Метод Уорда.
Возьмем пороговое расстояние между
кластерами
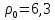 .
Так, объекты делятся на 4 кластера. Состав
кластеров приведен в таблице:
.
Так, объекты делятся на 4 кластера. Состав
кластеров приведен в таблице:
|
Номер кластера |
Количество объектов в кластере |
Состав класса |
|
кластер
1
|
1 |
Города:Оренбург
|
|
кластер 2
|
8 |
Города: Орск, Ясный, Новотроицк, Узулук, Гай, Кувандык, Бугуруслан, Абдулино
|
|
кластер 3
|
10 |
Города: Соль-Илецк, Сорочинск Районы:Оренбурский, Октябрьский, Новоорский, Ташлинский, Сакмарский, Пономаревский, Саракташский, Адамовский |
|
кластер 4
|
28 |
Города: Медногорск Районы:Светлинский, Шарлыкский, Северный, Грачевский, Матвеевский, Тоцкий, Донбаровский, Беляевский, Курманаевский, Тюльганский, Кваркенский, Новосергиевский, Красногвардейский, Алексеевский, Соль-Илецкий, Ясненский, Александровский, Переволодский, Акбулакский, Сорочинский, Кувандыкский, Бузулуцкий, Первомайский, Илекцкий, Гальский, Бугурусланский, Абдулинский |


|
Для наших значений получим такую таблицу средних значений:кластер |
x1 |
x2 |
x3 |
x4 |
x5 |
|
Кластер 1 |
6,441147236 |
1,938111934 |
1,999280901 |
6,042935126 |
6,646011128 |
|
Кластер 2 |
0,1590876 |
1,6596896 |
0,1304692 |
0,5181898 |
0,0337696 |
|
Кластер 3 |
-0,1256991 |
-0,3405606 |
1,2359494 |
-0,034185 |
-0,1465114 |
|
Кластер4 |
-0,230602 |
-0,4217865 |
-0,5500903 |
-0,3516644 |
-0,1946805 |
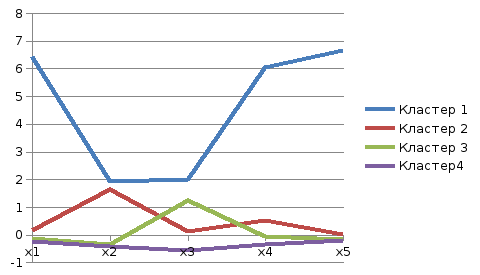
Получим такой график средних значений:
Интерпретация:
Кластер №1 состоит из 1 элемента, г. Оренбург. Характерны самые высокие значения по всем показателям
Для кластера №2 характерно близкое к максимальному число телефонных аппаратов, но почти самое низкое число введенных в действие жилых домов.
Для кластера №3 характерны практически минимальные показатели по числу предприятий оптовой и розничной торговли, а так же по числу телефонных аппаратов, однако число введенных в действие жилых домов велико
Кластер №4 принимает минимальные значения при всех показателях
Кластеризация методом k-средних.
Метод k-средних относится к дивизимным кластер-процедурам. Основной принцип работы иерархических дивизимных процедур состоит в последовательном разделении групп элементов сначала самых далеких, а затем все более приближенных друг к другу. Первоначально считается, что все объектов объединены и составляют один кластер. Среди множества объектов на основе матрицы расстояний определяются наиболее удаленные друг от друга и берут их за основу двух новых кластеров. Оставшиеся объектов распределяются по образованным двум классам по принципу: объект следует отнести к тому классу, расстояние до которого наименьшее. Затем в этих двух классах находят наиболее удаленные друг от друга объекты, которые следует отнести к разным классам и т.д. Преимущество дивизимных кластер-процедур состоит в том, что все расчеты осуществляются на основе исходной матрицы расстояний. В отличие от агломеративных кластер-процедур, ее не нужно пересчитывать на каждом шаге.
Для реализации данного метода изначально задается число классов, на которые необходимо разбить имеющуюся совокупность из объектов. Для того чтобы задать начальные условия необходимо иметь либо дополнительную информацию о количестве кластеров, либо предварительно оценить число кластеров с помощью иерархических кластер-процедур. Мы провели метод Уорда и обнаружили, что объекты делятся на 4 класса.
До начала процедуры классификации
задаются
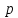 случайно выбранных объектов – эталоны
ε. Каждому эталону приписывается
порядковый номер, который, одновременно,
является номером класса. Из оставшихся
случайно выбранных объектов – эталоны
ε. Каждому эталону приписывается
порядковый номер, который, одновременно,
является номером класса. Из оставшихся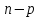 объектов извлекается объект и проверяется,
к какому из эталонов он находится ближе.
Данный объект присоединяется к тому
эталону, для которого наблюдается
минимальное расстояние, то есть
объектов извлекается объект и проверяется,
к какому из эталонов он находится ближе.
Данный объект присоединяется к тому
эталону, для которого наблюдается
минимальное расстояние, то есть .
Веса и эталоны пересчитываются по
правилу:
.
Веса и эталоны пересчитываются по
правилу:

Где
 -
«вес» класса,
-
«вес» класса,
 - номер итерации. При этом нулевое
приближение строится с помощью случайно
выбранных
- номер итерации. При этом нулевое
приближение строится с помощью случайно
выбранных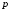 точек исследуемой совокупности:
точек исследуемой совокупности: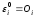 ,
,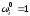 ,
,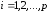 .
.
Введем начальные параметры:
Количество кластеров возьмем 4, т.к. по методу Уорда данные поделились на четыре кластера.
Количество итераций оставим то же, что и по умолчанию, т.е. 10.
Т.е. в нашем случае в начале выбираются
два эталона:
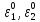 .
Далее выбирается объект и рассчитываются
расстояния от объекта к нашим двум
эталонам и выбирается минимальное
расстояние. Затем происходит пересчет
эталонов и пересчет весов. Далее
выбирается следующий объект и т. д.
.
Далее выбирается объект и рассчитываются
расстояния от объекта к нашим двум
эталонам и выбирается минимальное
расстояние. Затем происходит пересчет
эталонов и пересчет весов. Далее
выбирается следующий объект и т. д.
Получим состав наших двух кластеров:
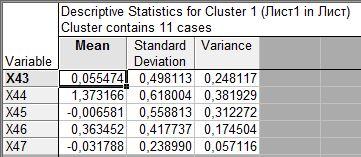
Первый кластер состоит из 11 объектов. Приведем некоторые из них.
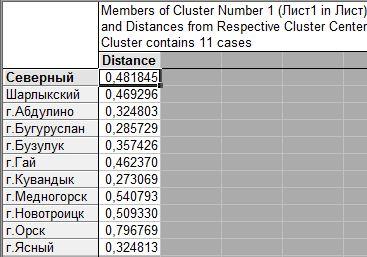
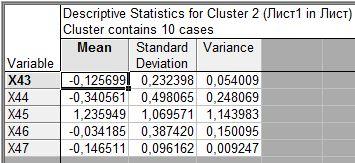
Второй кластер состоит из 10 объектов.
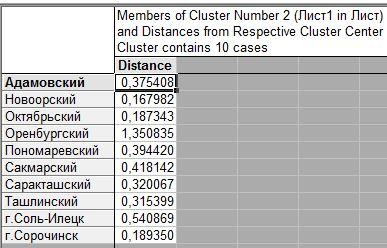
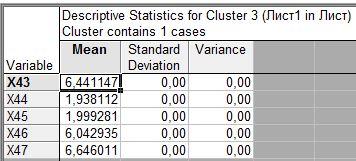
Третий из 1 объекта

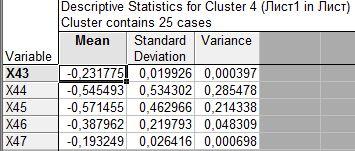
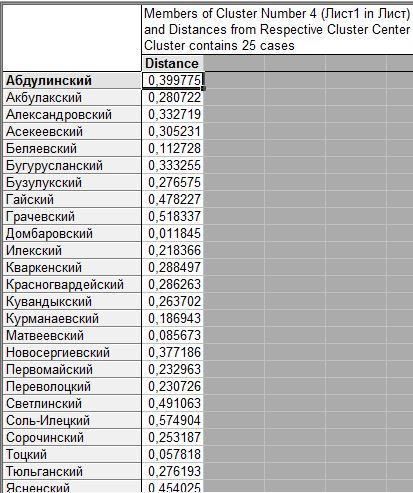
Четвертый из 25
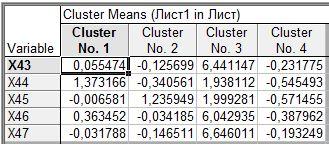
Построим средние значения каждого признака в каждом из двух кластеров:
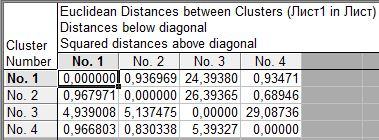
Можем найти евклидово и квадратичное евклидово расстояния между кластерами. Над диагональю матрицы видим квадратичное евклидово расстояние, под – обычное евклидово расстояние.
Построим график средних значений для каждого показателя:

Интерпретация полученных результатов:
Кластер №3 состоит из 1 элемента, г. Оренбург. Характерны самые высокие значения по всем показателям
Для кластера №3 характерно близкое к максимальному число телефонных аппаратов, но почти самое низкое число введенных в действие жилых домов.
Для кластера №2 характерны практически минимальные показатели по числу предприятий оптовой и розничной торговли, а так же по числу телефонных аппаратов, однако число введенных в действие жилых домов велико
Кластер №4 принимает минимальные значения при всех показателях
Проведем анализ внутриклассовых и межклассовых дисперсий:
Выведем суммы квадратов при расчете внутриклассовых и межклассовых дисперсий.
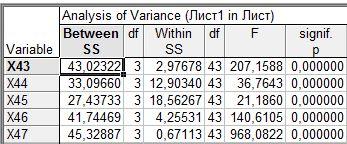
Сами значения внутриклассовых и межклассовых дисперсий получим, разделив значения сумм на соответствующие степени свободы.

Таблица, представленная выше, содержит также наблюденное значение F-критерия, а также значимость нулевой гипотезы о равенстве межгрупповой и внутригрупповой дисперсий. На уровне значимости 0,05 по всем признакам нулевая гипотеза отвергается. Это означает, что каждый из признаков вносит существенный вклад в разделение объектов на классы.
Получим результаты расчетов описательных статистик для каждого кластера: среднего арифметического, оценку среднего квадратичного отклонения, несмещенную оценку дисперсии по каждому признаку.