
Циклическое кодирование и переупорядочение
Н а
выходе схемы речевого кодирования имеем
последовательность кадров размером
260 бит и длительностью 20 мкс. В схеме
циклического кодирования кадр разбивается
следующим образом:
а
выходе схемы речевого кодирования имеем
последовательность кадров размером
260 бит и длительностью 20 мкс. В схеме
циклического кодирования кадр разбивается
следующим образом:
Далее биты класса 1а дополняются тремя битами проверки на четность P0, P1 и P2, которые формируются по следующей схеме:
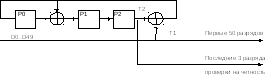
На вход схемы поступают биты класса 1а (D0..D49). С выхода снимаются значения ячеек памяти P0..P2, которые сформируются после прохождения всех 50 битов класса 1а.
Обозначим:
Т1 – очередной бит класса 1а, поступающий на вход схемы,
Т2 – содержимое ячейки P2 до прихода этого бита.
Тогда процессы, происходящие в схеме, можно описать уравнениями:
T1 = Di
T2 = P2
P2 = P1
P1 = P0 T1 T2
P0 = T1 T2
Здесь - исключающее ИЛИ (сложение по модулю 2; xor).
В начальный момент времени P0 = P1 = P2 = 0.

Одна из теорем теории кодирования утверждает, что любой циклический (n,k)-код может обнаруживать любой пакет ошибок длины n-k или меньше. Доля пакетов ошибок длины b > n-k, которые не могут быть обнаружены циклическим (n,k)-кодом, равна q-(n-k-1)/(q-1), если b = n-k+1, и равна q-(n-k), если b>n-k+1.
Таким образом, используемый (53,50) циклический код может обнаруживать любой пакет ошибок длины 3 или меньше, доля пакетов ошибок длины b=4, которые не могут быть обнаружены, равна 2-(53-50-1)/(2-1) = 0,25, доля пакетов ошибок длины b>4, которые не могут быть обнаружены, равна 2-(53-50) = 0,125. То есть вероятность обнаружения пакетов ошибок длиной b=4 составляет 75%, а вероятность обнаружения пакетов ошибок длиной b>4 составляет 87,5%.
На следующем этапе биты класса 1 с четными индексами собираются в порядке возрастания индекса в первой части кадра. За ними следуют три бита проверки на четность. Затем биты класса 1 с нечетными индексами запоминаются в буферной памяти и переставляются в порядке убывания индекса. Далее следует четыре нулевых бита, которые необходимы для работы кодера, формирующего код, исправляющий случайные ошибки в канале. Кадр завершает концевая комбинация битов класса 2, не претерпевшая изменений.
В приемнике осуществляется обратная последовательность действий:
удаляются четыре нулевых бита,
восстанавливается последовательность битов класса 1,
на основании первых 50 битов класса 1 формируются три бита проверки на четность и сравниваются с принятыми.
Сверточное кодирование
После выполнения операций циклического кодирования и переупорядочения , 189 бит класса 1 кодируются сверточным кодом (2,1,5) со скоростью r=1/2, в результате чего генерируются 378 закодированных бит, которые дополняются концевой комбинацией до кадра размером 456 бит.
Сверточное кодирование производится с целью повышения помехоустойчивости и происходит по следующей схеме:

Таким образом, при поступлении на вход одного бита на выходе формируются два.
Процесс можно описать следующими уравнениями:
D4 = D3
D3 = D2
D2 = D1
D1 = D
D = xi
Gi*2 = D D2 D3 D4
Gi*2+1 = D D1 D4
для i = 0 .. 188.
В начальный момент времени D = D1 = D2 = D3 = D4 = 0.
![]()
Работу кодирующего устройства сверточного кода удобно пояснить с помощью кодового дерева (рис.1).
Рис.1.
К
0
1
 одовое
дерево, соответствующее сверточному
кодирующему устройству.
одовое
дерево, соответствующее сверточному
кодирующему устройству.
Кодовое дерево строится следующим образом: если входной информационный символ, поступающий в сдвиговый регистр, равен 1, то ему приписывается линия (ветвь дерева), идущая вниз, а, если информационный символ равен 0 – то вверх. Символы сверточного кода, получаемые на выходе сумматоров по модулю 2, записывается над соответствующей ветвью дерева. Точки, из которых исходят ветви дерева, называются узлами. Определенная последовательность информационных символов на выходе кодирующего устройства порождает один из путей по кодовому дереву. Например, входная последовательность информационных символов 11111…, поступающая на кодирующее устройство (рис.1), порождает выходную последовательность 111000101001…
Таким образом, процесс кодирования для сверточного кода можно представить как последовательный выбор одного из путей по кодовому дереву. Выбор этого пути задается входной последовательностью информационных символов. В данном кодирующем устройстве сверточного кода выходные символы вычисляются посредством линейных операций (суммирование по модулю 2) над входными .Поэтому полученные сверточные коды являются линейными.
Для декодирования сверточных кодов разработан ряд эффективных методов декодирования, в частности, последовательное декодирование. Принцип последовательного декодирования в двоичном дискретном канале состоит в следующем: n регенерированных символов сверточного кода, соответствующих одной из ветвей кодового дерева, на приемной стороне записывается в регистр сдвига.
Декодирующее устройство, аналогичное кодирующему устройству данного сверточного кода, генерирует n символов сверточного кода, соответствующих каждой из ветвей кодового дерева, исходящей из данного узла. Каждая из двух последовательностей n символов, генерируемых в декодирующем устройстве, поразрядно суммируется по модулю 2 с принятой последовательностью, записанной в регистре. В результате этих операций вычисляется расстояние Хэмминга dx между этими последовательностями и принятой последовательностью. Затем выбирается путь с наименьшим dx между этими последовательностями и принятой последовательностью. Затем выбирается пути с наименьшим dx и выносится предварительное решение, что путь по данной ветви кодового дерева и является истинным. Расстояние dx для этого пути запоминается, и декодирующее устройство переходит к следующему узлу кодового дерева, к которому приводит выбранный путь. Из этого нового узла вновь исследуются два возможных пути и т.д.
Если вероятность искажения одного символа шумами при передаче равна р, то математическое ожидание числа ошибок, а, следовательно, и расстояние Хэмминга dx между принятыми символами сверточного кода и n символами, соответствующими правильному пути по данной ветви кодового дерева, будет равно np.
Если же по данной ветви выбран неправильный путь, то математическое ожидание расстояния dx для него будет приблизительно равно n/2. Следовательно, через l последовательных шагов декодирования математическое ожидание dx(l) для правильного пути будет равно lnp, а для неправильного пути- ln/2. Действительные значения dx(l) для правильного и неправильного пути будут случайными величинами с указанными математическими ожиданиями. Это показано на рис.2.
Рис.2.
З ависимость
кодового расстояния для правильного и
неправильного путей.
ависимость
кодового расстояния для правильного и
неправильного путей.
В последовательном декодирующем устройстве сравнивается текущее значение dx(l) с некоторым порогом z(l). Если на текущем шаге декодирования порог не превышен, то декодирующее устройство переходит к анализу путей, ведущих из следующего узла. Если порог превышен, то декодирующее устройство возвращается в прошлый узел, для которого не было превышения порога, и исследует другие возможные пути по кодовому дереву. Таким образом, декодирующее устройство обследует все доступные узлы до тех пор, пока не найдется пути, при котором текущий порог z(l) не превышается. Если же такого пути не находится, то порог повышается и указанная операция повторяется.
Поскольку связи между символами на выходе сверточного кодирующего устройства, имеющего к-разрядный регистр сдвига, распространяются на к ветвей кодового дерева, то, найдя один из путей по к ветвям дерева, удовлетворяющий установленному порогу, декодирующее устройство выносит окончательное решение о декодировании первой ветви, соответствующей этому пути. Далее так же декодируется вторая ветвь дерева, и т.д.
В таком процессе ошибка при декодировании произойдет, если неправильный путь по кодовому дереву не будет обнаружен на протяжении к последовательных ветвей.
Достоинством последовательного декодирования является то, что при исключении какого-либо пути по кодовому дереву отбрасываются все другие пути, исходящие из узлов исключенного. За счет этого экономится число операций, производимых при декодировании. Чем выше порог z(l), тем большее количество операций требуется, так как неправильный путь, начавшийся из некоторого узла, обнаруживается позднее. Поэтому сначала декодирование ведут при низком (жестком) пороге. Если же путей, удовлетворяющих этому порогу не находится, порог повышают.