

МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ
ХАРКІВСЬКИЙ НАЦІОНАЛЬНИЙ
УНІВЕРСИТЕТ РАДІОЕЛЕКТРОНІКИ
МЕТОДИЧНІ ВКАЗІВКИ
до лабораторних робіт з дисципліни
"СТРУКТУРИ ДАНИХ І АЛГОРИТМИ"
Харків 2010
МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ
ХАРКІВСЬКИЙ НАЦІОНАЛЬНИЙ
УНІВЕРСИТЕТ РАДІОЕЛЕКТРОНІКИ
МЕТОДИЧНІ ВКАЗІВКИ
до лабораторних робіт з дисципліни
"СТРУКТУРИ ДАНИХ І АЛГОРИТМИ"
для студентів напрямку 7.080202 – «Прикладна математика»
ЗАТВЕРДЖЕНО
кафедрою ПЗ ЕОМ
Протокол № 21 від 12.06.07
Харків 2010
Методичні вказівки до лабораторних робіт з дисципліни «Структури даних та алгоритми» для студентів напрямку 7.080202 – «Прикладна математика»./ Упоряд. О.А. Галуза, О.Л. Лещинська. Харків: ХНУРЕ, 2010. 45 с.
Упорядники: О. А. Галуза
О.Л. Лещинська
ЗМІСТ
Вступ |
5 |
1. Лінійні динамічні структури даних. Списки. |
6 |
2. Нелінійні структури даних |
12 |
3. Алгоритми сортування послідовностей |
16 |
4. Алгоритми пошуку |
29 |
5. Методи складання алгоритмів |
39 |
Перелік посилань |
44 |
ВСТУП
Під час створення програмного продукту розробник зіткається з двома основними труднощами: створення оптимального методу розв’язання поставленого завдання та корректна реалізація запропонованого рішення. Друге питання багато у чому залежить від майстерного володіння мовою та технологією програмування, в той час як перше – це предмет творчого підходу, успіх в якому тільки частково залежить від накопиченого досвіду. Саме такий досвід, а саме: набір класичних підходів до розв’язання алгоритмічних задач різних категорій та корисні класичні структури даних пропонуються до вивчення у курсі «Структури даних та алгоритми».
На лабораторних роботах пропонується ознайомитися з декількома варіантами реалізації списків, стеків та черг, дерев та графів, хеш-таблиць та множин. Багато уваги також приділяється знайомству з задачами, де застосування тієї чи іншої структури даних є ефективним. Пропонується самостійно запропонувати методи розв’язання класичних алгоритмічних задач та порівняти їх зі стандартними рішеннями. Розглядаються важливі варіанти розв’язання задач сортування та пошуку. Також під час виконання лабораторних робіт пропонується ознайомитися з методикою оцінки та порівняння ефективності розв’язання задачі різними методами.
Матеріал, наведений в розділі «методичні вказівки до лабораторної роботи» не є вичерпним. Обов’язковим є етап самостійного поглибленого ознайомлення студента з предметом роботи з використанням додаткової літератури, на яку даються посилання в тексті роботи. Тільки такий підхід гарантує повне оволодіння запропонованим предметом.
1 Лінійні динамічні структури даних. Списки.
1.1 Мета роботи – ознайомлення з базовими АТД (абстрактними типами даних) – лінійними структурами даних і принципами їхньої реалізації.
1.2 Методичні вказівки з організації самостійної роботи студентів
Динамічні структури за визначенням характеризуються відсутністю фізичної суміжності елементів структури в пам'яті мінливістю й непередбачуваністю розміру (числа елементів) структури в процесі її обробки [1, c.45-63].
Оскільки елементи динамічної структури розташовані за непередбаченими адресами пам'яті, адресу елемента такої структури неможливо обчислити з адреси початкового або попереднього елемента, як це робиться в масивах. Для встановлення зв'язку між елементами динамічної структури використовуються покажчики, через які встановлюються явні зв'язки між елементами. Таке подання даних у пам'яті називається зв'язковим. Елемент динамічної структури складається із двох або більше полів:
– інформаційні поля, у яких утримуються ті дані, заради яких і створюється структура. Одне з таких полів часто називають ключем;
– поля зв'язки, у яких утримуються покажчики, що зв'язують даний елемент із іншими елементами структури.
Cписки
Списком називається впорядкована множина, що складається зі змінної кількості елементів, до яких застосовні операції включення та виключення. Довжина списку дорівнює числу елементів, що містяться в списку, список нульової довжини називається порожнім списком. Лінійні зв'язні списки є найпростішими динамічними структурами даних.
На рис 1.1 нижче наведена структура однозв'язного списку. Поле data - інформаційне поле, next - покажчик на наступний елемент. Значення null у полі next означає, що наступного елемента у списку немає. Це ознака кінця списку. Більш неформально: head «знає» де перебуває перший елемент списку, Перший елемент списку «знає», де перебуває другий, і т.д. Той, хто «не знає», хто за ним наступний (next==null), обриває список.
![]()
Рисунок 1.1 - Структура однозв'язного лінійного списку
Двузв'язний список характеризується наявністю пари покажчиків у кожному елементі: на попередній елемент та на наступний (рис 1.2):
![]()
Рисунок 1.2 - Структура двозв'язного лінійного списку
Неформальне доповнення: той, хто «не знає», хто був перед ним, є першим, той, хто «не знає», хто після нього, – останній.
Списки в програмуванні застосовуються в тому випадку, якщо необхідно реалізувати користувальницький тип даних, що містить багато однотипних елементів, причому кількість цих елементів заздалегідь невідома, до елементів застосовується послідовний доступ, необхідний ефективний механізм реалізації операцій вставки й видалення елементів.
Класичним прикладом використання списків може служити реалізація АТД стек, черга й дек.
Стек реалізує лінійну послідовність елементів з дисципліною обслуговування LIFO (Last In First Out). Включення й вилучення елементів зі стека виконуються тільки з одного боку, що називається вершиною стека.
Черга – це лінійна послідовність елементів з дисципліною обслуговування FIFO (First In First Out). У черзі включення елементів виконується тільки з однієї сторони списку, а вилучення - з іншої.
Дек – це лінійна послідовність елементів, у якій як включення, так і вилучення елементів може здійснюватися з кожного із двох кінців списку. Дек легше всього представити як два стеки, складених дном один до одного.
Схематично моделі стека, черги й дека наведені на рис. 1.3. Стрілками показані операції додавання й вилучення елементів з послідовності.

Рисунок 1.3 - Моделі а) стека; б) черги в) дека
Стеки й черги найпоширеніші при реалізації різних моделей взаємодії потоків у багатопотокових програмах, коли один потік підготовляє дані, а інший їх обробляє.
Стеки також часто використовуються для перетворення рекурсивних процедур в ітеративні (реалізація власного механізму рекурсії з необмеженим стеком), а також для реалізації алгоритмів пошуку розв’язання задач з поверненнями (задач штучного інтелекту).
Реалізація списків на динамічній пам'яті
Для організації динамічної структури списку необхідно, щоб кожен її елемент містив кілька різнорідних полів (інформаційне й поле-зв'язку), а самі елементи структури розташовувалися в динамічній пам'яті. У мові С++ для цього використовується тип даних «структура», що поєднує елементи даних різних типів.
У структурах на динамічній пам'яті доступ до окремих елементів можна отримати тільки через їхню адресу. Такою адресою є згадуване вище поле-зв'язка. У випадку лінійного списку опис даних може виглядати так:
struct TElem {
char data[50];
TElem *next;
};
TElem * Head,*Current, *Last;
У даному прикладі елемент списку описаний як структура, що містить два поля. Поле data строкового типу слугує для розміщення рядка символів в елементі списку. Інше поле next являє собою покажчик, що слугує для організації спискової структури (він містить адресу, за якою в «купі» розташований наступний елемент списку). Такими ж покажчиками є Head (покажчик на початок списку), Last (покажчик на кінець списку) і Current (допоміжний покажчик).
Створення декількох елементів та їхнє об'єднання в список. Опис покажчика ще не означає створення елемента списку. Створити елемент списку можна за допомогою оператора динамічного виділення пам'яті new:
Current = new TElem;
Після виконання даної процедури в динамічній області пам'яті створюється змінна, тип якої визначається типом даних TElem. Покажчик Current можна розглядати як змінну, що зберігає адресу виділеної в динамічній пам'яті ділянки. Доступ до полів створеної в динамічній пам'яті змінної типу «структура» може бути здійснений через покажчик на її адресу в пам'яті завдяки операції -> (стрілка).
<адреса початка змінної> -> <ім'я поля структури>
Заповнимо поля елемента списку.
strcpy(Current->data,”строкові дані в першому елементі списку”);
Сurrent->next =NULL;
Head = Current; //Head й Current зараз містять адреси однієї й тієї ж змінної в «купі» (вказують на ту саму змінну)
Останньою дією ми привласнили покажчику Head значення покажчика Current. Це пов'язане з тим, що повинна існувати змінна, що завжди зберігає в собі адресу першого елемента списку. Інакше, якщо значення покажчика Current надалі буде змінене, то ми назавжди втратимо можливість доступу до даних, що зберігаються в першому елементі списку.
Значення покажчика NULL означає порожній покажчик. Ця ознака використовується для визначення того, що змінна-покажчик не містить припустиму адресу. Якщо Head == NULL, то список порожній.
Якщо Current->next == NULL, то Current не має наступного (є останнім).
У результаті виконання описаних дій ми одержали список з одного елемента. Створимо ще один елемент і додамо перед першим елементом у список (інакше говорять - у голову списку).
Сurrent = new TElem;
strcpy(Current->data,”дані в другому елементі списку”);
Current->next = Head;
Head = Current;
Приклад:
Побудувати список, елементи якого містять цілі числа 1, 2, 3, . . ., n. Кожне таке число називається ключем елементу списка.
Для цього визначимо тип даних TIntElem як:
struct TIntElem {
int data;
TIntElem *next;
};
TIntElem * Head =NULL,*Current=NULL;
і додамо n елементів у список шляхом «додавання в голову»:
int n = 5;
while ( n > 0 ){ Current = new TIntElem;
Current->data = n; Current->next = Head; Head = Current;
n - -;}
Помітимо, що при включенні елемента в голову списку порядок елементів у списку зворотній порядку їхнього включення.
Динамічна структура даних передбачає не тільки додавання елементів у список, але і їхнє вилучення. Найпростішим способом вилучення елемента зі списку є перевизначення покажчиків, пов'язаних з даним елементом ( що вказують на нього). Однак сам елемент даних при цьому продовжує займати пам'ять, хоча доступ до нього буде назавжди загублений. Для коректної роботи з динамічними структурами варто звільняти пам'ять при видаленні елемента структури. У мові C++ для цього можна використовувати оператор delete. Покажемо, як варто коректно видалити перший елемент нашого списку.
Current = Head;
Head = Head->next;
delete Current;
Щоб видалити елемент, що не є першим, з однозв'язного списку, необхідно знати адресу елемента, що йде в списку перед ним, щоб можна було виконати дії, зазначені на рис. 1.3:
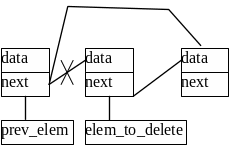
Рисунок 1.3 - Видалення елемента з однозв'язного списку
TElem * Elem_to_delete, Prev_elem;
…// щось робили зі списком, наприклад, створювали, друкували
Elem_to_delete = Prev_elem->next;
Prev_elem->next = Elem_to_delete->next;
delete Elem_to_delete;
Одна з найважливіших операцій при роботі зі списком – це прохід за списком. Припустимо, що з кожним інформаційним елементом списку потрібно виконати деяку операцію, що реалізується функцією void P(const TElem*), наприклад, надрукувати його на екрані. Нехай також Head вказує на початок списку. Тоді прохід за списком здійснюється так:
Current = Head;
while (Current) {
P(Current);
Curent = Current->next;
}
Варіанти індивідуальних завдань
- 5. Створити функції для роботи з однозв'язним списком: додавання елемента після заданого, у початок й у кінець, видалення елемента за ключем, пошук елемента за ключем, обмін двох елементів списку місцями, роздрук списку. Список представлений на динамічній пам'яті.
- 10. Створити функції для роботи із двузв'язним списком: додавання елемента після заданого, у початок й у кінець, видалення елемента за ключем, пошук елемента за ключем, обмін двох елементів списку місцями, роздрук списку. Список представлений на динамічній пам'яті.
З використанням функцій для роботи зі списком реалізувати наступні завдання:
Знайти максимальний і мінімальний елементи вектора й поміняти їх місцями.
Дано два вектори елементів, відсортованих за зростанням. Підрахувати кількість однакових елементів у цих векторах, тобто кількість t, для яких t = ai = bj, для деяких i та j.
Знайти кількість різних елементів у векторі цілих чисел. Наприклад, у векторі 1, 2, 2, 1 усього два різних числа
Дано одномірний вектор елементів, знайти в ньому суму елементів, які розташовані між максимальним та мінімальним.
Реалізувати стек на списку елементів та на основі стеку перевести заданий рядком символів арифметичний вираз (з чисел, операцій +,-,*,/ та дужок) у форму польського інверсного запису та обчислити його.
Вилучити з вектора цілих чисел всі елементи з парними ключами.
Дано одномірний вектор елементів, вибрати в ньому будь-який елемент (позначимо його b) і заповнити інший вектор так, щоб спочатку йшли всі елементи менше b, потім рівні b, потім більші b.
Дано одномірний вектор елементів, заповнити інший вектор так, щоб спочатку йшли всі парні елементи, а потім непарні.
Дано вектор елементів. Переставити елементи вектора у зворотному порядку.
Відсортувати вектор елементів.
1.4 Контрольні запитання і завдання
Що таке лінійної структури даних?
У чому переваги й недоліки статичних структур у порівнянні з динамічними?
У чому переваги й недоліки динамічних структур у порівнянні зі статичними?
Перелічіть існуючі лінійні структури даних.
Опишіть, як здійснюються операції вставки елемента в однозв'язний і двузв'язний список.
Опишіть, як здійснюються операції пошуку елемента в однозв'язному й двузв'язному списках.
Опишіть як здійснюються операції видалення елемента в однозв'язному й двузв'язному списках.