

Правило построения арифметического кода. Достоинства и недостатки кодов. Применение.
Кодирование:
1) При арифметическом кодировании каждый символ исходного текста представляется отрезком на числовой оси с длиной, равной вероятности его появления, и началом, совпадающим с концом отрезка символа, предшествующего ему в алфавите.
2) Пустому слову соответствует весь интервал от 0 до 1.
3) После получения каждого очередного символа, кодер уменьшает интервал, выбирая ту его часть, которая соответствует вновь поступившему символу.
4) Результатом арифметического кодирования является некоторая двоичная дробь из интервала [0, 1).
p(а)=3/4; p(b)=1/4
Шаг |
Просмотренная цепочка |
Интервал (в десятичной форме) |
Интервал (в двоичной форме) |
0 |
“” |
[0, 1) |
[0, 1) |
1 |
“a” |
[0, 3/4) |
[0, 0.11) |
2 |
“aa” |
[0, 9/16) |
[0, 0.1001) |
3 |
“aab” |
[27/64, 36/64) |
[0.011011, 0.100100) |
4 |
“aaba” |
[108/256, 135/256) |
[0.01101100, 0.10000111) |
В
качестве кода можно взять любое число
из диапазона, полученного на шаге 4.
Например,
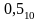
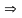
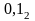 .
.
Декодирование: p(а)=3/4; p(b)=1/4
При декодировании декодер вначале разделяет интервал от 0 до 1 [0,1) на интервалы [0, 0,11] до [0,11;1) поскольку:
1)0<x<0,11, результатом декодирования будет буква а.
2)0<x<0,1001 буква а
3)0,011<x<0,1001 буква b
4)0,0110<x<0,1000011 буква а
В качестве кода берется число, имеющее наименьшее количество знаков после запятой.
Арифметический код может иметь среднюю длину кодовой комбинации менее 1 бит/сообщение эффективнее, чем Шеннона-Фано и Хаффмена. Применяется при сжатии текстов и для сжатия изображений (JPEG 2000).
Средний коэффициент сжатия 4…6 раз.
Недостаток: Требует больших вычислительных затрат, чем Хаффмена или Шеннона-Фано.
Эффективное кодирование при неизвестной статистике сообщений. Комбинаторный метод.
Пусть алгоритм состоит из двух символов А{a1,a2}
p(a1)=p; p(a2)=q
Множество всех блоков длины n в алфавите А разбиваем на группы, которые имеют одинаковые вероятности. Таких групп будет n+1.
В нулевой группе отсутствует буква а2. Первая группа состоит из всех блоков длины n и содержит одну букву а2. К-тая группа будет содержать К букв а2.
Код будет состоять из двух частей префикса, содержащего log2(n+1) и суффикса, содержащего log2
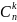
r=3
Кодовые слова |
Номер группы |
Вероятность |
Код
|
а1а1а1 |
0 |
p3 |
00 |
a1a1a2 a1a2a1 a2a1a1 |
1 |
p2q |
|
a1a2a2 a2a1a2 a2a2a1 |
2 |
pq2 |
10 00 10 01 10 10 |
a2a2a2 |
3 |
q3 |
11 |
 префикс
суфикс
префикс
суфикс0;3
группы= log2 =
log2
=
log2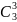 =
=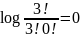 ,
суффикс 0- размерность.
,
суффикс 0- размерность.
1;2
группы=
log2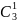 =
log2
=
log2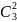 =
=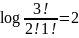
По префиксу сначала определяем номер группы, а затем по суффиксу определяем, какая кодовая комбинация определялась. Метод может применяться при известной и неизвестной статистике сообщений.