

Стратегии распределенных вычислений
Объекты окружают нас уже долгое время. Многие, создавая объекты, сразу же задумываются о необходимости их «распределения». Впрочем, распределение объектов (как и любых других инструментов вычислений) сопряжено с гораздо большими сложностями, чем можно было бы предвидеть. Многие поставщики инструментальных средств программирования не устают твердить: основное достоинство технологий распределения объектов заключается именно в том, что вы можете взять «пригоршню» объектов и разбросать их по узлам сети как вашей душе угодно, а фирменное промежуточное программное обеспечение сделает прозрачными все взаимосвязи. Свойство прозрачности позволяет объектам вызывать друг друга внутри одного процесса, между процессами на одной машине или на разных машинах, не заботясь о местонахождении «собеседников». Хотя многие стороны жизни распределенных объектов действительно приобретают искомую прозрачность, это явно не относится к аспектам производительности.
Интерфейсы локального и удаленного вызова
Главная причина неудовлетворительной работоспособности модели распределения кода по «классовой» принадлежности связана с основополагающими аспектами функционирования компьютерных систем. Вызов процедуры в пределах одного процесса протекает чрезвычайно быстро. Вызов между двумя отдельными процессами, работающими на одном компьютере, обслуживается на несколько порядков медленнее. Активизируйте один из процессов на другой машине, и вы увеличите время обработки еще на пару порядков, в зависимости от сложности топологии конкретной сети.
Отсюда следует, что интерфейсы одного и того же объекта, предназначенные для локального и удаленного доступа, должны различаться.
На роль локального интерфейса более всего подходит интерфейс с высокой степенью детализации. Хороший интерфейс класса, представляющего почтовый адрес, например, должен включать отдельные методы для задания/считывания почтового кода, наименования города, названия улицы и т.п. Достоинство интерфейса с высокой степенью детализации состоит в том, что он следует общему принципу объектной ориентации, состоящему в применении множества небольших простых фрагментов кода, которые могут сочетаться и переопределяться разными способами для пополнения и изменения множества функций класса в будущем.
Детальный интерфейс, однако, утрачивает свои преимущества при использовании в режиме удаленного доступа. Когда вызов метода обрабатывается медленно, несомненно, целесообразнее получать значения почтового кода, наименования города и названия улицы сразу, а не по одному. Такой интерфейс, спроектированный не с учетом гибкости и возможности расширения, а в целях уменьшения количества вызовов, должен отличаться низкой степенью детализации. Он, очевидно, гораздо менее удобен в использовании, но зато более эффективен в смысле быстродействия.
Любой объект, допускающий удаленные вызовы, должен быть снабжен интерфейсом с низкой степенью детализации, а объект, адресуемый в локальном режиме, — интерфейсом с высокой степенью детализации. Для поддержки взаимодействия двух объектов следует выбрать подходящий тип интерфейса. Если объект допускает возможность вызова из контекста стороннего процесса, вам придется использовать менее детальный интерфейс и расплачиваться усложнением модели программирования и потерей гибкости. Все это имеет смысл, разумеется, только тогда, когда приобретения того стоят; в общем же случае взаимодействия между процессами, безусловно, следует избегать.
По этим причинам нельзя просто взять группу классов, спроектированных в расчете на использование в едином процессе, применить технологию CORBA или что-то подобное и заявить, что распределенное приложение готово к работе. Распределенная модель вычислений — это нечто большее. Основывая свою стратегию распределения на классах, вы неизбежно придете к системе, изобилующей удаленными вызовами и потому нуждающейся в реализации неповоротливых интерфейсов с низкой степенью детализации.
В завершение отметим, что любая незначительная модификация кода дается с большим трудом.
Поэтому можно озвучить следующее правило:
«Не распределяйте объекты!»
Но как тогда эффективно использовать несколько процессоров? В большинстве случаев этого можно добиться с помощью механизма кластеризации (рис. 7.1). Разместите все классы в контексте одного процесса и активизируйте несколько копий процесса на разных узлах. Тогда каждый процесс будет пользоваться только локальными вызовами и достигнет цели значительно быстрее. Вы сможете применить во всех классах интерфейсы с высокой степенью детализации, упростить модель программирования и облегчить задачу сопровождения системы.
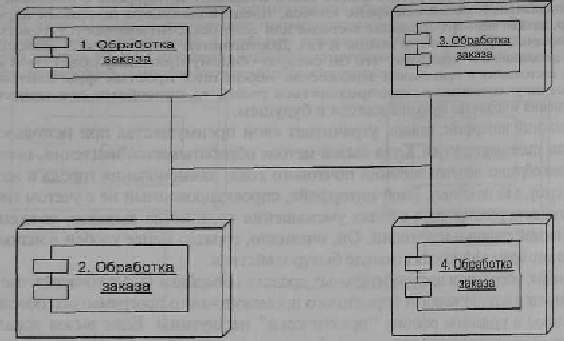
Рис. 7.1. Кластеризация предполагает размещение нескольких копий одного приложения
на различных узлах