

Модели и методики построения типовых систем обработки информации как информационных систем с метауправлением функциональностью, и примеры их применения
Модель и методика построения средств формализации и агрегации экспертных знаний по спецификациям доменов
Обязательным компонентом как процесса создания, так и преобразования (реинжиниринга) любой автоматизированной системы (и не только) является формализация экспертных знаний как сведений о существующей и (или) создаваемой системе, предъявляемых к ней требованиях, условиях ее функционирования и т. д. (/7, 118, 243,244/ и др.). В практике создания автоматизированных систем и их специального программного обеспечения принято рассматривать подобные сведения как совокупность спецификаций (/37, 212, 245, 246/ и др.), которые способствуют пониманию требований, предъявляемых к конечному продукту, и служат основой для проектирования, реализации, тестирования, сертификации, сопровождения и дальнейшего развития создаваемой системы.
В настоящий момент не существует формального определения понятия "спецификация" или '’специфицирование". В /246/ приведено определение спецификаций как формального отображения замысла в символьную конструкцию, исключающую ее неоднозначное толкование, которое наиболее соответствует общему предназначению процесса специфицирования. Спецификации представляют собой описание высокого уровня в терминах, характерных для описываемой системы (процесса), и должны отвечать требованиям точности, понятности и полноты /245/, а по степени формальности различают вербальные, формализованные и формальные спецификации /9/.
Совокупность структурированных спецификаций, обладающую свойствами целостности и непротиворечивости, можно рассматривать как информационную
модель (ИнМ), которая несет в себе всю совокупность сведений, характеризующих существенные свойства объекта моделирования (требование целостности) и согласованных по семантической и прагматической нагрузке использованного понятийного аппарата (требование непротиворечивости).
Такое определение, наиболее близкое к приведенным в /247, 248/, позволяет охватить общим термином "информационная модель" достаточно обширный класс информационных семантических систем: например, информационными моделями можно считать технологическую карту процесса, спецификатор работ, бизнес-план выпуска продукции (производства услуг), схему организационно-штатной структуры предприятия и т. д. (/110, 249, 250/ и др.), разного рода концептуальные модели (/7, 98,99/ и др.), а также определения информационных моделей, используемых в различных методологиях (в том числе и создания баз данных) (/152,183,251 - 254/ и др.).
Хотя любая абстрактная модель является гомоморфным отображением оригинала с сохранением его существенных свойств и несет в себе некоторую информацию о моделируемом объекте /255/, информационная модель имеет характер первичного семантического документа модельного типа (по классификации, приведенной в /256/). Структурированность спецификаций, составляющих ИнМ, обусловлена переходом от многомерного плана содержания специфицируемых свойств объекта моделирования к линейному плану его отображения в виде последовательности знаковых элементов модели /256/.
На основе результатов анализа /7, 110, 118, 167, 191, 257, 258/, процесс построения ИнМ можно описать следующим образом:
производится декомпозиция системы на подсистемы (домены), каждый из которых в свою очередь также может быть разбит на подсистемы (домены) меньшего объема (разбиение производится до того уровня, когда можно осуществить линейное специфицирование полученной подсистемы);
осуществляется специфицирование подсистем* результатом которого являются спецификации;
полученные спецификации формализуются с использованием той или иной схемы формализации (см. п. 2.3);
формализованные спецификации агрегируются п ИнМ с проверкой се корректности.
Следует отметить, что понятия подсистемы и домена не совпадают: в соответствии с методологией объектно-ориентированного анализа /183/ домен представляет собой некий функциональный "срез" системы, более близкий к определению бизнес-процесса в методологии реиижинирига бизнес- процессов (BPR - Business Process Reengineering) /110/.
Создание ИнМ, представляет собой достаточно весьма ответственный и трудоемкий процесс, осложняемый необходимостью коллективного взаимодействия разработчиков ИнМ (аналитиков, или инженеров по знаниям - /257/) и специалистов предметной области, владеющих знаниями о специфицируемом объекте (экспертов), со всеми вытекающими из этого отрицательными последствиями (см., например» /1,7,110» 123,172,259,2601).
Сложность и размерность объектов информационного моделирования, особенности организации процесса его проведения (последовательно- параллельная коллективная работа аналитиков и экспертов) и жесткие требования по срокам создания ИнМ привели к необходимости создания и внедрения средств автоматизации информационного моделирования для повышения производительности труда разработчиков ИнМ и качества создаваемых моделей/7. 110,118» 212» 245/.
Наиболее развитыми средствами автоматизированного специфицирования и информационного моделирования являются CASE-средства этапа системного анализа, подробный обзор и сравнительный анализ которых приведен в /7, 118/. Несмотря на несомненные достоинства CASE-средств, их применение
для информационного моделирования осложняется следующими обстоятельствами:
Каждое CASE-средство ориентировано на использование одной или нескольких схем формализации» и основная проблема выбора CASE-средства состоит в оценивании применимости той или иной схемы формализации для описания моделируемого объекта с учетом назначения модели и целей моделирования (причем не всегда CASE-средства могут обеспечить применение требуемой схемы формализации, особенно на начальных этапах проектирования системы, когда формализации подлежат предметные сведения специфической направленности - как, например, медицинское обеспечение систем скринирующей диагностики /261/).
CASE-средства ориентиропанм на аналитика, оперирующего понятиями схемы формализации и хорошо представляющего последнюю, а не эксперта предметной области.
Указанные недостатки заставляют искать иные подходы к созданию средств автоматизации информационного моделирования и организации их использования. Одним из наиболее перспективных направлений исследований в данной области являегся создание условий, позволяющих привлечь предметных экспертов непосредственно к формированию спецификаций по задаваемой схеме формализации, устранив "передаточное звено" в виде аналитика. Такой результат может быть получен с помощью применения метауправления, и сознания средств автоматизированного информационного моделирования как информационных систем с метауправлением.
Анализ содержания манипулирования знаниями в процессе информационного моделирования /191,219,220, 257, 262/ показывает, что процесс специфицирования естественным путем разбивается на два уровня определений, первый из которых является для второго управляющим (рис. 4.1):
Рис. 4.1. Уровни работы со знаниями ы процессе информационного моделирования
на первом уровне задаются определенные понятия, семантические ограничения и определения, подлежащие использованию при формировании ИнМ, и создается план формализации - совокупность схем содержательной и организационной декомпозиции объекта моделирования, а также одной или нескольких схем формализации с привязкой последних к схемам декомпозиции;
на втором уровне производится задание или модификация самих спецификаций, выраженных ранее определенными понятиями и записанных на ранее определенном дескриптивном языке, элементы которого с использованием ссылок на определенные понятия могут быть представлены в естественной и удобной для эксперта форме в терминах предметной области.
Таким образом, применение метауправления при формировании спецификаций основано на дескриптивной природе самих спецификаций /245/, что обеспечивает
задание формализмов языковых определений на метауровне для выражения понятий, служащих для описания моделируемых систем, простым и понятным способом, удобным для эксперта.
Приведенное разделение уровней определений позволяет формально разграничить области действия аналитика и эксперта н рамках парадигмы ме- тауправлеиия:
на первом уровне специфицирования аналитик преобразует свои знания в универсальные понятия некоего концептуального мира, описывающего определенную ПрО, и правила их композиции в подлежащей созданию ИнМ, то есть задает синтаксис знаковой модели (в виде метаспецификаций), которую далее будет формировать эксперт;
на втором уровне определений эксперт, манипулируя понятиями сформированного аналитиком концептуального мира, создает предметные спецификации конкретного домена.
Применение метауправления. приводит к существенному изменению схемы организации работ по проведению информационного моделирования (рис. 4.2):
после проведения декомпозиции системы на домены для каждого из их аналитиками осуществляются разработка метаспецификаций в виде номенк- латора понятий и спецификатора, и производится соответствующая подготовка (настройка) инструментальных средств информационного моделирования для их непосредственного использования экспертами;
в процессе специфицирования эксперт описывает знания о домене но схеме формализации, ранее нвложенной" аналитиками в средства моделирования в виде спецификатора домена - результатом специфицирования будут формализованные спецификации домена;
аналитиками осуществляется агрегация спецификаций и последующая верификация получаемой ИнМ.
На рис. 4.2 также показаны возможные "возвраты", отражающие внесение изменений в метаспецификации или предметные спецификации и обусловленные стремлением к получению корректной ИнМ.
Рис. 4.2. Схема работ по созданию ИнМ с применением метауправления
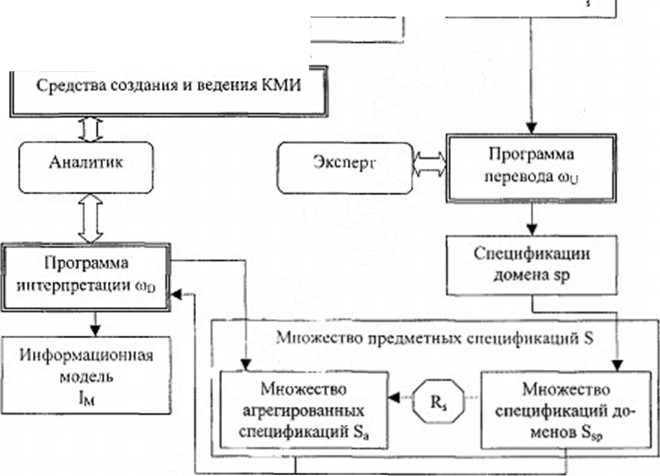
Очевидно, что при создании средств автоматизированного информационною моделирования (САИНМ) как ИСМУ номенклаторы понятий и спецификаторы доменов (далее - номенклаторы и спецификаторы соответственно) представляют собой компоненты метаинформации, первый из которых есть онтология (понятийная модель), а второй - такая компоновка элементов
онтологии, перевод которой в детерминированную форму позволяет получать предметные спецификации, структурированные в соответствии с используемой схемой формализации. Таким образом, термины "номенклатор" и "спецификатор" здесь и далее используются для обозначения именно формы представления онтологии и схемы формализации, "спроецированной” на онтологию, как компонентов метаинформации.
С учетом концептуальных и методологических основ построения ИСМУ, изложенных в главах 2 и 3, САИНМ может быть построена как информационная система с метауправлением, в которой использование метаинформации осуществляется по вычислительной схеме с характеристическим вектором <1, 2, 1, 1, 1> (см. п. 2.2). Специфика САИНМ с точки зрения используемых вычислительной схемы и логической структуры определяется содержанием автоматизируемых процессов информационного моделирования и заключается в следующем:
по отношению к САИНМ пользователями выступают как аналитики, формирующие и изменяющие КМИ, так и эксперты, для которых имеющиеся КМИ статичны;
процесс формирования предметных спецификаций по спецификатору домена есть процесс перевода спецификатора (в рамках разработанной БМПМИ - процесс конкретизации, то есть конкретизованный спецификатор и представляет собой предметные спецификации домена);
интерпретация конкретизованных спецификаторов (которые уже не являются КМИ) заключается в агрегации их содержимого в единую информационную модель.
Указанные особенности приводят к тому, что логическая структура САИНМ приобретает вид, показанный на рис. 4.3.
Рис.
4.3.
Логическая структура САИНМ
Формальная
модель САИНМ, соответствующая ее
логической структуре и являющаяся
частным случаем модели (2.3), может быть
определена как формальная система вила
IS*
= (Ц*
U* R„
о»,
Lp,, S, Rs) (4.1)
где
Lm>-
язык представления метаспецификаций;
Множество
КМИ
Uc
Множество
спецификаторов и„
Спецификатор
домена а-,е Uc
-
J
Множество
номенклаторов U<P





использование номенклаторов при формировании спецификаторов: Ru(ucP) = u<*,
если Ucp € Ucp, u« e Ucs и номенклатор ucp использован для создания спецификатора un;
(о в (Du и ®d - правила обработки метаспецификаций и предметных спецификаций (правила перевода £0и и правила интерпретации ©о)> описанные ниже;
Lm - язык представления предметных спецификаций;
S = S5p и S, - множество предметных спецификаций, образованное множеством спецификаций доменов Sv и множеством результатов агрегации
Sa;
Rs- отношение на множестве S, описанное ниже.
Аналогично модели (2.3), функционирование САИНМ в рамках модели (4.1) может быть описано как совокупность действий по формированию, переводу и интерпретации.
Формирование КМИ представляет собой процесс создания номенклато- ров и спецификаторов, образующих Uc, причем один номенклатор может быть использован при создании двух и более спецификаторов, но каждому спецификатор создается с использованием только одного номенклатора ((Vu) (u ella) (|R„"'(u)| - I)).
В данной работе предполагается, что для представления номенклаторов и спецификаторов используется БМПМИ (см. п. 3.1), а в качестве - один из языков, описанных в п. 3.2. При необходимости БМПМИ может быть расширена: например, в /58/ описано введение в модель и язык представления метаинформации типа понятий (сущности, отношения, атрибуты, значения), отображаемых информационными элементами и секциями ИСФ.
Номенклатор создается как результат идентификации и формулировки множества понятий, адекватных (концептуально) специфицируемому домену. По своему содержанию он представляет собой совокупность двух множеств - базовых понятий Р и множества базовых отношений R, в основу правил формирования которых положен
подход, изложенный в /227, 228, 263. - 265/ и дополненный с учетом 19/.
Каждое базовое понятие Pj задается в виде совокупности Р; = (nj, Aj, q, ,Sj) (4.2), где n* - имя i-го понятия, А; - множество атрибутов i-ro понятия, q, - семантическое значение i-ro понятия, Si - супертип (суперпонятие) для i-ro понятия.
Элементы множества Aj являются парами вида (a:j, z j), где a j - имя j-ro атрибута i-ro понятия (j > 0), - множество возможных значений этого атрибута (|Zj| £ 0).
Введение супертипа позволяет реализовать иерархическое отношение нтип-подтип" ("IS-A") (/220, 221, 262/ и др.): если в описании понятия Sj* 0, то новое понятие определяется как подтип (наследник, потомок) супертипа, наследующий все его атрибуты (возможно, также приобретенные).
Семантическое значение понятия qj представляет собой вербальное описание смысловой нагрузки данного понятию.
По аналогии с /263/, множество базовых отношений R = {Г|, ъ, г„} является множеством бинарных отношений, которые могут существовать между парами экземпляров базовых понятий в данной ПрО.
Спецификатор выступает как организующая структура (схема), по которой должно производиться специфицирование, отражающая перечень и структуру подлежащих выявлению и изложению сведений (знаний). Спецификатор формируется путем композиции элементов номенклатора, то есть содержит понятия в рамках терминологии ПрО со смысловой интерпретацией, определяемой (задаваемой) в процессе его формирования. С позиций БМПИМИ спецификатор представляет собой множество взаимосвязанных ИСФ, среди которых одна является базовым шаблоном (базой), а остальные - дополнениями (шаблонами, дополняющими базу).
Методика формирования номенклаторов и спецификаторов, а также возможность поддержки их формирования посредством множества шаблонов подробно описаны в /58/.
В качестве примера в приложении 5 приведен пример фрагмента спецификатора, а также полученных с его помощью предметных спецификаций. В основе этого спецификатора лежит декомпозиция специфицируемого процесса до уровня элементарных операций, каждая из которых может быть классифицирована как измерение, оценка и воздействие, и описание взаимодействия процессов по схеме конечных авт оматов.
Перевод КМИ при использовании БМПМИ достаточно очевиден - это конкретизация базы спецификатора, правила выполнения которой (то есть «и) полностью определяются моделью СДУ-перевода, приведенной в п. 3.3. Существенно» что БМПМИ в виде ИСФ позволят представить в рамках этой модели и предметные спецификации, то есть обеспечить Lps = L™, что существенно упрощает реализацию САИНМ.
Поскольку процесс конкретизации осуществляется экспертами, его эффективность во многом зависит от эргономических факторов, и особенно - от того, как реализованы процедуры выполнения правил конкретизации. Кроме того, процесс конретизации может сопровождаться частичной верификацией порождаемых спецификаций, которая осуществляется как проверка формальных требований используемой схемы формализации при вводе ответов пользователя.
Интерпрегаиия для САИНМ весьма специфична - ее составляют процессы агрегации предметных спецификаций и получение собственно информационной модели, выполняемые по правилам g>da и о>оо соответственно (соо
= ©од yJ ©do)-
Итоговой ИнМ должна соответствовать одна (единая, общая) понятийная модель, а разработка номенклаторов (и соответствующих им спецификаторов)
приводит к получению множества предметных спецификаций, в котором содержание каждого элемента соответствует только одному номенклато- ру. Кроме того, автономная разработка номенклаторов, спецификаторов и предметных спецификаций, являющаяся неизбежным следствием ориентации на распараллеливание работ по специфицированию с целью сокращения длительности информационного моделирования требует проверки непротиворечивости агрегируемых спецификаций.
Агрегация предметных спецификаций и является процессом объединения предметных спецификаций, полученных по тем или иным спецификаторам, в единую ИнМ, однако она не сводима ни к элементарному объединению множеств предметных спецификаций, ни к агрегированию /266/, так как требует учета семантики элементов объединяемых множеств /17/ и не предполагает замену множеств объектов (сущностей, величин и т. д.) одним агрегированным (или интегральным) объектом. Выполняемая при этом верификация есть проверка непротиворечивости спецификаций как корректности междо- менных связей.
Агрегация и сопутствующей ей процесс формальной верификации предметных спецификаций может быть обеспечен двумя операциями: агрегация спецификаций, полученных по одиому и тому же спецификатору, и агрегация спецификаций, полученных по различным спецификаторам. Полное описание методики агрегации и содержания указанных операций приведено в приложении 6.
Результаты выполнения операций агрегации помещаются в $а. Поскольку агрегации могут быть подвергнуты как спецификации доменов (элементы 5>,Д так и результаты выполнения операций агрегации (элементы Se), отношение R, характеризует использование элементов S9 и S, в получении Sa: R,(uO - u„ где u, € S, и» € $,, если спецификации ua получены как результат агрегации в том числе спецификаций и$.
Итоговая модель 1м также есть результат выполнения операции агрегации Um, если (Vus)( us е SjpX Rs+(us) = um), к которому применимы правила отображения со do: с)ро(ип) 1м- Под отображением в данном случае понимается визуализация содержимого um с использованием того или иного способа определения вычислительной семантики ИСФ - как правило, композиции содержимого атрибутов и слотов фреймов (см. п. 3.4).
При осуществлении процесса агрегации при участии множества экспертов и аналитиков важную роль для минимизации длительности этого процесса играет оптимизация использования ресурса аналитиков. Возможный подход к решению планирования агрегации, предполагающих учет метрических характеристик агрегируемых спецификаций, также приведен в приложении 6.
Описанные выше модель и методика построения средств формализации и агрегации экспертных знаний как ИСМУ были использованы при создании нескольких вариантов САИНМ. Опыт их применения в интересах информационного моделирования реабилитационных центров для детей-инвалидов /23/, бизнес-процессов промышленных предприятий /11,63/ и АСУ специального назначения /12, 50/ показал, что только временные затраты на формирование информационных моделей при использовании таких средств сокращаются в два и более раза. Эффективность применения подобных средств нелинейно увеличивается с ростом количества специфицируемых доменов, уменьшением ресурса аналитиков и уменьшением количества спецификаторов (уменьшением количества используемых схем формализации), а также пространственной распределенностью экспертов. Причина, по которой разработанная методика более эффективна по отношению к традиционному подходу, достаточно очевидна — это привлечение экспертов непосредственно к формированию спецификаций, и высокая степень функциональной адаптируемости САИНМ, создаваемых с применением метауправления.
Модель и методика построения средств порождения имитационных моделей по схеме метауправления на основе агрегативного подхода
Имитационное моделирование, являющееся важнейшим инструментом решения задач анализа, синтеза и оптимизации сложных систем в условиях существования явления "вычислительной неприводимости" /267/, в настоящее время имеет широчайшую теоретическую и методологическую базу (/184, 268
-272/и др.).
По мере накопления опыта применения и совершенствования средств имитационного моделирования все больший интерес стали вызывать исследования, направленные на автоматизацию имитационного моделирования. Наибольший пик этих работ пришелся на конец 80-х - начало 90-х годов, и основными направлениями исследований явились создание специализированных языков моделирования, генераторов моделей, проблемно- ориентированных пакетов и систем моделирования - /213, 273 - 282/ и др. Анализ результатов этих работ позволяет выделить семь групп работ, составляющих содержание применения имитационного моделирования и потенциально подлежащих автоматизации:
исполнение ("прогон”) модели на ЭВМ;
задание значений параметров модели для проведения имитационного эксперимента;
обратная интерпретация результатов, под которой понимается сопоставление результирующих значений переменных программной модели и составляющих моделируемой системы;
построение программной модели;
вторичная обработка (постобработка) результатов моделирования методами статического анализа и т. д.;
планирование экспериментов, анализ их результатов и определение момента завершения исследований;
построение формально-математической модели.
Описываемая ниже методика охватывает работы первых четырех групп, для автоматизации которых наиболее широко используются (/273, 275, 283 - 288/и др.):
реализация макросредств записи текста модели;
создание метаязыков описания моделей и соответствующих предпро- цессоров;
использование библиотек типовых, часто используемых фрагментов (сегментов, агрегатов) моделей;
разработка программ, позволяющих задать в диалоговом режиме значения параметров модели (исходные данные экспериментов) и компоновать тексты моделей.
Суть последнего из перечисленных подходов, представляющего наибольший интерес по полноте автоматизируемых операций, заключается в следующем:
содержимое модели систематизируется, после чего формируются правила компоновки текста модели при известных значения входных параметров;
далее разрабатывается программа, которая запрашивает у пользователя значения параметром модели, генерирует (формирует) текст модели на входном языке системы имитационного моделирования.
Как показывает опыт этих работ (/223, 224, 279, 289, 290/ и др.), программа-генератор позволяет существенно сократить затраты ресурсов, необходимых на модификацию модели при варьировании параметров эксперимента, и, реализуя диалоговый режим работы с широким набором сервисных функций, становится удобной и доступной в использовании даже для пользователей, не знакомых с языком имитационного моделирования и содержанием алгоритмов модели. Однако подобная программа является уникальной
для каждой модели (или множества моделей, объединенных целевым предназначением).
В то же время применение данного подхода приводит возможности к разграничения области деятельности специалистов, участвующих в проведении имитационного моделирования* на формирование (построение), моделей и собственно вычислительные эксперименты с имитационной моделью. Соответственно, как и в случае информационно!чэ моделирования (см. п. 4.1), можно разделить указанных выше специалистов на экспертов в области применения средств имитационного моделирования и программирования, в конечном итоге осуществляющих создание программ-генераторов, и аналитиков* являющихся специалистами в предметной области и призванных решать задачи исследования (анализа, оптимизации) с проведением вычислительных экспериментов на имитационных моделях.
Тогда автоматизированное построение текстов моделей и их использование может осуществляться следующим образом:
эксперт создает типовую модель (библиотеку моделей) и программу- генератор конкретных вариантов моделей, посредством которой аналитик формирует нужные ему модели и проводит на них эксперименты;
эксперт создает и пополняет базу типовых фрагментов (агрегатов), из которых аналитик выбирает и "настраивает" (адаптирует путем параметрической настройки) агрегаты* соответствующие своей задаче* формирует по ним модель с использованием программы-генератора, задает значения параметров эксперимента и осуществляет "прогон" модели.
Подобная организация работ имеет ряд несомненных достоинств с точки зрения использования ресурсов экспертов и аналитиков, однако будет целесообразной только в том случае, если затраты на разработку и возможную модификацию программ-генераторов в интересах конкретных задач исследования будут минимальны. Достичь этого можно с помощью метауправления -
если эксперт в интересах каждой задачи исследования, предполагающей применение имитационного моделирования, будет разрабатывать необходимые агрегаты (при их отсутствии в уже имеющейся базе) и формировать некое метаописание, по которому может быть сформирована программа-генератор, в свою очередь способная осуществлять построение текста имитационной модели с учетом целей и параметров проведения конкретного имитационного эксперимента во взаимодействии с аналитиком, и позволять выполнить сформированную модель.
Применение метауправления для автоматизированного построения текстов имитационных моделей и их последующего использования предполагает, что основу структуры вычислительного формализма системы автоматизированного построения текстов моделей (САИМ) образует базовая система имитационного моделирования (со своим входным языком), дополняемая средствами реализации трех процессов (рис. 4.4):
синтеза конструкций, воспроизводящих поведение моделируемой системы (то есть текста имитационной модели);
задания входных значений параметров модели и инициации выполнения модели;
формирования правил обратной интерпретации результатов.
В свою очередь, содержание этих процессов должно определяться совокупностью сведений, описывающих: структуру моделируемого объекта;
алгоритмы функционирования элементов объекта моделирования; параметры, характеризующие объект моделирования и его компоненты; правила генерации текста модели, позволяющие осуществить построение текста модели;
параметры базовой системы моделирования, определяющие режимы ее функционирования и условия проведения процесса имитации.
Рис. 4.4. Вычислительный формализм САИМ
Указанная совокупность сведений может быть разделена на две части - процедурную (агрегаты модели и программа обратной интерпретации результатов на входном языке базовой системы моделирования), и декларативную, которая представляет собой некое формализованное описание (ФО), являющееся метаописанием для синтеза программных средств, реализующих ука
занные выше вычислительные процессы вычислительного формализма САИМ.
Исходя из вышеизложенного, вычислительная схема использования метаинформации в САИМ, создаваемой как разновидность ИСМУ, будет иметь характеристический вектор < 1, 2, 2, I, 2 > (см. и. 2.2), а ее логическая структура будет расширением варианта структуры, показанного на рис. 2.8. Следует отметить, что в зависимости от базовой системы моделирования порождаемый текст имитационной модели (ИМ) может либо интерпретироваться (как это имеет место, например, в системе моделирования GPSS /291/), либо компилироваться в совокупность машинных кодов, пригодных к дальнейшему выполнению в качестве самостоятельной программы (например, СИМПАС /47/). На рис. 4.5 приведена логическая структура САИМ для второго варианта. Процесс функционировании САИМ с такой логической структурой может быть описан как совокупность трех стадий работ.
На первой стадии производятся:
разработка математической модели на основе постановки задачи на имитационное моделирование;
формирование макета программы имитационной модели; разработка агрегатов на языке моделирования, описывающих поведение элементов моделируемой системы;
формирование перечня входных и выходных параметров модели; разработка формальных правил построения текста модели на базе имеющихся афегатов и значений параметров элементов моделируемой системы;
разработка программы (процедуры) обратной интерпретации результатов, являющихся значениями объектов имитационной модели и среды моделирования.
Разработанные агрегаты снабжаются паспортами для обеспечения их параметрической настройки с целью обеспечения возможности их использования в составе различных моделей, и помешаются в библиотеку агрегатов.
Рис.
4.5. Логическая структура САИМ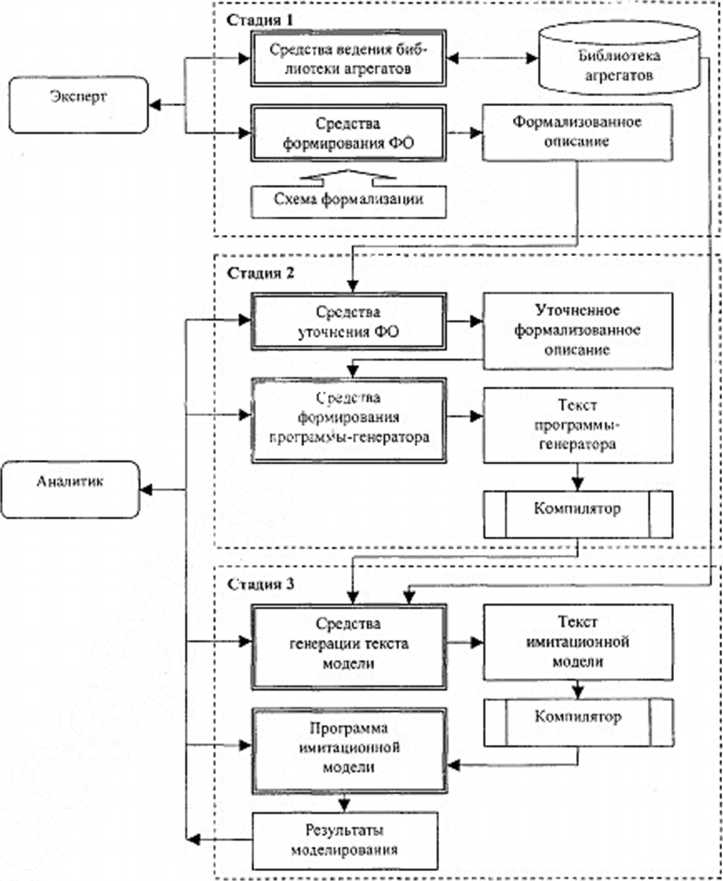
После этого эксперт осуществляет копирование всех агрегатов, необходимых для построения моделей в данном исследовании, из библиотеки агрегатов (являющейся общим ресурсом) в библиотеку задачи, и их параметрическую настройку для применения в рамках решаемой задачи исследований.
Совокупность декларативных сведений, сформированных на первой стадии, составляет формализованное описание, структура которого определяется используемой схемой формализации (см. п. 2.2).
Таким образом, формализованное описание представляет собой компонент метаинформации. Для предоставления возможности генерации множества моделей для различных вариаотов моделируемой системы в ФО могут содержаться альтернативные описания, задающие различные варианты структуры и поведения объекта моделирования и его элементов, разные режимы проведения моделирования, а также состав и способы представления результатов моделирования. Каждый альтернативный вариант связывается с конкретным типом описания того или иного элемента объекта моделирования, его подсистемы или всего объекта моделирования в целом. Все множество возможных типов объектов таким образом определяет все возможное многообразие вариантов моделей исследуемого объекта и позволяет аналитику достаточно просто осуществлять построение моделей различных типов посредством выбора из ФО того подмножества описаний, которое относится к варианту объекта моделирования, исследуемому в данный момент. Процесс такого выбора можно считать уточнением формализованного описания, а его результат - уточненным формализованным описанием (УФО). По своему замыслу альтернативность описаний аналогична вариантности структуры КМИ в рамках БМПМИ (см. п. 3.1), но механизм ее реализации имеет особенности, описанные ниже.
На второй стадии осуществляются:
формирование одного конкретного варианта ФО, однозначно определяющего строящуюся модель и возможности экспериментов с ней, то есть получение УФО, которое можно считать результатом конкретизации исходного ФО, но с некоторыми отличиями, описанными ниже;
построение программных средств (формирование их текста на языке программирования и последующую компиляцию), в свою очередь обеспечивающих построение текста модели и проведение имитационных экспериментов с ней, по своим функциям и возможностям соответствующих вышеупомянутым программам-генераторам текстов имитационных моделей.
На третьей стадии с помощью построенных на предыдущей стадии средств осуществляются:
задание значений параметров модели; генерация текста модели; компиляция полученног о текста модели;
выполнение полученной программы, осуществляющей проведение статистических испытаний;
анализ результатов моделирования.
Естественно, что описанный выше процесс имеет итерационный характер, соответствующий плану исследований моделируемой системы.
Предложенная схема имеет ряд преимуществ перед различными методами автоматизации моделирования, основными из которых являются следующие:
проводит ь эксперименты с достаточно сложной имитационной моделью, подготовленной экспертом, может аналитик, не знакомый с языками моделирования, причем формализованные описания, средства генерации средств построения моделей и проведения экспериментов отчуждаются от эксперта, и конструктивно представляют собой самостоятельный инструмент исследований;
модификация текста модели при проведении исследований альтернативных вариантов построения и функционирования объекта моделирования не требует изменения программ, а сводится только к корректировке уточненного формализованного описания, которое аналитик выполнясг самостоятельно.
В основе представления ФО как совокупности метазнаний декларативного характера лежит применение схемы формализации, которая, в свою очередь, формируется при создании САИМ и далее является неизменной. По сути схема формализации в данном случае играет роль языка представления метаинформации ИСМУ (см. п. 2.1), а ее содержание определяется каноническим составом модели, фиксирующим липовую компоновку текста модели в используемой базовой системе моделирования. В частности, такие "канонические модели" были построены для систем моделирования GPSS, СИМПАС, CSS и COMNET. Роль канонического состава состоит в том, что он позволяет зафиксировать общий вид результатов формирования текста модели и соответствующим образом сформировать требования к составу ФО в виде совокупности сведений трех групп:
подсистемы и элементы моделируемой системы, их взаимосвязи и параметры, характеризующие их свойства (в виде скалярных величин, векторов, матриц и вычисляемых функций), а также возможные альтернативные типы (см. выше);
имена используемых агрегатов, отождествляемых с элементами системы. и схему сопряжения агрегатов;
разного рода служебные параметры, позволяющие осуществлять управление функционированием базовой системы моделирования и процессом имитации (условия завершения моделирования, трассировка событий и т. д.);
правила генерации текста модели путем компоновки указанных агрегатов, обеспечения схемы их сопряжения, установления соответствия параметров модели и объектов среды моделирования и т. д.
Важнейшей особенностью процесса формирования ФО, содержащего указанные выше сведения, является сильная зависимость задаваемых значений друг от друга: например, в схеме сопряжения а!регатов могут быть указаны имена агрегатов только из заданного ранее множества имен, функции могут быть записаны как выражения над уже описанными параметрами и т. д., что также вносит свою специфику в выбор средств представления ФО.
Для представления ФО в принципе могут быть использованы модель и языки, описанные в пп. 3.1 и 3.2, однако в данном случае из-за необходимости выполнения уточнения ФО более целесообразно использовать логическую модель представления, определив состав конструктов для представления метаинформации и поставив им в соответствие логические предикаты, пригодные для фиксации факюв и отношений, составляющих ФО (применение математической логики к использование предикатов для представления знаний различного характера описано, например, в /206,225,292/).
Пример возможном схемы формализации и соответствующего ей состава конструктов ФО приведен в приложении 7.
Как неоднократно отмечалось выше, уточнение ФО представляет собой своеобразный процесс конкретизации, механизм которого существенно отмечается от рассмотренного в п. 3.3 и обеспечивается следующими средствами представления ФО:
конструктом "тип_объекта" могут быть заданы альтернативные типы объекта моделирования, а также его любых подсистем и элементов;
практически во все конструкты входит аргумент, которым является список типов объектов, при котором действует данный конструкт (то есть значе
ние этого аргумента задает область истинной интерпретации данного предиката.
В зависимости наличия значений аргумента "тип объекта" все конструкты, имеющиеся в произвольном ФО, можно разделить на два типа: содержащие только константы (высказывания, к которым относятся конструкты "типобъекта" и все конструкты, не содержащие аргумента "тип объекта"), и содержащие как константы, так и переменные, то есть предикаты, к которым относятся все конструкты, в которых имеется непустой аргумент "тип объекта"):
Р с F: F = (А|, А2,..., Ак}. F" г: F: F" = {В,, В2,BL}, где F - множество конструктов формализованного описания, состоящее из непересекающихся множеств F1 высказываний Al, А2, ..., АК и F" предикатов В I, В2,BL.
Аргумент "тип объекта’’ представляет собой список типов объектов S, имеющий вид:
S = ( d„ d2,dN), N>0, ds - (u, (Wj|, wi2,wiNi), (Vi) (N > i >1) HX), где d, - элемент списка типов объектов,
и - имя переменной, являющейся значением первого аргумента хотя бы одного конструкта "типобъекта";
Wji, Wjj, ..., Wj\-j - список значений переменной и, для которых элемент d; считается истинным.
Весь список S истинен, если истинен хотя бы один его элемент.
Во время формирования ФО эксперт с помощью конструктов "тип об7>скта'' (которые являются высказываниями) задает полный список типов объектов Т„ то есть для каждого объекта перечень всех возможных его типов (если это необходимо):
Ts~
Л
Vtir ,=1^ г-1 j
где No - количество объектов (подсистем и элементов), для которых заданы списки значений их типов.
Этот список удобно представить в виде дерева возможных интерпретаций /218,293/, так как, с одной стороны, каждый i-й "срез" дерева содержит все возможные типы i-ro объекта, а, с другой стороны, любой путь из корня дерева к конечному листу задает одну возможную интерпретацию на множестве типов.
Представленное в таком виде ФО дает возможность аналитику в процессе уточнения ФО конкретизировать описание моделируемой системы путем задания для каждого объекта одного конкретного типа из множества возможных, то есть определение интерпретации I как списка значений, в котором каждая переменная имеет одно и только одно значение:
I = {ij I (Vj) (1 < j <No) (3 k) (1 < k < mj): tjk € Tj a -i (3 v) (1 < v <m,)(v * k A tj, € Tj) A ij = tjk).
На этом действия аналитика по уточнению ФО заканчиваются, после чего соответствующее программное средство осуществляет:
проверку выполнения условия истинности всех предикатов, входящих в ФО, на этой интерпретации по правилу (Vj) (1 < j < L) [ (3 k) (1 < k < |Sj|) (d| (I) true) ^ (Bk = true) ];
элиминацию ложных предикатов из ФО.
Таким образом, по одному ФО может сформировано множество уточненных описаний, каждое из которых может самостоятельно использоваться как исходные данные для построения текста модели, а процесс уточнения выполняется по отношению ко всем предикатам ФО "сразу", а не путем последовательности запросов к аналитику и обработки его ответов, как это имеет место в модели, описанной в п. 3.3.
Пример построения текста модели, демонстрирующий применение описанной выше методики, приведен в приложении 8.
В состав ФО помимо информации о структуре и функционировании моделируемой системы входит описание параметров модели, значения которых подлежат заданию в виде исходных данных перед проведением вычислительного эксперимента с моделью, то есть при осуществлении третьей стадии работ с использованием САИМ. Выполнение этой стадии осложняется наличием между параметрами логических взаимозависимостей, приводящих к невозможности произвольного задания значений. Так, например, при описании сетей связи количество узлов связи определяет размер матрицы связности, содержимое матрицы связности - количество ребер сети и т. д. Учет подобных взаимосвязей весьма важен, так как аналитик должен иметь возможность произвольного доступа к любому параметру для задания и корректировки его значения. Данная проблема усугубляется тем, что параметры модели могут являться как скалярными, так и агрегированными величинами (векторами, матрицами и т. д.), размерность которых зависит от значений других параметров.
Для решения этой проблемы можно использовать ряд последовательных преобразований уточкепного ФО с целью получения отношений между описаниями параметров. Последовательность включает в себя выполнение следующих действий:
построение булевой матрицы отношения "зависит от" для всех входных параметров модели:
1 - если параметр j зависим от параметра i,
Мсти (i j) —
О-в противном случае; сжатие Мо™, необходимое для уменьшения ее размерности и упрощения дальнейшей обработки (склейка строк для векторов);
упорядочивание строк по типам переменных — скалярные величины, векторы, матрицы, таблицы, выражения;
построение матрицы транзитивного замыкания отношения Мао,*; ранжирование элементов матрицы Мотн* по итерационному алгоритму, в соответствии с которым все независимые параметры получают ранг "1", а далее при каждой итерации номер итерации присваивается в качестве ранга всем параметрам, зависящим только от тех параметров, которые уже имеют ранг/41/.
Наличие вычисленных рангов позволяет организовать действия пользователя при задании и корректировке исходных данных для моделирования через механизм статуса параметров. В полном списке параметров для каждого из них указывается один из следующих статусов:
"определен" - значение параметра уже задано пользователем;
"может быть определен" - значение параметра еще не задано, но может быть задано;
"не определен" - значение параметра не может быть задано, так как оно зависит от значений хотя бы одного параметра, имеющего в данный момент статус "не определен" или "может быть определен".
Изначально статус "может быть определен” присваивается только параметрам первого ранга. В дальнейшем при задании пользователем какого- либо параметра его статус изменяется на "определен", и, если это был последний не заданный параметр i-ro ранга, осуществляется приписывание параметрам (i* I )-го ранга статуса "может быть определен".
Если же пользователь изменяет значение некоторого ранее определенного параметра i-ro ранга, от значения которого зависят какие-либо уже заданные параметры старшего ранга, то параметры (i+l)-ro ранга получают статус "может быть определен", а параметры (i+2)-ro, (i+3)-ro и т. д. рангов получают статус "не определен".
Этот способ позволяет пользователю вводить и корректировать зависимые параметры, не заботясь о выявлении их взаимосвязей. Следует отме-
тить, что
данный способ может быть применен в любой диалоговой системе, предполагающей задание взаимосвязанных параметров.
Отдельной особенностью САИМ на принципах МУ является возможность формирования полиязыковых моделей, так как в ФО в качестве агрегатов могут быть указаны имена процедур на языке, не являющемся входным языком базовой системы моделирования, но поддерживаемой ею для разного рода программ выхода. В целом полиязыковость означает возможность как интеграции фрагментов модели, описанных (представленных) на различных по своему классу языках, в единую модель, так и возможность комплексиро- вания модели (моделирующей среды) с программными средствами» не входящими в состав системы моделирования. В ходе работ по созданию различных версий САИМ были использованы три подхода, позволяющие реализовать свойство полиязыковости при создании новых и модификации существующих систем моделирования:
расширение возможностей интерпретирующей системы путем создания программных средств поддержки межъязыкового интерфейса;
формирование средств поддержки моделирования в рамках универсального языка программирования;
интеграция полиязыковых средств в интерпретирующую среду.
Опыт создания полиязыковых моделей показал высокую эффективность такого подхода с точки зрения вычислительной эффективности получаемых моделей /38,46, 55/.
Описанная выше методика построения средств порождения имитационных моделей по схеме метауправления на основе агрегативного подхода разрабатывалась и апробировалась более 10 лет - /223, 289, 294/. Будучи изначально ориентированным на параметрическую настройку моделей /289, 294/, в дальнейшем под влиянием /9/ используемый подход существенно переработан на предмет использования метауправления и осуществления гибкой компоновки текстов моделей.
В ходе апробации методики были созданы три версии системы автоматизированного построения имитационных моделей, отличающиеся базовой системой моделирования (GPSS, СИМ П Л С), средой функционирования (СВМ, MS-DOS) и функциональными возможностями. Все они прошли многолетнюю апробацию в различных проектах в ряде организаций: наиболее сложные модели сетей связи и систем автоматизации были разработаны в НПП "Полет" (г. Н-Новогород), ИНТЕЛ ТЕХ (г. С-Петербург), СПВВИУС (г. С-Петербург). Проведенная апробация показала состоятельность использованного подхода и подтвердила высокое качество выполненной программной реализации. Ее результаты нашли частичное отражение в /10, 36, 48, 52, 53, 69, 76, 77, 85, 224/, а программная реализация полностью представлена в /86,87/.
Методика построения системы интеграции отчетноаналитической информации в иерархически организованной системе управления с использованием унифицированных спецификаторов документов
В любой сисгеме управления (СУ), в которой имеется контур обратной связи с объектом управления, осуществляется сбор информации состояния /102,106, 107,295,296/. Описываемая методика разработана применительно к иерархически организованным СУ в составе организационно- технологических систем, для которых характерны (/100,102,106,297 - 299/):
наличие организационно-технологических процессов, направленных на получение определенного результата с заданным расходованием ресурсов в различных областях деятельности (например, образование, медицинское и социальное обслуживание, управление деятельностью муниципальных образований и т. д.);
наличие коммуникационных процессов, направленных на обеспечение достаточного информационного взаимодействия территориально распределенных элементов СУ;
отсутствие жестких требований по оперативности реализуемых процессов сбора и обработки информации;
управление осуществляется не как реакция на единичные события, а как оценивание ситуации "в целом" и выработка управляющих воздействий по изменению или поддержанию сложившейся ситуации;
информация состояния имеет вид разного рода отчетно-аналитических документов, формируемых с установленной периодичностью и по разовым запросам, и содержащих фактографические сведения, которые сформированы и представлены в соответствии с некоторыми требованиями, определяемыми вышестоящим органом управления как форма документа.
К числу подобных систем относится абсолютное большинство административных и информационно-административных служб различных министерств, ведомств, и управленческих структур субъектов федерации - например, разного рода популяционные регистры (раковый, врожденных пороков развития, заболеваний диабетом и им подобные - /300 - 303/ и др.), санитарно-эпидемиологическая. ветеринарная, экологическая и иные службы и т. д.
Сбор информации в форме отчетно-аналитических документов (ОАД) для функциональной единицы (ФБ) СУ (отдельного должностного лица, подразделения, организации или учреждения) в общем случае сводится к выполнению следующих действий (рис. 4.6) - формирование первичных документов, получение документов от нижестоящий и взаимодействующих ФЕ и их обработка (преобразование) с целью формирования сводных (обобщенных) документов и передача сформированных документов вышестоящим и (или) взаимодействующим ФЕ.
Суть выполняемого преобразования поступающих документов в процессе формирования сводных (обобщенных) документов заключается в разбиении получаемых сведений на два множества, над первым из которых выполняется операция объединения (композиции), а над вторым — обобщения, состоящая в получении интегральных оценок путем Рсверткип вектора значений в скалярную величину по тем или иным правилам (суммирование, выбор максимального значения и т. д.).
Рис.
4.6 Основные компоненты процесса
интеграции ОАД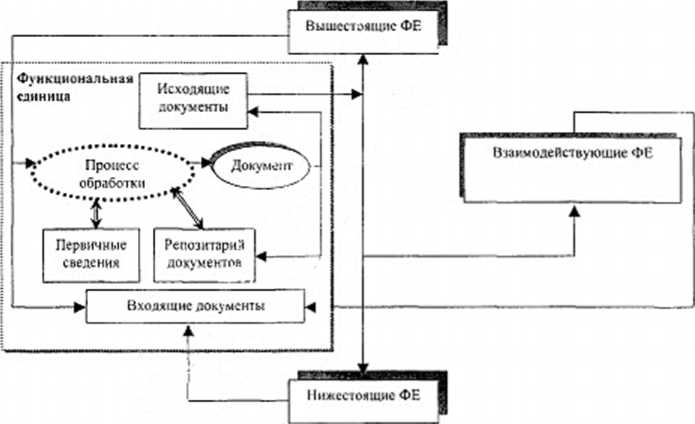
Таким образом, собственно интеграция ОАД представляет собой совокупность процессов объединения и обобщение сведений, характеризующих состояние (деятельность) компонентов управляемой системы при замене множества отдельных сущностей единой сущностью интегрального свойства (например, участок, район, город или класс, школа, предприятие и т. д.)-
Стремление к ослаблению существующего противоречия между требованиями по объему и скорости интегрированной обработки отчетно- аналитической информации с одной стороны, и эффективностью использующихся в настоящее время технологий реализации процессов документооборота - с другой приводят к тому, что современные системы интеграции отчетноаналитической информации (СИОАИ) в большинстве своем создаются как автоматизированные информационные системы, о которых информационную базу ФЕ составляют фактографическая база данных, содержащая первичные для данной ФЕ предметные сведения, и репозитарий документов.
Если СИАОИ создается на базе синтаксически неизменной ИС, то при ее эксплуатации возникает ряд проблем, прежде всего обусловленных фикси- рооанностью форм ОАД и правил их формирования, а также реализованных возможностей отбора сведений из информационной базы для формирования ОАД.
Кроме того, на практике подобные ИС нередко создаются в рамках гетерогенных динамичных компонентов (возможно, даже различной ведомственной и административной принадлежности), и поэтому при создании подобных СИАОИ необходимо учитывать следующие факторы:
сложившуюся организацию СУ;
установившиеся процедуры и периодичность сбора отчетно- аналитических документов, их объем и периодичность формирования;
имеющее место сочетание традиционных и автоматизированных способов формирования, передачи и обработки отчетно-аналитических документов;
разнородность используемых средств вычислительной техники, общего и специального программного обеспечения, несовместимость абсолютного большинства используемых средств по кодировкам, форматам представления
и алгоритмам обработки данных, а довольно часто - и по применяемым терминам и понятиям;
отсутствие единой телекоммуникационной среды, функционирующей исключительно в интересах СИАОИ - использование существующих средств телекоммуникаций носит разделяемый характер (относительно функциональных подсистем и служб, в интересах которых они используются) и основывается в основном на эксплуатации ресурсов коммутируемой телефонной сети общего пользования.
Перечисленные факторы, а также специфика целевого назначения СИАОИ (относительно низкая интенсивность формирования документов, неоперативный характер функционирования вне реального масштаба времени по отношению к организационно-технологическим процессам, не относящихся к числу критических /161, 165/) приводят к тому, что применение "классической11 методологии создания корпоративных информационных систем /7, 118, 171, 304/ в данном случае будет кране малоэффективным в силу низкой рентабельности подобных проектов. На практике административные службы (ФЕ верхних уровней иерархии) доводят до нижестоящих ФЕ требования к формам и периодичности формирования ОАД, но крайне редко обеспечивают средствами автоматизации формирования этих ОАД или финансами на их приобретение, оставляя решение этого вопроса за руководителями организаций и предприятий (см., например, /304 - 307/ и многие другие приказы и распоряжения), откуда и возникает разнородность состава средств, осуществляющих формирование ОАД в СИАОИ.
Таким образом, при создании и эксплуатации СИАОИ в иерархически организонанных СУ решению подлежат следующие основные проблемы:
обеспечение высокой адаптивности средств автоматизированного формирования ОАД в составе ФЕ к изменению форм документов и правил их формирования;
обеспечение взаимодействия разнородных средств ФЕ.
Следует отмстить, что проблема обеспечения взаимодействия разнородных функциональных приложений в настоящее время характерна и для электронной коммерции /308/, и требует решения трех основных задач: обеспечение электронного обмена информацией, преобразование данных и сопряжение архитектур.
С учетом вышеизложенного несомненный интерес представляет построение СИАОИ с использованием метауправления, целесообразность применения которого обусловлена следующим /18/:
если невозможно или нецелесообразно стандартизовать и унифицировать используемые программные средства, то можно поступить таким образом по отношению к информации, являющейся определяющей (или управляющей) для формируемых и обрабатываемых документов;
введение новых форм и правил формирования документов и изменение существующих при использовании МУ будет сводиться к созданию и корректировке метаинформации - без изменений или с минимальными изменениями в программных средствах, и может осуществляться централизованно;
при общем недетермикизме создания СИАОИ и свободе архитектурных и инструментальных решений стандартизация элементов хранения, обработки информации и информационного обмена на основе соответствующих компонентов метаинформации дает возможность фиксации идеологии унифицированного промежуточного слоя, не затрагивая конкретику реализации баз данных и приложений /28/.
СИАОИ может либо изначально создаваться как ИСМУ, либо путем создания ИСМУ для ФЕ, образующих некоторое ядро СИАОИ, интегрируемое с существующими средствами, не поддерживающими применение метауправления, посредством специальных программных "шлюзов” - рис. 4.7. Привлекательность второй стратегии обусловлена тем, что она не требует единовременных затрат
на широкомасштабное переоснащение всех ФЕ и минимально ущемляет интересы производителей уже эксплуатируемых программных средств, и в то же время вносит элементы унификации и стандартизации, позволяющие перейти к качественно более высокому уровню организации процессов интеграции отчетно-аналитической информации и снизить степень влияния технических решений, принимаемых отдельными производителями программных средств, на взаимодействующие информационные системы.
Рис.
4.7. Основные компоненты комбинированной
СИАОИ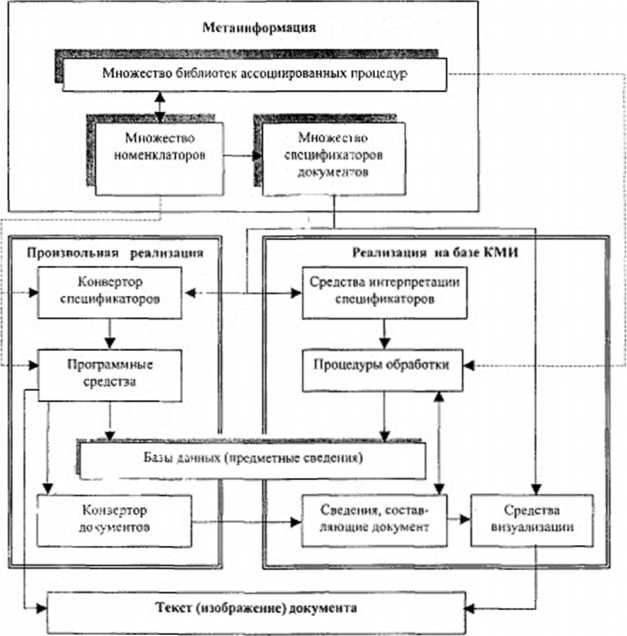
Разработанная методика построения системы интеграции отчетноаналитической информации в иерархически организованной системе управления с использованием унифицированных спецификаторов документов предполагает:
создание информационных систем ФЕ как ИСМУ с использованием вычислительной схемы с характеристическим вектором <1,2, 1, 1, 1> (см. п. 2.2);
применение КМИ трех типов: номенклаторов доменов, фильтров данных и спецификаторов документов, а собственно документы рассматриваются совокупность метасведений и определенным образом структурированных предметных сведений;
применение специально разработанного XML-приложения, являющегося расширением XML-приложения для базовой модели представления мета* информации, описанного в п. 3.2.2, п качестве лингвистического средства представления КМИ и документов.
Из-за большого объема описание разработанного XML-приложения приведено в приложении 9. где также показана возможность настройки XML- редактора, описанного в п. 3.S, для формирования номенклаторов доменов, спецификаторов документов и фильтров данных. Несмотря на большое количество добавленных тегов, правила конкретизации КМИ для данного XML- приложения идентичны рассмотренным в п. 3.3 с учетом указанной в приложении 9 принадлежности правила конкретизации каждого добавленного тега к одному из числа базовых - "И", "ИЛИ", "МИЛИ", "повтор” и "необязательно".
Структура, правила формирования и интерпретации номенклаторов доменов. фильтров данных, спецификаторов документов и самих документов имеют ряд специфических особенностей, подробно описанных в приложении
10,
а ниже приведены только ключевые моменты рассматриваемой методики, связанные с использованием КМИ в общем процессе интеграции ОАД.
Обобщенная схема применения КМИ в интересах интеграции ОАД изображена на рис. 4.8. Все КМИ, а также документы имеют паспорта подлежат хранению в репозитарии информационной базы ИС ФО, а процесс помещения КМИ в репозитарий представляет собой опубликование КМИ, сопровождаемое назначением ему глобального уникального идентификатора (ГУИ) (см. структуру паспорта, а также ГУИ и алгоритм его вычисления в приложении 2).
Номенклатор понятий (далее - номенклатор) фиксирует онтологию домена ПрО, доступную при последующем описании форм ОАД и правил их формирования, с единым толкованием семантики элементов понятийной модели (в этом плане номенклатор домена и номенклатор, описанный в п. 4.1, совпадают). Каждый номенклатор Н из множества опубликованных номенклаторов Н в общем случае содержит четыре раздела:
Нь - "технологические сведения”, к числу которых относятся такие сведения, которые являются характеристиками не информационных объектов, а среды эксплуатации информационной системы - разного рода реквизиты, параметры окружения и иобстановки'' (текущая дата, время, наименование организации и т. д.).
На - "единичные сведения" предназначен для описания информационного объекта домена, то есть составляющих информационный объект сущностей, их атрибутов и связей между сущностями - как внутренних, так и внешних.
Нзг - "интегрированные сведения", к которым относятся сведения, вычисляемые на основании множества кортежей данных, "видимых" на момент вычисления этих сведений (например, моменты случайной величины и т. д.);
Рис. 4.8. Обшая схсма формирования и использования КМИ
H41 — "правила фильтрации", задаваемые как множество возможных элементарных критериев отбора (выборки) сведений.
Специфика второго раздела номенклатора заключается в том, что его содержимое составляет множество ИСФ, каждая из которых соответствует одному информационному объекту (сущности) и в обшем случае содержит множество внутренних и (или) внешних ссылок ка другие информационные объекты, а также иерархически организованное описание атрибутов информационного объекта. Используя механизм ссылок, можно найти все информационные объекты, связанные с данным, по всех имеющихся номенклато- рах, что в конечном итоге дает возможность формирования сложных запросов к базе данных (например, по цепочке "отводы” - "прививки” - "пациент” - "лечащий врач" - "сведения об амбулаторном приеме" можно получить сведения, позволяющие оценить корреляцию заболеваний пациентов с их отводами от прививок по медицинским показаниям).
Использование номенклаторов обеспечивается на множеством ассоциированных процедур, поставленных в соответствие вершинам разделов номенклатора и позволяющих реализовать формальный смысл понятий, которые обозначают эти вершины.
В силу специфики СИАОИ прерогатива разработки номенклаторов принадлежит старшим в иерархическом отношении ФЕ, а нижестоящие ФЕ потенциально могут расширять номенклатор в своих интересах (например, номенклатор иммунологической службы Министерства здравоохранения может быть дополнен на региональном уровне понятиями, специфичными для иммунологической службы этого региона). Изменение номенклатора тождественно изменению синтаксиса ИС СИОАИ и требует адекватных изменений в ассоциированных процедурах. В идеале версии номенклатора должны рассылаться нижестоящим ФЕ вместе с библиотекой ассоциированных процедур, обеспечивающих его применение.
Фильтр данных содержит описание правил отбора сведений из базы данных с целью последующего формирования документа на выбранном множестве данных. Правила формируются как конъюнкция условий или их отрицаний из четвертых разделов номенклаторов (I-L^ "правила фильтрации" - см. выше) с дополнением их признаками подлежащих выполнению действий по отбору ("добавить" или "исключить").
Совокупность сведений, хранимых в бане данных и отвечающих условиям некоторого фильтра данных, представляет собой выборку (которая в зависимости от реализации может быть как физически формируемой таблицей, так и исключительно логическим понятием).
Спецификатор документа (далее - спецификатор) является описанием формы документа и параметров его отображения, а учитывая установленную процедуру конкретизации и интерпретации спецификатора, он, по сути, задает и правила формирования документа.
Синтаксис спецификатора достаточно сложен (см. приложения 9 и 10), так как выбранный подход к определению структуры спецификатора предполагает фактическое объединение трех уровней описания документа: концептуального, логического и представления (компоновки), которые обычно рассматриваются отдельно (например, в /186,309/).
В первом приближении можно считать, что спецификатор есть объединение описаний фильтров данных и одного или нескольких компонентов документа. Описания фильтров данных задаются в том же виде, как и для фильтров данных как отдельных КМИ, н дают возможность статического задания правил отбора сведений для формирования документа (например, если формируется список сделанных прививок от полиомиелита, то в спецификаторе явно указывается отбор сведений по типу прививки). В случае необходимости усечения получаемой выборки непосредственно во время формирования документа при интерпретации спецификатора могут быть указаны фильтры данных, условия которых также будут учтены (например, фильтр "пациенты 10-го участка" в приведенном выше случае даст возможность динамически ограничить получаемый список прививками только но 10-му участку).
Каждый компонент документа может быть одним из типовых компонентов документа (ТКД): надписью, список или таблицей, причем ТКД допускают определенную возможность композиции - элементом списка может быть таблица, а содержимым ячейки таблицы - список или надпись и т. д. Различие между списком и таблицей заключается в том, что в список помещаются строки, каждая из которых формируется по одной строке выборки, а в таблице при формировании содержимого ячеек доступна только вся выборка, и оперировать можно с ее характеристиками — сумма значений поля, объем выборки и т. д., в том числе путем использования этих характеристик как аргументов функции пли операндов арифметического выражения.
Описание каждого ТКД в общем случае включает в себя три группы сведений:
дополнительные условия выборки, формируемые по содержимому четвертых разделов номенклаторов и дополняющих действующие правила построения выборки на период формирования данного ТКД (для таблиц такие условия могут быть заданы и для отдельных строк и столбцов);
сведения, определяющие содержание надписей, элементов списков и ячеек таблиц через элементы содержимого первого, второго и третьего разделов номенклаторов (в зависимости от вида ТКД);
сведения, определяющие правила композиции, представления и отображения содержимого ТКД (заголовки, сортировки, нумерация, стили и форматы и т. д.).
Использование спецификатора обеспечивается как ассоциативными процедурами элементов номенклаторов, которые внедрены в спецификатор,
так и процедурами, обеспечивающими интерпретацию вершин ИСФ спецификатора ’’надпись", "список" и "таблица".
Фильтр данных и спецификатор являются КМИ, которые могут быть выполнены, то есть подвергнуты конкретизации (по правилам, описанным в п. 3.3) и интерпретации, причем выполнение фильтра всегда осуществляется в контексте выполнения спецификатора.
Процесс интерпретации спецификатора может быть описан следующим образом:
по конъюнкции статических правил отбора сведений, содержащихся в спецификаторе, и содержимого указанных пользователем фильтров данных определяется выборка, на которой будет формироваться документ;
осуществляется последовательное формирование компонентов документа (с учетом возможности “вложенности" ТКД процесс формирования компонента "верхнего" может иметь рекурсивный характер).
Поскольку в процессе формирования документа правила отбора сведений (содержимое текущей выборки) могут неоднократно изменяться как наложение и снятие дополнительных условий, текущие правила определяются через стековый механизм.
Результатом выполнения спецификатора является документ - совокупность сигнатуры и структурированных сведений. Сигнатура представляет собой сведения о том, как именно был конкретизован спецификатор, по которому впоследствии был сформирован именно данный документ. Установление соответствия между структурными элементами документа, описанными в его спецификаторе, и сведениями, содержащимися в самом документе, осуществляется в два этапа: автоматическая конкретизация спецификатора по сигнатуре и сопоставление вершин "надпись”, "список" и "таблица” ИСФ конкретизованного спецификатора со списками данных в документе. Этот процесс имеет место при визуализации документа (представлении его в виде
текста) и при использовании содержимого документа в интересах формирования других документов (см. ниже). Таким образом, передаче документа между ФЕ фактически передаются только сигнатура и предметные сведения, входящие в документ. Наличие у ФЕ-получателя спецификатора полученного документа последующие визуализация документа и использование содержащихся в нем сведений затруднений не вызывают, чем и обеспечивается в том числе независимость процессов пересылки и обработки документов от вычислительной платформы и используемых программных средств.
Возможность формирования документов по содержимому ранее сформированных документов представляет собой мощное средство агрегации и интеграции отчетно-аналитической информации. По сути, используемые при этом теги задают правила извлечения сведений из имеющихся документов, их компоновки и (или) использования при вычислении элементов компонента формируемого документа. Например, из списка можно "вырезать" один или несколько столбцов, из таблицы ячейку или множество ячеек и т. д., и использовать строки, столбцы, ячейки в том числе в формулах для вычисления, например, значений ячеек формируемой таблицы (например, получив таблицы по заболеваемости от множества учреждений, можно построить не только сводную таблицу, но и таблицу, характеризующую распределение нозологии и частоты заболеваний по району, городу и т. д.). Будучи один раз указанными в спецификаторе, данные правила могут быть применены к различным ранее сформированным документам, выступающим носителями конкретных агрегируемых и интегрируемых сведений. Процессы агрегации и интеграции MOiyi носить многоступенчатый характер, позволяя получать необходимый сводный документ путем агрегации и интеграции сведений из сводных документов более "низкого" уровня интеграции - рис. 4.9.
Рнс.4.9.
Пример последовательности формирования
документов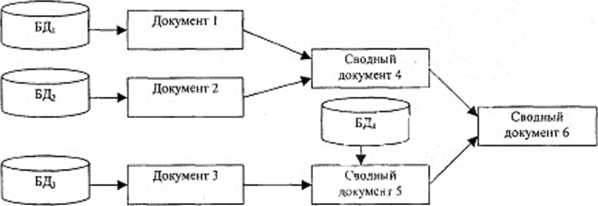
Описанная выше организация процессов создания и обработки документов в наиболее полной мере отвечает потребностям процесса интеграции отчетно-аналитической информации в многоуровневой системе управления благодаря возможностью адаптации процессов интеграции информации и единству построения информационно-лингвистического обеспечения.
Адаптация к изменениям содержимого информационных потоков достигается:
возможностью модификации (наращивания) содержания номенклатора понятий;
возможностью описания новых форм документов с пересылкой их спецификаторов всем заинтересованным пользователям системы и отказа от использования спецификаторов документов, применение которых прекращено.
Единство построения информационно-лингвистического обеспечения реализуется:
использованием единого номенклатора (группы номенклаторов);
возможностью обмена между пользователями системы номенклатора- ми, спецификаторами и содержанием документов в единой форме представления, определяемой выбранным языком представления;
централизованным выполнением действий по ведению номенклаторов и разработке спецификаторов документов, используемых в СИОЛИ.
Данная методика построения СИАОИ использована при создании семейства ряда программных комплексов лечебно-профилактических учреждений ("Автоматизированная система профилактических осмотров детского населения АСПОН-Дт" /310/» "Управление иммунизацией" /311/)» а также при создании региональной системы мониторинга врожденных пороков развития, охватывающей множество разнородных лечебно-профилактических учреждений и Городской консультативно-диагностический медико-генетический центр г. С-Петербурга /303/. Кроме того, рассматриваемая методика представляет собой достаточно перспективный подход к построению подсистем сбора результатов разного рода мониторинга, интерес к которым возрастает в последнее время /30,33/.
Концептуальная модель синтаксически вариантной аналитической информационной системы и методика ее предметной адаптации
Создание и внедрение аналитических информационных систем (АИС), основанных на применении технологий хранилищ и интеллектуального анализа данных, в настоящее время рассматривается как один из наиболее перспективных подходов к созданию высокоэффективных систем поддержки принятия решений на основе применения современных информационных технологий» математического аппарата и средств вычислительной техники /312-315/.
Главной предпосылкой появления в начале 90-х годов концепции АИС как отдельного класса ИС явилось осознание возможности принципиально нового подхода к осуществлению сбора и анализа информации в системах стратегического и оперативного планирования и управления» основанного на:
использовании разнородных источников данных в едином кибернетизированном информационном пространстве (или инфосфере);
возможности современных средств вычислительной техники по хранению массивов информации большого объема для осуществления ретроспективного анализа и прогнозирования.
Базовыми компонентами АИС по /68,316 - 325/ являются: аналитическая оболочка (АО), реализующая технологию интеллектуального анализа данных (ИАД) (Data Mining) и основанная на совокупности методов количественных и качественных исследований сверхбольших массивов разнородных ретроспективных данных;
информационная подсистема, основанная на технологиях хранилищ данных (ХД) (Data Warehouse), витрин данных (ВД) (Data Mart) и оперативного анализа данных (On-Line Analytical Processing, OLAP);
соответствующим образом организованные вычислительная среда и средства сбора информации, реализация которых базируется на известные, апробированные технологии и средства.
Авторами работ /68, 312, 314, 316 - 318/ и др. утверждается, что комплексное использование перечисленных технологий позволяет реализовать следующие возможности:
выявление скрытых закономерностей и факторов; количественная оценка факторов влияния и угроз; использование имеющегося опыта на основе поиска прецедентов; высокодостоверный прогноз эволюции объекта исследования. Основными задачи, решение которых возлагается на АИС, являются: оценка текущего и прогнозируемого состояния объекта управления и среды его функционирования;
обнаружение и исследование скрытых закономерностей, факторов, тенденций и взаимосвязей;
агрегация и интеграция информации, необходимой для обоснования и принятия решений;
формирование альтернативных решений и поддержка выбора "оптимального" в соответствии с заданным критерием и результатами анализа сценариев развития ситуаций;
моделирование процесса эволюции состояния объеюа в нестационарной неоднородной среде и т. д.
Следует отметить, что:
содержательное наполнение аналитических информационных систем в большой степени зависит от специфики предметной области и объекта управления, однако формальных методов его определения на сегодняшний день не существует, и выбор конкретных математических методов и обрабатываемых данных осуществляется исключительно эвристически с последующим уточнением в ходе применения системы:
направление исследований, связанное с созданием аналитических информационных систем еще находится в начальной стадии своего развития, оно определилось и бурно развивается с середины 90-х годов, поэтому в настоящее время имеются только лишь отдельные образцы соответствующих инструментальных средств и некоторый опыт их создания и применения;
практически отсутствует отечественный опыт разработок в данной области.
В то же время интерес к АИС в настоящее время чрезвычайно высок, и прежде леею - со стороны органов государственного управления, силовых структур, крупных холдингов и банковских структур (достаточно посмотреть на перечень материалов на открытом в 2000г. сайте www.olap.ru). Однако имеющиеся коммерческие образцы систем НАД (изделия Microsoft, Oracle, SAS Institute и др.) при своей достаточно высокой стоимости имеют весьма существенный недостаток - сочетание фиксированного набора средств мате-
магического инструментария с частными программно реализованными методиками решения задач анализа (/174, 326, 327/ и др.). Это приводит как к существенному ограничению областей применения указанных систем и решаемых задач управления, так и к высокому риску неверного выбора потенциальными пользователями инструментария, адекватною решаемым ими задачам. Общая ситуация с применением АИС осложняется еще и слабой насыщенности рынка, отсутствием развитых мехашпмов анализа опыта применения систем ИАД и уникальности прагматических аспектов их использования (более того, в современных условиях сам факт, а также методики и результаты применения систем ИАД зачастую приобретают статус "ноу хау" /328/).
Таким образом, при создании АИС основной проблемой становится обеспечение корпоративной деятельности множества экспертов с динамической адаптацией множества средств хранения данных и инструментов ИАД к классам решаемых задач и предметным областям. При этом каких-либо ограничений на используемые частные методики ИАД, состав математического инструментария, а также задачи и области применения АИС на момент ее разработки принципиально не накладывается, так как функциональные требования к АИС в части объектов анализа, классов решаемых задач, методов и схем их решения на момент создания АИС зачастую могут быть определены только предположительно, а области их применения могут характеризоваться большой степенью неопределенности и высокой динамикой (что, например, имеет место при применении АИС в интересах информационной борьбы и особенно - защиты информации /329 - 331/). Вышеизложенное порождает потенциальную неоднозначность в проектировании АИС, неразрешимую в рамках традиционных архитектур и технологий создания корпоративных информационных систем.
По результатам анализа подходов к созданию адаптивных программных систем и опыта применения метода метауправления были сформулированы
два базовых принципа системной интеграции, обеспечивающих .формирование АИС нового поколения /25,27,32,61/:
многоуровневый подход к синтезу архитектуры и профилей АИС и формализации процессов ее функционирования;
создание АИС как синтаксически вариантной информационной системы, вариантность которой реализуется на основе метауправления в виде совокупности процессов формирования и обработки компонентов метаинформации.
Результатами применения многоуровневого подхода к синтезу архитектуры и профилей АИС и формализации процессов ее функционирования являются (рис. 4.9):
декомпозиция процессов функционирования АИС; потенциальный состав пользователей АИС и распределение их возможностей и обязанностей с позиций участия в функционировании АИС;
двухступенчатый характер хранения и обработки предметный сведений; функциональная, организационная и техническая структуры, архитектура и профили АИС и соответствующие отношения отображения (структуры
на профили, а профилей - на архитектурные компоненты).
Процессы функционирования АИС, являющиеся основой для синтеза ее функциональной структуры, определяются путем выделения управляющего, основного (содержательного) и обеспечивающего процессов, и формализуются как три взаимосвязанных уровня управления функционированием АИС (рис. 4.10):
стратегический (управляющий) — уровень управления охватываемой предметной областью и классом потенциально решаемых задач в рамках динамически формулируемых конкретных проблем анализа и прогностики, представляющий собой процесс управления структурой и содержанием хра-
нммых предметных сведений, а также множеством программно реализованных математических методов, обеспечивающих решение задач ИАД
Рис. 4.9. Объекты и результаты применения многоуровневого подхода
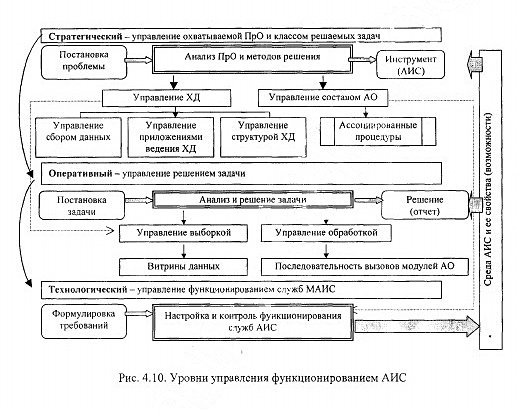
оперативный (основной) - уровень отдельных задач в рамках общей решаемой проблемы, на котором по отношению к каждой задаче выполняются этапы се постановки, анализа и решения;
технологический (обеспечивающий) — уровень функционирования служб ЛИС, составляющих ее технологические профили (телекоммуникации, разграничение доступа, защита информации, архивация результатов решения задач и т. д.).
Потенциальный состав пользователей ЛИС, являющийся основой для синтеза организационной структуры, определяется как совокупность еле-
дующих должностных лиц, контура информационного взаимодействия которых показаны на рис. 4.11:
лицо, принимающее решения (ЛПР) - руководитель, осуществляющий постановку проблем и задач и являющийся для АИС конечным потребителем получаемых результатов;
предметный эксперт (ПЭ) - специалист предметной области, несущий основную нагрузку по определению состава и содержательному анализу предметных сведений, а также результатов их обработки;
эксперт-аналитик (ЭА) - специалист, осуществляющий выбор методик решения задач и выполняющий их решение на основе формальных методов обработки;
администратор данных (АД) - лицо, выполняющее действия по сбору необходимых предметных сведений и помещению их в хранилище данных;
системный интегратор (СИ) - лицо, осуществляющее управление службами АИС, ее конфигурированием и содержательным наполнением.
Двухступенчатый характер хранения и обработки предметный следует из специфики функционирования АИС и предполагает разделение информационного хранилища на две части - хранилище данных и витрины данных (см. рис. 4.11). В первом приближении хранилище данных предназначено для хранения всех предметных сведений, собранных АД и совместно используемых другими пользователями путем выбора необходимых сведений и копирования их в витрины данных. Последние представляют собой локальные информационные хранилища, цикл жизни которых ограничен рамками процесса решения одной задачи. В витринах данных размещаются как исходные предметные сведения, необходимые для решения задачи, так и все результаты, получаемые в процессе ее решения. Совокупность ХД и БД, а также информационных связей (потоков данных) является основой для синтеза информационной структуры АИС. Детальное описание разработанных вариантов
функциональной, организационной, информационной и технической структуры АИС, ее профилей и архитектуры приведено в /59/.
Рис.
4.11. Состав и взаимосвязи рабочих мест
пользователей АИС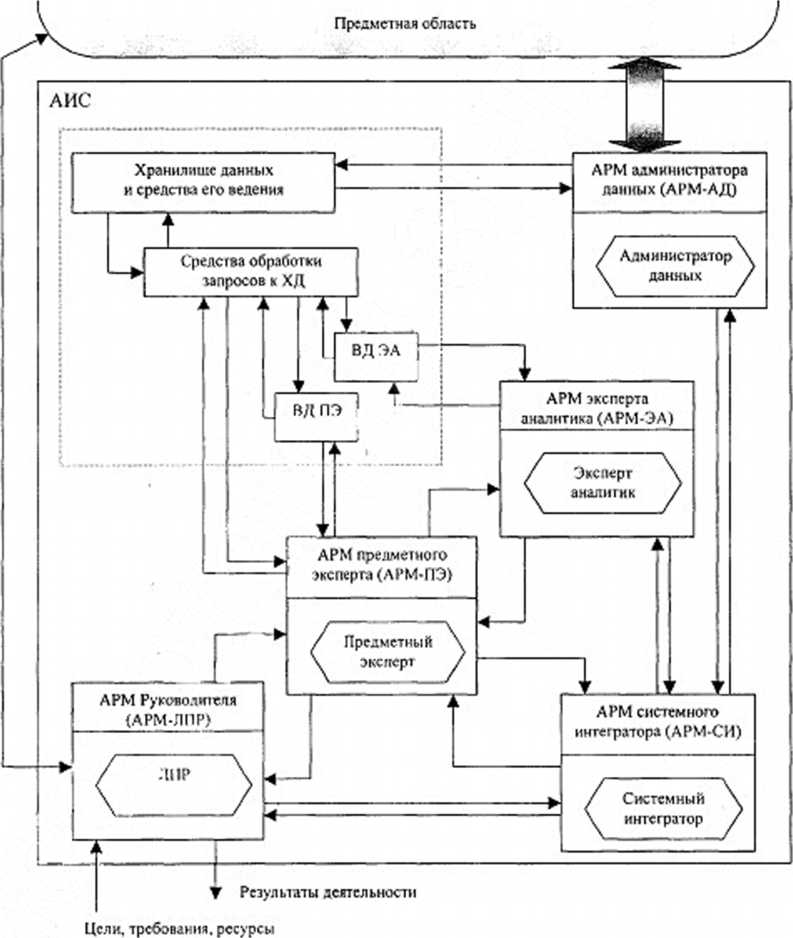
Второй принцип построения АИС - создание ее как СВИС - является приложением концептуальных и методологических основ построения ИСМУ, изложенных в главах 2 и 3, к построению АИС с учетом следующих особенностей ее архитектуры и организации функционирования:
два уровня хранения данных - наличие хранилища данных и витрин данных, заполняемых по содержимому ХД в интересах решения отдельных задач;
наличие в составе пользователей АИС системного интегратора, который может осуществлять разработку и модификацию библиотек ассоциированных процедур и математического инструментария как часть действий стратегического уровня управления функционированием АИС (см. рис. 4.10).
В целом применение метауправления при построении АИС во многом аналогично его применению в СИОАИ (см. п. 4.3 и приложение 10), основные отличия заключаются в следующем:
номенклаторы доменов соответствуют структуре ХД, имеют только два раздела ("единичные сведения" и "правила отбора сведений") и используется для формирования запросов к ХД, результатом выполнения которых является изменение содержимого БД;
запросы к ХД по своей структуре аналогичны фильтрам данных, описанным в п. 4.3. дополненным перечнем атрибутов, значения которых должны быть помещены в формируемую выборку;
поскольку логическая структура ВД принципиально динамична, для ее описания используется отдельный вид КМИ - спецификации таблиц ВД, создаваемые и изменяемые при помещении выборок в ВД;
выполнение модуля АО рассматривается как процесс формирования документа, исходными данными для которого являются содержимое ВД, и результат которого (документ и его спецификации) также помещается в ВД, благодаря чему содержание процесса аналитической обработки данных зада
ется с помощью запросов на выполнение этапов решения задачи, а формирование этих запросов поддерживается номенклатором модулей и операций АО;
неконкретизованные запросы к ХД и на выполнение этапа решения рассматриваются как соответствующие шаблоны, представляющие собой КМИ отдельного типа.
В целом синтаксически вариантная АИС представляет собой ИСМУ с характеристическим вектором <1,2,1,1,1> и логической структурой, показанной на рис. 4.12. Существенно, что логическая структура синтаксически вариантной АИС имеет некоторую симметрию по используемым КМИ и программным средствам их выполнения, значительно упрощающую реализацию подлежащих созданию программных средств.
Описанные выше особенности построения АИС и применения в ее конструкции метауправления приводят к тому, что в ней могут быть выделены процессы метауправления трех типов, которые с использованием обозначений, приведенных на рис. 4.12, можно определить следующим образом:
управление структурой ХД и составом модулей АО (то есть собственно управление синтаксисом АИС)
({< Бнхл»^нхд>}» Rju) ^ (<$хд, Охд>, Pr), ({a,X(a),Y(a)}) -^(Sao) управление заполнением таблиц БД по содержимому ХД, и, как следствие - составом и содержанием спецификаций таблиц ВД
Ою(Оп(Кзхд), рхдЛвд» Ктвд) (Т'вд, Ктвд) управление содержанием выполняемого этапа решения как композиции вызовов модулей АО с указанием исходных данных для работы каждого модуля, и, как следствие - составом и содержанием документов и их спецификаций в ВД
Ом(Оо(Кзр), Твд, КтвД| Дод, Кдвд) (Т вд»К твд» Двд Д^двд) • Представление метаинформации в синтаксически вариантной АИС может быть обеспечено XML-приложением, являющимся расширением XML-
приложения для базовой модели представления метаинформации - по аналогии, как это сделано в рамках методики, описанной в п. 4.3 (см. приложения 9 и 10), а все многообразие программных средств, обеспечивающих формирование и обработку КМИ, сводится к соответствующем образом настроенному XML-редактору, а также программам конкретизации и интерпретации с использованием механизма ассоциированных процедур (см. пп. 3.3 - 3.5).
Рис. 4.12. Логическая структура синтаксически вариантной АИС
Указанные
выше программные средства составляют
ядро информационной подсистемы
АИС, фрагмент
структуры
которой (в части средств, обеспечивающих
использование метауправления) приведен
на рис. 4.13.
Рис.
4.13. Фрагмент структуры информационной
подсистемы АИС
Предметная адаптация синтаксически вариантной АИС фастически является процедурой изменения ее синтаксиса и сводится к настройке ее информационной подсистемы, предполагающей выполнение системным интегратором АИС ряда действий, описанных далее.
Разработка номенклатора домена предметной области осуществляется ПЭ с помощью средства создания и редактирования номенклаторов. Разработанный номенклатор помещается в репозитарий номенклаторов.
Разработка логической и Физической моделей данных, соответствующих номенклатуру домена, выполняется либо с использованием специальных инструментальных средств, либо "вручную'1. Результатом является описание разработанных логической и физической моделей, используемое в дальнейшем для модификации структуры таблиц БД хранилища данных.
Модификация структуры хранилища данных заключается в реализации разработанной физической модели данных путем внесения соответствующих изменений в системный каталог ХД.
Разработка ассоциированных процедур, поддерживающих использование номенклатора, выполняется с использованием принятых в АИС средств программирования.
Разработка приложений для ведения основного Фонда хранилища данных выполняется с использованием средств программирования, принятых в АИС. Разработанные средства, обеспечивающие ввод и модификацию подлежащих хранению в ХД данных, передаются на АРМ администратора данных.
В целом описанный выше подход к созданию АМС как СВИС приводит к тому, что все изменения в синтаксисе системы, продиктованные необходимостью ес адаптации, локализуются в номеиклаторах, каталогах ХД библиотеке ассоциированных процедур и библиотеке модулей аналитической оболочки. Такой способ построения АИС позволяет осуществлять ее модификацию и модернизацию непосредственно в процессе ее эксплуатации, обеспечи- пая высокую
адаптируемость системы, и позволяет преодолеть трудности, связанные с потенциальной неопределенностью в аналитическом инструментарии решения задач, имеющиеся на момент создания системы.
Кроме того, ввод в эксплуатацию АИС, созданных как синтаксически вариантные, приводит к ситуации, когда их свойства становятся динамичными и уникальными для каждого экземпляра эксплуатируемой системы. Это повышает устойчивость и скрытность АИС, подлежащих использованию в потенциально агрессивных средах, а также как элемента систем управления оборонного характера /296, 332, 333/. В этом случае сама парадигма серийных средств воздействия и средств противодействия с фиксированными так- тико-техническими характеристиками становится неприемлема при планировании, например, информационных операций /4, 334, 335/ и иных боевых действий, если в составе системы управления, являющейся объектом предполагаемого воздействия или его частью, имеется синтаксически вариантная АИС. Данное положение позволяет рассматривать создание синтаксически вариантных АИС как одно из эффективных направлений перспективного развития вооружения и военной техники, соответствующее общей стратегии в этой области на ближайшее десятилетие /4/.
Полное описание методики построения синтаксически вариантной АИС приведено п монографии /59/, а ее апробация осуществляется в настоящее время в Военном университете связи в рамках создания макетной версии многоцелевой АИС, концепция которой описана в /68/. Опыт выполненных к настоящему времени работ, в частности, показал, что применение метауправления позволяет существенно упростить создание информационной подсистемы АИС аа счет унификации средств формирования и обработки КМИ, а также достоинств XML как средства представления КМИ, и сосредоточить основные усилия на методах ИАД и их реализации в виде модулей АО /71/.
Выводы по четвертой главе
Использование метауправления позволяет в более полной мере по сравнению с существующими средствами информационного моделирования привлечь экспертов к формированию предметных спецификаций, освободив их от необходимости знания схем формализации, повысить корректность спецификаций и (или) сократить количество итераций по достижению требуемой полноты и корректности ИнМ, уменьшить потребности в ресурсе аналитиков, а также достичь высокой степени инвариантности программной реализации инструментальных средств информационного моделирования от схем и планов формализации конкретных объектов моделирования.
Применение двухуровневого построения текста имитационной модели, являющегося вариантом применения метауправления в построении САИМ, позволяет получить качественно более высокий уровень автоматизации работ, связанных с применением имитационного моделирования, чем это обеспечивают разного рода системы и пакеты имитационного моделирования, сократить затраты на проведение имитационного моделирования.
Применение метауправления для описание содержания, правил формирования и формы представления отчетно-аналитических документов по содержимому базы данных и других, ранее сформированных документов, в терминах номенклаторов понятий прикладной области в интересах интеграции и агрегации отчетно-аналитической информации может быть реализовано в рамках разработанных методологических основ построения ИСМУ и даст эффективную возможность осуществления автоматизации сбора отчетно- аналитической информации в разнородных иерархически организованных системах управления организационно-технологическими системами некритического характера.
Создание аналитических информационных систем как синтаксически вариантных может рассматриваться как один из основных принципов их построения
необходимость которого продиктована спецификой применения АИС для решения задач идентификации и прогностики в динамичных средах.
Все приведенные в данной главе модели и методики соответствуют частным конкретным вариантам создания отдельных классов ИС как ИСМУ, а их реализация во многом облегчается унифицированностью средств формирования, конкретизации и интерпретации компонентов метаинформации благодаря общности разработанной модели представления метаинформации и моделям процессов формирования и конкретизации метаинформации, а также общей стратегией создания XML-Приложений как лингвистического средства представления метаинформации, а при необходимости - и предметных сведений.
В целом переход к синтаксически вариантным информационным системам представляется целесообразным направлением развития информационных технологий, способным коренным образом изменить используемые принципы программной реализации функциональных приложений в тех областях, где применение традиционных технологий создания программных средств нерентабельны из-за короткого жизненного цикла и единичного применения создаваемых программных средств (как в случае информационного или имитационного моделирования), либо где имеются сложности, связанные с потенциальной неопределенностью требований к создаваемой ИС и их высокой последующей динамикой (как, например, это имеет место для АИС), либо с разнородностью взаимодействующих средств и возможной нетиповой обработкой структурированных сведений (СИОАИ).