

2.6. Нормальное распределение
Если случайная величина формируется под действием большого количества независимых факторов, вклад каждого из которых в значение случайной величины мал, то в силу центральной предельной теоремы эта случайная величина будет иметь нормальное распределение. В роли таких величин могут выступать: объем продаж в конкурентной отрасли или в промышленности в целом, суммарные инвестиции, суммарное потребление домашних хозяйств и тому подобные величины, имеющие аддитивную природу, то есть складывающиеся из многих малых взаимно независимых величин.
Основная особенность случайной величины состоит в том, что нельзя предвидеть, какое значение она примет в результате испытания. Однако при достаточно большом числе испытаний поведение суммы независимых случайных величин почти утрачивает случайный характер и становится почти закономерным. При увеличении числа слагаемых в сумме противоположные случайные колебания отдельных величин сглаживаются и распределение вероятностей суммы становится весьма простым, приближаясь при определенных условиях к нормальному распределению.
Нормальное распределение одной случайной величины Xоднозначно определяется лишь двумя параметрами: средним значением, обычно обозначаемым, и стандартным отклонением, обычно обозначаемым. Это обычно обозначают так:Х=N(,)
2.6.1. Свойства нормального распределения
Рассмотрим основные свойства нормального распределения.
10. Если ряд случайных величин(X1,X2, …Xn)имеет нормальное распределение, то их сумма(X1+X2+ …+Xn)или любая линейная комбинация (1X1+2X2+ …+nXn)также будет иметь нормальное распределение.
20. Распределение величины
![]() ,
представляющей собой взвешенную суммупнезависимых нормально распределенных
случайных величин Хk=N(k,k)
с параметрамиk
иk,
также будет иметь нормальное распределение
с параметрами
,
представляющей собой взвешенную суммупнезависимых нормально распределенных
случайных величин Хk=N(k,k)
с параметрамиk
иk,
также будет иметь нормальное распределение
с параметрами
![]() и
и![]() .
.
В частности, если все ck=1/n,
всеkиk,
одинаковы и равныl,l,соответственно, то=l,
а
![]() .
Обозначая
.
Обозначая
![]() ,
имеем, таким образом,М[
,
имеем, таким образом,М[![]() ]
= М[Х],[Х]
=[Х]/
]
= М[Х],[Х]
=[Х]/![]() .
Отсюда видно, что разброс среднего
арифметического независимых нормально
распределенных случайных величин
стремится к нулю при неограниченном
увеличении числа этих величин. Если,
например, взята достаточно большая
репрезентативная выборка населения,
то средний доход в выборке почти наверняка
окажется близким к действительному
среднему доходу населения.
.
Отсюда видно, что разброс среднего
арифметического независимых нормально
распределенных случайных величин
стремится к нулю при неограниченном
увеличении числа этих величин. Если,
например, взята достаточно большая
репрезентативная выборка населения,
то средний доход в выборке почти наверняка
окажется близким к действительному
среднему доходу населения.
2.6.2 Плотность вероятности и функция нормального распределения
График плотности вероятности нормального распределения имеет типичный колоколообразный вид и показан на рис. 2.5. Максимум этой функции находится в точке х=, а "растянутость" вдоль осиXопределяется параметром. Чем меньше значение этого параметра, тем более острый и высокий максимум имеет плотность нормального распределения. Аналитически плотность вероятности нормального распределения на интервале (-,+).
 ,
,
а функция распределения

M[X]=
,
D[X]= 2,
V[X]=![]()
Плотность вероятности нормального
распределения пропорциональна величине
ехр![]() ,
гдеz- безразмерная
величина, определяемая выражениемz=
,
гдеz- безразмерная
величина, определяемая выражениемz=![]() .
Поэтому плотность нормального
распределения достаточно быстро убывает
при удалениихот среднего значения.
Случайная величинаzимеет
нулевое математическое ожидание и
единичную дисперсию; это вытекает из
их определений и свойств, учитывая, чтоz=
.
Поэтому плотность нормального
распределения достаточно быстро убывает
при удалениихот среднего значения.
Случайная величинаzимеет
нулевое математическое ожидание и
единичную дисперсию; это вытекает из
их определений и свойств, учитывая, чтоz=![]() .
.
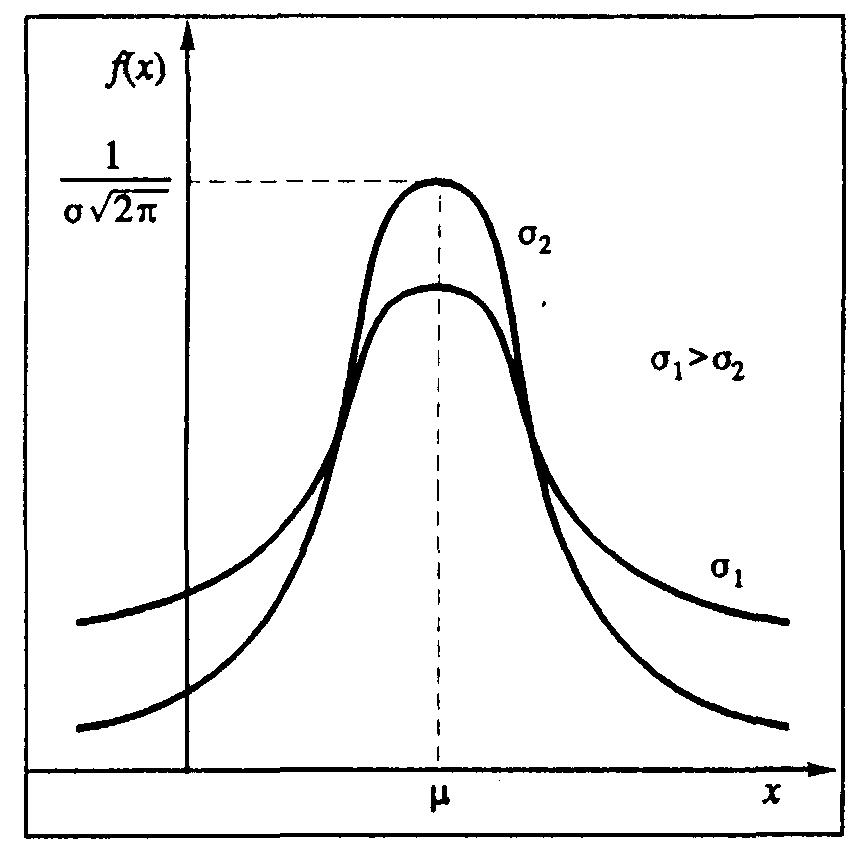
Рис. 2.5. Функция плотности вероятности нормального распределения
Она как и исходная случайная величинах,нормально распределена, но уже не зависит от каких-либо параметров. Поэтому достаточно протабулировать стандартное нормальное распределение (то есть представить в виде таблиц значения плотности вероятностиfZ(z)), чтобы определить характеристики любой нормально распределенной величины. Эта функция называется плотностью стандартного нормального распределения. Стандартное нормальное распределение - это нормальное распределение с параметрами = 0, =1 (ZN(0,1))
На
практике чаще используют таблицы
значений не плотности, а функции
распределения стандартной нормальной
величины F(x).
Интересуясь, например, вероятностью
того, что нормально распределенная
случайная величинаXпопадает в интервалx1X<x2
мы вначале находим соответствующий
интервал для нормально распределенной
стандартной случайной величиныZ(z1Z<z2):z1=![]() иz2=
иz2=![]() .
Затем по таблице находим значения
функции распределенияF{z1)иF(z2)и определяем вероятность попадания
случайной величиныZв
заданный интервал
.
Затем по таблице находим значения
функции распределенияF{z1)иF(z2)и определяем вероятность попадания
случайной величиныZв
заданный интервал
Prob{z1Z<z2} =F{z1) -F(z2), совпадающую с искомой вероятностью попадания случайной величиныXв заданный интервалProb{x1X<x2}. Геометрически эта вероятность изображается площадью под графиком функции плотности вероятности в интервале отx1 доx2.
Аналогично можно решать и обратную задачу - нахождения интервала, в который нормально распределенная случайная величина попадает с заданной вероятностью. Эта процедура часто используется в задачах теории оценивания и проверкигипотез. Так, например, пусть мы хотим проверить гипотезу о равенстве среднего значения нормально распределенной случайной величиныX(для генеральной совокупности) нулю, допуская вероятность ошибки 0,05 в случае, если эта гипотеза верна. В этом случае выборочное значение стандартной нормально распределенной случайной величиныZдолжно попадать в такой интервал, что вероятностьProb{z1Z<z2}= 0,95. Из этого условия и соображений симметрии можно найти границы интервала - критические значенияzкр=z2=-z1, такие, чтоProb{Z z1} =Prob{Z z2}= 0,05/2 = 0,025.
Сравнивая выборочное значение величины называемое z-статистикой с критическим значениемzкр, мы принимаем (если z1z<z2) или отвергаем (еслиz<z1 или z2<z) проверяемую гипотезу с точностью (уровнем значимости)ε=0,05 (5%).