

3. Семантические базы данных иис
3.1. Общие положения
Создание баз данных (БД) ИИС во многих моделях является сложным и неудобным для проектировщика процессом, если эти модели не содержат достаточных средств представления смысла данных. От указанного недостатка свободно семантическое моделирование, имеющее два уровня: концептуальное моделирование и моделирование собственно базы данных.
На верхнем уровне осуществляется переход от неформализованного описания предметной области (ПО) и информационных потребностей пользователя к их формальному выражению с помощью специальных языковых средств. На нижнем уровне производятся преобразование концептуальной модели ПО в схему БД и ее нормализация.
Базисным в теории БД является понятие «предметная область», содержащее определения объекта и предмета.
Объект – это то, что существует вне нас и независимо от нашего сознания - явление внешнего мира, материальной действительности. Объекты потенциально обладают огромным количеством свойств и находятся в потенциально бесконечном числе взаимосвязей друг с другом. Выделить из всего этого нужно самое важное и необходимое.
Предмет – это объект, ставший носителем определенной совокупности свойств и входящий в различные взаимоотношения, которые представляют интерес для пользователя. Таким образом, предмет – это модель реального объекта.
Совокупность объектов, информация о которых представляет интерес для пользователя, образует объектное ядро предметной области.
Понятие «предметная область» соответствует точке зрения потребителя информации на объектное ядро, при которой выделяются только те свойства объектов и взаимосвязей между ними, которые представляют определенную ценность и должны фиксироваться в базе данных. Таким образом, ПО представляет собой абстрактную картину реальной действительности.
В каждый момент времени ПО находится в одном из состояний, которое характеризуется совокупностью объектов и их взаимосвязей. Если объекты образуют объектное ядро, то совокупность взаимосвязей отражает структуру фрагмента действительности. С течением времени одни объекты исчезают, другие появляются, меняются их свойства и взаимосвязи. Тем не менее, возникающие новые состояния считаются состояниями одной и той же ПО. Таким образом, ПО состоит из определенной последовательности состояний.
Вводя пространство состояний, можно рассматривать в нем определенные траектории, или последовательности состояний s0,s1,…,st, в которых находится ПО в моменты времени 0,1,…,t. Члены такой последовательности не могут быть совершенно произвольными, поскольку
состояние st обычно связано с предшествующими состояниями. Поэтому ПО можно определить как класс последовательных состояний – траекторий. Совокупность всех общих свойств траекторий называется семантикой предметной области.
3.2. Средства описания предметной области
Средства описания ПО должны достаточно просто интерпретироваться людьми и одновременно быть точными, структурированными и обозримыми (конечными). Кроме того, они должны быть универсальны, чтобы описывать любые предметные области. Поэтому в теории БД говорят о концептуальном, или информационно-логическом, моделировании ПО. Дадим некоторые определения.
Тип – это понятие, объединяющее все объекты данного вида. В отличие от объекта, существующего в конкретный момент в конкретном месте, тип не имеет пространственно-временной локализации. Типы обеспечивают объединение точек зрения различных пользователей в данной ПО. Тип не является множеством объектов. С объектом он находится не в отношении «часть-целое», а в отношении «абстрактное-конкретное». Каждый тип имеет уникальное имя, например «ПРЕПОДАВАТЕЛЬ». В каждом состоянии предметной области любой объект может иметь один или несколько типов.
Между типами существуют отношения. Отношение частичного порядка обозначается как IS-A: «Если тип Т1 IS-A Т2, то в любой момент времени t объект типа Т1 является объектом типа Т2». Если множество типов конечно, то его можно изобразить в виде ориентированного графа, вершины которого помечены именами типов, а дуги соединяют те вершины, которые находятся в отношении IS-A, см. рисунок.
Человек

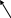
Сотрудник
Учащийся

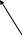


Преподаватель
Аспирант
Студент
Концептуальная
семантическая модель
Над типами можно совершать некоторые операции, например равенства, объединения или включения. Эти операции порождают новые типы, семантика которых определяется совместимостью или несовместимостью исходных типов. Весь арсенал операций позволяет представить достаточно сложные структуры предметной области, например: «ЧЕЛОВЕК = МУЖЧИНА ЖЕНЩИНА».
Имя – тип лингвистических объектов. С каждым типом Т связывается одноместный предикат Р(Т) на множестве объектов типа ИМЯ, который выделяет множество имен объектов типа Т.
Отношение INSTANCE-OF – показывает, что одни объекты являются множествами, состоящими из других объектов. Объект о называется простым, если множество объектов о1, для которых name(о1) INSTANCE-OF name(о), является пустым. В противном случае объект о называется составным. Необходимо заранее разделить объекты на составные и простые.
Композиционный объект – множество элементов, связанных отношением, отличным от отношения принадлежности. Пример композиционного объекта – дата, состоящая из года, месяца и числа.
Ограничение целостности. Исключает противоречия в концептуальных моделях. Например, недопустимость включения одного и того же студента о в две различные группы о1 и о2 может быть записана следующим образом:
оТ, о1Т1, о2Т2, name(о)INSTANCE-OF name(о1),
name(о) INSTANCE-OF name(о2) ,
о1=о2,
где утверждается, что включение в разные группы окажется фиктивным, т. к. в этом случае группы о1 и о2 должны быть одним и тем же объектом.
Семантическое моделирование в промышленно-выпускаемых программных системах имеет некоторую специфику, определяемую фирмой-изготовителем. Примером может служить пакет Erwin.
Концептуальная модель может быть переведена в физическую либо ручным способом по предписанным в программном обеспечении правилам, либо автоматически с помощью специальных дополнительных средств.
4. Алгоритмы обработки знаний методами ИИ
4.1. Формализованные правила
Обработка базы знаний (БЗ) методом "до первого успеха".
Рассмотрим процедуру достижения некоторой обобщенной цели “установить факт” по методу "до первого успеха":
Если факт принадлежит базе фактов (БФ), то “успех”. В противном случае п.2.
Выполнить цикл обработки базы правил (БП) – п.3.
Если БП пуста, то “неуспех”. В противном случае п.4.
Рассмотреть первое правило БП (ПБП) – п.4.1.
4.1. Если все факты условия из ПБП принадлежат БФ, то пп.4.2,
4.3. Иначе – п.4.4.
Если результат действия из ПБП есть искомый факт, то “успех”. В противном случае пп.4.3 – 4.5.
4.3. Добавить результат действия из ПБП в БФ, если его там нет.
4.4. Определить БП=БП-ПБП.
4.5. Перейти к п.2.
Пример. Рассмотрим следующую базу знаний:
Б З:
БФ:
A,C,D,E,G,H,K
З:
БФ:
A,C,D,E,G,H,K
БП: 1. K,L,M I
2. I,L,J Q
3. C,D,E B
4. A,B Q
5. L,N,O,P Q
6. C,H R
7. R,J,M S
8. F,H B
9. G F,
где "," между фактами условных частей правил означает логическое перемножение, а "" - "следует"; любое правило читается как "из … следует…". Задание: установить факт Q. Последовательность решения (по пунктам алгоритма): п.1: QБФ п.2 п.3: БП (не пусто) п.4: ПБП=1БП (первое правило из БП) п.4.1: {L,M}БФ п.4.4: новая база правил БП1=БП -1БП (остаются правила 2,…,9) п.4.5 п.2 п.3: БП1 п.4: ПБП=2БП п.4.1: {I,L,J}БФ п.4.4: БП2=БП1 -2БП (правила 3,…,9) п.4.5 п.2 п.3: БП2 п.4: ПБП=3БП п.4.1: {C,D,E}БФ п.4.2: BQ п.4.3: новая база фактов БФ1=БФ+B п.4.4: БП3 = БП2 - 3БП (правила 4,…,9) п.4.5 п.2 п.3: БП3 п.4:
ПБП=4БП п.4.1: {A,B}БФ1 п.4.2: "успех". Очевидно, что БП рассматривается не полностью и программа не приводит к новым требованиям "установить факт".
Обработка БЗ с перебором всей БП. Алгоритм обработки поясним на примере предыдущей базы знаний с той же целью:
1. Анализ БФ на предмет наличия Q: QБФ.
2. Выбор правила 1БП.
3. Анализ условной части 1БП: {L,M}БФ.
4. Выбор правила 2БП.
5. Анализ условной части 2БП: {I,L,J}БФ.
6. Выбор правила 3БП.
7. Анализ условной части 3БП: {C,D,E}БФ.
8. БФ1=БФ+B.
9. Выбор правила 4БП.
10. Анализ условной части 4БП: {A,B}БФ1.
11. БФ2=БФ1+Q.
12. Выбор правила 5БП.
13. Анализ условной части 5БП: {L,N,O,P}БФ2.
14. Выбор правила 6БП.
15. Анализ условной части 6БП: {C,H}БФ.
16. БФ3=БФ2+R.
17. Выбор правила 7БП.
18. Анализ условной части 7БП: {R,J,M}БФ3.
19. Выбор правила 8БП.
20. Анализ условной части 8БП: FБФ3.
21. Выбор правила 9БП.
22. Анализ условной части 9БП: GБФ.
23. БФ4=БФ3+F.
24. Анализ БФ3 на предмет наличия Q: "успех".
Очевидны просмотр всей БП и наращивание БФ. Увеличенная БФ может использоваться при решении других задач, следующих за рассмотренной. В рассмотренных программах при анализе базы знаний порождаются новые факты, которые приводят к порождению других новых фактов. Такие алгоритмы относятся к монотонным алгоритмам.
Обработка БЗ с ветвлением (порождение подпроблем). Алгоритм поясним на примере прежней задачи. Для установления факта Q (цель) анализируем БФ и, поскольку там нет Q, просматриваем правила и находим то действие, результат которого равен Q (2БП). Для установления факта Q требуется установить факты I, L, J (порождение подпроблем или ветвление). Факт Q называется отцом подпроблем I, L, J. Для установления факта I отыскиваем правило с результатом действия I (1БП). Факт K есть в БФ. Факты L, M отсутствуют в качестве результатов действий. Поэтому переходим к следующему правилу, содержащему результат действия Q (4БП). Факт A условной части 4БП есть в БФ. Факт B устанавливается после анализа 3БП , так как в нем {C,D,E}БФ. Теперь легко устанавливается требуемый факт Q.
Обработка БЗ с возвратом. Рассмотрим БЗ, состоящую из следующих строк фактов и правил:
С1: рабочий(михаил).
С2: студент(иван).
С3: отец(петр,иван).
С4: отец (михаил,петр).
С5: отец(иван,виктор).
С6:
отец(
,![]() )
:- сын(
,
).
)
:- сын(
,
).
С7:
дед(
,
)
:- отец(
,![]() ),отец(
,
).
),отец(
,
).
С8: сын(михаил,юрий).,
где ":-" означает "если" а "," между предикатами соответствует союзу "и". Пусть имеется запрос, который помещается в стек целей (СЦ):
СЦ1=дед(![]() ,
,![]() ),рабочий(
).
),рабочий(
).
Программа решает задачу: существуют ли такие и , что являются дедами и при этом - рабочие. Процедура поиска решения следующая.
1-й цикл. Разрешаются одна за другой две цели в СЦ1. Вначале отыскивается в БЗ пара для цели дед( , ). Сопоставление цели дед( , ) и С7 заканчивается успешно путем замены на и на , после чего оба выражения становятся идентичными. Это делает унификатор УНИФ =
= ( , ). Далее преобразуется содержимое СЦ1 в СЦ2 заменой цели дед( , ) посылкой (условной частью) из С7:
СЦ2= отец( , ),отец( , ),рабочий( ).
Новый СЦ является резольвентой СЦ1 и С7.
2-й цикл. Первая цель в СЦ2, т.е. отец( , ), сравнивается по очереди с С1-С8, и находится унификатор УНИФ=(петр ,иван ) для отец( , ) и С3. Первая цель нового СЦ считается решенной и удаляется из СЦ. К оставшимся целям СЦ2 применяют тот же УНИФ:
СЦ3=отец(иван, ),рабочий(петр).
3-й цикл. Цель отец(иван, ) можно сопоставить с С5 из С1-С8 через УНИФ=(виктор ):
СЦ4= рабочий(петр).
4-й цикл. Цель рабочий(петр) в СЦ4 не сопоставляется с С1-С8. Тупик. Осуществляется возврат с восстановлением ближайшего к СЦ4 стека СЦ3, достижение первой цели которого привело к тупику (обозначим копию СЦ3 как СЦ3.1 - точка возврата ТВ):
СЦ3.1=отец(иван, ),рабочий(петр).
5-й цикл. Сопоставляется цель отец(иван, ) в СЦ3.1 уже с С6 через УНИФ=(иван ). Получаем новое состояние стека:
СЦ3.2=сын( ,иван),рабочий(петр).
6-й цикл. Цель сын( ,иван) в СЦ3.2 не сопоставляется с С1-С8. Тупик. Возврат к ближайшему к СЦ3.2 стеку СЦ3.1:
СЦ3.1.1= отец(иван, ),рабочий(петр).
7-й цикл. Цель отец(иван, ) не сопоставляется с другими С7-С8. Тупик. Возврат к ближайшему к СЦ3.1.1=СЦ3.1=СЦ3 стеку СЦ2:
СЦ2.1= отец( , ),отец( , ),рабочий( ).
8-й цикл. Цель отец( , ) в СЦ2.1 сопоставляется уже с С4 через УНИФ=(михаил ,петр ):
СЦ2.2=отец(петр, ),рабочий(михаил).
9-й цикл. Цель отец(петр, ) в СЦ2.2 сопоставляется с С3 через УНИФ=(иван ), что дает
СЦ2.3= рабочий(михаил).
10-й цикл. Цель рабочий(михаил) в СЦ2.3 сопоставляется с С1. Стек становится пустым. Ответ: =михаил, =иван.
Прямая цепь рассуждений. Рассмотрим следующую базу правил:
Если процентные ставки =падают,
то уровень цен на бирже =растет.
Если процентные ставки =растут,
то уровень цен на бирже =падает.
Если валютный курс доллара =падает,
то процентные ставки =растут.
Если валютный курс доллара =растет,
то процентные ставки =падают.
5. Если процентные ставки федерального резерва =падают
и обращение федерального резерва =добавить,
то = процентные ставки падают.
С целью формализации записи правил введем следующие переменные:
INTEREST – изменение процентных ставок (рост или падение),
DOLLAR – валютный курс (падает, растет),
FEDINT – процентные ставки федерального резерва (растут, падают),
FEDMON – федеральный резерв (добавление или изъятие),
STOK – уровень цен на бирже (растет, падает).
Получим такую базу правил:
Если INTEREST=падает,
то STOK=растет.
Если INTEREST=растет,
то STOK=падает.
Если DOLLAR=падает,
то INTEREST=растет.
Если DOLLAR=растет,
то INTEREST=падает.
Если FEDINT=падает
и FEDMON=добавить,
то INTEREST=падает.
Образуем следующие структуры:
- список различных переменных (в условиях правил) и их значений,
- очередь переменных,
- указатели на правило и номер условия.
Введем запрос: “Если добавить денег из федерального бюджета, как будет вести себя фондовая биржа?”. Алгоритм поиска решения методом “от причины к следствию” имеет следующий вид:
1. Определить начальное условие – причину. В нашем случае: FEDMON=добавить.
2. Занести переменную условия (FEDMON) в очередь переменных (очередь примет вид: 1. FEDMON), а ее значение (добавить) – в список переменных. Для рассматриваемого примера этот список содержит четыре переменных, из которых INTEREST и DOLLAR пока не могут иметь значения, так как меняют их в разных правилах, а FEDINT и FEDMON точно известны:
INTEREST=…
DOLLAR=…
FEDINT=падает
FEDMON=добавить.
3. Просмотреть список переменных из условных частей правил и найти ту переменную (FEDMON), которая стоит первой в очереди. Если переменная найдена, записать в указатели номер первого найденного правила (номер 5) и номер 1 условия. Если переменная не найдена - пункт 6 алгоритма.
4. Присвоить значения непроинициализированным переменным условной части найденного правила по списку переменных (FEDINT=падает) или запросить, если в списке переменных их значений нет. Проверить все условия правила (в правиле 5 два условия), отражая их номера в указателе (вначале указатель условия будет равен 1, затем 2), и в случае их истинности (у нас оба условия истинны) обратиться к части “то” правила.
5. Присвоить в списке переменных значение (падает) переменной (INTEREST), входящей в часть “то” рассматриваемого правила, и поместить ее в конец очереди переменных (очередь: 1. FEDMON, 2. INTEREST). Пункты 3, 4, 5 повторить для других правил, в условных частях которых встречается та же переменная очереди (FEDMON, в нашем примере после 5 других правил нет).
6. Удалить переменную, стоящую в начале очереди (FEDMON).
7. Закончить процесс рассуждений, как только опустеет очередь. Если в очереди есть переменные (INTEREST), вернуться к шагу 3 алгоритма.
На шаге 3 для нашего примера переменная INTEREST встречается в правилах 1, 2. Но найденное на шаге 5 значение падает соответствует только правилу 1. Получим STOK=растет. Очередь переменных: 1. INTEREST, 2. STOK. Переменная INTEREST удаляется из очереди. Очередь: 1. STOK. Переменной STOK нет в условных частях правил, поэтому поиск завершен. Ответ: 1. Процентные ставки падают. 2. Уровень цен на бирже растет.
Обратная цепь рассуждений. Рассмотрим следующую базу правил:
Если DEGREE=нет, то POSITION=нет.
Если DEGREE=да, то QUALIFY=да.
Если DEGREE=да и DISCOVERY=да,
то POSITION=научный работник.
Если QUALIFY=да и GRADE<3.5 и EXPERIENCE>=2,
то POSITION=инженер по эксплуатации.
Если QUALIFY=да и EXPERIENCE<2,
то POSITION=нет.
Если QUALIFY=да и GRADE>=3.5,
то POSITION=инженер-конструктор,
где
DEGREE – ученое звание (да, нет),
DISCOVERY – открытие (да, нет),
EXPERIENCE – стаж работы,
GRADE – средний балл,
POSITION – должность,
QUALIFY – возможность принятия на работу.
Введем запрос: “Какую работу предложить данному посетителю, имеющему ученую степень, не сделавшему никакого открытия, со средним баллом 3 и стажем работы 4 года?” Для ответа образуем структуры:
- упорядоченного списка переменных вывода (список логических выводов) с номером правила: 1. POSITION, 2. QUALIFY,
3. POSITION, 4. POSITION, 5. POSITION, 6. POSITION;
- списка неповторяющихся переменных и их значений из условных частей правил (список переменных условия), не встречающихся в следствиях, с учетом запроса:
DEGREE=да,
DISCOVERY=нет,
EXPERIENCE=4,
GRADE=3;
- стека пар указателей номеров правил и условий.
Поиск ответа методом “от цели к фактам ”имеет следующий порядок.
1. Определить неизвестную переменную логического вывода (здесь -переменная запроса POSITION).
2. В списке логических выводов искать первое вхождение этой переменной (1. POSITION). Если переменная найдена, в указатели ввести номер вхождения-правила (в нашем случае это 1) и установить номер условия 1. Если переменная не найдена, выдать “ответа нет”.
3. Присвоить значения всем переменным условий найденного правила, наращивая номера условий (для нашего примера условие одно: известно, что DEGREE=да).
4. Если в списке переменных условий какой-либо переменной найденного правила не присвоено значения и её нет в списке переменных логических выводов, запросить у оператора (в нашем случае не требуется).
5. Если какая-либо переменная условий найденного правила входит в список переменных логического вывода (в рассматриваемом примере такого нет), поместить в стек указателей номер ближайшего правила, в логический вывод которого она входит, установить номер условия 1 и перейти к шагу 3.
6. Если из правила нельзя определить значение переменной логического вывода (POSITION=?, так как в нашем примере правило 1 противоречиво), удалить соответствующий ему элемент (номер правила 1) из стека указателей и по списку переменных логического вывода продолжить поиск следующего правила (3) с этой переменной логического вывода (POSITION).
7. Если новое правило (3) найдено, заполнить стек указателей новыми данными (номер правила 3, номер условия 1) и перейти к шагу 3 (переменная первого условия правила 3: DEGREE=да, второго условия: DISCOVERY=нет). Правило 3 противоречиво. Из стека указателей удаляем номер этого правила. По списку переменных логических выводов переходим к правилу 4 и шагу 3. Переменная QUALIFY первого условия правила 4 входит в список переменных логических выводов. Добавляем в стек указателей пару “правило 2, условие 1”, сохраняя предыдущие данные - ”правило 4, условие 1”. Переходим к шагу 3: DEGREE=да, QUALIFY=да. Удаляем пару “правило 2, условие 1” из стека указателей, обрабатываем предыдущую пару “правило 4, условие 1”: QUALIFY=да. Увеличиваем номер условия: “правило 4, условие 2”: GRADE=3, т.е GRADE <3.5. Следующее условие: EXPERIENCE=4, т.е. EXPERIENCE>=2.
8. Если переменная не найдена ни в одном из оставшихся правил в списке логических выводов, правило для предыдущего вывода неверно. Если предыдущего вывода не существует, сообщить, что “ответа нет”. Если предыдущий вывод существует, вернуться к шагу 6.
9. Определить значение переменной из правила, расположенного в начале стека логических выводов (правило 4: POSITION=инженер по эксплуатации); правило 4 из стека удалить. Если среди переменных условий есть еще переменные логического вывода (в нашем примере их больше нет), увеличить значение номера условия и перейти к шагу 3. Если в условиях больше нет переменных логического вывода, сообщить окончательный ответ (POSITION=инженер по эксплуатации).
Обратная цепь рассуждений особенно ярко демонстрирует себя в задачах, где ищется причина (причины) при известных следствиях. Пример: определить причину, по которой не заводится автомобиль.