

Физическая структура. Структурные характеристики.
Физическая структура - то, как представляется обрабатываемая информация в памяти компьютера, как видит ее системный программист – разработчик операционных систем и систем управления базами данных
Типовые операции над информационными элементами
- выделение элементов определенного типа среди других (необходимы: имя (идентификатор), размер и адрес элемента);
- сравнение значений элементов между собой и с литералами (константами) – необходимы те же характеристики плюс типы внутреннего представления (физические структуры) сравнивамых элементов;
- над элементами записей данными могут выполняться арифметические операции, которые требуют тех же самых структурных характеристик;
- переход к другому связанному элементу структуры – необходим адрес связанного элемента
Структура данных - множество информационных элементов и связей между ними.
Для работы с физическими представлениями структур различных уровней (записей, файлов и баз данных) необходимы следующие структурные характеристики:
имя элемента структуры;
размер элемента структуры;
адрес элемента;
адрес связанного элемента;
тип внутренней структуры элемента .
Анализ возможных способов физической организации информации различных уровней рассматривали в зависимости от:
способа представления собственно информации об объектах предметной области хранимой в памяти компьютера;
способа представления структурных характеристик (явного или не явного);
способа хранения (совместного или автономного) структурных характеристик и собственно информации.
Элементами структуры являются данные.
Кроме естественного представления элементов – данных (символьное, числовое, дата и т.п.) в системах обработки данных часто используется кодированное представление, когда значения символьных данных, значительных по размеру или определенных на одних и тех же словарях (доменах), заменяются компактными, чаще всего цифровыми кодами.
Наиболее часто используют два способа формирования кодов: порядковое и серийно-порядковое. ( сущ-ет также двоично-позиционное кодирование)
Последовательно-смежная организация и списковая организация.
Под организацией значений данных понимают относительно устойчивый порядок расположения записей данных в памяти ЭВМ и способ обеспечения взаимосвязи между записями.
Организация значений данных (далее называемая просто организацией данных) может быть линейной и нелинейной. При линейной организации данных каждая запись, кроме первой и последней, связана с одной предыдущей и одной последующей записями. У записей, соответствующих нелинейной организации данных, количество предыдущих и последующих записей может быть произвольным.
Линейные методы организации данных различаются только способами указания предыдущей и последующей записи по отношению к данной записи. Но это приводит к тому, что алгоритмы, эффективные для одних методов организации данных, становятся неприемлемыми для других методов.
Среди линейных методов выделяются последовательная и цепная организации данных. При последовательной организации данных записи располагаются в памяти строго одна за другой, без промежутков, в той последовательности, в которой они обрабатываются. Последовательная организация данных обычно и соответствует понятию массив (файл).
Записи, составляющие массив, с точки зрения способа указания их длины делятся на записи фиксированной, переменной и неопределенной длины. Записи фиксированной (постоянной) длины имеют одинаковую, заранее известную длину. Если длины записей неодинаковы, то длина указывается в самой записи. Такие записи называют записями переменной длины. Вместо явного указания длины записи можно отмечать окончание записи специальным символом-разделителем, который не должен встречаться среди информационных символов значения записи. Записи, заканчивающиеся разделителем, называются записями неопределенной длины.
При последовательно-смежной организации логически связанные элементы физически размещаются в памяти непосредственно друг за другом, без разрывов.
При использовании адресных указателей логически связанные элементы физически могу размещаться в любых участках памяти, и каждый элемент содержит адрес связанного с ним другого элемента. Такая организация хранения называется цепной или списковой.
Решение целого ряда задач обработки данных требует применения таких методов организации данных, которые позволили бы связать физически разнесенные в памяти данные в логическую последовательность, определяющую порядок их обработки. Простейшим методом, применяемым для этих целей, является списковая (цепная) организация данных.
Списком называется множество записей, занимающих произвольные участки памяти, последовательность обработки которых задается с помощью адресов связи. Адресом связи некоторой записи называется атрибут, в котором хранится начальный адрес или номер записи, обрабатываемой после этой записи. Обычная последовательность обработки записей в списке определяется возрастанием значений ключа в записях.
В списке выделяется собственная информация (записи с содержательными сведениями) и ассоциативная информация, т. е. все адреса связи.
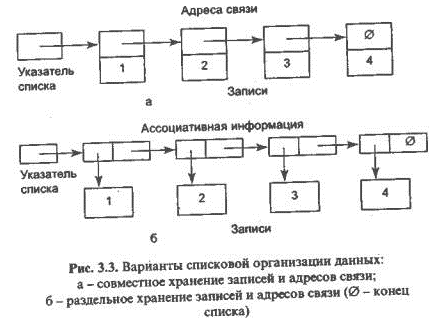
Возможны два способа хранения структурных характеристик и собственно информации об объектах – совместное и автономное.
В последовательных структурах элементы логически следуют друг за другом, располагаясь в смежных участках памяти. В списковых - связи между элементами данных передаются посредством адресных указателей. Для отражения связей между элементами данных используются символические указатели.
Символическая связь – повторение значения поля, по которому производится связывание. Обычно связывающий компонент – идентификатор данных. Связи между элементами данных отражаются с помощью битовых структур. В этом случае кроме файла, содержащего сведения об объектах создаются 1 или несколько битовых структур (битовых векторов или матриц), показывающих взаимоотношения элементов основного файла. Совокупность индекса и индексного массива является индексной структурой. В БД обычно используют довольно сложные многоуровневые логические структуры данных. Сокращение объема памяти в БД занимаются специализированные архиваторы, являющиеся утилитами БД. Проектирование физических и логических структур данных тесно связано между собой.
Последовательная организация хранения данных (ПОХД).
ПОХД обладает следующими преимуществами:
1.отсутствие дополнительной адресной информации и плотное размещение данных в запоминающей среде, приводящее к сокращению объема памяти.
2.возможность использования любых носителей информации.
3.сокращение времени обработки при условии, что порядок размещение на носителе совпадает с требованием в порядке обработки.
4.простота организации данных и манипулирование ими, так как идет увеличение объема памяти и уменьшение цены, то значимость 1 и 2 фактора снижается.
Последовательные структуры данных имеют недостатки:
1.неудобство корректировки.
2.необходимость разворачивания нелинейных логических структур в линейные.
3.трудности в обеспечении адекватного, интегрированного отображения предметной области.
4.длительность выборочного поиска.
5.адаптация новых элементов данных последовательную структуру должно выполняться согласно логическому порядку следующего элемента, что вызывает необходимость физического перемещения данных.
В последнее время в связи с широким распространением реляционной БД, использование последовательных данных в файлах увеличивается. Многие реляционные СУБД предусматривают организацию хранения каждого отношения данных в качестве видимого файла.
Списковая организация хранения данных.
Заключается в использование адресных указателей для связей элементов данных. Различают списковую организацию с совместным и раздельным хранением, с объектной, собственной, ассоциативной, адресной информацией, однонаправленные и двунаправленные списки. Такая классификация списковых структур традиционная. Взависимости от характера связывания элементов, списковая структура может связывать однотипные элементы данных в единую структуру – однородный список. На одном и том же множестве элементов может быть задано несколько связей, каждая из которых выделяет подмножество элементов, это списки – многосвязные. Если информация в списках одного типа, то информация называется гомогенной. Если информация разнородна, то список называется гетерогенным.
списковая организация обладает преимуществами:
1.возможность естественным путем передавать сложные логические взаимодействия между элементами, при корректировках списковых структур добавление и анулирование элементов в списках производится без физического перемещения элементов путем изменения адреса элементов, при этом память может быть повторно использована вновь добавляемым элементом. Новые элементы могут быть привязаны к любому месту памяти.
2.позволяют динамически наращивать состав БД без существенного изменения существующих ее частей.
3.устраняют дублирование данных (избыточность), позволяют на одном и том же множестве элементов обеспечивать их различную упорядоченность.
4.просто могут быть организованы в любой прямоадресной памяти.
НЕДОСТАТКИ:
1. Большой расход памяти на указатели.
2. Физический разброс данных по носителю, увеличивающий время обработки данных.
3. Потеря адреса связи в каком-либо элементе списка, делает недоступным всю оставшуюся часть структуры, а искажение адреса приводит к аварийным ситуациям.
4. Списковая структура нуждается в сложном управлении свободной памяти.
5. Эффект дробления памяти приводит к необходимости реорганизации массива.
Индексные файлы
Индексные файлы (индексно-прямые, индексно-последовательные, В-деревья)
Индексные файлы могут представить как файлы состоящие из 2-х частей: индексная часть и основная часть. Различают 2 типа файлов:
- с плотным индексом или индексно-прямые файлы
- с неплотным индексом (неполным) или индексно – последовательные файлы
значение ключа – это значение первичного ключа
Для индексно-прямых файлов поиск начинается в индексной области, где применяется двоичный алгоритм поиска, потом путем прямой адресации обращение к основной области по конкретному номеру записи.
При вставке и удалении узлов производится реструктуризация дерева с тем, чтобы сохранить его сбалансированность.
Индексные файлы
(автономное хранение характеристики СВЯЗЬ )
3 20 1 16
Физич. адрес |
Номер физич.записи |
Ф.И.О. |
Пол |
Национальность |
1 |
25 |
Иванов И.И. |
М |
русский |
41 |
96 |
Климук Н.И. |
Ж |
украинка |
81 |
33 |
Ковалев В.А. |
М |
белорус |
121 |
330 |
Козлов Н.А. |
М |
русский |
161 |
111 |
Кузнецова Н.В. |
Ж |
азербайджанка |
201 |
110 |
Петренко И.П. |
Ж |
украинка |
241 |
100 |
Петров П.И. |
М |
русский |
281 |
112 |
Рабинович И.Н. |
Ж |
еврейка |
321 |
35 |
Сидоров В.В. |
М |
русский |
Индекс по Ф.И.О. Индекс по ПОЛ
Ф.И.О. |
№ записи |
|
Пол |
№ записи |
Иванов И.И. |
25 |
|
Ж |
96 |
Климук Н.И. |
96 |
|
Ж |
111 |
Ковалев В.А. |
33 |
|
Ж |
110 |
Козлов Н.А. |
330 |
|
Ж |
112 |
Кузнецова Н.В. |
111 |
|
М |
25 |
Петренко И.П. |
110 |
|
М |
33 |
Петров П.И. |
100 |
|
М |
330 |
Рабинович И.Н. |
241 |
|
М |
100 |
Сидоров В.В. |
281 |
|
М |
35 |
Индекс по НАЦИОНАЛЬНОСТЬ Таблица соответствия
Национальность |
№ записи |
|
№ записи |
Адрес |
азербайджанка |
111 |
|
25 |
1 |
белорус |
33 |
|
33 |
81 |
еврейка |
241 |
|
35 |
281 |
русский |
25 |
|
96 |
41 |
русский |
330 |
|
110 |
201 |
русский |
100 |
|
111 |
161 |
русский |
281 |
|
330 |
121 |
украинка |
96 |
|
100 |
241 |
украинка |
110 |
|
330 |
321 |
Возможно составление индексного файла по нескольким атрибутам:
- пол, Ф.И.О.,
- национальность, Ф.И.О.
Учитывается иерархия согласно порядку следования атрибутов,
т.е. индексирование по Ф.И.О., пол или Ф.И.О., национальность бессмысленно
Индекс по НАЦИОНАЛЬНОСТЬ , Ф,И,О,
Прямое и инвертированное представление информации файла.