

Математическая статистика.
План:
-
Описательная статистика;
-
Методы индуктивной статистики;
-
Корреляционный анализ.
1. Статистика – это совокупность статистических данных, характеризующих какое – нибудь явление или процесс (например, статистика рождаемости, статистика смертности, статистика успеваемости учащихся и т.д..)
Описательная статистика – занимается вопросами сбора и представления, первичной статистической информации в табличной и графической формах.
Основной задачей статистики является выявление и исследование общих закономерностей, присущих совокупностям, состоящим из очень большого числа элементов. Выбранные элементы составляют выборку; количество элементов в выборке называют объемом выборки. Совокупность из которой сделана выборка, называют генеральной совокупностью.
Запись х1, х2, …хi, …xn-1, xn – простой статистический ряд (выборка).
Отдельные значения xi – варианты (данные).
Варианты в ряду могут иметь как различные, так и одинаковые, повторяющиеся значения.
Например, игральный кубик бросили 12 раз и записали выпавшие числа в порядке их появления: 3, 4, 5, 6, 6, 5, 4, 4, 4, 3, 2, 1. n=12
Варианты: x1=3, x2=4, x3=5, …
|
Xj |
1 |
2 |
3 |
4 |
5 |
6 |
|
kj |
1 |
1 |
2 |
4 |
2 |
2 |
- статистическое распределение ряда, kj - частоты значений.
Последовательность обработки данных
В качестве примера исследуем рост девушек. Это исследование может иметь практическую ценность для швейной промышленности: модные платья выпускаются различных размеров и в количествах, пропорциональных вероятностям спроса на каждый размер. Нами опрошены 30 студенток 1-го курса и получено 30 чисел (объем выборки n=30).
X={161, 169, 170, 167, 168, 173, 162, 165, 166, 168, 175, 161, 165, 165, 181, 170, 163, 164, 165, 155, 158, 171, 162, 162, 158, 159, 160, 165, 167, 167}.
1. Сортировка данных по возрастанию значений. Числа, записанные в порядке возрастания, образуют вариационный ряд.
Эксперимент дает в руки исследователя 30 чисел. После сортировки получаем вариационный ряд:
|
x= |
155 |
158 |
158 |
159 |
160 |
161 |
161 |
162 |
162 |
162 |
|
|
163 |
164 |
165 |
165 |
165 |
165 |
165 |
166 |
167 |
167 |
|
|
167 |
168 |
168 |
169 |
170 |
170 |
171 |
173 |
175 |
181. |
2. В вариационном ряду уже можно проследить повторяемость вариант — некоторые значения повторяются чаще других (имеют большую вероятность).
Более отчетливо можно проследить распределение вероятностей, сгруппировав данные по классам. Для этого диапазон значений (от наименьшего до наибольшего) разбивают на равные интервалы (классы) и подсчитывают количество вариант в каждом интервале (частоту). Составляют таблицу (табл. 1). В третьей строке таблицы записывают вероятности появления значений в соответствующем интервале. Интервалы в таблице помечены сокращенно одним числом, соответствующим правой границе интервала. Числу 157 отвечает интервал (154; 157]. Обычно по краям таблицы располагают заведомо пустые интервалы, показывая ее завершенность.
Таблица 1.
|
Интервал |
154 |
157 |
160 |
163 |
166 |
169 |
172 |
175 |
178 |
181 |
184 |
|
Частота,k |
0 |
1 |
4 |
6 |
7 |
6 |
3 |
2 |
0 |
1 |
0 |
|
Вероятность, p=k/n |
0 |
0,03 |
0,13 |
0,20 |
0,24 |
0,20 |
0,10 |
0,07 |
0 |
0,03 |
0 |
В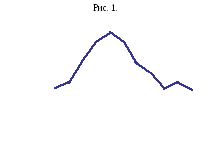 ероятности
находятся как относительные частоты:
p=k/n
(отношение частоты к общему количеству
вариант).
Данная таблица описывает закон
распределения вероятностей. Заметим,
что здесь мы получаем не вероятность
отдельного значения, а вероятность
появления произвольного значения на
заданном интервале числовой оси —
плотность
вероятности.
ероятности
находятся как относительные частоты:
p=k/n
(отношение частоты к общему количеству
вариант).
Данная таблица описывает закон
распределения вероятностей. Заметим,
что здесь мы получаем не вероятность
отдельного значения, а вероятность
появления произвольного значения на
заданном интервале числовой оси —
плотность
вероятности.
Очевидно, что вероятность в каждом пропорциональна частоте, поэтому в практике исследований часто ограничиваются нахождением частот, не заполняя третью строку в таблице. Замена вероятности на частоту равносильна переходу к новой единице ее измерения.
3
Рис. 2.
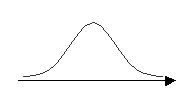
Весьма распространено так называемое нормальное распределение вероятностей.
График плотности вероятности при нормальном распределении имеет симметричную колоколообразную форму (рис. 2). Близко к нормальному распределение вероятностей для роста девушек в приведенном примере.
Графический материал для отдельных групп данных может быть подвергнут сопоставлению с целью выявления различий.
4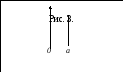 .
Статистические показатели
— это числовые параметры, сокращенно
представляющие распределение вероятностей.
В возможности такого сокращенного
представления можно убедиться, изучив
рисунки 3 и 4. Обе кривые на рисунке 3
одинаковой формы, различие только в
положении относительно координатной
оси. Если левая кривая задается функцией
.
Статистические показатели
— это числовые параметры, сокращенно
представляющие распределение вероятностей.
В возможности такого сокращенного
представления можно убедиться, изучив
рисунки 3 и 4. Обе кривые на рисунке 3
одинаковой формы, различие только в
положении относительно координатной
оси. Если левая кривая задается функцией
![]() ,
то, как известно из школьного курса
алгебры, правая кривая удовлетворяет
равенству
,
то, как известно из школьного курса
алгебры, правая кривая удовлетворяет
равенству
![]() .
Число a
и есть в данном случае показатель
положения. В практике исследований
используют следующие показатели
положения: средняя арифметическая
величина, мода и медиана.
.
Число a
и есть в данном случае показатель
положения. В практике исследований
используют следующие показатели
положения: средняя арифметическая
величина, мода и медиана.
Н
Рис. 4.
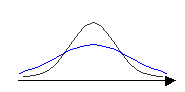
![]() ,
то деформированному — функция
,
то деформированному — функция
![]() .
Параметр
задает степень разброса данных: для
исходного графика =1;
для деформированного — >1.
.
Параметр
задает степень разброса данных: для
исходного графика =1;
для деформированного — >1.
Для оценки разброса данных используются дисперсия и среднеквадратическое отклонение.
Средняя арифметическая. Говорят, что она обладает обобщающим свойством, т. к. в это значение вносят вклад все варианты. Средняя арифметическая вычисляется по формуле
Мx
![]() (1)
(1)
или
в сокращенной записи с использованием
знака суммирования
и скользящего индекса i=1,
2, 3, ... , п,
![]() .
Для средней арифметической величины
употребляют также обозначение Мx.
.
Для средней арифметической величины
употребляют также обозначение Мx.
Очень часто при больших выборках среднюю величину находят взвешенным способом, и полученное значение называют средневзвешенной величиной. Суть этого способа поясним на примере. Пусть учащиеся класса имеют такие оценки по алгебре: пятерка — у 6 человек; четверка — у 7; тройка — у 12 и двойка — у одного. Средний балл находим так:
![]() .
.
Для нахождения средневзвешенной используют таблицу распределения частот по интервалам. В числителе записывают сумму произведений частот k, на средние значения хi в каждом интервале. Для упрощения расчетов это среднее значение по интервалу заменяют на середину интервала. Так для интервала 157 это значение равно x'i=(154+157)/2=155,5. Если в выборке содержатся только целочисленные варианты, то, учитывая, что левая граница не входит в интервал, за середину этого интервала можно принять значение x'i=(155+157)/2=156. Другие точки соответственно будут равны 159, 162, 165, ... Если в ряду даются округленные значения вариантов, середина интервала также может быть округлена до целого. Делаемые таким образом ошибки в различных классах в какой-то мере поглощаются друг другом. В этом проявление закона больших чисел. Формула средневзвешенной:
![]() ,
(2)
,
(2)
где т — количество интервалов. В знаменателе сумма частот, равная объему выборки.
Найдем средний рост девушек по формуле средней взвешенной. Составим вспомогательную таблицу.
|
|
156 |
159 |
162 |
165 |
168 |
171 |
174 |
177 |
180 |
|
|
k |
1 |
4 |
6 |
7 |
6 |
3 |
2 |
0 |
1 |
|
|
|
156 |
636 |
972 |
1155 |
1008 |
513 |
348 |
0 |
180 |
4968 |
Теперь вычислим искомую среднюю величину:
![]() см.
см.
Подсчет по формуле (1) дает 165,4 см. Разница, как видим, невелика. Полученное значение округляется до точности, с которой приводятся варианты.
Мода — наиболее вероятное значение. Практически в качестве моды выбирают значение, чаще других повторяющееся в вариационном ряду.
Медиана отражает взаимное расположение данных на числовой прямой. Это число, справа и слева от которого располагается равное количество вариант. Медиана делит числовую ось на два равновероятных интервала. Вычисление медианы производится по-разному, в зависимости от четности или нечетности объема выборки:
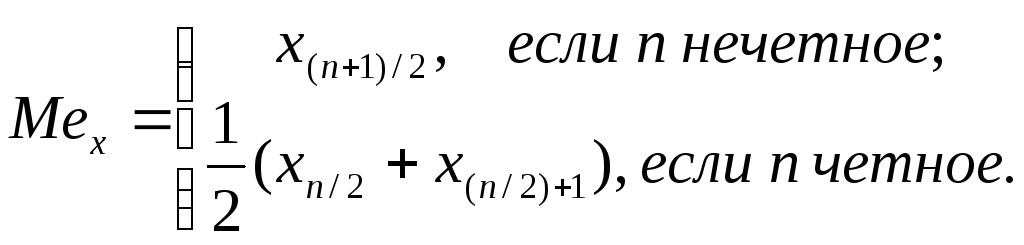 (3)
(3)
Итак, рассмотренные показатели положения по-разному характеризуют распределение вероятностей. Их сравнение по выборке позволяет установить характер распределения вероятностей. Если мода, медиана и средняя арифметическая совпадают, то распределение симметрично. Практически его можно считать нормальным. Если эти параметры различаются, то график распределения вероятностей имеет асимметрию. В этом случае говорят о правом или левом эксцессе.
Дисперсия1 (средний квадрат отклонения) служит оценкой разброса данных, определяет «ширину» графика:
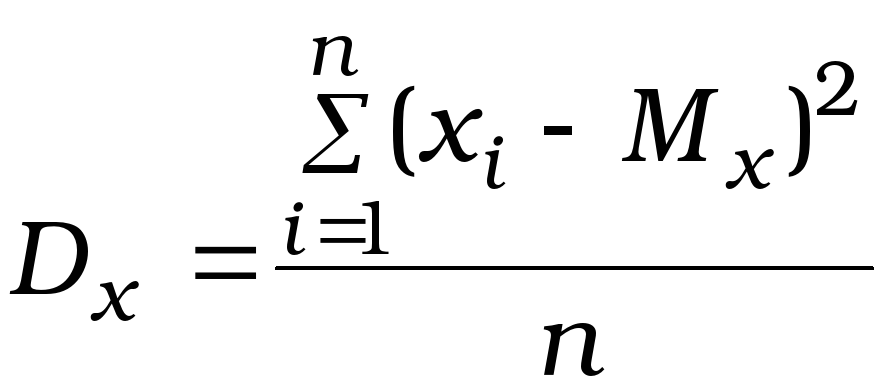
При выборочном исследовании для всякого статистического показателя находится приближенное значение. Теория показывает, что значения дисперсии, находимые по данным выборки имеют в среднем заниженные значения. В практике рекомендуется использовать скорректированную формулу, дающую более точное значение этого показателя по данным выборки:
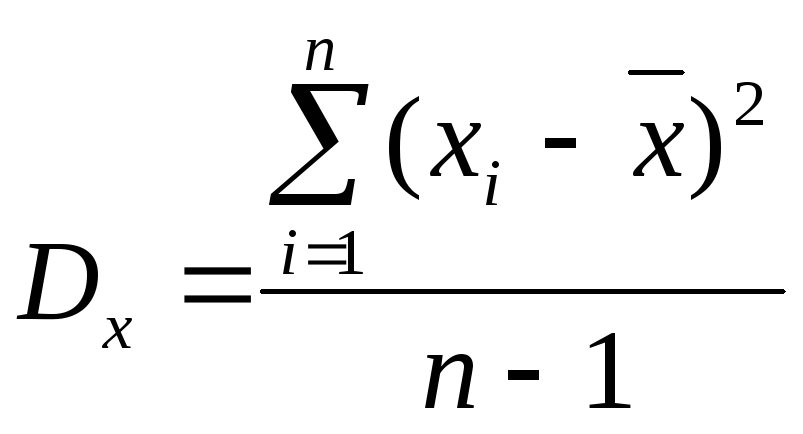 (4)
(4)
С ростом п разница значений, получаемых по обеим формулам уменьшается.
Среднеквадратическое отклонение (сигма) — это корень из дисперсии. Достоинство этого параметра в том, что он измеряется в тех же единицах, что и исследуемая случайная величина:
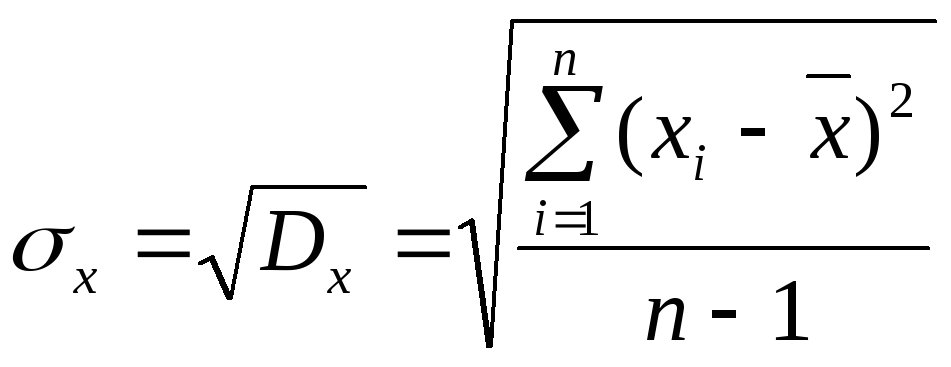 .
(5)
.
(5)
Для нашего вариационного ряда получаются следующие параметры:
Мx =165 см, Моx=165 см, Меx= 165 см, =5,48 см.
Поскольку значения показателей Мx, Моx и Меx практически совпадают, распределение является нормальным.
Рекомендации к анализу и интерпретации результатов. Полученное распределение вероятностей роста девушек, как мы уже отмечали, находит непосредственное практическое применение. Часто в науке выявленное распределение играет вспомогательную роль.
Сопоставление графиков распределения вероятностей и статистических показателей для двух выборок позволяет делать научные выводы. Так сравнение показателей обученности учащихся, обучаемых по традиционной и по новой методике позволяет судить об эффективности педагогической методики. Для такого исследования привлекаются две независимые группы учащихся.
Более подробные сведения об организации эксперимента и математической обработке данных можно почерпнуть в указанной ниже литературе (см., например, [4]).
В настоящее время для статистической обработки экспериментальных данных широко применяются электронные таблицы (например MS Excel).