

Варианты заданий.
Задание №1 (варианты)
-
В качестве исходного массива рассматривается массив элементов типа:
TElement = record
Value: Real;
Info: String;
end;
-
Предметный класс должен предусматривать возможность задания массива с произвольного типом элементов, т.е. использовать функцию сравнения, задаваемую и перекрываемую пользователем для конкретного используемого массива.
-
Для защиты работы студент должен представить исходный и отсортированный массив, а также статистику расчета для неупорядоченного, упорядоченного по возрастанию и упорядоченного по убыванию исходных массивов.
Варианты заданий сведены в таблицу 1.1.
Таблица 1.1.
|
№ варианта |
Метод решения |
|
1.1 |
Сортировка выбором |
|
1.2 |
Сортировка пузырьком |
|
1.3 |
«Шейкерная» сортировка |
|
1.4 |
Сортировка простыми вставками |
|
1.5 |
Cортировка Шелла |
|
1.6 |
Быстрая сортировка |
-
Разработка динамических структур данных
Постановка задачи: Требуется разработать программно-математическое обеспечение, реализующее работу с динамической структурой данных (в соответствии с вариантом задания).
Требования к ПМО: Структурно ПМО должно быть реализовано в виде интерфейсной части, обеспечивающей:
-
задание массива из формы приложения (посредством компонента TStringGrid);
-
выбор файла для заполнения структуры из файла (для пакетного режима работы);
-
выбор элемента структуры по порядковому номеру;
-
выбор элемента структуры по информационному полю;
-
выбор файла для выгрузки содержимого,
а также предметной части, реализованной в виде класса, обеспечивающего:
-
хранение данных в динамической структуре;
-
заполнение структуры из файла (для пакетного режима работы);
-
добавление нового элемента структуры;
-
вставка элемента в заданную позицию (для списков и деревьев)
-
выгрузку элемента из структуры (для стека и очереди);
-
выбор элемента по порядковому номеру (для списков и деревьев);
-
выбор элемента по информационному полю (для списков и деревьев);
-
выгрузки содержимого в файл.
Методические указания к выполнению
Динамические структуры по определению характеризуются отсутствием физической смежности элементов структуры в памяти непостоянством и непредсказуемостью размера (числа элементов) структуры в процессе ее обработки.
Поскольку элементы динамической структуры располагаются по непредсказуемым адресам памяти, адрес элемента такой структуры не может быть вычислен из адреса начального или предыдущего элемента. Для установления связи между элементами динамической структуры используются указатели, через которые устанавливаются явные связи между элементами. Такое представление данных в памяти называется связным. Элемент динамической структуры состоит из двух полей:
-
информационного поля или поля данных, в котором содержатся те данные, ради которых и создается структура; в общем случае информационное поле само является интегрированной структурой - вектором, массивом, записью и т.п.;
-
поле связок, в котором содержатся один или несколько указателей, связывающий данный элемент с другими элементами структуры;
Когда связное представление данных используется для решения прикладной задачи, для конечного пользователя "видимым" делается только содержимое информационного поля, а поле связок используется только программистом-разработчиком.
Достоинства связного представления данных - в возможности обеспечения значительной изменчивости структур:
-
размер структуры ограничивается только доступным объемом машинной памяти;
-
при изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей.
К динамическим структурам относятся списки (однаправленные, двунаправленные, кольцевые однаправленные и кольцевые двунаправленные), стеки, деки, очереди, деревья.
Под списком мы будем понимать конечный упорядоченный набор объектов произвольных размера и природы.
Связанные списки используются в двух основных случаях. Во-первых, при создании в оперативной памяти набора данных, размер которого заранее неизвестен. Если заранее известно, какого размера память потребуется для решения задачи, то можно использовать массив. Однако, если действительный размер списка неизвестен, то применяют связанный список. Во-вторых, связанные списки используются в базах данных. Связанный список позволяет быстро выполнять вставку и удаление элемента данных без реорганизации всего дискового файла. По этим причинам связанные списки широко используются в программах по управлению базами данных.
Связанные списки могут иметь одиночные или двойные связи.
Список с одной связью (однонаправленный список) содержит элементы, каждый из которых имеет связь со следующим элементом данных. В списке с двойной связью (двунаправленный список) каждый элемент имеет связь, как со следующим элементом, так и с предыдущим элементом.
Линейный (однонаправленный) список является динамической структурой данных, данные в которую могут включаться и изыматься в произвольно выбранное место.
Каждая компонента списка определяется ключом. Обычно ключ - это либо число, либо строка символов. Ключ располагается в поле данных компоненты, он может занимать как отдельное поле записи, так и быть частью информационного поля записи.
Рассмотрим схематичное изображение однонаправленного списка:

Над списками выполняются следующие операции:
-
начальное формирование списка (запись первой компоненты);
-
добавление компоненты в конец списка;
-
определение первого элемента в линейном списке;
-
чтение компоненты с заданным ключом; с заданным свойством;
-
вставка компоненты в заданное место списка (обычно до компоненты с заданным ключом или после неё);
-
исключение компоненты с заданным ключом из списка.
-
упорядочивание узлов линейного списка в определенном порядке.
Стеком называется динамическая структура данных, добавление компоненты в которую и исключение компоненты из которой производится из одного конца, называемого вершиной стека.

В организации стека используется доступ по принципу "последней пошел, первый вышел". Такой метод доступа называют методом LIFO (Last-In, First-Out).
Обычно над стеками выполняются три операции:
-
начальное формирование стека (запись первой компоненты);
-
добавление компоненты в стек;
-
выборка компоненты (удаление).
Очередью называется динамическая структура данных, добавление компоненты в которую производится в один конец, а выборка осуществляется с другого конца.

Очередь представляет собой линейный список данных, доступ к которому осуществляется по принципу "первый вошел, первый вышел", иногда сокращенно его называют методом доступа FIFO (First-In, First-Out). Элемент, который был первым поставлен в очередь, будет первым получен при поиске или обработке. Элемент, поставленный в очередь вторым, при поиске будет получен также вторым и т.д. Этот способ является единственным при постановке элементов в очередь и при поиске элементов в очереди.
Применение очереди не позволяет делать прямой доступ к любому конкретному элементу.
Над динамической структурой - очередью - выполняются следующие операции:
-
начальное формирование очереди (запись первой компоненты);
-
добавление компоненты в конец очереди;
-
определение первого элемента в очереди с последующим извлечением его из очереди.
Одним
из недостатков однонаправленных списков
является отсутствие доступа к
предшествующим элементам указанного
компонента списка. Если производится
просмотр списка, то для повторного
обращения к нему исходный указатель на
начало списка должен быть сохранен.
Предположим, что в структуре
однонаправленного списка было сделано
изменение: поле-ссылка последнего
элемента теперь содержит указатель или
на заглавное звено, или на элемент,
следующий за заглавным звеном. Такой
список называется кольцевым или
циклическим. Из любого элемента кольцевого
списка можно получить доступ к любому
другому элементу. Кольцевой список не
имеет первого и последнего элемента
![]()
Однонаправленный кольцевой список с включенным заглавным звеном схематически можно изобразить следующим образом:
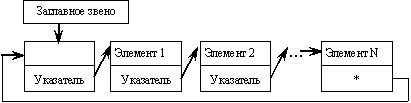
Пустой кольцевой список с включенным заглавным звеном схематически можно изобразить следующим образом:

В зависимости от количества связей между соседними элементами различают односвязные и двусвязные списки.
Каждый элемент в списке с двойной связью имеет указатель на следующий элемент списка и указатель на предыдущий элемент списка.
Двунаправленный список отличается двумя основными преимуществами. Во-первых, список может просматриваться в обоих направлениях. Это не только упрощает сортировку списка, но также позволяет пользователям базы данных просматривать данные в обоих направлениях. Во-вторых, список при нарушении одной из связей может быть восстановлен по другой связи. Это свойство имеет смысл использовать при отказах оборудования, приводящих к нарушению списка.
Двунаправленный список строится подобно однонаправленному списку, причем в записи должно быть предусмотрено место для двух указателей. Итак, каждый элемент двунаправленного списка представим записью, которая состоит из трех полей:
1) информационного поля или поля данных;
2) ссылки на следующий элемент списка;
3) ссылки на предыдущий элемент списка.
Двунаправленный список, так же как и однонаправленный, может иметь заглавные звенья и не иметь их.
Cлучай, когда заглавное звено одно:

Пустой двунаправленный список с одним заглавным звеном:

Приведем вариант структуры двунаправленного списка с двумя заглавными звеньями:

В данном случае двунаправленный список стал симметричным.
Соответствующий пустой двунаправленный список с двумя заглавными звеньями выглядит так:

Рассмотрим три свойства двунаправленных списков:
-
по списку можно двигаться в любом направлении;
-
если List есть указатель на любой элемент двунаправленного списка, то выполняются следующие свойства
List = List^.pNext^.pPrev
и
List = List^.pPrev ^.pNext
Данные свойства легко можно проиллюстрировать с помощью схемы:

-
возможность легкого исключения узла из списка, в котором он находится, по известному указателю на этот узел. Алгоритмы, в которых требуется исключать узлы из середины списка, встречаются достаточно часто, и как раз этим обстоятельством и объясняется распространенное использование списков с двумя связями.
Над двунаправленными списками выполняются следующие операции:
-
начальное формирование списка (запись первой компоненты);
-
добавление компоненты в конец списка;
-
вставка компоненты в заданное место списка (обычно до компоненты с заданным ключом или после неё);
-
определение первого или последнего элементов в двунаправленном списке;
-
чтение компоненты с заданным ключом; с заданным свойством;
-
исключение компоненты с заданным ключом из списка;
-
упорядочивание узлов линейного списка в определенном порядке.
Дерево — это совокупность элементов, называемых узлами (при этом один из них определен как корень), и отношений (родительский–дочерний), образующих иерархическую структуру узлов. Узлы могут являться величинами любого простого или структурированного типа, за исключением файлового. Узлы, которые не имеют ни одного последующего узла, называются листьями.
В двоичном (бинарном) дереве каждый узел может быть связан не более чем двумя другими узлами. Рекурсивно двоичное дерево определяется так: двоичное дерево бывает либо пустым (не содержит ни одного узла), либо содержит узел, называемый корнем, а также два независимых поддерева — левое поддерево и правое поддерево.
Двоичное дерево поиска может быть либо пустым, либо оно обладает таким свойством, что корневой элемент имеет большее значение узла, чем любой элемент в левом поддереве, и меньшее или равное, чем элементы в правом поддереве. Указанное свойство называется характеристическим свойством двоичного дерева поиска и выполняется для любого узла такого дерева, включая корень.
Согласно определению двоичного дерева поиска число 9 помещаем в корень, все значения, меньшие его — на левое поддерево, большие или равные — на правое. В каждом поддереве очередной элемент можно рассматривать как корень и действовать по тому же алгоритму. В итоге получаем

Выделим типовые операции над двоичными деревьями поиска:
-
добавление элемента в дерево;
-
удаление элемента из дерева;
-
обход дерева (для печати элементов и т.д.);
-
поиск в дереве.
Поскольку определение двоичного дерева рекурсивно, то все указанные типовые операции могут быть реализованы в виде рекурсивных подпрограмм (на практике именно такой вариант чаще всего и применяется). Отметим лишь, что использование рекурсии замедляет работу программы и расходует лишнюю память при её выполнении.
Подробно описание структур и способов их реализации можно найти:
-
Д. Кнут. «Искусство программирования на ЭВМ», М., Мир, 1978
-
Ахо Альфред В., Хопкрофт Джон Ульман, Джеффри, Д. Структуры данных и алгоритмы : Пер. с англ. : Уч. пос. - М. : Издательский дом "Вильяме", 2000.