

Контроль приоритетов
Одной из задач, решаемых коммутатором ATM, является выбор ячейки, которая должна быть послана следующей. Наиболее простым методом выбора является строгое следование схеме приоритетов. Например, если в буфере находятся ячейки, относящиеся к трафику с постоянной скоростью (CBR), они должны быть отправлены в первую очередь. Если же таких нет, то нужно передавать ячейки, относящиеся к службе rtVBR. Если такие ячейки также отсутствуют, то передаются ячейки службы nrtVBR и т. д., до тех пор, пока не будут обслужены все категории трафика (рис. 15.10)
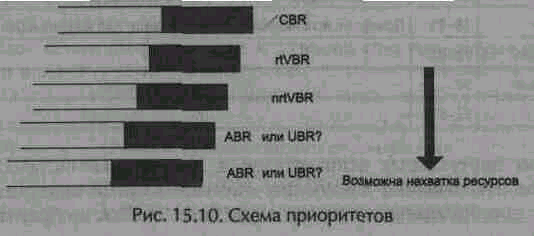
К сожалению, описанная методика наталкивается на проблему нехватки ресурсов. Можно допустить, чтобы трафик CBR имел приоритет перед любыми другими категориями, поскольку он не порождает внезапных всплесков и всегда оставляет часть полосы пропускания доступной для остальных служб. Однако если наивысший приоритет получит трафик VBR, не исключено, что многочисленные виртуальные соединения данного типа одновременно начнут передачу на максимальной скорости. В результате общий объем передаваемых данных может превысить имеющуюся полосу пропускания, и тогда менее приоритетные службы могут быть полностью приостановлены. При этом возможно возникновение временного тайм-аута для пользовательских приложений, которые обязаны провести повторную передачу данных, что может привести к перегрузке сети. Данная проблема еще более усугубляется, если дать приоритетные права службам UBR или ABR. Дело в том, что данные службы рассчитаны на использование всей имеющейся полосы пропускания, так что ячейки с более низким приоритетом будут постоянно дискриминироваться.
Более сложная, но менее проблематичная схема выбора ячеек для передачи сводится к тому, чтобы при наиболее высоком приоритете службы CBR (необходимом для достижения высокого качества сервиса), поддерживалось некоторое взвешенное распределение полосы пропускания между остальными службами (рис. 15.11).
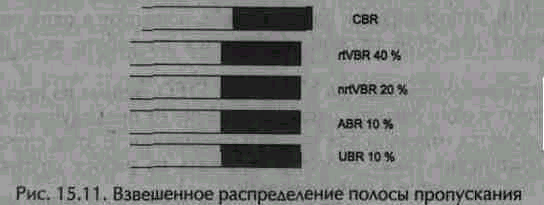
На практике значения, указанные на рис. 15.11, приходится рассчитывать заново при установлении или разрыве очередного виртуального соединения.
Организация очередей в коммутаторах
Эффективность использования свободной полосы пропускания напрямую связана с организацией очередей в коммутаторах ATM. В табл. 15.8 приведено краткое описание различных алгоритмов организации очередей.
Поступающие в коммутатор ATM данные не могут быть обработаны мгновенно. Необходимо какое-то время для принятия решения о том, что с ними делать. Для их промежуточного хранения необходима буферная память. Механизм управления буфером является одним из основным механизмов управления трафиком. Буферная память должна динамически выделяться тому или иному потоку в зависимости от требуемого качества обслуживания. Для организации отдельных очередей для каждого виртуального соединения можно разделить общую буферную память на несколько частей, каждая из которых будет предназначаться для трафика с определенным качеством обслуживания. При этом объем выделяемой части буфера и алгоритм работы с ней напрямую связан с типом трафика. Каждый буфер обслуживает свои очереди; на один порт может приходиться несколько очередей. При выборе объема буфера следует учитывать следующее обстоятельство: чем больше объем буфера, тем, в общем случае, выше цена оборудования. С другой стороны, достаточно емкий буфер способен обеспечить защиту от перегрузок.
Таблица 15.8. Алгоритмы организации очередей
Алгоритм очереди
|
Описание
|
Очередь FIFO
|
Все виртуальные соединения, относящиеся к одной категории сервиса, помещаются в одну очередь и одинаково страдают от перегрузок
|
Очередь FIFO с раздельным определением перегрузки
|
Все виртуальные соединения, относящиеся к одной категории сервиса, помещаются в одну очередь. При этом состояние перегрузки определяется для каждого соединения, но перегрузка одного соединения все еще влияет на другие, так как они используют одну очередь
|
Раздельные очереди для каждого виртуального соединения
|
Каждое виртуальное соединение имеет свою собственную очередь. Перегрузки в одном соединении не влияют на другие
|
При формировании очередей по принципу FIFO ячейки из всех виртуальных соединений, относящихся к одной службе, попадают в одну очередь, и нехватка ресурсов для этой службы сказывается на работе всех виртуальных соединений.
При раздельном учете каналов в очередях FIFO данные из всех соединений также попадают в одну очередь, однако в отличие от предыдущего метода перегрузка определяется отдельно для каждого соединения. В этом случае перегрузка любого соединения также способна повлиять на работу других, поскольку данные для них находятся в одной очереди.
В случае, если коммутатор ATM поддерживает отдельные очереди для каждого виртуального соединения, перегрузка одного соединения никак не повлияет на остальные.