

Распределенные БД. Технологии файл-сервер и клиент-сервер.
Распределенные бд. Технология клиент-сервер.
Файл сервер
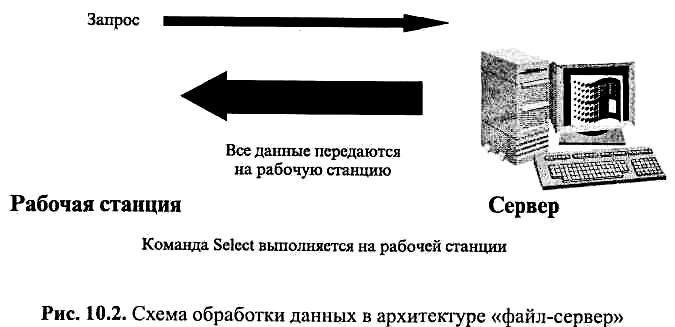
На рис. 10.2 представлена принципиальная схема обработки данных в архитектуре «файл-сервер». При использовании такой архитектурной модели основная обработка данных проводится на рабочей станции. Такая модель приводит к необходимости передачи больших объемов данных по сети, что увеличивает трафик, а это, в свою очередь, может привести к замедлению обработки данных, увеличению стоимости, снижению надежности и другим недостаткам.
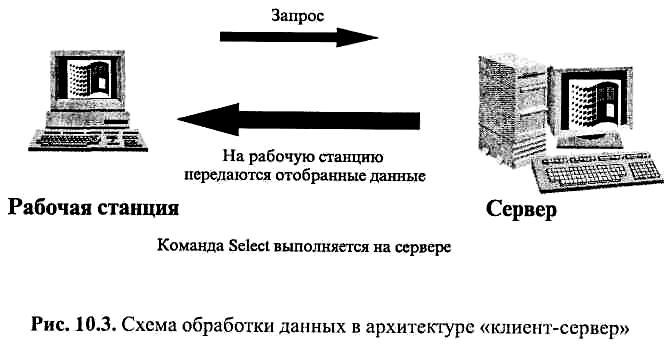
В системах с «клиент-серверной» архитектурой (рис. 10.3) основная обработка данных проводится на сервере.
«Клиент-серверные» системы имеют следующие преимущества:
снижение сетевого трафика за счет выполнения запросов на сервере;
оптимизация выполнения запросов;
возможность хранения бизнес-правил на сервере (ограничения целостности, хранимые процедуры, отражающие логику обработки);
возможность использования CASE-средств для генерации кодов серверных объектов (триггеров, хранимых процедур, текстов SQL-запросов);
управление пользовательскими привилегиями и правами доступа;
широкие возможности резервного копирования и архивации данных.
Сравнительные характеристики технологий «файл-сервер» и «клиент-сервер» приведены в табл. 10.4.
Таблица 10.4
Характеристика |
«Файл-сервер» |
«Клиент-сервер» |
Интенсивность сетевого трафика |
|
+ |
Обеспечение целостности данных |
|
+ |
Обеспечение безопасности данных |
|
+ |
Устойчивость к сбоям |
|
+ |
Сложность проектирования |
+ |
|
Сложность эксплуатации системы |
+ |
|
Ограничения на число пользователей |
|
+ |
Распределенные базы данных. Технология тиражирования.
Тиражирование данных - это асинхронный перенос изменений объектов исходной базы данных (source database) в БД, принадлежащим различным узлам распределенной системы. Функции тиражирования данных выполняет специальный модуль СУБД - сервер тиражирования данных, называемый репликатором (replicator). Его задача - поддержка идентичности данных в принимающих базах данных (target database) данным в исходной БД. Сигналом для запуска репликатора служит срабатывание правила (см. Раздел 2), перехватывающего любые изменения тиражируемого объекта БД. Возможно и программное управление репликатором посредством сигнализаторов о событиях в базе данных.
Тиражирование - используемая в РБнД технология, предусматривающая поддержку копий всей БД или ее фрагментов в нескольких узлах сети. Копия базы данных, являющаяся членом набора других копий, которые могут быть синхронизированы между собой, называется репликой. Копии БД обычно приближены к местам использования информации. Как синоним понятию «тиражирование» используется термин «репликация». Тиражирование является сравнительно новой технологией.
Процесс обновления реплик, при котором происходит передача обновляемых записей и других объектов и согласование дублирующихся данных, называется синхронизацией. Обмен данными между репликами может быть как односторонним, так и двусторонним. Кроме того, возможна синхронизация реплик под управлением синхронизатора. В отличие от собственно распределенных систем (систем с фрагментированием), в которых, как правило, при выполнении распределенных запросов реализуется протокол двухфазной фиксации, в системах с реплицированными базами данных обычно используется инструментарий асинхронной репликации.
В настоящее время многие известные СУБД предлагают пользователям возможности репликации. Но, как и во всякой новой области, терминология и подходы к реализации отличаются от системы к системе.
Совокупность данных, которые могут подвергаться тиражированию, называется публикацией.
В системах с тиражированием присутствуют все функции, присущие другим видам распределенных систем, плюс еще специфические функции, вызванные именно тиражированием. Это функции, обеспечивающие пересылку изменений всем узлам-пользователям; функции поддержания идентичности всех копий (реплик) БД; если эталонная база - единственная, то функции формирования базы данных-эталона и некоторые другие. Причем часть этих функций может быть совмещена на одном узле, а часть - отсутствовать, в зависимости от использованной технологии тиражирования.
Проблемы, возникающие при параллельном доступе, и пути их решения.
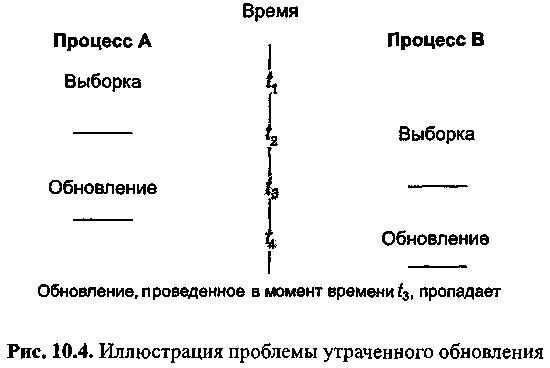
При параллельном выполнении операций над базой данных могут возникать некоторые проблемы. Одна из них - проблема утраченных (потерянных) обновлений (Lost update) - заключается в том, что если пользователи параллельно обновляют одни и те же данные, то запомненным будет то обновление, которое было проведено последним. Остальные обновления будут потеряны (рис. 10.4).
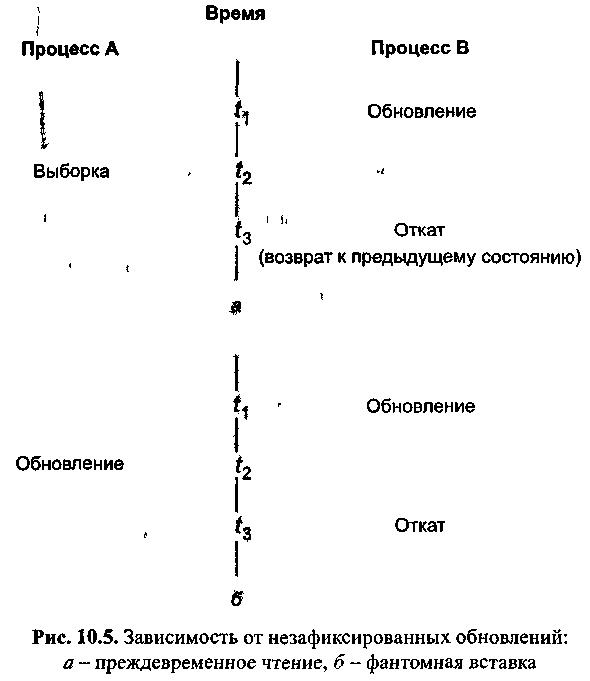
Другая проблема - зависимость от незафиксированных обновлений - состоит в том, что пользователь А может увидеть данные, которые уже были обновлены пользователем В, но эти обновления еще не были окончательно зафиксированы. Далее пользователь В может в силу [различных причин, например из-за выявленных ошибок ввода, провести откат базы данных в исходное состояние (рис. 10.5). Пользователь А в этом случае будет предпринимать действия над ошибочными (данными. Иногда для такого рода проблем используется термин преждевременное чтение (Dirty read).
Еще одна проблема может возникнуть, если пользователь проводит какую-то групповую обработку данных, не связанную с корректировкой данных, например вычисляет сумму или среднюю величину, а какие-то значения обрабатываемого множества в этот момент претерпевают изменения в результате выполнения параллельной транзакции. Иногда разделяют ситуации, когда проводится изменение существующих записей и когда осуществляется вставка новой записи. Первая проблема называется неповторяющееся чтение, а вторая - фантомная вставка.
Эта ситуация не приводит к искажению информации в базе данных и поэтому в некоторых ситуациях считается допустимой, Например в случае, если специалист проектирует форму отчета и в этом процессе получает черновые отчеты.