

3.3.2 Нумерация объектов
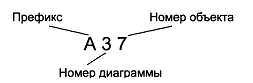
В DFD каждый номер функционального блока может включать в себя префикс, номер родительской диаграммы и собственно номер объекта (рис. 3.9). Номер объекта уникальным образом идентифицирует функциональный блок на диаграмме. Номер родительской диаграммы и номер объекта в совокупности обеспечивают уникальную идентификацию каждого блока модели.
Уникальные номера присваиваются также каждому хранилищу данных и каждой внешней сущности вне зависимости от расположения объекта на диаграмме. Каждый номер хранилища данных содержит префикс D (от английского Data Store) и уникальный номер хранилища в модели (например, D3).
Аналогично каждый номер каждой внешней сущности содержит префикс Е (от английского External entity) и уникальный номер сущности в модели (например, Е5).
Итак, диаграммы потоков данных (DFD) обеспечивают удобный способ описания передаваемой информации как между частями моделируемой системы, так и между системой и внешним миром. Это качество определяет область применения DFD — они используются для создания моделей информационного обмена организации, например модели документооборота. Кроме того, различные вариации DFD широко применяются при построении корпоративных информационных
систем.
Главн цель постр-ия иерархии DFD заключ-ся в том, чтобы сделать опис-ие системы ясным и понятным на кажд уровне детализ-и, а также разбить его на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
• размещать на каждой диаграмме от 3 до 6—7 процессов (аналогично SADT). Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса;
• не загромождать диаграммы несущественными на данном уровне деталями;
• декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов. Эти две работы должны выполняться одновременно, а не одна после завершения другой;
• выбирать ясн, отражающие суть дела, имена процессов и потоков, при этом стараться не исп аббревиатуры.
Первый шаг - построение контекстных диаграмм. Обычно при проектировании относительно прост систем строится единств-ая контектная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы. Перед построением контекстной DFD необходимо проанализировать внешние события (внешние сущности), оказывающие влияние на функционирование системы. Количество потоков на контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков на след уровнях диаграммы. Для сложн систем строится иерархия контекстн диаграмм. При этом контекстная диаграмма верхнего уровня содержит не единственный главный процесс, а набор подсистем, соединенных потоками данных. Контекстн диаграммы след ур-ня детализируют контекст и структуру подсистем.
Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Это можно сделать путем построения диаграммы для каждого события. Кажд событие представл-ся в виде процесса с соответств-ми входн и выходн потоками, накопителями данных, внешн сущностями и ссылками на друг процессы для описания связей между этим процессом и его окружением. Затем все построенные диагр-мы сводятся в одну диаграмму нулевого ур-ня. Кажд процесс на DFD, в свою очередь, может быть детализирован при помощи DFD или (если процесс элементарный) спец-ии. При детализ-ии должны выполняться след правила:
• правило балансировки — при детализ-ии подсистемы или процесса детализирующая диаграмма в качестве внешних источников или приемников данных мож иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с кот имеют информац. связь детализируемые подсистема или процесс на родит диаграмме;
• правило нумерации - при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т.д.
Спецификация процесса должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу.
Спецификация является конечной вершиной иерархии DFD. Решение о завершении детализации процесса и использовании спецификации принимается аналитиком исходя из следующих критериев:
• наличия у процесса относительно небольшого количества входных и выходных потоков данных (2—3 потока);
• возможности описания преобразования данных процессом в виде последовательного алгоритма;
• выполнения процессом единственной логической функции преобразования входной инф-ии в выходную;
• возможности описания логики процесса при пом спецификации небольш объема (не более 20-30 строк).
Спецификации должны удовлетворять следующим требованиям:
• для каждого процесса нижнего уровня должна существовать одна и только одна спецификация;
• спецификация должна определять способ преобразования входных потоков в выходные;
• нет необходимости определять метод реализации этого преобразования;
• специф-ия должна стремиться к огранич-ю избыточности — не следует переопределять то, что уже было определено на диаграмме;
• набор конструкций для построения спецификации должен быть простым и понятным.
Структурированный естеств язык применяется для читабельного, достаточно строгого описания спецификаций процессов. Он представл собой разумн сочетание строгости ЯП и читабельности естеств языка и состоит из подмнож-ва слов, организованных в определенные логич стр-ры, арифметических выражений и диаграмм. После построения законченной модели системы ее необходимо верифицировать (проверить на полноту и согласованность). В полной модели все ее объекты (подсистемы, процессы, потоки данных) должны быть подробно описаны и детализированы. Выявленные недетализированные объекты следует детализировать, вернувшись на предьщущие шаги разработки. В согласованной модели для всех потоков данных и накопителей данных должно выполняться правило сохранения информации: все поступающие куда-либо данные должны быть считаны, а все считываемые данные должны быть записаны.