

Регистровые структуры процессоров x86-64 архитектуры (amd64, Intel64)
В процессорах x86-64 архитектуры (Hammer, Athlon 64, Opteron) регистры общего назначения (GPR) расширены с 32 до 64 бит (см. рис. 3.7) и к ним добавлены еще 8 новых 64-разрядных регистров (R8 – 15). Также 8 новых регистров (XMM8 – 15) добавлено в блок SSE, что обеспечивает поддержку SSE-2.
В блоке FPU используются существующие в х87 регистры данных ST0–ST7 (80-разрядные) и 64-разрядные мультимедийные регистры ММ0–ММ7, объединенные в общее пространство с регистрами ST. Регистр указателя команд (RIP) и регистр флагов (RFLAGS) также расширены до 64 разрядов.

Сегментное распределение виртуальной памяти
Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т. п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Распределение памяти сегментами(рис)
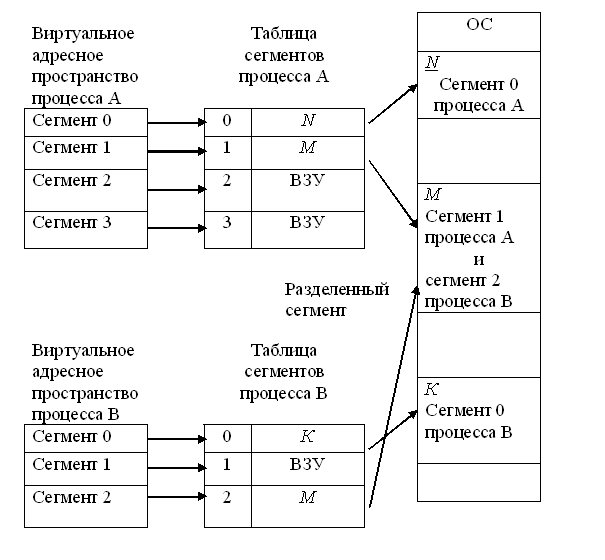
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g — номер сегмента, а s — смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
Сильносвязанные и слабосвязанные многопроцессорные системы
Сильносвязанные системы:
В архитектурах многопроцессорных сильносвязанных систем можно отметить две важнейшие характеристики: симметричность (равноправность) всех процессоров системы и распределение всеми процессорами общего поля оперативной памяти.
В таких системах, как правило, число параллельных процессов невелико (не больше 16) и управляет ими централизованная операционная система. Процессы обмениваются информацией через общую оперативную память. При этом возникают задержки из-за межпроцессорных конфликтов. При создании больших мультипроцессорных ЭВМ (мэйнфреймов, суперЭВМ) предпринимаются огромные усилия по увеличению пропускной способности оперативной памяти (перекрестная коммутация, многоблочная и многовходовая оперативная память и т. д.). В результате аппаратные затраты возрастают чуть ли не в квадратичной зависимости, а производительность системы упорно «не желает» увеличиваться пропорционально числу процессоров. Так, сложнейшие средства снижения межпроцессорных конфликтов в оперативной памяти суперкомпьютеров серии CRAY X-MP/Y-MP позволяют получить коэффициент ускорения не более 3,5 для четырехпроцессорной конфигурации системы.
Слабосвязанные системы:
Существует несколько способов построения крупномасштабных систем с распределенной памятью.
1. Многомашинные системы. В таких системах отдельные компьютеры объединяются либо с помощью сетевых средств, либо с помощью общей внешней памяти (обычно – дисковые накопители большой емкости).
2. Системы с массовым параллелизмом МРР (Massively Parallel Processor). Идея построения систем этого класса тривиальна: берутся серийные микропроцессоры, снабжаются каждый своей локальной памятью, соединяются посредством некоторой коммуникационной среды, например сетью.
Системы с массовым параллелизмом могут содержать десятки, сотни и тысячи процессоров, объединенных коммутационными сетями самой различной формы – от простейшей двумерной решетки до гиперкуба. Достоинства такой архитектуры: во-первых, она использует стандартные микропроцессоры; во-вторых, если требуется высокая терафлопсная производительность, то можно добавить в систему необходимое количество процессоров; в-третьих, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию.
Однако есть и решающий «минус», сводящий многие «плюсы» на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно.
3. Кластерные системы. Данное направление, строго говоря, не является самостоятельным, а скорее представляет собой комбинацию из архитектур SMP и МРР. Из нескольких стандартных микропроцессоров и общей для них памяти формируется вычислительный узел (обычно по архитектуре SMP). Для достижения требуемой вычислительной мощности узлы объединяются высокоскоростными каналами.
Эффективность распараллеливания процессов во многих случаях сильно зависит от топологии соединения процессорных узлов. Идеальной является топология, в которой любой узел мог бы напрямую связаться с любым другим узлом. Однако в кластерных системах это технически трудно реализуемо. Обычно процессорные узлы в современных кластерных системах образуют или двумерную решетку или гиперкуб.
Для синхронизации параллельно выполняющихся в узлах процессов необходим обмен сообщениями, которые должны доходить из любого узла системы в любой другой узел. При этом важной характеристикой является максимальное расстояние между узлами. Если сравнивать по этому параметру двумерную решетку и гиперкуб, то при увеличении числа узлов топология гиперкуба является более выгодной.
Время передачи информации от узла к узлу зависит от стартовой задержки и скорости передачи. Прогресс в производительности процессоров гораздо больше, чем в пропускной способности каналов связи. За время передачи процессорные узлы успевают выполнить большое количество команд. Поэтому инфраструктура каналов связи является одной из главных компонент кластерной или МРР-системы.
Благодаря маштабируемости, именно кластерные системы являются сегодня лидерами по достигнутой производительности.