

Теория математической обработки геодезических измерений
1Теория погрешностей
-
Обработка и анализ измерений одной величины
-
Моделирование погрешностей измерений
-
Пусть X – истинное значение измеряемой величины, остающееся неизменным в процессе измерений;
Х – случайная величина (СВ), представляющая собой вероятностную модель измерительной технологии;
xi
– значение
величины
X,
представляющее собой результат
i-го
измерения
и являющееся элементом спектра СВ «X»,
т.е.
![]() ;
;
i = 1, 2, ... , n – индекс измерения;
n – количество измерений;
E(X) – математическое ожидание (МО) СВ «X»;
![]() – дисперсия СВ
«X».
– дисперсия СВ
«X».
В такой ситуации можно определить следующие погрешности измерений:
i = xi – X – истинная погрешность i-го измерения; (Т.1)
i = xi – E(X) – случайная погрешность i-го измерения; (Т.2)
= E(X) – X – постоянная погрешность технологии измерений. (Т.3)
Очевидно, что
i = i + , (Т.4)
т.е. истинная погрешность представляет собой сумму случайной и постоянной погрешностей.
Определения (Т.1) – (Т.4) иллюстрируются (Рис. Т.1) на совмещенных числовых осях X и (индекс «i» опущен):

 0
0
 |
| | |
|
| | |
0 X E(X) x X
Рис. Т.1. Истинная, случайная и постоянная погрешности.
(Имеется только результат измерений «x» относительно известного начала 0.)
Представим основные числовые характеристики – математические ожидания (МО), дисперсии и начальные моменты второго порядка – каждого вида погрешностей, опираясь на определения (Т.1) – (Т.3) и известную связь между начальными и центральными моментами второго порядка ( = σ2 + 12):
Постоянная погрешность : E() = ; D() = 0; () = .
Случайная
погрешность
: E()
= 0; D()
=
![]() ; ()
=
; ()
=
![]() .
.
Истинная
погрешность
: E()
= ; D()
=
![]() ; ()=
; ()=
![]() +
.
+
.
Убедитесь в данных результатах в качестве Упражнения, помня что:
E()
=
![]() ≡ 0;
E(X)
=
≡ 0;
E(X)
=
![]() ,
D(X)
=
,
D(X)
=
![]() ,
а (X)
=
,
а (X)
=
![]() + (
+ (![]() )2.
)2.
Все приведённые числовые характеристики погрешностей связаны между собой так же, как и сами погрешности (Т.4):
E() = E() + E() = (Т.5)
D()
= D()
+ D()
=
![]() (Т.6)
(Т.6)
()
= ()
+ ()
=
![]() +
(Т.7)
+
(Т.7)
Постоянная
погрешность ,
будучи детерминированной величиной,
не является объектом вероятностного
моделирования. Её значения определяют
из специальных исследований, а в среднее
арифметическое результатов измерений
![]() вводят соответствующую поправку. Это
– один путь учета влияния постоянных
погрешностей. Другой путь борьбы с ними
заключается в надлежащей организации
технологии измерений, компенсирующей
эти погрешности в окончательных
результатах xi.
Дело в том, что результат измерений xi
обычно является функцией нескольких
отсчетов (операций), по которым он
вычисляется. Например, углы при
геодезических и астрономических
измерениях определяют при альтернативных
положениях вертикального круга и на
разных участках лимба. Если результаты
xi
не содержат постоянной погрешности,
определяемой формулой (Т.3), т.е. =
E(X)
– X
=
0, то
вводят соответствующую поправку. Это
– один путь учета влияния постоянных
погрешностей. Другой путь борьбы с ними
заключается в надлежащей организации
технологии измерений, компенсирующей
эти погрешности в окончательных
результатах xi.
Дело в том, что результат измерений xi
обычно является функцией нескольких
отсчетов (операций), по которым он
вычисляется. Например, углы при
геодезических и астрономических
измерениях определяют при альтернативных
положениях вертикального круга и на
разных участках лимба. Если результаты
xi
не содержат постоянной погрешности,
определяемой формулой (Т.3), т.е. =
E(X)
– X
=
0, то
E(X) = X. (Т.8)
Выражение (Т.8) эквивалентно условию отсутствия постоянной погрешности в измерениях.
Специальные исследования, направленные на определение постоянной погрешности, могут представлять собой процедуру, подобную эталонированию. Эталон, согласно [РМГ 29–99] – это «средство измерений…, предназначенное для воспроизведения и (или) хранения единицы (физической величины) и передачи её размера … средствам измерений». Численно он представляет собой некоторую меру, значение которой известно с высокой степенью точности.
Обозначим числовое значение эталона как Y. Процедура эталонирования обычно заключается в измерении величины Y = const путём реализации некоторой технологии, вероятностная модель которой – это СВ «Y». В результате мы получаем выборку y1, y2, …, y k. Пусть эта выборка простая, т.е. не коррелированная и равноточная. Полагая, что выборка принадлежит генеральной совокупности (ГС) «Y», она же СВ «Y», мы можем оценить её МО. В курсе ТВ и МС показано, что оптимальной оценкой МО ГС «Y» по данным простой выборки является среднее арифметическое, представляющее собой состоятельную и несмещённую оценивающую функцию (ОФ) с минимальной дисперсией:
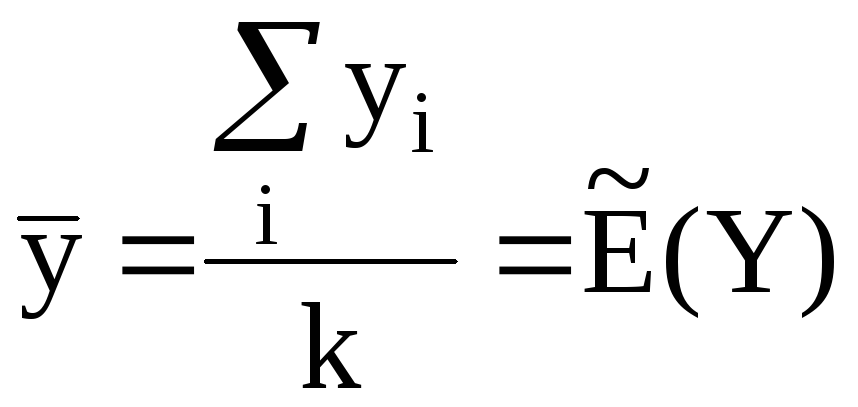 . (Т.9)
. (Т.9)
Разность между оценкой (Т.9) и значением эталона Y позволит оценить постоянную погрешность:
![]() –
Y. (Т.10)
–
Y. (Т.10)
Естественно, что должна быть проверена нулевая гипотеза о незначимости найденной постоянной погрешности
H0 = {E(Y) = Y } (Т.11)
против альтернативной
HA = {E(Y) ≠ Y }. (Т.12)
Нулевая гипотеза (Т.11) проверяется с помощью теста
tЭ
= (![]() –Y)
/
–Y)
/
![]() . (Т.13)
. (Т.13)
Здесь
![]() ,
а
,
а
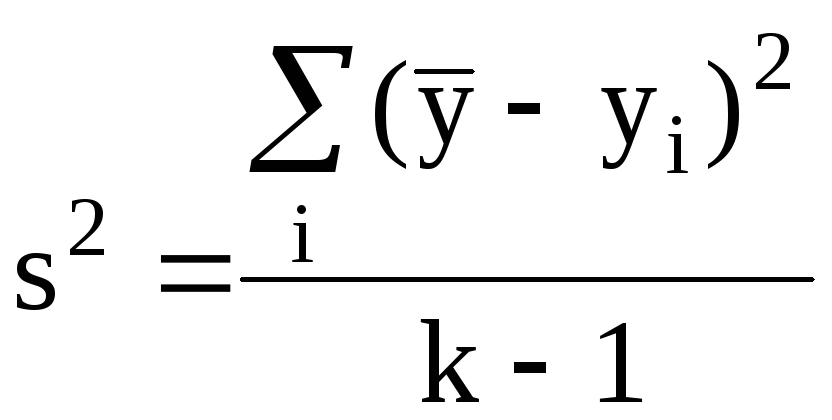 . (Т.14)
. (Т.14)
Критическая область проверяемой гипотезы находится за пределами интервала tT = [tH; tB]. Нижняя tH и верхняя tB границы интервала – это квантили распределения Стьюдента, определяемые при (k – 1) степенях свободы на уровне значимости :
t H = t k-1;1-tB = t k-1;tH
Когда tЭ
![]() tT,
нулевая
гипотеза отвергается,
т.е. постоянная
ошибка δЭ
признаётся значимой,
то она должна вводиться в каждый очередной
результат
tT,
нулевая
гипотеза отвергается,
т.е. постоянная
ошибка δЭ
признаётся значимой,
то она должна вводиться в каждый очередной
результат
![]() ,
с целью нахождения наиболее
надёжного значения (ННЗ)
X
измеряемой величины X:
,
с целью нахождения наиболее
надёжного значения (ННЗ)
X
измеряемой величины X:
X
=
![]() – δЭ. (Т.15)
– δЭ. (Т.15)
В случае незначимости
постоянной
погрешности Э,
ННЗ X
величины X
принимается равным СА
![]() .
В такой ситуации истинная
и случайная
погрешности совпадают: .
.
В такой ситуации истинная
и случайная
погрешности совпадают: .
Далее обратимся к случайным погрешностям и определим их основные свойства, полагая распределение этих погрешностей нормальным. Данное предположение основывается на том, что технологии геодезических измерений соответствуют условиям «Центральной предельной теоремы».
Нормальное распределение СВ «X» характеризуется двумя параметрами: a= E(X) и b = X. Для случайной погрешности = x – E(X) они будут равны следующим значениям:
aΔ = E() = 0 и bΔ = Δ = X. Тогда плотность нормальной случайной погрешности будет иметь вид:
f()
=![]() e
e
![]() . (Т.16)
. (Т.16)
Этой функции соответствует следующий график (рис.Т.2):
f(X) f()
 P(>
0) = P(
0)
P(>
0) = P(
0)
0

0 E(X) X
Рис. Т.2. Плотность распределения нормальной случайной погрешности.
Нормальную случайную погрешность можно стандартизировать и перейти к стандартному значению t случайной погрешности, вычисляемому по формуле:
t = X. (Т.17)
Уравнение плотности (Т.16) определяет, а Рис. Т.2 иллюстрирует основные свойства случайных погрешностей, распределенных по нормальному закону.
1. Случайные погрешности имеют нулевое МО (При любом законе распределения!):
E() = 0. (Т.18)
2. Положительные и отрицательные случайные погрешности равновероятны (Для симметричных распределений!):
P(> 0) = P( 0) = 1/2. (Т.19)
3. Малые по абсолютной величине случайные погрешности более вероятны, чем большие, т.е.:
P(0
< ||
< X)
![]() 0.68 > P(X
< ||
<X)
0.68 > P(X
< ||
<X)
![]() 0.27. (Т.20)
0.27. (Т.20)
В последней формуле (Т.20) конкретные значения вероятностей 0,68 и 0,27 как раз и соответствуют нормальному распределению.
Наиболее распространённым и удобным обобщённым показателем точности или неопределённостью случайных погрешностей измерений чаще всего служит их средняя квадратическая погрешность (СКП) измерений, представляющая собой оценку стандарта измерений, который одновременно является стандартом случайных погрешностей:
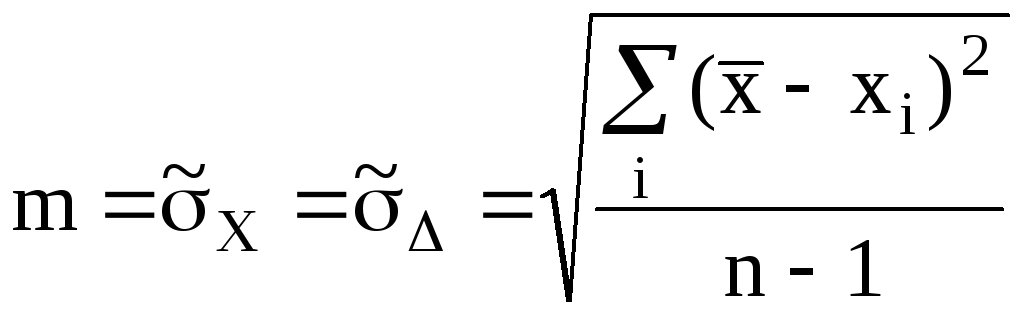 . (Т.21)
. (Т.21)
Дополнительными показателями точности измерений, т.е. точности случайных погрешностей служат ещё две величины: средняя погрешность ϑX=[||] / n или ϑX =[|v|] / (n – 0,5), как оценка среднего отклонения, и срединная погрешность ρ=|n| или ρ=|vn|, как оценка срединного отклонения. При нормальном распределении случайных погрешностей между этими показателями и средней квадратической погрешностью существует функциональная зависимость:
ϑX ≈ 0,8 m или m ≈ 1,25 ϑX; (Т.22)
ρ ≈ ⅔ m или m ≈ 1,5 ρ. (Т.23)
Приведённые соотношения могут служить «быстрыми» критериями проверки гипотезы о нормальности распределения. Однако их мощность много ниже критериев Пирсона или Колмогорова-Смирнова. В связи со сказанным, было бы уместно рассматривать эти соотношения в качестве индикаторов нормальности.