

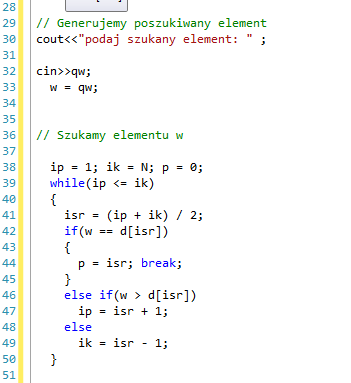
Lista kroków
krok 1: |
ip |
|||||
krok 2: |
Dopóki ip ik: wykonuj kroki 3...5 |
|||||
krok 3: |
|
|||||
krok 4: |
Jeśli w = d[isr], to p isr i zakończ algorytm |
|||||
krok 5: |
Jeśli w > d[isr], to ip isr + 1. Inaczej ik isr – 1 |
|||||
krok 6: |
Zakończ algorytm |
Opisanie programu
Na początku pracy algorytmu ustawiamy zmienne robocze. Zmienna ip przechowuje pierwszy element partycji, w której wykonujemy oszukiwanie elementu w. Zmienne ik przechowuje ostatni indeks elementu w tej partycji. Początkowo partycja obejmuje cały zbiór.
W zmiennej p algorytm umieści indeks elementu zbioru równego poszukiwanemu elementowi. Wstępnie ustawiamy ten indeks na 0 w celu zaznaczenia, iż element nie został jeszcze znaleziony.
Rozpoczynamy pętlę warunkową. Warunkiem kontynuacji jest niepusta partycja, w której poszukuje się elementu w. Pierwszą czynnością w pętli jest wyliczenie indeksu elementu środkowego isr.Następnie sprawdzamy, czy element poszukiwany jest równy elementowi środkowemu. Jeśli tak, to w zmiennej p umieszczamy indeks elementu środkowego i algorytm kończymy.
W przeciwnym razie poszukiwany element w może leżeć w lewej partycji jeśli jest mniejszy od elementu środkowego lub w prawej partycji w przypadku przeciwnym. Ustawiamy zatem odpowiednio zmienne ip oraz ik:
w > d[isr] - prawa partycja, ip przesuwamy na is + 1, ik pozostaje bez zmian w d[isr] -lewa partycja, ip pozostaje bez zmian, ik przesuwamy na isr - 1.
Po tej operacji wracamy na początek pętli.
Gdy pętla warunkowa się zakończy w sposób naturalny (w wyniku ostatniego podziału otrzymujemy pustą partycję), zmienna p zawiera 0. Oznacza to, iż element w nie występuje w zbiorze. Jest to przypadek pesymistyczny i wymaga wykonania log2n + 1 obiegów pętli.
Program w języku C++


Testowanie algorytmu
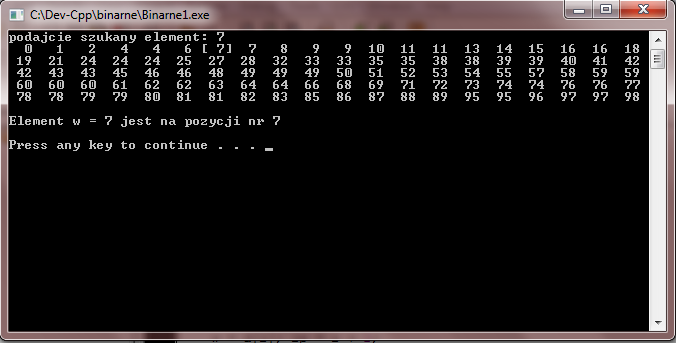
Niech będziemy szukać pozycję liczby 7.
Program zgłosi następne wyniki:
Następnie, szukając liczbę 9 wyniki będą taki:

Czyli liczba 9 nie występuje w zbiorze.
Teraz sprawdzimy jak dziala algorytm dla zbiorów o różnych rozmiarach.
Dla tego zastosujemy biblioteku#include <ctime>i funkcje clock_t t0=clock();
która pokaże za jaki czas program będzie wykonany.

![]()
Dla zbioru, jaki składa się ze sta elementów (N=100) czas trwania jest rowny 0.42 sec.
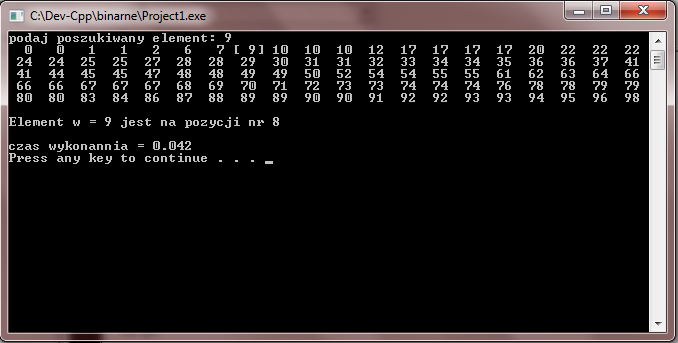
Jeżeli rozmiar zbioru zwiększyć w 10 raz (N=1000) to wyszukiwanie binarne będzie zrealizowane za 0.422 sekundy.

Dla porównania, zwiększymy rozmiar zbioru do 10000 elementów. Wtedy czas wykonania programu będzie 3.987 sek.

Jeżeli zmienić maksymalną wartość elementu na 1000 (M=1000 a nie M=99), liczbę elementów zmienić na 10000(N=10000) to wyniki będą następne:

Czyli czas wykonania programu istotnie zwiększył się.