

2.6.3 Создание индексов и связей между таблицами
Чем больше хранится данных в таблицах, тем больше индексов необходимо для эффективного поиска данных. Индекс – это внутренняя таблица, состоящая из двух столбцов: значение выражения, в котором содержатся все поля, включенные в индекс, и местоположение каждой записи таблицы с данным значением индексного выражения. Для создания индексов по ключевым полям, необходимо установить тип индекса Primary. Для внешних ключей используется тип Regular.
Определив необходимые таблицы и индексы, создадим связи таблиц.
Как уже было описано выше, все таблицы в базе данных будут связаны между собой отношением «один ко многим». Для установления связи между таблицами следует соединить первичный ключ таблицы, находящийся на стороне отношения «один» с соответствующим ему внешним ключом таблицы на стороне отношения «многие».
После установки связи, можно определить критерии обеспечения целостности, для любого действия в главной таблице которое изменяет ключевое значение, таких как, добавление, удаление и изменения.
Для изменения и удаления записей возможно введения одного из следующих правил:
-
Cascade – замена или удаление всех записей в подчинённой таблице, удовлетворяющих старому ключевому значению главной таблице.
-
Restrict – проверяет наличие в подчинённой таблице значений удовлетворяющих текущему значению главного ключа, и при их наличии запрещает изменения или удаление.
-
Ignore – игнорирует ссылочную целостность и позволяет изменять или удалять значения главного ключа.
Для добавления записей можно определить только два правила проверки:
-
Restrict – запрещает добавление, если в главной таблице отсутствует запись с подходящим ключевым значением.
-
Ignore – не выполняет никаких проверок.
Связи таблиц показаны на рисунке 3.3.
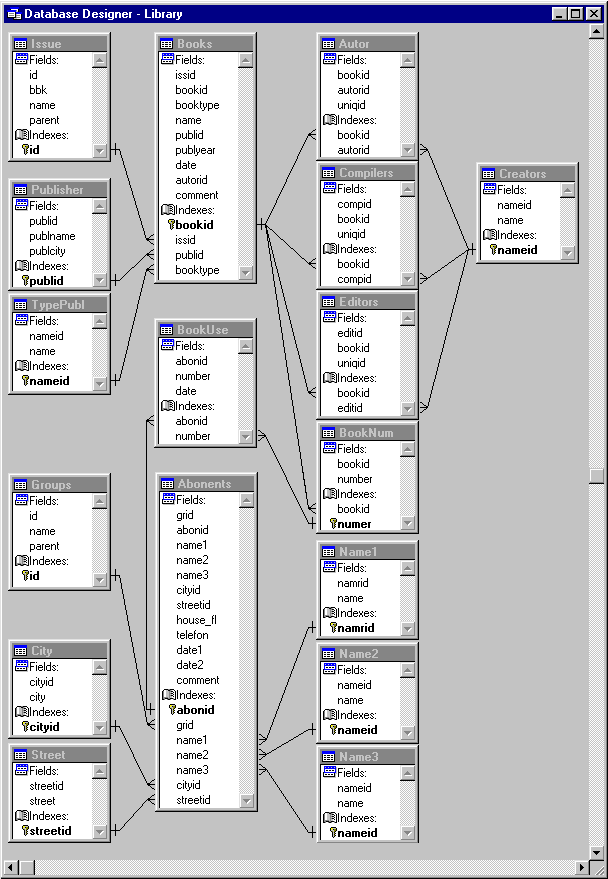
Рис.3.3 Схема связей таблиц
2.8 Разработка алгоритма.
Назначение любой базы (в том числе и БРЭА) заключается в получении пользователем базы необходимой ему информации. Кроме того, пользователю должны быть предоставлены возможности пополнения базы данных вновь возникшей информацией и её коррекции в случае изменения тех или иных компонент, хранящихся в базе данных.
Указанные моменты определяют технологический цикл кругооборота информации между пользователем и базой данных, а также основные направления прохождения информации внутри самой базы, иными словами, - взаимодействие отдельных компонент, составляющих в целом базу данных.
Сказанное может быть проиллюстрировано схемой информационных потоков БД, представленной на рис.4.1. От пользователя поступает некоторое множество заданий на выполнение тех или иных информационных действий. Входные формы воспринимают эти задания и инициализируют соответствующие запросы, которые в свою очередь осуществляют поиск необходимой информации в таблицах, где находятся данные, позволяющие выполнить заданные действия. Выбранная информация с помощью исполнительных частей запросов пересылается в выходные формы и представляется пользователю для её оценки и принятия решения.
Обобщённо алгоритм, реализующий данную технологическую схему обработки информации, представляет собой следующую совокупность действий:
1. Выбор соответствующей выходной формы (Формаi, i=l, ).
2. Заполнение полей формы (Формаi, i=l, ).
3. Отображение информации на видеоконтрольном устройстве.
4. Если необходима твёрдая копия полученных данных, то Ввод исходных данных.
5. Анализ исходных данных (Формаi, i=l, N).
6. Если исходные данные корректны, то переход на пункт 4, в противном случае - выдача диагностического сообщения и переход на пункт 1.
7. Передача данных соответствующему запросу (Запросij, i=l, N; j=l, ).
8. Анализ параметров и условий выборки информации.
9. Формирование списка таблиц для поиска информации (Таблицаi,...,Таблицаk, i, k).
10. Поиск информации по выбранному списку таблиц в соответствии со значениями параметров и условиями выборки.
11. Если информация, удовлетворяющая заданным параметрам и условиям выборки, отсутствует, то выдаётся соответствующее диагностическое сообщение и переход на пункт 1. При нахождении необходимой информации, она передаётся исполнительным частям запросов (Запросij, i=l ,N; j=l , ) и переход на пункт 9.
12. производится её печать, в противном случае переход на пункт 13.
13. Выяснение необходимости завершить работу с базой данных. Если «Да», то переход на пункт 14, если «Нет», то переход на пункт 1.
14. Конец работы.
Здесь и далее обозначения имеют следующий смысл:
• N - мощность (количество) множества входных форм;
• К,, - мощности множеств запросов, соответствующих входным формам (Формаi, i=l, N);
• -мощность множества таблиц;
• - мощность множества выходных форм.
Данный алгоритм может быть выражен блок-схемой, представленной на рис.4.2. Такое представление даёт возможность более наглядного понимания процесса прохождения информации.
АРМ функционирует в следующих режимах:
-
Ввод данных в базу данных АРМ;
-
Просмотр информации из базы данных АРМ;
-
Коррекция информации в базе данных АРМ;
-
Формирование выходных документов.
Выбор режимов работы осуществляется пользователем после инициализации программных модулей. Следовательно структурная схема будет иметь вид показанный на рис.
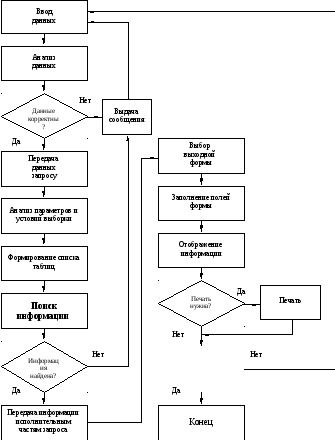

Рис. 4.2 Блок-схема алгоритма, реализующего технологическую схему обработки информации
Рис. 4.3 Структурно-функциональная схема АРМ
В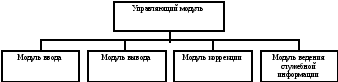
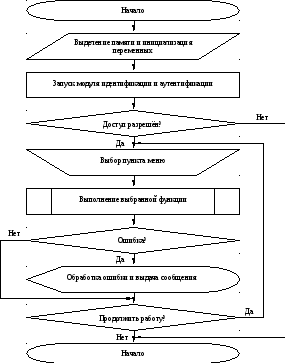 качестве примера рассмотрим блок-схему
алгоритма функционирования управляющего
модуля. Блок-схема приведена на рис.
качестве примера рассмотрим блок-схему
алгоритма функционирования управляющего
модуля. Блок-схема приведена на рис.
Рис. 4.4 Блок-схема функционирования алгоритма управляющего модуля