

3.7. Концептуальные модели и схемы баз данных
Широкое распространение реляционных СУБД и их использование в самых разнообразных приложениях показывает, что реляционная модель данных достаточна для моделирования предметных областей. Однако проектирование реляционной базы данных в терминах отношений на основе кратко рассмотренного выше механизма нормализации зачастую представляет собой очень сложный и неудобный для проектировщика процесс [4]. При этом проявляется ограниченность РМД в следующих аспектах.
Модель не предоставляет достаточных средств для передачи смысла данных. Семантика реальной предметной области должна в независимости от модели представляться в голове проектировщика. В частности, это относится к упомянутой выше проблеме представления ограничений целостности.
Для многих приложений трудно моделировать предметную область на основе плоских таблиц. В ряде случаев на самой начальной стадии проектирования разработчику приходится прилагать массу усилий, чтобы описать предметную область в виде одной (возможно, даже ненормализованной) таблицы.
Несмотря на то, что весь процесс проектирования происходит с учетом зависимостей, реляционная модель не предусматривает средств для их представления. Процесс проектирования начинается с выделения некоторых существенных для приложения объектов предметной области («сущностей») и выявления связей между этими сущностями, тем не менее РМД не предлагает какого-либо аппарата для разделения сущностей и связей.
В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
Более сложные элементы ER-модели рассмотрим на примере самых основных и наиболее очевидных понятиях ER-модели данных [41].
Подтипы и супертипы сущностей. В языках программирования с развитыми типовыми системами (в языках объектно-ориентированного программирования) вводится возможность наследования типа сущности, исходя из одного или нескольких супертипов.
Связи «many-to-many». Иногда необходимо связать сущности таким образом, что с обоих концов связи могут присутствовать несколько экземпляров сущности (например, все члены кооператива сообща владеют имуществом кооператива). Для этого вводится разновидность связи «многие-ко-многим».
Уточняемые степени связи. Иногда необходимо определить возможное количество экземпляров сущности, участвующих в данной связи (например, разработчику запрещено участвовать более чем в трех проектах одновременно). Для выражения этого семантического ограничения на конце связи указывают ее максимальную или обязательную степень.
Каскадные удаления экземпляров сущностей. Некоторые связи бывают настолько сильными (конечно, в случае связи «один-ко-многим»), что при удалении опорного экземпляра сущности (соответствующего концу связи «один») нужно удалить и все экземпляры сущности, соответствующие концу связи «многие». Соответствующее требование «каскадного удаления» можно сформулировать при определении сущности.
Домены. Как и в случае реляционной модели данных, бывает полезно определить потенциально допустимое множество значений атрибута сущности (домена).
Вышеперечисленные и другие более сложные элементы ER-диаграммы «сущность—связи» делают ее существенно более мощной, но одновременно несколько усложняют ее использование. Естественно, при реальном использовании ER-диаграмм для проектирования БД необходимо ознакомиться со всеми возможностями.
Рассмотрим теперь подробнее один из упомянутых элементов — подтип сущности.
Сущность может быть расщеплена на два или более взаимно исключающих подтипа, каждый из которых включает общие атрибуты и/или связи, явно определяемые один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе подтипизацию продолжают и на более низких уровнях, но в большинстве случаев достаточно двух-трех уровней.
Сущность, на основе которой определяются подтипы, называется супертипом. Подтипы должны образовывать полное множество, т. е. любой экземпляр супертипа должен относиться к некоторому подтипу. Иногда для полноты приходится определять дополнительный подтип ПРОЧИЕ (рис. 3.10) [4].
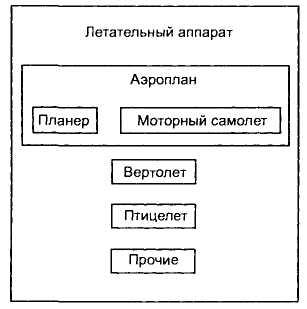
Рис. 3.10. Пример сущности супертипа
Дадим словесную интерпретацию графического изображения. От супертипа: ЛЕТАТЕЛЬНЫЙ АППАРАТ, который должен быть АЭРОПЛАНОМ, ВЕРТОЛЕТОМ, ПТИЦЕЛЕТОМ или ДРУГИМ ЛЕТАТЕЛЬНЫМ АППАРАТОМ. От подтипа: ВЕРТОЛЕТ, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА. От подтипа, который является одновременно супертипом: АЭРОПЛАН, который относится к типу ЛЕТАТЕЛЬНОГО АППАРАТА и должен быть ПЛАНЕРОМ или МОТОРНЫМ САМОЛЕТОМ.
Иногда удобно иметь два или более разных разбиения сущности на подтипы. Например, сущность ЧЕЛОВЕК можно разбить на подтипы по профессиональному признаку (ПРОГРАММИСТ, ДОЯРКА и т. д.); по половому признаку (МУЖЧИНА, ЖЕНЩИНА); по квалификационному (ТЕХНИК, ИНЖЕНЕР, МАГИСТР и т. д.).
Получение реляционной схемы из ER-диаграммы. Для реального использования вышеприведенного материала необходима, кроме прочего, методика создания таблицы из ER-диаграммы.
Шаг 1. Каждая простая сущность превращается в таблицу. Простая сущность — сущность, не являющаяся подтипом и не имеющая подтипов. Имя сущности становится именем таблицы.
Шаг 2. Каждый атрибут становится возможным столбцом с тем же именем; может выбираться более точный формат. Столбцы, соответствующие необязательным атрибутам, могут содержать неопределенные значения; столбцы, соответствующие обязательным атрибутам, — не могут.
Шаг 3. Компоненты уникального идентификатора сущности превращаются в первичный ключ таблицы. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый. Если в состав уникального идентификатора входят связи, к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (этот процесс может продолжаться рекурсивно). Для именования этих столбцов используются имена концов связей и/или имена сущностей.
Шаг 4. Связи «один-ко-многим» (и «один-к-одному») становятся внешними ключами, т. е. делается копия уникального идентификатора с конца связи «один», и соответствующие столбцы составляют внешний ключ. Необязательные связи соответствуют столбцам, допускающим неопределенные значения; обязательные связи — столбцам, не допускающим неопределенные значения.
Шаг 5. Индексы создаются для первичного ключа (уникальный индекс), внешних ключей и тех атрибутов, на которых предполагается в основном базировать запросы.
Шаг 6. Если в концептуальной схеме присутствовали подтипы, то возможны два способа (табл. 3.1):
а) все подтипы в одной таблице;
б) для каждого подтипа — отдельная таблица.
При применении способа а) таблица создается для наиболее внешнего супертипа, а для подтипов могут создаваться представления. В таблицу добавляется, по крайней мере, один столбец, содержащий код ТИПА; он становится частью первичного ключа.
При использовании метода б) для каждого подтипа первого уровня (для более нижних — представления) супертип воссоздается с помощью представления UNION (из всех таблиц подтипов выбираются общие столбцы — столбцы супертипа).
Таблица 3.1. Преимущества и недостатки способов создания таблицы

Шаг 7. Имеется два способа работы при наличии исключающих связей (табл. 3.2):
а) общий домен;
б) явные внешние ключи.
Если остающиеся внешние ключи все в одном домене, т. е. имеют общий формат (способ а), то создаются два столбца: идентификатор связи и идентификатор сущности. Столбец идентификатора связи используется для различения связей, покрываемых дугой исключения. Столбец идентификатора сущности используется для хранения значений уникального идентификатора сущности на дальнем конце соответствующей связи.
Если результирующие внешние ключи не относятся к одному домену, то для каждой связи, покрываемой дугой исключения, создаются явные столбцы внешних ключей; все эти столбцы могут содержать неопределенные значения.
Таблица 3.2. Преимущества и недостатки способов работы при наличии исключающих связей

Альтернативные модели сущностей [4] приведены на рис. 3.11—3.13. Вариант 2 гораздо лучше варианта 1, если подтипы действительно существуют. В свою очередь, вариант 3 намного лучше варианта 3 при наличии осмысленного супертипа D.
Рис. 3.11. Вариант 1. Связи сущностей

Рис. 3.12. Вариант 2. Связи сущностей при существовании подтипов

Рис. 3.13. Вариант 3. Связь сущностей при наличии супертипа D
3.7.2. Виды нотаций
Кроме вышеприведенного способа представления ER-диаграмм, существуют и другие. Рассмотрим их подробнее.
Case-метод Баркера. Нотация ER-диаграммы была впервые введена П. Ченом и получила дальнейшее развитие в работах Р. Баркера (Barker R. CASE*Method. Entity-Relationship Modelling. Copyright Oracle Corporation UK Limited, Addison-Wesley Publishing Co., 1990). Метод Баркера изложен на примере предметной области компании по торговле автомобилями по результатам опроса персонала компании.
Главный менеджер. Одна из основных обязанностей — содержание автомобильного парка, т. е. ему известно, сколько заплачено за машины и каковы накладные расходы. Обладая этой информацией, он устанавливает минимальную цену, за которую можно продать конкретный экземпляр. Кроме того, он несет ответственность за продавцов и обязан знать, кто что продает и сколько уже продал.
Продавец. Он обязан знать, какую цену запрашивать и какова нижняя граница сделки. Кроме того, он должен владеть информацией о машинах: год выпуска, марка, модель и т. п.
Администратор. Его задача сводится к составлению контрактов, для этого нужна информация о покупателе, автомашине и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи.
Первый шаг моделирования — анализ информации в результате опроса и выделение сущностей (рис. 3.14). Определение сущности было приведено ранее.
![]()
Рис. 3.14. Графическое изображение сущности
Каждая сущность должна обладать уникальным идентификатором [14]. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами:
-
иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация. Одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами;
-
обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
-
обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности;
-
может обладать любым количеством связей с другими сущностями.
Из приведенных выше сведений следует, что сущности, которые могут быть идентифицированы с главным менеджером — это автомашины и продавцы. Продавцу важны автомашины и связанные с их продажей данные. Для администратора важны покупатели, автомашины, продавцы и контракты. Исходя из этого, выделяются четыре сущности (автомашина, продавец, покупатель, контракт), которые изображаются на диаграмме следующим образом (рис. 3.15).
![]()
Рис. 3.15. Выделенные сущности
Следующим шагом моделирования является идентификация связей. Уточним понятие связи, приведенное ранее.
Связь — это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущность-потомок может существовать только при существовании сущности-родителя.
Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением, имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка.
Например, связь продавца с контрактом может быть выражена следующим образом:
-
продавец может получить вознаграждение за один или более контрактов;
-
контракт должен быть инициирован ровно одним продавцом.
Степень связи и обязательность графически изображаются следующим образом (рис. 3.16) [14].

Рис. 3.16. Графическое изображение степени связей и обязательности
Таким образом, два предложения, описывающие связь продавца с контрактом, графически будут выражены следующим образом (рис. 3.17) [14].
![]()
Рис. 3.17. Изображение связи между сущностями «продавец» и «контракт»
Описав также связи остальных сущностей, получим следующую схему (рис. 3.18) [14].

Рис. 3.18. Диаграмма связей между сущностями
Последним шагом моделирования является идентификация атрибутов (определение атрибута приводилось ранее).
Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т. д.).
Экземпляр атрибута — это определенная характеристика отдельного элемента множества; определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута.
Атрибут может быть либо обязательным, либо необязательным (рис. 3.19) [14]. Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т. е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа).
Уникальный идентификатор — это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рис. 3.20) [14].

Рис. 3.19. Изображение атрибутов сущности

Рис. 3.20. Изображение вида идентификации сущности
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком «#».
Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности — это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные — как альтернативные ключи.
С учетом имеющейся информации дополним построенную ранее диаграмму (рис. 3.21) [14].
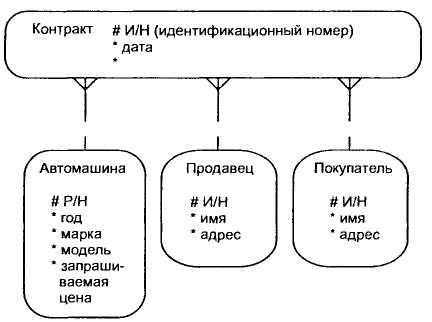
Рис. 3.21. Дополненная диаграмма связей сущностей
Основы методологии IDEF1. Стандарт IDEF1 был разработан как инструмент для анализа и изучения взаимосвязей между информационными потоками в рамках коммерческой деятельности предприятия. Целью подобного исследования является дополнение и структуризация существующей информации и обеспечение качественного менеджмента информационными потоками. Необходимость в подобной реорганизации информационной области, как правило, возникает на начальном этапе построения корпоративной АИС, и методология 1DEF1 позволяет достаточно наглядно обнаружить «черные дыры» и слабые места в существующей структуре информационных потоков. Применение методологии IDEF1, как инструмента построения наглядной модели информационной структуры предприятия по принципу «как должно быть», позволяет решить следующие задачи:
1. выяснить структуру и содержание существующих потоков информации на предприятии;
2. определить существующие правила и законы, по которым осуществляется движение информационных потоков, а также принципов управления ими;
3. определить, какие проблемы, выявленные в результате функционального анализа и анализа потребностей, вызваны недостатком управления соответствующей информацией;
4. выявить информационные потоки, требующие дополнительного управления для эффективной реализации модели.
Характерно, что с помощью IDEF1-модели рассматривают не только автоматизированные компоненты, БД и соответствующую им информацию, но и реальные объекты, такие как сами сотрудники, кабинеты, телефоны и т. д. В отличие от методов разработки структур БД (IDEF1X), IDEF1 является аналитическим методом. Результаты анализа информационных потоков могут быть использованы для стратегического и тактического планирования деятельности предприятия и улучшения информационного менеджмента.
Основные преимущества IDEFI. Методология IDEF1 позволяет на основе простых графических изображений моделировать информационные взаимосвязи и различия между:
-
реальными объектами;
-
физическими и абстрактными зависимостями, существующими среди реальных объектов;
-
информацией, относящейся к реальным объектам;
-
структурой данных, используемой для приобретения, накопления, применения и управления информацией.
Концепции моделирования IDEFI. При построении информационной модели разработчик всегда оперирует двумя основными глобальными областями, каждой из которых соответствует множество характерных объектов. Первой из этих областей является реальный мир, или же совокупность физических и интеллектуальных объектов, таких, как люди, места, вещи, идеи и т. д., а также все свойства этих объектов и зависимости между ними. Второй же является информационная область. Она включает в себя существующие информационные отображения объектов первой области и их свойств. Информационное отображение, по существу, не является объектом реального мира, однако изменение его, как правило, является следствием некоторого изменения соответствующего ему объекта реального мира. Методология IDEF1 разработана как инструмент для исследования статического соответствия вышеуказанных областей и установления строгих правил и механизмов изменения объектов информационной области при изменении соответствующих им объектов реального мира.
Терминология и семантика IDEFI. Методология IDEF1 разделяет элементы структуры информационной области, их свойства и взаимосвязи на классы. Центральным понятием методологии IDEF1 является понятие сущности. Класс сущностей представляет собой совокупность информации, накопленной и хранящейся в рамках предприятия и соответствующей определенному объекту или группе объектов реального мира. Основными концептуальными свойствами сущностей в IDEF1 являются:
1) устойчивость. Информация, имеющая отношение к той или иной сущности, постоянно накапливается;
2) уникальность. Любая сущность может быть однозначно идентифицирована из другой сущности.
Каждая сущность имеет свое имя и атрибуты. Класс атрибутов представляет собой набор пар, состоящих из имени атрибута и его значения для определенной сущности. Каждая сущность может характеризоваться несколькими ключевыми атрибутами. Класс взаимосвязей в IDEF1 представляет собой совокупность взаимосвязей между сущностями. Взаимосвязь между двумя отдельными сущностями считается существующей в том случае, когда класс атрибутов одной сущности содержит ключевые атрибуты другой сущности. Каждый из вышеописанных классов имеет свое условное графическое отображение.
На рис. 3.22 приведен пример IDEF1-диаграммы [15]. На ней представлены две сущности с именами «Отдел» и «Сотрудник» и взаимозвязь между ними с именем «работает в». Имя взаимосвязи всегда выражается в глагольной форме. Если же между двумя или несколькими объектами реального мира не существует установленной зависимости, то с точки зрения IDEF1 между соответствующими им сущностями взаимосвязь также отсутствует [15].

Рис. 3.22. Пример IDEF1-диаграммы
Основы методологии IDEF1X. IDEF1X является методом разработки реляционных БД и использует условный синтаксис, специально созданный для удобства построения концептуальной схемы. Концептуальной схемой называют универсальное представление структуры данных в рамках коммерческого предприятия, независимое от конечной реализации БД и аппаратной платформы. Будучи статическим методом разработки, IDEF1X изначально не предназначен для динамического анализа по принципу «as is» («как есть»), тем не менее он иногда применяется в этом качестве, как альтернатива методу IDEF1. Использование метода IDEF1X наиболее целесообразно для построения логической структуры БД после того, как все информационные ресурсы исследованы (например, с помощью метода IDEF1) и решение о внедрении реляционной БД, как части корпоративной АИС, принято. Следует заметить, что средства моделирования IDEF1X специально разработаны для построения реляционных информационных систем, и если необходимо разработать другую систему (например, объектно-ориентированную), то лучше избрать другие методы моделирования.
Существует несколько очевидных причин, по которым IDEF1X не следует применять в случае построения нереляционных систем. Во-первых, IDEF1X требует от проектировщика определения ключевых атрибутов, для того чтобы отличить одну сущность от другой, в то время как объектно-ориентированные системы не требуют задания ключей в целях идентифицирования объектов. Во-вторых, в тех случаях, когда более чем один атрибут является однозначно идентифицирующим сущность, разработчик должен определить один из этих атрибутов первичным ключом, а все остальные — вторичными. Таким образом построенная и переданная для окончательной реализации программисту IDEFlX-модель является некорректной для применения методов объектно-ориентированной реализации; она предназначена для построения реляционной системы.
Концепция и семантика IDEFIX. Несмотря на то, что терминология IDEF1X практически совпадает с терминологией IDEF1, существует ряд фундаментальных отличий в теоретических концепциях этих методологий. Сущность в IDEF1X описывает совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых друг от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности. Таким образом, сущность в 1DEF1X описывает конкретный набор экземпляров реального мира в отличие от сущности в IDEF1, которая представляет собой абстрактный набор информационных отображений реального мира. Примером сущности IDEF1X может быть сущность «СОТРУДНИК», которая представляет собой всех сотрудников предприятия, а один из них, скажем, Иванов Петр Сергеевич, является конкретной реализацией этой сущности. На рис. 3.22 каждый экземпляр сущности СОТРУДНИК содержит следующую информацию: ID сотрудника, имя сотрудника, адрес сотрудника и т. п. В IDEFlX-модели эти свойства называются атрибутами сущности. Каждый атрибут содержит только часть информации о сущности.
Связи между сущностями в IDEF1X представляют собой ссылки, соединения и ассоциации между сущностями. Фактически, связи — суть глаголы, которые показывают, как соотносятся сущности между собой, что демонстрирует ряд нижеприведенных примеров.

Здесь взаимосвязи между сущностями соответствуют схеме «один-ко-многим», т. е. один экземпляр первой сущности связан с несколькими экземплярами второй сущности. Причем первая сущность является родительской, а вторая — дочерней. В приведенных примерах глаголы заключены в угловые скобки. Связи отображаются в виде линии между двумя сущностями с точкой на одном конце и глагольной фразой, отображаемой над линией. Диаграмма связи между Сотрудником и Отделом приведена на рис. 3.22.
Отношения «многие-ко-многим» обычно используются на начальной стадии разработки диаграммы, например, в диаграмме зависимости сущностей и отображаются в IDEF1X в виде сплошной линии с точками на обоих концах. Поскольку отношения «многие-ко-многим» могут скрыть другие бизнес-правила или ограничения, они должны быть полностью исследованы на одном из этапов моделирования. Например, иногда отношение «многие-ко-многим» на ранних стадиях моделирования идентифицируется неправильно, на самом деле представляя два или несколько случаев отношений «один-ко-многим» между связанными сущностями. Или в случае необходимости хранения дополнительных сведений о связи «многие-ко-многим», например, даты или комментария, такая связь должна быть заменена дополнительной сущностью, содержащей эти сведения. При моделировании необходимо иметь в виду, что все отношения «многие-ко-многим» следует подробно обсудить на более поздних стадиях моделирования в целях правильного моделирования отношений.
Идентификация сущностей. Представление о ключах. Сущность в диаграмме IDEF1X описывается графическим объектом в виде прямоугольника. На рис. 3.23 приведен пример IDEF1X-диаграммы [16]. Каждый прямоугольник, отображающий сущность, разделяется горизонтальной линией на части. Верхняя часть называется ключевой областью (в ней расположены ключевые поля), а нижняя часть — областью данных (в ней расположены неключевые поля). Ключевая область объекта СОТРУДНИК содержит поле «Уникальный идентификатор сотрудника», в области данных находятся поля «Имя сотрудника», «Адрес сотрудника», «Телефон сотрудника» и т. д.
Ключевая область содержит первичный ключ для сущности или набор атрибутов, выбранных для идентификации уникальных экземпляров сущности. Атрибуты первичного ключа располагаются над линией в ключевой области. Неключевые атрибуты располагаются в области данных.

Рис. 3.23. Пример IDEFlX-диаграммы
При создании сущности в IDEFlX-модели одним из главных вопросов является вопрос: «Как идентифицировать уникальную запись?». Требуется уникальная идентификация каждой записи в сущности для того, чтобы правильно создать логическую модель данных. Напомним, что сущности в IDEF1X всегда имеют ключевую область, поэтому в каждой сущности должны быть определены ключевые атрибуты.
Выбор первичного ключа для сущности очень важен и требует особого внимания. В качестве первичных ключей используют несколько атрибутов или групп атрибутов. Атрибуты, которые могут быть выбраны первичными ключами, называются кандидатами в ключевые атрибуты (потенциальные атрибуты); они должны уникально идентифицировать каждую запись сущности. В соответствии с этим, ни одна из частей ключа не может быть NULL, не заполненной или отсутствующей.
Например, для того чтобы корректно использовать сущность СОТРУДНИК в IDEFlX-модели данных (и далее, в базе данных), необходимо уникально идентифицировать записи. Правила, по которым выбирается первичный ключ из списка предполагаемых ключей, очень жесткие, тем не менее их применяют ко всем типам баз данных и информации. Согласно правилам, атрибуты и группы атрибутов должны:
-
уникальным образом идентифицировать экземпляр сущности;
-
не использовать NULL-значений;
-
не изменяться со временем. Экземпляр идентифицируется с помощью ключа. При изменении ключа, экземпляр соответственно меняется;
-
быть как можно короче для индексирования и получения данных. При использовании ключа, являющегося комбинацией ключей из других сущностей, необходимо убедиться в том, что каждая часть ключа соответствует правилам.
Для наглядного представления о том, как следует подходить к выбору первичных ключей, найдем первичный ключ для сущности СОТРУДНИК:
-
Атрибут «ID сотрудника» является потенциальным ключом, так как он уникален для всех экземпляров сущности СОТРУДНИК.
-
Атрибут «Имя сотрудника» не очень хорош для потенциального ключа, так как среди служащих на предприятии может быть, к примеру, двое Иванов Петровых.
-
Атрибут «Номер страхового полиса сотрудника» является уникальным, но проблема в том, что СОТРУДНИК может не иметь такового.
-
Комбинация атрибутов «Имя сотрудника» и «Дата рождения сотрудника» может оказаться удачной для наших целей и стать искомым потенциальным ключом.
После проведенного анализа назовем два потенциальных ключа: первый — «Номер сотрудника», второй — комбинация, включающая поля «Имя сотрудника» и «Дата рождения сотрудника». Поскольку атрибут «Номер сотрудника» имеет самые короткие и уникальные значения, то он больше других подходит для первичного ключа.
При выборе первичного ключа для сущности разработчики модели часто используют дополнительный (суррогатный) ключ, т. е. произвольный номер, который уникальным образом определяет запись в сущности. Атрибут «Номер сотрудника» является примером суррогатного ключа. Суррогатный ключ лучше всего подходит на роль первичного ключа потому, что является коротким и быстрее всего идентифицирует экземпляры в объекте. К тому же, система способна генерировать суррогатные ключи так, чтобы нумерация была сплошной, т. е. без пропусков.
Потенциальные ключи, которые не выбраны первичными, могут использоваться в качестве вторичных или альтернативных ключей. С помощью альтернативных ключей часто отображают различные индексы доступа к данным в конечной реализации реляционной базы.
Если сущности в IDEFlX-диаграмме связаны, связь передает ключ (или набор ключевых атрибутов) дочерней сущности. Эти атрибуты называются внешними ключами. Внешние ключи определяются как атрибуты первичных ключей родительского объекта, переданные дочернему объекту через их связь. Передаваемые атрибуты называются мигрирующими.
Классификация сущностей в IDEF1X. Зависимые и независимые сущности. При разработке модели зачастую приходится сталкиваться с сущностями, уникальность которых зависит от значений атрибута внешнего ключа. Для этих сущностей (для уникального определения каждой сущности) внешний ключ должен быть частью первичного ключа дочернего объекта.
Дочерняя сущность, уникальность которой зависит от атрибута внешнего ключа, называется зависимой сущностью. Сущность СОТРУДНИК является зависимой сущностью потому, что его идентификация зависит от сущности ОТДЕЛ. В обозначениях IDEF1X зависимые сущности представлены в виде закругленных прямоугольников.
Зависимые сущности далее классифицируются как сущности, которые не могут существовать без родительской сущности и сущности, которые не идентифицируются без использования ключа родителя (сущности, зависящие от идентификации). Сущность СОТРУДНИК принадлежит ко второму типу зависимых сущностей, так как сотрудники могут существовать и без отдела.
Напротив, существуют ситуации, в которых сущность зависит от существования другой сущности. Рассмотрим две сущности: ЗАПРОС, используемый для отслеживания запросов покупателей, и ПОЗИЦИЯ ЗАПРОСА, которая отслеживает отдельные элементы в ЗАПРОСЕ. Связь между этими сущностями можно выразить в виде ЗАПРОС <содержит> одну или несколько ПОЗИЦИЙ ЗАПРОСА. В этом случае, ПОЗИЦИЯ ЗАПРОСА зависит от существования ЗАКАЗА.
Сущности, независящие при идентификации от других объектов в модели, называются независимыми сущностями. В вышеописанном примере сущность ОТДЕЛ — независимая. В IDEF1X независимые сущности представлены в виде прямоугольников.
Типы связей между сущностями. Идентифицирующие и неидентифицирующие связи. В IDEF1X концепция зависимых и независимых сущностей усиливается типом взаимосвязей. Пусть необходимо, чтобы внешний ключ передавался в дочернюю сущность (и, в результате, создавал зависимую сущность), тогда следует создать идентифицирующую связь между родительской и дочерней сущностью. Идентифицирующие взаимосвязи между сущностями обозначаются сплошной линией.
Неидентифицирующие связи, являющиеся уникальными для IDEF1X, также связывают родительскую сущность с дочерней. Эти связи используются для отображения другого типа передачи атрибутов внешних ключей — передачи в область данных дочерней сущности (под линией).
Неидентифицирующие связи отображаются пунктирной линией между объектами. Поскольку переданные ключи в неидентифицирующей связи не являются составной частью первичного ключа дочерней сущности, то этот вид связи не проявляется ни в одной идентифицирующей зависимости. В этом случае и ОТДЕЛ, и СОТРУДНИК рассматриваются как независимые сущности.
Тем не менее взаимосвязь отражает зависимость существования, если бизнес-правило для взаимосвязи определяет, что внешний ключ не может принимать значение NULL. Если существует внешний ключ, то это означает, что запись в дочерней сущности может существовать только при наличии ассоциированной с ним родительской записи.
Преимущества IDEF1X. Основным преимуществом IDEF1X [16] по сравнению с другими методами разработки реляционных БД является жесткая и строгая стандартизация моделирования. Установленные стандарты позволяют избежать различной трактовки построенной модели, которая, несомненно, является значительным недостатком ER-диаграмм.