

47. Закон Амдала для розподілених систем та його наслідки.
Хай система складається з s простих пристроїв з піковими продуктивностями 1,....,s. Якщо граф системи зв'язний, то максимальна продуктивність rmax системи виражається формулою
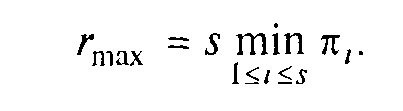
Майже дослівне повторенням твердження 3 носить назву:
НАСЛІДОК (1-ИЙ ЗАКОН АМДАЛА)
Продуктивність обчислювальної системи, що складається із зв'язаних між собою пристроїв, в загальному випадку визначається найнепродуктивнішим її пристроєм.
Припустимо, що всі пристрої, до того ж, прості і універсальні, тобто на них можна виконувати різні операції. Хай на такій системі реалізується деякий алгоритм, а сама реалізація відповідає якійсь його паралельній формі. Допустимо, що висота паралельної форми рівна m, ширина рівна q і всього в алгоритмі виконується N операцій.
Другий та третій закони Амдала
Мінімальне число пристроїв системи, при якому може бути досягнуто максимально можливе прискорення, рівне ширині алгоритму.
Припустимо, що з яких-небудь причин n операцій з N ми вимушені виконувати послідовно. Причини можуть бути різними. Наприклад, операції можуть бути послідовно зв'язані інформаційно. І тоді без зміни алгоритму їх не можна реалізувати інакше. Відношення = n/N назвемо часткою послідовних обчислень.
НАСЛІДОК (2-Й ЗАКОН АМДАЛА)
Хай система складається з s однакових простих універсальних пристроїв. Припустимо, що при виконанні паралельної частини алгоритму всі s пристроїв завантажені повністю. Тоді максимально можливе прискорення рівне
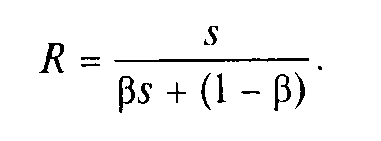
Позначимо через пікову продуктивність окремого ФП. Оскільки якщо система складається з s пристроїв однакової пікової продуктивності, то прискорення системи дорівнює сумі завантаженості всіх пристроїв:
![]()
Якщо всього виконується N операцій, то серед них N операцій виконується послідовно і (1 - )N паралельно на s пристроях по (1 - )N/s операцій на кожному. Можна вважати, що всі послідовні операції виконуються на першому ФП. Всього алгоритм реалізується за час
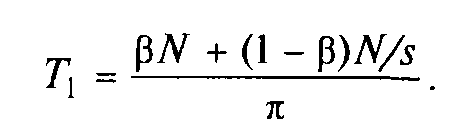
На паралельній частині алгоритму працюють як перший, так і вся решта пристроїв, витрачаючи на це час:
![]()
для 2 ≤ і ≤ n. Тому p1 = 1 і
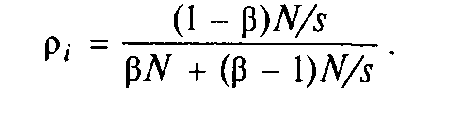
Отже
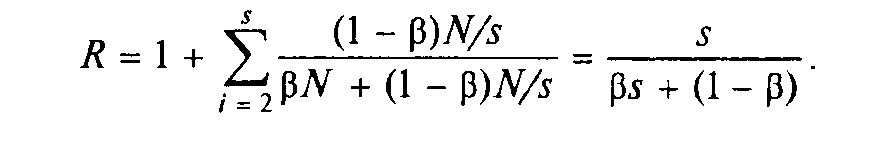
НАСЛІДОК (3-Й ЗАКОН АМДАЛА)
Хай система складається з простих однакових універсальних пристроїв. При будь-якому режимі роботи її прискорення не може перевершити зворотню величину частки послідовних обчислень.
48. Класифікація паралельних комп’ютерів і систем. Класифікація Шора
Одна з перших класифікацій комп'ютерних систем була запропонована Д. Шорам на початку 70-х років. Вона цікава тим, що є спробою виділення типових способів компонування комп'ютерних систем на основі фіксованого числа базових блоків: пристрою керування, арифметико-логічного пристрою, пам'яті команд і пам'яті даних. Додатково передбачається, що вибірка з пам'яті даних може здійснюватися словами, тобто вибираються всі розряди одного слова, і/або бітовим шаром - по одному розряду з однієї і тієї ж позиції кожного слова (іноді ці два способи називають горизонтальною і вертикальною вибірками відповідно). Звичайно ж, при аналізі даної класифікації треба робити знижку на час и появи, оскільки передбачити велику різноманітність паралельних систем теперішнього часу тоді було у принципі неможливо. Отже, згідно з класифікацією Д. Шора, всі комп ютери розбиваються на шість класів, перший з яких дістав назву машини І, другий - машини II, і т. д.
На поданих нижче рисунках позначено: ПІ - пам'ять команд (інструкцій), ПК - пристрій керування, АЛП - арифметико-логічний пристрій, ПД - пам'ять даних. Машина І - це комп'ютерна система, яка містить пристрій керування, арифметико-логічний пристрій, пам'ять команд і пам'ять даних із послівною вибіркою (рис. 1.1).
Зчитування даних здійснюється вибіркою всіх розрядів деякого слова для їх паралельної обробки в арифметико-логічному пристрої. Склад АЛП спеціально не вказується, що допускає наявність декількох функціональних пристроїв, в тому числі конвеєрного типу. За цими міркуваннями до даного класу потрапляють як класичні послідовні машини (ІВМ 701, РDР-11, VАХ 11/780), так і конвеєрні скалярні (СDС 7600) і векторно-конвеєрні (СRАУ-1).
Якщо в машині І здійснювати вибірку не по словах, а по одному розряду з усіх слів, то одержимо машину II (рис. 1.2). Слова в пам'яті даних, як і раніше, розташовуються горизонтально, але доступ до них здійснюється iнакше. Якщо в машині І відбувається послідовна обробка слів при паралельній обробці розрядів, то в машині II - послідовна обробка бітових шарів при паралельній обробці множини слів.
Структура машини II лежить в основі асоціативних комп'ютерів (наприклад, так побудовано центральний процесор машини STARAN), причому фактично такі комп'ютери мають в складі арифметико-логічного пристрою множину порівняно простих операційних пристроїв порозрядної обробки даних. Іншим прикладом служить матрична система ІСL DАР, яка може одночасно обробляти по одному розряду з 4096 слів.
Якщо об'єднати принципи побудови машин І і II, то одержимо машину III (рис. 1.3). Ця машина має два арифметико-логічні пристрої - горизонтальний і вертикальний, а також модифіковану пам'ять даних, яка забезпечує доступ як до слів, так і до бітових шарів. Вперше ідею побудови таких систем у 1960 році висунув У Шуман, що називав їх ортогональними (якщо пам'ять представляти як матрицю слів, то доступ до даних здійснюється в напрямі, "ортогональному" традиційному - не по словах (рядках), а по бітових шарах (стовпцях)). У принципі, як машину STARAN так і IСL DАР можна запрограмувати на виконання функцій машини IIІ, але оскільки вони не мають окремих АЛП для обробки слів і бітових шарів, віднести їх до даного класу не можна. Повноправними представниками машин класу III є обчислювальні системи сімейства ОМЕN-60 фірми Sanders Associates, побудовані в прямій відповідності до концепції ортогональної машини.
Якщо в машині І збільшити кількість пар арифметико-логічний пристрій <==> пам'ять даних (іноді цю пару називають процесорним елементом), то одержимо машину IV (рис. 1.4). Єдиний пристрій керування видає команду за командою відразу всім процесорним елементам. З одного боку, відсутність з'єднань між процесорними елементами робить подальше нарощування 'їх числа відносно простим, але з іншого боку, сильно обмежує застосовність машин цього класу. Таку структуру має обчислювальна система РЕРЕ, яка об'єднує 288 процесорних елементів.
Якщо ввести безпосередні лінійні зв'язки між сусідніми процесорними елементами машини IV, то одержимо структуру машини V (рис. 1.5). Будь-який процесорний елемент тепер може звертатися до даних як у своїй пам'яті, так і в пам'яті безпосередніх сусідів. Подібна структура характерна, наприклад, для класичної матричної багатопроцесорної системи ІLLIAС IV.
Відмітимо, що у всіх машинах з 1-ї по V-у дотримана концепція розділення пам'яті даних і арифметико-логічних пристроїв, припускаючи наявність шини даних або якого-небудь комутуючого елемента між ними. Машина VI, названа матрицею з функціональною пам'яттю (або пам'яттю з вбудованого логікою), є іншим підходом, що передбачає розподіл логіки процесора по всьому запам'ятовуючому пристрою (рис.1.6). Прикладом можуть служити як прості асоціативні запам'ятовуючі пристрої, так і складні асоціативні процесори.
Одну з перших практично значимих класифікацій паралельних комп'ютерних систем подав у 1966 році співробітник фірми ІВМ Майкл Флін, який зараз є професором Стенфордського університету (США). Його класифікація базується на оцінці потоку інформації, яка поділена иа потік даних між основною пам'яттю та процесором, та потік команд, які виконує процесор. При цьому потік даних та команд може бути як одиничним, так і множинним. Згідно з М. Фліном, усі комп'ютерні системи поділяють так:
ОКОД - комп'ютерні системи з одиничним потоком команд та одиничним потоком даних (SISD - Single Instruction Single Data stream).
МКОД - комп'ютерні системи з множинним потоком команд та одиничним потоком даних (MISD - Multiply Instruction Single Data stream).
ОКМД - комп'ютерні системи з одиничним потоком команд та множинним потоком даних (SIMD - Single Instruction Multiply Data stream).
МКМД - комп'ютерні системи з множинним потоком команд та множинним потоком даних (МIMD - Multiply Instruction Multiply Data stream).
Розглянемо запропоновану М. Фліном класифікацію детальніше. На поданих нижче рисунках позначено: ПК - пристрій керування, ПР - процесор, ПД - пам'ять даних.
До класу комп'ютерних систем з одиничним потокохм команд та одиничним потоком даних належить, зокрема, комп'ютер з архітектурою Джона фон Неймана, яким, наприклад, є розповсюджений персональний комп'ютер. Організація роботи комп'ютерних систем цього класу була розглянута в попередніх розділах книги.
Структура комп'ютерної системи з множинним потоком команд та одиничним потоком даних показана на рис. 1.7Ь. Комерційні універсальні комп'ютерні системи цього типу на даний час невідомі, проте вони можуть з'явитися у майбутньому. До цього типу систем з деякими умовностями можна віднести спеціалізовані потокові процесори, зoкрема систолічні, які використовують, наприклад, при обробці зображень.
В комп'ютерній системі з одиничним потоком команд та множинним потоком даних (рис. 1.7 с) одночасно обробляється велика кількість даних. До цього класу, зокрема, належать раніше розглянуті векторні процесори. До комп'ютерних систем з одиничним потоком команд та множинним потоком даних можна віднести також апаратну підсистему процесорів Реntіum, яка реалізовує технологію ММХ опрацювання даних для графічної операційної системи Windows.
Характерним прикладом комп'ютерної системи з одиничним потоком команд та множинним потоком даних може служити система, яка складається з двох частин: зовнішнього комп'ютера з архітектурою Джона фон Неймана, який виконує роль пристрою керування, і масиву ідентичних синхронізованих елементарних процесорів, здатних одночасно виконувати ту ж саму дію над різними даними. Кожен процесор у масиві Має місцеву пам'ять невеликої ємності, де зберігаються дані, які обробляються паралельно.
З масивом процесорів з'єднано шину пам'яті зовнішнього комп'ютера таким чином, що він може довільно звернутися до кожного процесора масиву. Програма може виконуватися традиційно послідовно на зовнішньому кохмп'ютері, а її частина може паралельно виконуватися на масиві процесорів. У комп'ютерній системі з множинним потоком команд та множинним потоком даних кожен процесор оперує із своїм потоком команд та своїм потоком даних (рис.1.7d).
Як правило, окремі процесори багатопроцесорної системи є серійними пристроями, що дозволяє значно зменшити вартість проекту. У класі МКМД треба відрізняти сильно зв'язані системи, власне багатопроцесорні системи, від мереж комп'ютерів, тобто слабо зв'язаних систем; тобто багатопроцесорні системи та комп'ютерні мережі потрапляють до різних підкласів класу МІМD.
В 1978 році Д. Куком було запропоновано розширення класифікації Фліна. У своїй класифікації Д. Кук розділив потоки команд та даних на скалярні та векторні потоки. Комбінація цих потоків приводить в підсумку до 16 типів архітектури паралельних комп'ютерних систем.