

Скалярная и векторная обработка
Под вектором будем понимать упорядоченный массив элементов. Под скаляром – отдельный элемент вектора. Формат элемента вектора (также как и скаляра) может быть произвольным: байт, полуслово, слово, двойное слово. В оперативной памяти вектор может располагаться как в последовательных ячейках, так и с некоторым произвольным шагом.
Для задания адреса вектора в оперативной памяти необходимо задать его начальный адрес, шаг (смещение между соседними элементами вектора) и длину (размерность – количество элементов вектора).
Для задания адреса скаляра в оперативной памяти необходимо задать только начальный адрес.
Под векторной вычислительной системой будем понимать вычислительную систему, которая оперирует (выполняет операции) с векторами.
Что же такое векторизация и в чем е превосходство векторной обработки по сравнению с традиционной скалярной обработкой данных?
Что такое векторизация?
В самом широком смысле векторизация – это преобразование операций, выполняемых по ходу процесса решения задачи, из скалярной традиционной формы в векторную.
Один крайний случай заключается в следующем. Допустим, что каким-либо способом (с помощью человека или искусственного интеллекта) можно распознавать ситуации, когда последовательность команд, исполняемых скалярными устройствами, или последовательность операторов языка высокого уровня дает те же результаты, которые могли бы быть получены с помощью одной или нескольких команд, исполняемых векторными обрабатывающими устройствами. Этот вид векторизации называется синтаксической векторизацией, поскольку в данном случае смысловое значение команд и данных не учитывается, а учитывается только их форма. Данный тип векторизации является наиболее общим, и именно его обычно имеют в виду.
Самая сильная сторона этого типа оказывается одновременно и самой слабой. С одной стороны, поскольку учитывается только форма представления программ и данных, имеется теоретическая возможность реализовать процесс векторизации с помощью специальных программных средств – так называемых автоматических векторизаторов. Даже если сделать это автоматически не удается, все равно человеку для осуществления преобразования программ и данных из скалярной формы в векторную форму требуются только формальные сведения.
Однако, что же делать, если человек или соответствующие программные средства не найдут формального преобразования, позволяющего превратить не векторную программно-информационную структуру в векторную. Часть специалистов придерживается мнения, что такого рода препятствия возникают из-за ограниченности параллелизма среднего масштаба, содержащегося в векторной обработке. Если использовать практически неограниченные возможности крупномасштабного параллелизма в вычислительных системах, состоящих из большого числа одновременно работающих независимых процессоров, то упомянутое препятствие исчезнет при условии, что число процессоров будет стремиться к бесконечности быстрее, чем загрузка каждого отдельного процессора к нулю. Тогда в пределе, согласно правилу Лопиталя, производительность вычислительной системы может представлять собой монотонно возрастающую функцию от числа процессоров.
В практическом аспекте проблема векторизации сохраняет свою актуальность. Существуют 2 основные причины, по которым синтаксическая векторизация может потерпеть неудачу. Первая и главная из них – это разнообразие форм представления структур программ и данных, которое может свести любую векторизацию к тем или иным аномальным случаям. Например, когда все скаляры рассматриваются как векторы единичной длины, или когда объем преобразований столь велик, что с учетом затраченного на него времени новая векторная программа окажется хуже, чем старая скалярная. Вторая причина заключается в том, что для получения векторизованной программы могут потребоваться столь сложные глобальные преобразования, которые окажутся не под силу ни автоматическому векторизатору, ни программисту.
Для того чтобы преодолеть названные трудности, необходимо обратиться к другому подходу к векторизации или преобразованию программ – семантическому. Под этим понимается целесообразность интерпретации содержащихся в программах структур данных и подстановку векторных конструкций, выполненных с учетом смыслового содержания задачи, а не ее формы.
В некоторых случаях такого рода действия не выходят за рамки преобразования текста программы строка за строкой. В других случаях требуется полная замена одного алгоритма другим, причем разработка этого другого алгоритма не может быть выполнена без обращения к абстрактным математическим принципам.
Как осуществить векторизацию?
Один из первых принципов семантической векторизации – не размениваться на мелочи. Иногда нужно остановиться на уровне отдельных элементов массивов. Иногда необходимо попытаться охватить более крупную часть задачи и посмотреть, что происходит со структурами данных в целом.
Один из путей достижения этой цели состоит в том, чтобы свести структуры данных к известным семантическим структурам. Если затем удастся доказать теоремы, приводящие к эффективным процедурам обработки этих структур в вычислительной системе векторного или параллельного типа, значит, произведена векторизация!
Область, в которой данный подход большей частью приводит к успеху – это численные методы решения линейных уравнений. В настоящее время хорошо известно, как осуществлять векторизацию некоторых алгебраических матричных операций для отдельных классов разреженных матриц.
Следовательно, если удастся семантически свести свою структуру к какой-либо структуре из области линейной алгебры, то чаще всего векторизация просто означает понимание того, что вы столкнулись с частным случаем общего метода. Например, пусть имеется описание набора сейсмических колебаний во времени и в пространстве. Традиционный способ их обработки, например вычисление быстрого преобразования Фурье (БПФ) – по одному колебанию за один раз. Этот подход отражал не только естественный образ мышления, но и был вынужденным из-за ограничения памяти предыдущих поколений вычислительных систем. Однако, стоит только заметить, что набор колебаний во времени и в пространстве образует заполненную матрицу, как можно применять хорошо известный способ оптимальной векторизации БПФ, при котором колебания рассматриваются как полный набор: вначале в пространстве, затем – во времени, т.е. используется транспонированная матрица.
По приведенному примеру можно сделать несколько замечаний и задать ряд вопросов. Во-первых, он показывает, что необходимо уметь обращаться со структурами данных, не являющиеся векторами, превращая их в такие структуры, которые можно рассматривать как векторные. Во-вторых, правомерно спросить, смог бы программист или автоматический векторизатор осуществить подобную векторизацию, приняв в качестве отправной точки скалярную запись алгоритма, например, на Фортране. На этот вопрос трудно ответить. Однако если следовать духу данного раздела, то такой вопрос задавать вообще неправильно. Нас здесь интересует не такой тип интеллекта, а тот, который позволил бы определить, что представляет собой алгоритм как таковой помимо того, что он является частным случаем общей теоремы. Примером того, как далеко за черту простых манипуляций с текстами программ может распространяться действие общих методов, могут служить так называемые алгоритмы расчета по красным и черным клеткам, применяемые в итеративных методах. В этом случае используются только абстрактные утверждения о том, что при спектральном разложении некоторых типов матриц определенные скалярные и векторные алгоритмы сходятся к одному и тому же результату с одинаковой скоростью. В данном примере мы имеем векторизацию, осуществляемую на качественно ином уровне логических возможностей.
Что обычно препятствует векторизации? В широком смысле таких препятствий 2. Во-первых, структура данных, над которой должна быть произведена та или иная операция, может не быть вектором. Это может происходить по разным причинам, начиная от постоянного присутствия «небольших» дыр до сильно разреженных структур. Первый случай имеет место в алгоритмах решения краевых задач, в которых дырам соответствуют граничные значения. Вторая ситуация характерна, например, для операций со строками матриц, которые хранятся по столбцам. Промежуточный случай возникает, когда из сетки, записанной в лексикографическом порядке, удаляются данные, соответствующие красным и (или) черным клеткам.
Второе препятствие, часто возникающее на пути векторизации – это рекурсивные вычисления. Ключевое условие реализации векторной или параллельной обработки состоит в том, чтобы элементы, участвующие в одних и тех же операциях, не взаимодействовали между собой при исполнении этих операций. Рекурсивные отношения делают это невозможным. Рассмотрим следующий простой пример:
А(I+1) = А(I) + В(I) для I от 1 до N.
Здесь ясно, что ни одно значение А не может быть получено раньше, чем все предыдущие значения. Или все-таки может?
Разумеется, если буквально следовать тому, что написано выше, ответ будет отрицательным. Существует ли, однако, другой алгоритм, с помощью которого можно было бы решить ту же задачу, но без явной рекурсии?
Более общий взгляд на данную вычислительную схему может привести к рассмотрению алгебраической и алгоритмической проблемы обращения некоторых типов бидиагональных матриц. Если это произойдет, то можно считать, что достигнут семантический уровень линейной алгебры.
Приведенный пример иллюстрирует проблему, сформулированную в виде: «Х нельзя векторизовать». Хотя часто действительно оказывается невозможным осуществить векторизацию на синтаксическом уровне из-за тех или иных программных конструкций, переход к альтернативным формам алгоритмов, реализующих те же математические методы, часто делает векторизацию возможной. Следовательно, упомянутая выше фраза имеет смысл только в контексте разрешенных преобразований.
С точки зрения структуры вычислительных систем векторная обработка представляет собой совершенно особый эволюционный этап в развитии параллельных вычислительных систем и параллельных вычислений. Она требует оборудования, обладающего большими логическими возможностями, и использует параллелизм среднего масштаба ценой некоторых ограничений в части структур данных. Наоборот, с точки зрения алгоритмических методов векторная обработка означает революцию, поскольку требует взаимозависимого развития идей и алгоритмов. Она также подняла вопрос о том, где должна проходить граница (если проходит вообще) между человеком и искусственным интеллектом.
Реализация принципов векторной обработки
Рассмотрим механику векторной обработки на примере сложения двух одномерных массивов A(NDIM) и B(NDIM) размерности NDIM и запись результата в C(NDIM):
C=A+B
Данной операции присущ параллелизм - сложение элементов массивов Ai и Bi есть независимые процессы, которые могут исполняться параллельно. В алгоритмических языках высокого уровня (C, Fortran, Pascal и т.п.) существуют специальные операторы цикла, необходимые для исполнения данного суммирования:
do i=1, NDIM
Ci=Ai+Bi
end do
В вычислительной системе с последовательной (скалярной) обработкой данный цикл будет исполняться последовательно: приращение индекса цикла, загрузка операндов Ai и Bi, выполнение сложения, запись результата и т.д.
При выполнении каждой итерации цикла из оперативной памяти считываются последовательно команды, дешифрируются и выполняются. Результаты выполнения команд записываются в заданные места строго в порядке, предусмотренном программой.
Плавному течению конвейера в вычислительной системе мешает много явлений, в частности: зависимости по данным; условные переходы. В рассмотренном простом цикле нельзя выполнять операцию сложения пока не будут получены из оперативной памяти оба операнда; нельзя выполнять запись результата (очередного элемента массива С) до завершения операции сложения.
В итоге, даже при использовании всех современных методов разрешения конфликтных ситуаций (изменения порядка выполнения команд, переименования регистров, предсказания переходов, выполнения ветвей программы по предположению и т.п.) не удается обеспечить необходимую загрузку конвейера, а значит, и добиться максимально возможной производительности.
Итак, реализация операций обработки векторов на скалярных процессорах с помощью обычных циклов ограничивает скорость вычислений по следующим причинам:
перед каждой скалярной операцией необходимо вызывать и декодировать скалярную команду;
для каждой команды необходимо вычислять адреса элементов данных;
данные должны вызываться из оперативной памяти, а результаты запоминаться в оперативной памяти. В больших вычислительных системах оперативная память выполняется, как правило, в виде набора модулей, доступ к которым может осуществляться одновременно. В условиях, когда каждая команда вырабатывает свой собственный запрос к оперативной памяти, такой раздробленный доступ может стать причиной возникновения конфликтов обращения к оперативной памяти, препятствующих эффективному использованию ее потенциальной пропускной способности.
необходимо осуществлять упорядочение выполнения операций в функциональных устройствах. В целях увеличения производительности эти устройства строятся по конвейерному принципу. Эффективному использованию конвейерных устройств препятствует последовательная “природа” оператора цикла.
реализация команд построения циклов (счетчик и переход) сопровождается накладными расходами. Кроме того, наличие в цикле команды перехода препятствует эффективному использованию принципа опережающего просмотра.
В тоже время анализ алгоритма показывает, что имеется возможность выполнять одноименную операцию сложения над всеми элементами исходных массивов без конфликтов. Причем, чем больше размер этих массивов, тем больше простор для параллельной работы.
Эффект параллельности будет достигнут если вычислительная система будет оперировать с векторными командами. В зависимости от типа векторной вычислительной системы возможны различные варианты. Например, в векторной вычислительной системе операции обработки выполняются только при условии, что операнды находятся в векторных регистрах и результат тоже заносится в один из векторных регистров. Тогда в рассмотренном примере, при условии, что размерность векторных регистров равна или больше размерности векторных операндов, нам необходимы всего 4 векторные команды: 2 команды засылки операндов в векторные регистры, одна команда сложения и одна команда записи результата в оперативную память. Конечно, кроме этих четырех векторных команд необходимы и скалярные команды, которые подготовят начальные адреса векторов, шаги – при необходимости. Однако, даже с учетом этих вспомогательных скалярных команд, производительность вычислительной системы с векторными командами будет существенно выше обычной последовательной (скалярной) вычислительной системы, так как после начала выполнения векторной команды нет необходимости считывать из оперативной памяти очередные команды последовательного цикла, дешифрировать их, заниматься преодолением конфликтных ситуаций, препятствующих работе конвейера.
Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера. При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями оперативной памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений в векторной вычислительной системе состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
Теоретически ускорение за счет векторизации по сравнению с последовательным кодом могло бы составить величину, равную длине вектора процессора (при условии, что векторная и скалярная операции выполняются за один и тот же момент времени). Однако, в действительности время исполнения векторной команды больше времени последовательной за счет необходимости времени на загрузку операндов в векторные регистры, дешифровку и запуск команд. Поэтому реальное ускорение всегда меньше теоретического. Пример ускорения при вычислении суммы двух векторов (массивов) за счет использования векторной команды приведен на рис. 1.
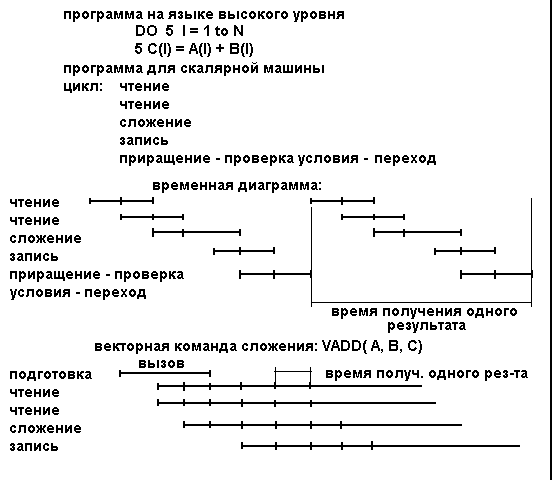
Рис. 1. Вычисление суммы двух векторов на скалярном и векторном процессоре.
Итак, изучение искусства оптимизации скалярных программ показывает, что первым ограничивающим повышение скорости счета фактором является время, необходимое на реализацию отдельной команды. Исполнение даже одной арифметической операции требует исполнения еще нескольких команд. Время, затрачиваемое именно на эти последние команды, становится критическим фактором. Чем больше арифметических операций, тем данная проблема становится острее. Если бы вычислительная система могла «знать», что, например, существует множество арифметических операций, которые нужно выполнять, то появилась бы возможность исполнять отдельные действия параллельно: передавать операнды из оперативной памяти в функциональные устройства, выполнять отдельные этапы арифметических операций, возвращать результаты в оперативную память, вести счетчик требуемого числа повторений операций и др. Этот конвейерный процесс в точности есть именно то, из чего состоит векторная обработка. Руководствуясь одной командой, векторный процессор как бы создает конвейерную линию, исполняющую операцию, заданную в команде без прерываний и без необходимости готовить и исполнять для каждой пары операндов дополнительные команды.
Работа векторного процессора в таком режиме требует координации его различных стадий. Для этого структура вычислительной системы должна иметь более высокий уровень логических возможностей. Необходимо также, чтобы структура данных была достаточно регулярной, чтобы эти логические возможности и оборудование векторного процессора могли быть использованы в полной мере. Назовем эти структурированные данные векторами. К другим характеристикам векторов относятся следующие:
для векторов, длина которых меньше максимальной, установочное (стартовое время) является одинаковым и не зависящим от длины. Следовательно, чем длиннее векторы, тем выше производительность.
поскольку элементы одного вектора обрабатываются параллельно разными устройствами, между ними не может быть взаимодействия на протяжении всего времени выполнения векторной операции. Это означает, что между элементами вектора при выполнении векторной операции не может быть никаких рекурсивных связей.
Векторная обработка реализуется в вычислительных системах двух типов: векторно-матричных и векторно-конвейерных.