

Свойства дисперсии
1. Дисперсия постоянной равна нулю.
Действительно, т.к. М(С) = С, то D(C) = M(C – C)2 = M(0) = 0.
2. При вынесении постоянного множителя за знак дисперсии его надо возводить в квадрат:
D(kx) = M(kx – ka)2 = M(k2(x – a)2) = k2M(x – a)2 = k2D(x).
3. Дисперсия суммы независимых случайных величин равна сумме их дисперсий D(x + y) = D(x) + D(y). Здесь важна оговорка о "независимости" величин. При невыполнении этого условия данное свойство не имеет места. Например, при у = х дисперсия суммы не равна сумме дисперсий D(x + х) = D(2x) = 4D(х) D(х) + D(х).
4. Дисперсия суммы двух случайных величин равна сумме их дисперсий и удвоенной ковариации, где ковариация – смешанный центральный момент xy – математическое ожидание произведения отклонений случайных величин от своих центров: xy = М(х – a)(y – b), где a = M(x), b = M(y). Если обозначить дисперсии и ковариацию xx , yy , xy (эквивалентные обозначения), то утверждается, что D(x + y) = xx + yy + 2xy .
Доказательство: D(x + у) = М((x + y) – (а + b))2 = М((x – а) + (у – b))2 = = М(x – а)2 + М(у – b)2 + 2М(x – а)(у – b) = xx + хх + 2xх .
Для независимых случайных величин М(х – a)(y – b) = М(х – a)М(y – b) (согласно 4-му свойству математического ожидания), М(х – a) = М(y – b) = 0 (центральное свойство математического ожидания), следовательно, для независимых случайных величин ковариация равна нулю xy = 0. В этом случае справедливо утверждение D(x + y) = D(x) + D(y).
В другом частном случае у = х (зависимые величины) ковариация равна дисперсии xy = xx и опять получается правильный ответ, который согласуется с правилом вынесения постоянного множителя за знак дисперсии: D(x + х) = xx + хх + 2xх = 4xx = 4D(х).
Следствие: Для независимых случайных величин
D(x + у) = 2 D(x) + 2 D(y).
Например, D(x – у) = D(x) + D(у); (здесь = –1, 2 = 1).
Правило "3-х сигм"
Интересно, что для любой случайной величины справедливо следующее практическое правило: "Случайные отклонения от центра распределения – маловероятны". На практике это означает, что все данные с отклонениями, большими 3х , считаются неслучайными, чаще всего – выбросами, грубыми ошибками в записи чисел, или же поясняются неоднородностью совокупности (эти сомнительные данные с большими отклонениями очевидно не принадлежат изучаемой совокупности).
Оценим вероятность появления больших отклонений (выведем неравенство Чебышева). Запишем и преобразуем формулу для дисперсии:
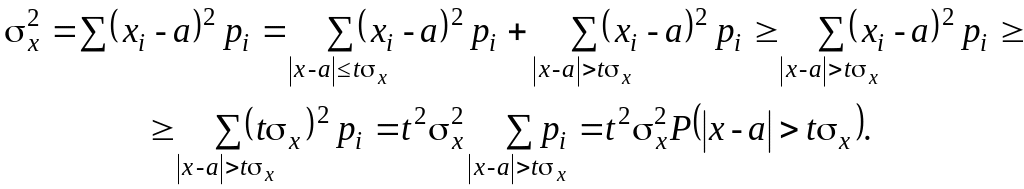
Отсюда получаем довольно грубую оценку вероятности появления больших отклонений
![]()
и вероятности противоположного события
![]() .
.
Если t = 3, то Р(|x – a| 3x) > 1 – 1/9 > 0,89.
Таким образом, с уровнем доверия не менее 90% можно утверждать, что случайные отклонения |x – a| не превышают 3x .
m |
P(m) |
F(m) |
1 |
0,3000 |
0,3000 |
2 |
0,2100 |
0,5100 |
3 |
0,1470 |
0,6570 |
4 |
0,1029 |
0,7599 |
5 |
0,0720 |
0,8319 |
6 |
0,0504 |
0,8824 |
7 |
0,0353 |
0,9176 |
8 |
0,0247 |
0,9424 |
9 |
0,0173 |
0,9596 |
10 |
0,0121 |
0,9718 |
11 |
0,0085 |
0,9802 |
12 |
0,0059 |
0,9862 |
13 |
0,0042 |
0,9903 |
14 |
0,0029 |
0,9932 |
15 |
0,0020 |
0,9953 |
16 |
0,0014 |
0,9967 |
17 |
0,0010 |
0,9977 |
18 |
0,0007 |
0,9984 |
19 |
0,0005 |
0,9989 |
20 |
0,0003 |
0,9992 |
Р(2 m 8) = P(2) + P(3) + P(4) + P(5) + P(6) + P(7) + P(8) = = 0,2100 + 0,1470 + 0,1029 + + 0,0720 + 0,0504 + 0,0353 + 0,0247 = 0,6424.
Для непрерывной случайной величины функция F(x) называется "функцией распределения" или "интегральной функцией распределения". Она определена для всех значений х, в том числе и между узлами дискретной случайной величины. Согласно определению F(х) = P(X х), на интервалах [xi , xi+1) кумулята сохраняет постоянные значения, равные F(xi); F(х < х1) = 0; F(х хk) = 1 (здесь хk – наибольшее значение случайной величины).
График кумуляты (функции распределения для дискретной величины) – ступенчатый, значения кумуляты изменяются скачками в заданных узлах xi случайной величины от 0 до 1.