

5. Содержание отчета
5.1. Функциональная схема системы ТУ.
5.2. Формулы расчёта числа кодовых комбинаций для исследованных СПК.
5.3. Таблица кодовых комбинаций, соответствующих передаваемым командам ТУ для обоих методов кодообразования.
5.4. Осциллограммы сигналов в контрольных точках системы при передаче одной команды ТУ.
5.5. Выводы по лабораторной работе.
6. Контрольные вопросы
6.1. Объясните принцип работы системы ТУ с частотно-распределительно-комбинационным методом избирания.
6.2. Как рассчитывается количество кодовых комбинаций для СПК на все сочетания и полного СПК?
6.3. Что изменится в функциональной схеме при увеличении числа объектов ТУ?
6.4. Изобразите временную диаграмму работы системы при передаче одной команды ТУ для СПК на все сочетания и полного СПК.
6.5. Почему в СПК на все сочетания многочастотные посылки должны разделяться защитными паузами, а в полном СПК нет?
6.6. Укажите достоинства и недостатки безынтервальных кодов. Лабораторная работа № 13 «Исследование шифратора и дешифратора рекуррентного кода»
1. Цель работы
1.1. Изучение функциональной схемы кодера и декодера рекуррентного кода.
1.2. Экспериментальное исследование кодера и декодера рекуррентного кода при искусственном вводе искажений символов кодовой комбинации.
1.3. Построение временных диаграмм для различных режимов передачи кодовых сообщений.
2. Основные теоретические положения
Все коды разделяются на две большие группы: блочные и непрерывные [2-5]. В непрерывных кодах деление на блоки отсутствует, и операции кодирования и декодирования совершаются непрерывно над последовательностями символов.
Рекуррентные коды относятся к непрерывным кодам и не делятся на блоки. Операции кодирования и декодирования символов кода здесь происходят непрерывно. Широко применяется цепной непрерывный код, который и используется в данной работе, позволяющий исправлять групповые ошибки (пачки).
Рекуррентные коды обозначаются дробью n0/n. Простейшим является код, у которого за каждым информационным следует контрольный (проверочный) символ. Такой код обозначается 1/2. Длина контрольных символов при этом равна длине информационных символов: n0 = k = n/2, следовательно, избыточность кода
![]()
Образование последовательности контрольных символов из информационных показано на рис. 13.1.

Последовательность контрольных символов образуется из последовательности информационных символов путём сложения по модулю 2 информационных символов, отстоящих друг от друга на постоянное расстояние l0. Схема кодирующего устройства (кодера) с четырехъячеечным регистром сдвига со «связью вперед» приведена на рис. 13.2.

Работа кодирующего устройства поясняется табл. 13.1. Последовательность информационных символов соответствует состоянию первой ячейки регистра Р в дискретные моменты времени Ti, а последовательность контрольных (проверочных) символов – символам на выходе сумматора по модулю 2.
Каждый информационный символ получается путём суммирования символов второй и четвертой позиций состояний ячеек предыдущей строки табл. 13.1. Это соответствует суммированию сигналов на выходе второй и четвертой ячеек регистра сдвига кодирующего устройства.
Таблица 13.1
Дискретное время |
Состояние ячеек регистра Р |
Выход сумматора М |
|||
1 |
2 |
3 |
4 |
||
T1 |
1 |
0 |
0 |
0 |
0 |
T2 |
0 |
1 |
0 |
0 |
0 |
T3 |
1 |
0 |
1 |
0 |
1 |
T4 |
1 |
1 |
0 |
1 |
0 |
T5 |
0 |
1 |
1 |
0 |
0 |
T6 |
1 |
0 |
1 |
1 |
1 |
T7 |
1 |
1 |
0 |
1 |
1 |
T8 |
1 |
1 |
1 |
0 |
0 |
T9 |
0 |
1 |
1 |
1 |
1 |
T10 |
0 |
0 |
1 |
1 |
0 |
T11 |
1 |
0 |
0 |
1 |
1 |
Коммутатор Км на передающей стороне выдает на выход последовательность, состоящую из первого информационного символа, затем первого проверочного, затем второго информационного и т.д. Получаемая таким образом последовательность является выходной последовательностью закодированных символов рекуррентного кода 1/2.
Декодер состоит из двух частей: вырабатывающей исправляющую последовательность и производящей исправление (коррекцию кода).
Схема первой части декодирующего устройства приведена на рис. 13.3. Коммутатор Км декодера работает синхронно и синфазно с коммутатором кодера, а регистр сдвига Р также имеет четыре ячейки.
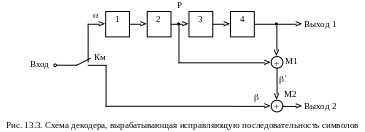
На вход декодера подается последовательность закодированных символов. Коммутатор Км разделяет её на информационную часть, подаваемую на вход регистра сдвига Р, и последовательность контрольных символов , подаваемую на вход выходного сумматора М2. Четырехъячеечный регистр сдвига Р декодера имеет такую же схему, как и регистр сдвига кодера.
Если ошибки отсутствуют, то последовательность символов на выходе сумматора М1 совпадает с последовательностью контрольных символов, подаваемых на вход сумматора М2. В этом случае на выходе 2 последовательность символов состоит из одних нулей, а последовательность символов на выходе 1 представляет собой неискажённые информационные символы.
Если в канале связи между кодером и декодером возникают ошибки, то последовательность символов на выходе 2 содержит единицы в определенном расположении, которое позволяет исправлять ошибки.
Рассматриваемый код позволяет исправлять пакет ошибок длиной
l 2l0 = 4.
Серия ошибок длиной 2l0 = 4 поражает только половину информационных символов длиной l0 = 2 и половину контрольных символов длиной l0 = 2. Допустим, что на выходе декодера (рис. 13.3) появляется первый ошибочный символ и подается пакет ошибок длиной 2l0 = 4. Регистр до этого момента содержал безошибочные информационные символы. Поэтому первые l0 = 2 шага регистра дают в последовательности символов на выходе 2 декодера положение ошибок в контрольных (проверочных) символах. В дальнейшем контрольная последовательность символов содержит только безошибочные символы.
Последующие за этим l0 = 2 шага: из первого полурегистра выдаются на вход сумматора ошибочные информационные символы, поэтому в последовательности символов на выходе 2 также вырабатываются две единицы (в результате сложения с неискаженными символами).
Дальнейшие l0 = 2 шага: на выходе 2 возникают дополнительные две единицы из-за ошибочных информационных символов, возникающих на выходе второго полурегистра. Следовательно, на выходе 2 декодера последовательность символов содержит:
1) единицы на местах ошибок в контрольных символах (первые два шага);
2) со сдвигом l0 = 2 шага единицы на местах ошибок в информационных символах (на третьем и четвертом шагах);
3) то же, что и в п.2, но с дополнительным сдвигом на l0 = 2 шага (на пятом и шестом шагах).
Автоматическая операция исправления последовательности, возникающей на Выходе 1 декодера с помощью исправляющей последовательности на Выходе 2 (см. рис. 13.3), осуществляется с помощью схемы исправления ошибок, приведенной на рис. 13.4. Эта схема является продолжением схемы на рис. 13.3 (Выход 1 соединяется с Входом 1, а Выход 2 с Входом 2).
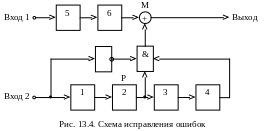
Исправляющая последовательность подается непосредственно на инвертирующий элемент «НЕ», который преобразует символы «1» в «0», а «0» в «1» и подает их на левый вход логического элемента «И». Схема нижнего регистра такая же, как и на рис. 13.3. С выхода ячейки 2 исправляющая последовательность подается со сдвигом на l0 = 2 шага на нижний вход элемента «И», а с выхода ячейки 4 регистра – на правый вход элемента «И», сдвинутой на 2l0 = 4 шага. Единица на выходе элемента «И» возникает только в тех случаях, когда на все его три входа подаются единицы. Она представляет собой команду на исправление ошибки.
Последовательность принятых информационных символов остается сдвинуть так, чтобы команды на исправление ошибок были поданы согласованно. Эту функцию выполняют 2 ячейки регистра сдвига на входе 1 (рис. 13.4). Исправленная последовательность формируется на выходе схемы.
Как следует из вышесказанного, на пути информационных символов включено 3l0 = 6 ячеек регистров сдвига. При этом для вывода всех ошибочных символов необходим защитный интервал длиной 6l0 + 1 = 13 символов.
Сложность аппаратуры для рекуррентного кода оценивается по числу ячеек регистров сдвига. Кодирующее устройство имеет 2l0 = 4 ячейки регистра, а декодирующее 5l0 = 10 ячеек, из которых 3l0 = 6 ячеек имеет исправляющая схема.
Для увеличения защищенности кода и дины пакета исправляемых ошибок увеличивают n, т.е. используют коды (n 1)/n. Схемы таких кодирующих и декодирующих устройств несколько усложняются.
К недостаткам рекуррентного кода относится необходимость иметь интервал времени с неискаженными символами после прохождения пакета ошибок. Это может вызвать дополнительные искажения, если пакет ошибок по длине больше допустимого.
Поскольку рекуррентный код реализуется простыми техническими средствами, его применение является целесообразным для передачи больших объёмов информации.