содержания однозначные словосочетания, вместо 2 или более неоднозначных компонентов.
Например: программирование, язык –
является менее определенным, если выступают отдельно, чем если исп. «язык программирования»
4) Иерархическая организация терминов и понятий, позволяющая для каждого определенного входа словаря найти более широкие понятия, идя вверх, или узкие, идя вниз. Например, для такого понятия как синтаксис можно получить более широкое понятие «язык» или более узкое – «пунктуация».
Словари не полностью устраняют неоднозначность языка, но помогают устранить влияние многих нарушений норм языка, что значительно повышает эффективность работы ИПС.
Структура словаря синонимов
Например:
410 anneal (закалять)
strain
.
.
413 capacity (емкость сопротивления)
impedance (полное сопротивление)
persistence
Классы понятий представлены трехразрядными номерами и отдельные входы показаны под каждым номером понятия. Во второй части тезауруса термины приведены в алфавитном порядке. В средней колонке располагается номер понятия, а третья колонка состоит из одного или более трехразрядного синтаксического кода, который присваивается словам для использования их при синтаксическом анализе.
Например:
Boundary 524 070
Broke 380 134 104
Тезаурус основ слов и список суффиксов
Нулевой тезаурус – тезаурус основ слов (или нулевой тезаурус) состоит из основ слов, входящих в типовой фонд документов. Против каждой основы стоит порядковый номер. Основы слов могут быть получены из полных слов отделением суффиксов. Для этой цели создается словарь суффиксов.
Словарь суффиксов
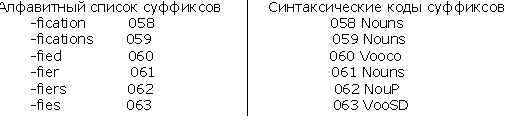
Каждый суффикс приведен с порядковым номером и с одним или более синтаксическим кодом, которые могут быть использованы, если необходимо объединить основы слов и суффиксы вновь в (новые) слова.
Синтаксические коды – неполные наименования частей речи, которые должны быть объединены с дополняющими кодами, приписанными к основам слов для определения соответствия суффиксам основ. Например, такой частичный код как 0Т10 из словаря основ будет объединен с кодом из списка суффиксов вида Vooso для формирования полного кода (0Т10+Vooso=VT1S0 – в этом случае полный код означает: переходный глагол с одним дополнением в 3 лице ед.числе. В системе SMART словари словосочетаний основаны на совместной встречаемости понятий тезауруса, а не слов текста.
Для обнаружения словосочетаний применяются 2 основные стратегии.
1) словари статистических словосочетаний базируются на алгоритме обнаружения словосочетаний, который принимает во внимание только статистические характеристики совместной встречаемости словосочетаний. При этом не делается никакой попытки обнаружить какие-либо конкретные синтаксические связи между компонентами.
2) с другой стороны словарь синтаксических словосочетаний включает не только нахождение соответствующих компонентов словосочетаний, но также информирует об отношениях синтаксической зависимости, которые должны учитываться при распознавании словосочетаний. Например: если нужно обнаружить связь между понятиями «program» и «language», то любые комбинации этих понятий (такие как «languages and programs», «programming languages») были бы признаны правильными в словаре статистических словосочетаний. С другой стороны, имеющееся в синтаксическом словаре дополнительное ограничение требует, чтобы понятие, соответствующее слову «program», было синтаксически зависимо от понятия «language». Это исключает такое словосочетание, как «languages and programs». Но допускает словосочетание «programming languages». В словосочетаниях разрешается до 6 компонентов.
Иерархия понятий
В системе анализа содержания иерархическая классификация слов и основ слов может быть использована как для идентификации информации, так и для поиска. В систему SMART включена иерархия номеров понятий, а не слов текста. Широкие, т.е. более общие понятия, соответствующие корням иерархического дерева, располагаются в левой части системы, а более узкие – в правой.
Например,

Понятие 270 – корень дерева. Имеет 4 более низких понятия. Непрерывная линия – сыновья (род - вид). Пунктирная линия – перекрестные ссылки (общие виды отношений).
Принципы построения тезауруса в системе smart
Ни одно редко встречающееся понятие не следует включать в тезаурус. Термины слишком общего значения с высокой частотой встречаемости также должны быть исключены из словаря, т.к. они снижают эффективность поиска. Незначащие слова должны быть тщательно изучены пред включением их в список слов, предназначенных для исключения.
Например, слово «hand» должно быть включено в тезаурус по биологии, но его не следует включать в таких выражениях: on the other hand.
У неоднозначных терминов должны быть закодированы только те их значения, в которых они встречаются (field – «поле», «область» относится к понятию subject area – предметная область, а с другой стороны по его специальному значению в алгебре, поэтому «field» со значением «patch of land» не следует включать в мат. словарь). Г.Селтон «Автоматическая обработка, хранение и поиск информации» = G.Selton «Automatic Information Organizationand Retrieval».
Особенности фактографических информационно-поисковых систем(фипс)
Источником информации для ДИПС и ФИПС является документ, но при составлении ПОД для ДИПС используется не сам документ0, а его реферат. Для ФИПС исходным материалом может быть только сам документ (использование реферата исключено полностью). Применительно к ФИПС понятие ПОД полностью отсутствует в его привычном смысле, т.к. документ с точки зрения его содержания не рассматривается. Фактически ПОД ФИПС складывается из поисковых образов отдельных фактов, например: описание структур соединений и их свойств (в химической области).
Фактографический поиск должен обеспечить полное (100%) отсутствие «шума», в противном случае ФИПС не будет отвечать своему назначению.
Прежде всего высокая точность информационного поиска достигается благодаря отличительным особенностям словаря системы: преобладание спец. терминов. Включение таких терминов в словарный состав ИПЯ тем более необходимо, т.к. помимо задач накапливания информации и ее поиска перед ФИПС стоит задача также и синтеза информации, в ходе решения которой эти понятия могут потребоваться.
ДИПС же стремится избавиться от узкоспециальных терминов, т.к. это ведет к большому росту словаря ИПЯ. Ограничение же словаря в ФИПС ведет к потере информации. ФИПС работает с определенными массивами элементарных сообщений, под которыми подразумевают наименование объекта с приписанными ему признаками и их значениями.
Способы представления информации в фипс
Наиболее широко распространенным способом представления информации в ФИПС является:
1) объектно-характеристические таблицы (ОХТ) с двумя кодами. На одном входе перечисляются объекты, а на другом – наименование характеристик (св-в, признаков этого объекта). Конкретные значения (словесные или числовые) записываются на пересечении строк и столбцов. Такой способ представления информации возможен при бинарном виде отношений.
2) систему подобных отношений между объектами и характеристиками можно представить в виде иерархических деревьев, вершинам которых будут соответствовать понятия (объекты или характеристики), а дугам – отношения.
3) еще один подход к созданию ИПЯ ФИПС основан на стандартных анкетах. Особенностью анкеты (в отличие от ОХТ) является то, что в анкете значение некоторых признаков представляет собой числовой интервал (возраст). Это означает, что для заполнения анкеты надо не просто поставить какое-то количество этих признаков, которые попадают в интервал значений.
Список конкретных значений признаков открытый : по мере пополнения информационных фондов в список могут вводиться новые дополнительные значения. Такая форма анкет значительно проще, т.к. не имеет никаких ограничительных признаков.
Автоматизированные фипс (афипс)
Минимальной фактографической единицей является факт или триада – объект, свойство, значение. Табличное представление факта – та структура, где строки представляют объекты, столбцы – параметры объектов, а на их пересечении находятся значения этих параметров для соответствующих объектов.
Факты классифицируют по разным основаниям:
1) простые факты и сложные, являющиеся совокупностью простых;
2) исходные факты и синтезированные, получающиеся путем преобразования сложных;
3) числовые факты, значения которых представлены числами, и нечисловые, значения в которых представлены регламентированными словесными конструкциями. Фактографическая информация в АФИПС представлена в виде базы данных.
База данных – совокупность взаимосвязанных данных, отображающих заданный набор характеристик объектов (параметров) и отношений между ними.
Банк данных – способ организации АФИПС, представляет собой совокупность одной или нескольких взаимосвязанных баз данных, а также программно-математических и языковых средств управления ими, обеспечивающих высокую степень автоматизации процессов ввода-вывода, поиска, обработки и коррекции фактографических данных, удобства взаимодействия пользователя с системой и возможность доступа к данным.
Программное обеспечение в АФИПС представлено пакетом прикладных программ (ППП).
Пакет прикладных программ (ППП) – комплекс программ, работающих под управлением программы-монитора, предназначенный для решения отдельного класса задач, близких друг к другу по содержанию или по применяемым методам.
Программа-монитор – часть управляющей программы операционной системы, которая реализует самоуправление работой всех компонентов ППП.
АФИПС относится к смешанным системам типа «человек – машина», в которых человеку отводятся функции творческого характера, а звено «машина – ИПС» рассматривается как средство организации рутинных процессов.
По степени автоматизации АФИПС делятся на системы с автоматизированным поиском и вводом информации
2) с автоматизированными процессами ввода-вывода, поиска, коррекции и синтеза информации.
Особое место в АФИПС занимает процедура автоматизации индексирования документов и запросов.
Автоматизация индексирования документов в афипс
Существующие методы автоматического индексирования делят на 3 группы:
1) дериватное индексирование (индексирование извлечением)
2) приписное индексирование
3) автоматическая классификация
1. При индексировании извлечением ЭВМ анализирует лексический состав текстов и выбирает из текстов те слова и их сочетания, которые удовлетворяют заранее установленным критериям.
2. При приписном индексировании ЭВМ сравнивает лексический состав текстов с индексными терминами, предварительно полученной классификационной схемы, и приписывает документам одну или несколько релевантных предметных рубрик в соответствии с установленными формальными критериями.
3. Метод автоматической классификации включает автоматическое построение ИПЯ и автоматическое приписное индексирование. При автоматическом построении ИПЯ система устанавливает основные тематические группы терминов на основании статистического анализа частоты их употребления в заданном массиве документов.
Автоматическое индексирование запросов
Автоматизированное индексирование запросов выполняется теми же 3 методами, но при индексировании запроса производится его усиление. Под усилением понимают дополнение к терминам ПОЗа совокупности близких по смыслу терминов. Как правило, полную автоматизацию процедуры индексирования запроса при проведении усиления осуществить не удается, поэтому на экран дисплея выводятся фрагменты тезауруса, дающие возможность пользователю самому выбрать соответствующие термины для расширения запроса.
Экспертные системы (ЭС). Системы принятия решений.
Отличие ЭС от ИПС – ЭС работают с базами знаний, а не с базами данных, следовательно, возникает проблема в создании способа представления этих знаний. Также отличие в том, что ИПС выдает ту информацию, которая в ней заложена, а ЭС выводит новую информацию.
ЭС – человеко-машинная система, состоящая из:
базы знаний (БЗ) – совокупность знаний, описанных с использованием выбранной формы их представления
механизм вывода – логика системы – обеспечивает манипулирование знаниями при решении прикладных проблем
![]() , ч – человек
, ч – человек
Характерная особенность ЭС, отличающая их от традиционных ИПС, - использование нового вида информации – знаний. Знания – хранимая в ЭВМ информация, формализованная в соответствии с определенными структурными правилами, которые ЭВМ может использовать при решении проблем по таким алгоритмам как логические выводы. Знания – обычно, факты (классы объектов)+взаимосвязи между ними. Формализм описания такого рода знаний – представление знаний, а компонент, использующий для решения проблем знания экспертов, описанных в специальной форме представления – механизм вывода.
Представление знаний – средство описания знаний человека.
Основные способы представления знаний:
продукционные правила
семантические сети
логика предикатов
модель доски объявлений (классной доски)
фреймовые системы
ПРОДУКЦИОННЫЕ ПРАВИЛА (ПП)
Один из наиболее простых. В таких ЭС все знания представлены описаниями в форме ЕСЛИ–ТО. Часть ЕСЛИ – посылка, ТО – вывод.
если А1,А2…Ап то В
Это означает, что если все условия А1,А2…Ап истинны, то посылка В тоже истинна.
Продукционные системы – системы обработки знаний, использующие представление знаний продукционными правилами.
Структура продукционной системы:
база правил – область памяти, содержащая базу знаний – совокупность знаний, представленных в виде ЕСЛИ–ТО
глобальная база данных – область памяти, содержащая факты, описывающие вводимые данные и состояние системы
интерпретатор правил – механизм вывода, который является тем компонентом системы, который формирует заключения, используя базу правил и базу данных
Рассмотрим правило (..)
если (1) y является отцом x (А1)
(2) z является братом у (А2) n=2
то z является дядей x (В)
Если n=0, то знание состоит только из вывода – факт.
Механизм вывода связывает знания воедино, а затем выводит из последовательности знаний заключение.
Положим, что в базе знаний вместе с описанными ранее знаниями содержатся и такие:
если z является отцом x
z является отцом y
x и y не являются одним и тем же лицом
то x и y являются братьями, сестрами или братом и сестрой
Петр является отцом Ивана
Петр является отцом Николая
Иван является отцом Василия
Из этого можно вывести заключение, что Николай – дядя Василия.
Иван-Василий-Петр (подставляем в x,y,z) можно вывести уже сделанное заключение и полученные ранее результаты. Эта полностью формализованная процедура, использующая такие методы как согласование образов (устанавливается, совпадают ли между собой 2 формы представления), поиск в базе данных, возврат (возврат к исходному при неудаче решения) – механизм вывода.
ФРЕЙМОВЫЕ СИСТЕМЫ
Идея принадлежит Марвину Мински.
Фрейм – структура данных для представления стереотипной ситуации. Его можно представить в виде сети из узлов и связей между ними. Каждый узел – определенное понятие, которое может или не может быть задано в явном виде.
Терминалы – не заданные в явном виде узлы. Они образуют нижние уровни графовой структуры, когда на верхних – понятия, которые всегда справедливы в отношении представленной данным фреймом ситуации. Следовательно, эти узлы должны быть заполнены конкретными данными, представляющими собой их возможные задания в процессе приспособления фрейма к определенной ситуации из того класса ситуаций, которые представляет данный фрейм. Каждый терминал может устанавливать условия, которым должны отвечать их задания: простые условия устанавливаются маркерами, которые могут, например, потребовать, чтобы заданием терминала было какое-либо лицо, предмет, элементарное действие или указатель на какой-либо другой фрейм, представляющий собой другую, более частичную ситуацию – субфрейм. Таким образом, совокупность заданных в явном виде узлов-понятий образует основу для «понимания» любой конкретной ситуации.
Понимание происходит путем конкретизации терминалов и согласования возможных для каждого из них понятий со вполне определенной обстановкой в окружающем мире.
В своей теории Мински не проводит границы между теорией человеческого мышления и теорией построения систем искусственного интеллекта. Он считает, что процессы человеческого мышления базируются на хранящихся в его памяти многочисленных заполненных структурах данных – фреймах, с помощью которых человек осознает зрительные образы (фреймы визуальных образов), понимание слова (семантические фреймы), рассуждения, действия (фреймы-сценарии). Процесс понимания при этом сопровождается активизацией в памяти соответствующего фрейма и согласовании его терминальных вершин с текущей ситуацией.
Фрейм-сценарий – последовательность действий, описывающих часто встречающуюся ситуацию. В этой последовательности действий используется принцип казуальной связи, то есть результатом каждого действия являются условия, при которых может произойти следующее действие. Каждый сценарий имеет своих исполнителей ролей, различные интерпретации, отражающие точки зрения различных исполнителей ролей, следовательно, сценарий – система фреймов.
ПРИМЕР
Сценарий посещения ресторана представлен с точки зрения посетителя.
Сценарий: РЕСТОРАН
Роли: посетитель
официантка
шеф
кассир
Цель: получить пищу, чтобы утолить голод
Сцена I: Вход
1. Войти в ресторан
2. Глаза направить туда, где есть пустые столы
3. Выбрать, где сесть
4. Направиться к столу
5. Сесть
Сцена II: Заказ
6. Получить меню
7. Прочитать меню
8. Решить, что хочешь заказать
9. Сделать заказ официантке
Сцена III: Еда
10. Получить пищу
11. Съесть пищу
Сцена IV: Уход
12. Попросить счет
13. Получить чек
14. Направиться к кассиру
15. Заплатить деньги
16. Выйти из ресторана
В каждом сценарии средства выполнения могут варьироваться по обстоятельствам. Например, в сцене 2 заказ модно сделать так:
письменно
устно
жестами
В сцене 4 выплата денег может быть осуществлена так:
кассиру
официантке
словами «включите в мой счет»
Одним из множества возможных способов формализации фрейма-сценария предполагается представление его в виде сети или иерархической структуры. Узел самого верхнего уровня сети отождествляется с заголовком сценария. Дочерние варианты этого узла – терминалы фрейма.
Фрейм-сценарий «РЕСТОРАН» изображен в виде графической структуры И/ИЛИ.
Каждой из 4 сцен соответствует вершина И, вершина графа – заголовок сценария. Первые 2 вершины (Вход и Заказ) имеют по 2 вершины ИЛИ, а остальные – по одной. Первые 2 вершины ИЛИ первых двух вершин И соответствуют действию, совершенному при утвердительном ответе на вопросы «А если посетитель уже в ресторане?» и «А если заказ сделан другом?» В этом случае действия не нужны и вершины пусты. Все остальные вершины, так же как и их материнские вершины соответствуют входу, еде, заказу, уходу. Каждая из этих вершин имеет вершины и соответствует действиям, помеченным в сценарии арабскими цифрами. Вершины 9 и 10 имеют по 3 дочерние вершины ИЛИ, соответствующие вариантам заказа и уплаты денег.

ПРЕДСТАВЛЕНИЕ ЗНАНИЙ СЕМАНТИЧЕСКИМИ СЕТЯМИ (с. с)
В с.с знаки имеют интерпретацию, а отношения между ними образуют сеть, воспроизводящую определенные стороны связей между понятиями в психике человека.
Язык с.с включает множество базовых понятий, каждое их которых характеризуется своими признаками и их значениями, например:
техникум – понятие, определяемое 2 признаками (переменными):
«дает специальное образование»
«готовит специалистов для»
1 признак может иметь 2 значение – среднее и высшее
2 признак имеет значения – для производства, для народного образования
Для техникума 1 признак – среднее, 2 признак – для производства.
пединститут
Значения тех же признаков иные – высшее и для народного образования соответственно.
Совокупность понятий, которая вносится в конкретную сеть, зависит от целевого назначения системы или ее конкретного использования. Если она предназначена для ответов на вопросы о состоянии образования в стране, то она должна содержать понятия «школа, студент, ВУЗ», то есть совокупность понятий должна быть проблемно ориентирована.
Язык содержит базовое множество отношений. Входящие в него отношения связывают между собой элементы среды или их кодовые имена (элементы языка):
часть-целое
действие-объект
действие-время
действие-место
Система базовых отношений (в отличие от системы базовых понятий, которая проблемно ориентирована) носит универсальный характер, то есть мало зависит от предметной области. Анализ текстов на русском, английском и итальянском языках показал, что число базовых отношений, посредством которых можно выразить любые отношения ЕЯ приблизительно равно 200.
Семантический язык содержит и правила оперирования базовыми отношениями, позволяющие посредством четко определенных операций формировать более сложные отношения. Итак, семантические языки содержат:
проблемно-ориентированную совокупность базовых понятий
универсальный слой базовых отношений и производных от них
Они позволяют зафиксировать в памяти системы базовое множество знаний, необходимое для формирования «модели мира». Эти семантические языки позволяют посредством семантических сетей представить неязыковые знания. Форма выражения семантического языка - с.с, т.к понятия и отношения между ними можно описать сетью, состоящей из узлов и дуг. Узлы – сущности и понятия, дуги – их отношений. Все узлы и дуги снабжены метками, показывающими, что именно они описывают. Такой формализм представления знаний - с.с.
Системы искусственного интеллекта формируют искусственную модель мира, используя семантический язык. Этот процесс начинается со сбора информации о реальной среде. Далее особый блок – блок селекции – выделяет предметы, соответствующие понятиям, определяемым признаками, и их значениям. Например, если речь идет об управлении в порту, то блок селекции находит различные предметы, склад, контейнеры в определенный момент времени.
Другой блок – пространственной ориентации – фиксирует их координаты, то есть посредством базовых и производных отношений описывается взаимное расположение предметов (находится га, внутри, под). Таким образом создается моментальный снимок ситуации на управляемом объекте.
Логический блок на основании правил комбинирования базовых отношений порождает новые отношения, специфические для каждой предметной области. При наступлении нового момента времени исходная модель первого уровня сменяется новой – другим «моментальным снимком». Информация о предшествующем моменте времени не стирается, а передается в память. Таким образом, в памяти находится информация о последовательно сменяющихся состояниях «внешнего мира», то есть управляемого объекта. Это дает возможность поиска закономерных связей в изменениях, происходящих во времени. Такой поиск с семантических системах является функцией особого блока – блока гипотез. Процедура формирования гипотезы на основе причинно-следственной связи выглядит так:
В определенный момент времени в определенном месте есть предмет Р1 или происходит событие С1, а в следующий момент времени в этом месте появляется Р2 или происходит С2. Факт следования вторых за первыми записывается в памяти и если при повторных появлениях Р1 за ним НЕ следует Р2, то связь из памяти стирается. В противном случае можно полагать, что Р1 является причиной Р2. После заранее предусмотренного числа повторений связь между двумя конкретными предметами «осознается», то есть фиксируется определенным знаком и вносится в базу знаний о мире. Таким образом, место модели первого уровня, которая является моментальным снимком ситуации, то есть содержит только текущие данные об объекте, заменяется моделью второго уровня, в которой представлены знания об объекте. На следующих уровнях происходит последующее обобщение модели, классификация предметов и связей, приписывая переменным кванторов всеобщности и существования. Таким образом, структура представления знаний в виде с.с. позволяет создать в экспертной системе «внутреннюю модель» внешнего мира, выполняя следующие операции:
пополнение знаний о мире (перестройка модели)
обобщение собираемой информации и фиксация на основе этого закономерных связей (причина - следствие)
формирование новых понятий определенного типа
Для описания структуры данных в системах подобного типа используют язык ЛИСП. В отличие от фрейма, в с.с. узлы заполнены, во фреймах же они пусты для новой информации. В с.с. все уровни полностью фиксированы, а во фреймах нижние звенья иерархии (терминалы) содержат условия-запросы, ответы на которые формируются в процессе взаимодействия системы с ситуацией. С.с. стабильны.
МОДЕЛЬ ДОСКИ ОБЪЯВЛЕНИЙ (МДО)
Ряд практических задач можно решить лишь разбив их на подзадачи, каждой из которых соответствует некоторая подобласть некоторой предметной области, где решается именно эта подзадача. В экспертных системах, предназначенных для решения подобных задач, находит применение так называемая «архитектура доски объявлений». МДО является способом организации и использования, а не способом представления знаний. Фактически, МДО является одной из развитых модификаций продукционной системы. В этой модели для каждой отдельной проблемы, которые в совокупности составляют единое целое, имеется соответствующее множество знаний. Все множества через общую рабочую область памяти – доску объявлений – управляются так, что все знания используются согласованно, как единое целое. Такие отдельные множества знаний – источники знаний (ИЗ), каждый из которых строится как продукционная система. Они не вызывают один другого и обычно не содержат знаний друг о друге. В то же время они действуют совместно, так как вносят элементы решения в общую задачу, влияя на поведение друг друга путем анонимного отклика на информацию, записанную на доске объявлений. Для эффективной реализации процесса обработки знаний в целом система содержит механизм управления допуском ИЗ в соответствии с текущей ситуацией. Этот механизм управления – планировщик системы – анализирует сложившуюся ситуацию, выносит решение о том, какой уровень обработки должен обладать наибольшим приоритетом и осуществлять планирование запуска ИЗ.
Этот способ реализуется в экспертной системе «Hearsay». Это система распознавания речи. Для нее характерна многоступенчатая иерархическая структура ИЗ, каждый из которых распределен в своей предметной области и принадлежит к различным иерархическим уровням. Задача, решаемая системой, - интерпретация исходных данных, содержащихся в речевом сигнале, чтобы обеспечить понимание речи. По мере перехода от !!!!!!!!!!!!! менее абстрактных иерархических уровней к высшим, более абстрактным, меняется характер интерпретации данных, последовательно идентифицируются параметры речевого сигнала, сегменты сигнала, слогов, слова, последовательности слов и фраз.
При этом элементы решения задач, полученные на нижних иерархических уровнях, служат исходными данными для высших иерархических уровней, и решение, принятое на наивысшем уровне иерархии, - полное решение задачи.
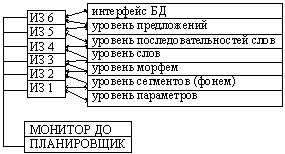
ИТАК: сейчас экспертные системы называют электронными суперкомплексами. Основные задачи, решаемые ими:
распознавание речи
распознавание образов
обучение (в том числе иностранным языкам) – экспертные обучающие системы – ЭОС.
Автоматизированные обучающие системы(аос)
Чтобы повысить эффективность обучения, необходим индивидуальный подход. Системы обучения и контроля знаний предназначены для индивидуального контроль знаний при частичной автоматизации одной или нескольких функций преподавателя, направленных на организацию и проведение учебных занятий.
ОБЛАСТЬ ПРИМЕНЕНИЯ АОС – все виды занятий, кроме лекционных (на лекциях должен быть эффект обратной связи).
В зависимости от характера учебного занятия можно выделить:
-- обучающие программы, в процессе работы которых обучаемые получают новые знания
-- репетирующие программы – направлены на закрепление определенных знаний и навыков обучаемого
-- контролирующие программы – обеспечивают проверку уровня знаний, умений, навыков и оценивают его
АОС – человеко-машинный комплекс, функционирующий в режиме разделения времени и предназначенный для управления процессом индивидуального обучения.
Основным режимом работы ЭВМ в диалоговой АОС является режим разделения времени, т.е. способ организации учебного процесса, при котором некоторое число независимых абонентов имеет в процессе решения задач непосредственный, постоянный и одновременный доступ к ЭВМ.
В зависимости от характера одновременно решаемых задач АОС реализует однопрограммный и многопрограммный режимы обучения.
Однопрограммный режим – режим, при котором один пользователь или группа пользователей работают под управлением одной обучающей и контролирующей программы.
Многопрограммный режим – обеспечивает режим управления работой группы обучаемых, в которой каждый обучаемый или несколько обучаемых изучают свой курс, заложенный в обучающей программе.
Структура АОС
АОС состоит из подсистем, которые можно разделить на функциональные и обеспечивающие.
Функциональные системы – связаны с основной целевой функцией системы. Например: подсистемы обучения, контроля, самостоятельной работы и т.д.
Обеспечивающие системы – создают необходимые условия для реализации функциональных подсистем и системы в целом.
Основными из обеспечивающих подсистем являются:
1). Техническая – основным техническим средством АОС является ЭВМ (ПК), снабженная аппаратурой хранения, отображения и ввода информации.
2). Программная – представлена различными программными средствами: совокупностью программ, обеспечивающих ввод .хранение, обработку и предъявление обучаемому учебной информации с помощью средств отображения.
3). Учебно-методическая - ????
Примером АОС является система программирования обучающих курсов (СПОК). Бывает СПОК-ВУЗ и СПОК-ШКОЛА.
СПОК-ВУЗ представляет собой специализированный пакет прикладных программ, ориентированных на диалоговое обучение по широкому кругу учебных дисциплин с помощью АОС на базе серийных ЭВМ. С помощью СПОК-вуз могут реализовываться основные задачи учебной работы в высших учебных заведениях:
-- обучение (с текущим контролем)
-- контроль знаний (текущий, рубежный, итоговый)
-- самообучение и самоконтроль
-- самостоятельное повторение учебного материала и закрепление приобретенных навыков
Средством общения обучаемого с системой СПОК является специальный язык – язык обучающих курсов (ЯОК).
Ответ на запрос обучаемого строится из элементов языка и подвергается в процессе работы АОС контролю на соответствие синтаксису и семантике.
Синтаксический контроль проверяет правильность следования символов, составление из них слов и предложений, разрешаемых правилами грамматики входного языка.
Семантический контроль устанавливает смысловое содержание ответа, его соответствие смыслу поставленного вопроса.
Язык обучающих курсов (яок)
Алфавит ЯОК включает 3 группы символов:
-- буквенные символы (все прописные буквы лат. алфавита от A до Z)
--цифровые символы(0..9)
--специальные символы ( , *).[] + \)
АУК(автоматизированный учебный курс) на ЯОК представляет собой последовательность операторов, обрабатываемых и выполняемых СПОК в определенной последовательности.
Анализ сообщений
Основной принцип анализа сообщений – сопоставление сообщений с заранее предусмотренными эталонами. Для описания анализов ответов в ЯОК предусмотрены специальные операторы(операторы второго уровня)
Коды операций и операции ЯОК:
делятся на 3 уровня
1 уровень:
--RD(read) – используется для выдачи порции обучающей информации
--QU(question) – для формирования вопроса/задания
--TY(type) – для выдачи реплик по поводу ответа обучаемого
--UN(unknown) – содержит текст, который будет выдан обучаемому, если его ответ не совпал ни с одним из эталонов, заданных в предыдущих операторах анализа ответа
2 уровень(операторы анализа сообщений):
--CA(correct answer) – оператор эталона ответа
--СВ – альтернативный правильный ответ
--WA(wrong answer) – предусмотренный неправильный ответ
--WB – альтернативный неправильный ответ
3 уровень(служебные операторы):
--AD – сложить
--SB – вычесть
--MP – умножить
--LD – загрузить
--FN – функция
Например:
RD учим таблицу умножения
QU 2 х 2 = ?
CA 4
TY молодец! (переход)
CB четыре
TY правильно, быстрее отвечай цифрой (переход)
CB four
TY правильно, быстрее отвечай цифрой (переход)
CB vier
TY правильно, быстрее отвечай цифрой (переход)
WA 3
TY неверно, подумай
WB 5
TY неверно, еще раз
…
UN неверно, есть еще попытка
UN -----//-----
UN смотри…
QU 2 х 3 = ?
Лингвистический пример: (множественный выбор)
Проверка знаний лексики англ. яз.
QU что означает слово ‘complexion’?
набор вещей
цвет лица
фигура
CA 2
TY молодец (переход)
CB цвет лица
TY правильно (переход)
WA 3
TY неправильно
Тестовый метод:
Завершение фраз
QU дополните предложение «Ann … 17 years old.»
CA is
WA are
Автоматизированный учебный курс (аук) по иносранным языкам
Представление знаний в АУК
При разработке АУК по иностр.языкам одной из главных становится проблема представления знаний. АУК, являясь искусственной системой, включает в себя в качестве одного из ведущих компонентов модель коммуникативной деятельности. Эта модель описывает коммуникативную ситуацию, ее предметную область, структуры речевого взаимодействия в данной ситуации, языковые средства, используемые при решении задач в комплексном обучении. Средством построения модели коммуникативной деятельности в комплексном обучении служат ФРЕЙМЫ.
Фрейм – это совокупность определенным образом структурированных данных, кот. представляет стереотипную ситуацию.
Фрейм – определенным образом организованная совокупность некоторых данных (языковых и неязыковых), минимально необходимых для представления коммуникативной ситуации.
Фрейм является инструментом моделирования коммуникативной деятельности в АУК.
Рассмотрим коммуникативную ситуацию с точки зрения ее составляющих. Она включает основные компоненты:
--объекты речевой деятельности(предметная сфера)
--субъекты речевой деятельности(2 партнера по общению)
--языковые средства речевой деятельности и продукт взаимодействия партнеров в результате коммуникативной деятельности – диалога.
Согласно этой структуре для построения модели коммуникативной системы необходимы такие фреймы:
Фрейм ситуации Ф1
Фрейм предметной области Ф2
Фрейм языковых средств Ф3
Сценарий диалога (речевого взаимодействия партнеров) Ф4
Т.к. речь идет о моделировании коммуникативной системы(КС) для учебных целей, необходим еще один фрейм – фрейм учебных средств, использующийся для управления обучением Ф5
Ф1 – содержит общее описание КС (тема, условия, роли и характеристики партнеров, цели и мотивы их речевой деятельности)
Ф2 – представляет содержание КС (набор основных объектов с их характеристиками – атрибутами)
Ф3 – включает языковые средства, необходимые для обеспечения речевой деятельности в КС
Ф4 – описывает эталоны речевого поведения партнеров в данной КС (наиболее характерную, типовую структуру диалога с учетом характеристик партнеров)
Ф5 – содержит инструкции, средства коррекции, формулы поощрения
Фреймы объединены в единую систему, обеспечивающую взаимодействие между входящими в нее компонентами
ПРИМЕР:
Рассмотрим систему фреймов в КС «Покупка хлеба»
Ф1
Тема |
Покупка хлеба |
Условия |
Магазин «Хлеб» |
Партнеры |
Покупатель (учащийся), Продавец (компьютер) |
Цель |
Приобрести хлеб определенного сорта, качества, количества |
Мотив |
Потребность в хлебе, выраженная в просьбе одного из членов семьи |
Характеристики партнеров |
Оба вежливы, используют разговорную форму литературного языка |
Ф2 – фрагмент фрейма хлеб
Класс |
Подкласс |
Наименование |
Вид |
Сорт |
Цена |
Единица |
Качество |
Продукты питания |
Хлебо-булочные изделия |
Хлеб |
Черный |
Бородинский |
1-50 |
Буханка |
Свежий |
|
|
|
|
Украинский |
1-86 |
Половина |
сегодняшний |
|
|
|
|
Изюминка |
1-10 |
Четверть |
Несвежий |
|
|
|
Белый |
Батон подмосковный |
0.95 |
|
Черствый |
|
|
|
|
Булка городская |
1-00 |
|
вчерашний |
|
|
|
|
Кирпичик |
1-20 |
|
|
Ф3 – фрейм состоит из 2-х частей:
универсальные средства, используемые в различных сферах общения (тематически немаркированные):
а). Формулы приветствия (Здравствуйте, Добрый день)
б). Формулы выражения благодарности (Благодарю, Спасибо)
в). Формулы выражения просьбы (Мне нужно, Я бы хотел)
г). Формулы выражения вопроса о наличии (У вас есть…)
2. ситуативно-тематические, характерные только для определенной ситуации (маркированные):
а). Формулы, выражающие вопрос о количестве (сколько буханок, целую или половинку)
б). Формулы, выражающие вопрос о цене (по чем, сколько стоит)
Ф4 – фрейм-сценарий диалога, состоит из 2-х частей, описывающих деятельность обоих партнеров по общению (покупатель – продавец)
ДЕЯТЕЛЬНОСТЬ РЕЧЕВОЕ ДЕЙСТВИЕ
ПОКУПАТЕЛЬ
1. Зайти в магазин, подойти к продавцу |
Поздороваться |
2. Выяснить, имеется ли хлеб нужного сорта |
Задать вопрос о наличии хлеба нужного сорта |
3. Если имеется, поинтересоваться качеством |
Задать вопрос о количестве |
4. Если не имеется, выяснить, имеется ли какой-либо другой сорт хлеба |
Задать вопрос о наличии какого-нибудь другого сорта хлеба |
5. Если этот сорт подходит, то повторить 3) |
Задать вопрос о количестве |
6. Попросить нужное количество |
Выразить просьбу о количестве |
7. Выяснить, сколько стоит хлеб |
Задать вопрос о цене |
8. Расплатиться |
Назвать передаваемую сумму |
9. Закончить диалог |
Выразить благодарность, попрощаться |
ПРОДАВЕЦ
1. При появлении покупателя |
Поздороваться, задать вопрос что нужно |
2. На вопрос о наличии хлеба |
Ответить в соответствии с ассортиментом |
3. На вопрос о качестве |
Сообщить качество |
4. Если запрашиваемого хлеба нет |
Сообщить, какой имеется |
5. На вопрос о качестве другого сорта хлеба |
Повторить # 3 |
6. На просьбу об отпуске определенного количества |
Отпустить со словами пожалуйста |
7. На вопрос о цене |
Сообщить цену |
8. На сообщение о передаваемой сумме |
Поблагодарить |
9. На выражение благодарности и прощание |
Попрощаться |
Ф5
Поощрения: Хорошо, Прекрасно
Формулы привлечения внимания к ошибке: Что вы сказали? Повторите еще раз
Структура аук
АУК является системой, включающей следующие компоненты:
1). Комплекс тестов служит для установки исходного уровня знаний, умений и навыков учащихся
2). Комплекс упражнений и инструкций, которые обеспечивают решение учебных задач по формированию и развитию соответствующих видов речевой деятельности
3). Справочная информационная подсистема содержит: лексико-грамматический и страноведческий справочник, АУС (автоматизированный учебный словарь), АУГ (автоматизированная учебная грамматика). Подсистема выдает информацию о лексическом, грамматическом, страноведческом материале курса.
4). Подсистема анализа сообщений учащихся – производит распознавание сообщений учащихся, вводимых в компьютер для определения их соответствия лексическим и грамматическим нормам языка.
5). Подсистема контроля и коррекции учебной деятельности учащихся. Осуществляется контроль за учебной деятельностью и коррекцией ошибок.
6). Банк дидактических материалов включает дополнительные тексты, связанные по содержанию с конкретным уроком.
7). Блок управления, предназначенный для всей учебной деятельности учащихся в АУК (выбора уроков, выдачи различных сообщений, обращенных к подсистеме и банку дидактических материалов).
ВИДЫ УПРАЖНЕНИЙ, ПРИМЕНЯЕМЫХ В АУК:
ОБУЧЕНИЕ ГРАММАТИКЕ
Целесообразно создать автоматическую учебную грамматику (АУГ), которая должна состоять из 2-х взаимосвязанных частей:
--справочной, состоящей из правил с примерами
--тренировочной, представляющей собой тренажер с упражнениями
В обучении грамматике выделяются 3 этапа:
1). Объяснение правил с иллюстрацией примеров
2). Формирование грамматического навыка употребления определенного языкового явления (тренировочные упражнения)
3). Свободное употребление грамматического явления в диалоге с компьютером (конструирование сообщений)
Некоторые виды таких упражнений:
--на изменение формы слова
--на изменение порядка слов в предложении
--на преобразование предложений
ОБУЧЕНИЕ ЛЕКСИКЕ (или словарные упражнения)
Например: --упражнения на составление слов из отдельных букв
--лексические упражнения, включающие изучаемую лексику в контексте коммуникативной системы
ОБУЧЕНИЕ ЧТЕНИЮ (используются тесты)
Виды тестов:
1). Множественный выбор
2). Тесты на группировку фактов
3). Тесты на исключение лишних слов
4). Тесты на заполнение пропусков (тесты на прогнозирование)
Упражнения предназначены для проверки понимания прочитанного текста и умения оценить его.
КОМПЬТЕРНЫЕ ИГРЫ
Автоматизированный учебный словарь (аус)
Компьютерное обучение иностранному языку в качестве одного из вспомогательных средств использует АУС. АУС ориентирован на учебные задачи. Задача АУС – выдача по запросу учащихся лексико-грамматической информации о любой лексической единице, включая ее основные морфологические, лексические и синтаксические характеристики.
Основная единица АУС – словарная статья определенной структуры. В словарной статье выделяют 12 зон, каждая из которых включает один вид информации:
1 зона – заглавие (слово в канонической форме)
2 зона – указание на лексико-грамматический класс слова (сущ, глагол…)
3 зона – морфологические формы словоизменения (для англ языка – формы Прош времени и причастия)
4 зона – толкование наиболее употребляемых значений слова
5 зона – примеры употребления слова в этих значениях в контексте на уровне предложений
6 зона – переводные эквиваленты
7 зона – указание на тематическую соотнесенность слова и стилистические пометы
8 зона – синонимы
9 зона – антонимы
10 зона – наиболее употребительные словосочетания
11 зона – устойчивые словосочетания и фразеологизмы
12 зона – производные слова
В словарной статье нужно отметить полноту лексикографической информации и то, что эта информация подразделяется по уровню предполагаемой языковой компетентности учащегося на 3 слоя:
1). для начинающего уровня (1, 2, 3, 5)
2). продвинутый уровень (---//--- + 4, 6, 7, 10, 12)
3). повышенный уровень (все зоны)
ЭОС – экспертно-обучающая система. В ней помимо знаний по предмету, необходимы также знания по методу диагностики знаний обучаемого и объяснения ошибок.
ЭМОС – экпертно-моделирующие обучающие системы
Интернет (the internet)
--всемирная информационная компьютерная сеть, объединяющая большие и малые компьютерные сети.
--единое информационное пространство, состоящее из миллионов взаимодействующих компьютеров
Компьютеры, постоянно подключенные к Интернету и управляющие перемещением информации в сети, называются СЕРВЕРАМИ ИНТЕРНЕТА.
Устройство, которое используется для передачи информации между компьютерами, называется МОДЕМ. Модем служит для связи 2-х компьютеров с помощью телефонной линии.
Чтобы подключиться к Интернету, нужно найти ПРОВАЙДЕРА, т.е. организацию, которая обеспечивает доступ к Интернету.
Сервисные службы интернета.
E-MAIL (электронная почта)
Телеконференции USENET – система сетевых новостей, позволяющая предавать сообщения (от 1-го ко всем), предназначена для ведения дискуссий и обмена новостями. Электронная почта и система телеконференций – «заочные» системы обмена информацией.
IRC – International Relay Chat – разговоры текстом через Интернет в режиме реального времени (Online).
www – world wide web – предназначена для очной, т.е. интерактивной работы. Она предоставляет возможность поиска и сбора информации. Информация представлена в виде веб-страниц. ВЕБ-СТРАНИЦА – это комплексные документы, которые содержат любые виды данных (текст, графика, видео, анимация).
Местонахождение нужной страницы определяется адресом URL – Uniform Resource Locator.
АДРЕС – унифицированная форма записи адресов документов в сети Интернет.
В основу веб-системы положено понятие «гипертекста», т.е. множества отдельных текстов, которые имеют ссылки друг на друга. Эти тексты называются документ, статья или веб-документ.
Гипертексты создаются с помощью языка html, т.е. языка разметки текстов (html – hoper text mark up language). Создание документа на языке html аналогично программированию. В текст вставляются коды – ТЕГИ, – которые выполняют роль команд. Для поиска информации в www используются поисковые системы.
ЭТИКЕТ В ИНТЕРНЕТЕ
Правила – краткость и грамотность. Использование экстралингвистических факторов – смайлов.
Пакет прикладных программ microsoft office (’95 – под windows ’95)
Является самым популярным средством автоматизации делопроизводства. Пакет содержит программные приложения, необходимые для организации эффективной работы в офисе.
В стандартный пакет Microsoft Office’95 входят:
1). Word 7.0 – текстовый редактор. Самое распространенное приложение. В системе имеется:
а). Мастер подсказок, который следит за действиями пользователя и позволяет получить справку о том, как эффективно пользоваться Word в конкретной ситуации
б). Дает возможность автоматически нумеровать страницы, главы, параграфы, рисунки, автоматически оформлять оглавление.
2). Excel 7.0 – электронные таблицы, с помощью которых можно:
а). создать электронные базы данных, содержащие необходимую для работы информацию
б). проводить анализ типа «что будет если» (может предсказать, что произойдет при
изменении некоторых начальных условий в новых обстоятельствах)
в). Обладает множеством квалифицированных знаний.
3). Access 7.0 – создание баз данных. Позволяет:
а). хранить объемы информации, практически ничем не ограниченные
б). организовывать данные в наиболее удобной форме
в). производить поиск
г). готовить отчеты, содержащие данные в виде текста, рисунков и анимации
д). грамотно расположить данные, описать и связать, уровнять их.
4). Power Point – программа презентаций. Создание презентаций предоставляет пользователю возможность создавать презентации. Здесь шаблоны содержат слайды, а в слайд вставлены заглушки (туда вставляется текст, анимация и т.п.)
5). Schedule – система планирования и создания расписаний. Позволяет пользователю планировать последовательное выполнение работ.
6). Binder 7.0 – программа объединения документов. Объединение всех программ в подшивку. Все программы могут работать самостоятельно и независимо, а при необходимости могут работать совместно.