

1.возникновение ИТ
Понятие информационная технология возникло в последние десятилетия XX века в процессе становления информатики. Особенностью информационной технологии является то, что в ней и предметом, и продуктом труда является информация, а орудиями труда — средства вычислительной техники и связи. Информационная технология как наука о производстве информациивозникла именно потому, что информация стала рассматриваться как
вполне реальный производственный ресурс наряду с другими материальными ресурсами. При этом производство информации и ее верхнего уровня — знаний — оказывает решающее влияние на модификацию и создание новых промышленных технологий нформационная технология — совокупность методов и способов получения, обработки, представления информации, направленных на изменение ее состояния, свойств, формы, содержания и осуществляемых в интересах пользователей.
2.понятия систем и управления
Система – организационное сложное целое, состоящее из множества элементов, расположенных в определенном порядке и зависящих друг от друга, взаимодействующих между собой при помощи отношений и связей, и образованное для выполнения конкретной цели. Системы можно классифицировать: по способу образования:
•естественные – системы, созданные природой без вмешательства человека;
•искусственные – системы, созданные человеком для удовлетворения различных потребностей; сущности:
•космические;
•биологические;
•технические;
•социальные;
•экономические;
•экологические;
•политические и др.;
Виды систем управления:
стратегическое планирование деятельности организации; управленческой деятельностью; управление внутренними или внешними коммуникациями; управление человеческими ресурсами;
управление производственной и обслуживающей деятельностью; управленческое консультирование;

управление внутренними или внешними коммуникациями.
3.концептуальная модель базовой ит
4.классификация комп по областям применения
ПК) появились в результате эволюции .ПК в начале ориентировались на самого широкого
потребителя непрофессионала Классификация серверов по виду ресурса: файл-сервер;сервер баз данных; принт-сервер;вычислительный сервер;сервер приложений. Классификация серверов по масштабу сети:сервер рабочей группы; сервер отдела; сервер масштаба предприятия (корпоративный сервер).
5. Общие требования, предъявляемые к современным компьютерам предъявляются требования: Отношение стоимость/производительность Надежность и
отказоустойчивость. Масштабируемость . Совместимость (мобильность) программного обеспечения
Надежность основана на предотвращении неисправностей путем снижения интенсивности отказов и сбоев его элементов.
Отказоустойчивость - это такое свойство вычислительной системы, которое обеспечивает ей, возможность продолжения действий, заданных программой, после возникновения неисправностей.
Масштабируемость - возможность наращивания числа и мощности процессоров, объемов оперативной и внешней памяти и других ресурсов вычислительной системы.
Концепция программной совместимости заключается в создании такой архитектуры, которая была бы одинаковой с точки зрения пользователя для всех моделей системы независимо от цены и производительности каждой из них.
6. Оценка производительности вычислительных систем
Единицей измерения производительности компьютера является время: компьютер, выполняющий тот же объем работы за меньшее время является более быстрым.
В современных процессоров скорость протекания процессов взаимодействия внутренних функциональных устройств определяется задержками в этих устройствах и задается единой системой синхросигналов, вырабатываемых некоторым генератором тактовых импульсов, работающим с постоянной тактовой частотой. Производительность ЦП зависит от трех параметров: такта (или частоты) синхронизации, среднего количества тактов на команду и количества выполняемых команд. Одной из альтернативных (по отношению к времени выполнения) единиц измерения производительности процессора является MIPS - (миллион команд в секунду). Для научно-технических задач производительность процессора оценивается в
MFLOPS (миллионах чисел-результатов вычислений с плавающей точкой в секунду, или миллионах элементарных арифметических операций над числами с плавающей точкой, выполненных в секунду).
7. Числовая и нечисловая обработка
необходимость в обработке экономической информации, в создании информационных систем для различных организаций .эти применения требуют различных баз данных, которые могут хранить миллионы и миллиарды отдельных записей. Чтобы предварительно найти требуемую запись, обработать ее и определить форму ее вывода требуются такие операции, как поиск и
сортировка.Эти процессы характеризует нечисловую обработку данных.
При числовой обработке используются такие объекты, как переменные, векторы, матрицы, многомерные массивы, константы и т.д.
При нечисловой обработке объектами могут быть файлы, записи, поля, иерархии, сети, отношения и т. д. В классических ЭВМ способы построения запоминающих устройств и способы обращения к ним центрального процессора ориентированы на числовую обработку
8. Ограничения фон-неймановской архитектуры
Вфоннеймановской архитектуре для обработки огромного объема информации мы располагаем одним процессором. При этом возникает ситуация, когда миллиарды байтов (символов) информации находятся в состоянии ожидания передачи через канал и обработки на устройстве весьма ограниченной мощности.. необходимо внести два изменения в архитектуру:а)использовать параллельные процессоры;б)приблизить процессоры к данным, чтобы устранить их постоянную передачу по каналу
ВЗУ фоннеймановской архитектуры обращение происходит по адресу. Но при нечисловой обработке обращение должно осуществляться по содержанию. Поэтому используется способ эмуляции ассоциативной адресации с помощью основного адресного доступа. При этом создаются специальные таблицы (справочники) для перевода ассоциативного запроса в соответствующий адрес. Таблицы называются списками ссылок, или индексами. Один из выходов – ассоциативные запоминающие устройства (АЗУ)
9. Концепция параллельной обработки данных
Необходимость параллельной обработки может возникнуть по следующим причинам:1.Велико время решения данной задачи.2.Мала пропускная способность системы.3.Необходимо улучшение использования системы.
Для распараллеливания необходимо соответствующимУскорениобраз м о ганизовать выч сления. Сюда входят:составление параллельных программ; обнаружение в зм жного параллел зма
Рассмотрим е
граф, описывающий обработк
последовательн и данных ость процессов
большой
программы.
Условия
параллель
ного
выполнени
я
Дляпроцессовиспольз вания скрытой параллельной обработки требуются преобразования программных конструкций, такие как:уменьшение ысоты деревьев арифметических выражений; преобразование линейных рекуррентных соотношений; замена операторов; преобразование блоков IF и DO к каноническому виду; распределение циклов
Уменьшение
высоты
дерева
(a+b)+
(c+d) h = 2
Дерево б)
Для арифметического выражения с n переменными или константами уменьшение высоты дерева позволяет достигнуть ускорения обработки порядка O(n/log2 n) при использовании O(n) процессоров. В рассмотренном примере выражение может быть вычислено за два шага вместо трех первоначальных Замена операторов.Исходный блок операторов присваивания:X=BCD+E Y=AX; Z=X+FG; Ts = 6 при n = 1 Путем замены операторов можно получить следующий блок: X=BCD+E ;Y=ABCD+AE;Z=BCD+E+FG;Tm = 3 при n = 5 Этот блок может быть вычислен параллельно при использовании 5 процессоров за три шага с ускорением обработки U = Ts /Tm = 6/3 = 2
10. Концепция конвейерной обработки данных
Примером конвейерной организации является сборочный транспортер на производстве. Если
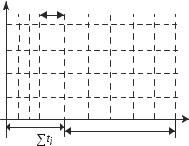
транспортер несет аналогичные, но не тождественные изделия, то это – последовательный конвейер; если же все изделия одинаковы, то это – векторный конвейер.
последовательные конвейеры. Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями.
Последовательный конвейер
|
|
|
|
|
|
t j |
|
|
|
|
|
I V |
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
||
I |
I |
I |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
I |
I |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
I |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
t |
|
|
|
|
t р а з = |
|
|
|
( L 1) t j |
|
|
|
Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых команд и операндов соответствует максимальной производительности конвейера
11. Классификация архитектур вычислительных систем
Структура обыкновенной однопроцессорной ЭВМ архитектуры фон Неймана содержит одинарный поток команд и одинарный поток данных (структура ОКОД или SISD).
Процессоры образуют конвейер, на вход которого поступает одинарный поток данных. Информация на выходе одного процессора является входной информацией для следующего в конвейерной цепочке.
Это обеспечивается подведением к каждому процессору своего потока команд, то есть имеется множественный поток команд.
В системе SIMD используется несколько потоков данных и один общий поток команд.
Если эти процессоры организованы так, что при выполнении заданных вычислений, инициированных контроллером, они работают параллельно, то система называется матричным процессором (задачи числовой обработки).
Если соединить каждый процессор непосредственно с его памятью и работать в режиме поиска по всему массиву, то получим
ассоциативный процессор
(задачи нечисловой обработки). Процессорные ансамбли применимы как для числовой, так и нечисловой обработки.
Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс.
К классу MIMD могут быть отнесены, следующие конфигурации:
-мультипроцессорные системы;
-системы с мультиобработкой;
-многомашинные системы;
-локальные и глобальные компьютерные сети, в т.ч. Internet.
12. Мультипроцессорные системы
Мультипроцессорные системы - это системы, имеющие два или более процессоров с общим управлением, совместно использующие ресурсы системы (память, информационные шины, команды, данные) и взаимодействующие между собой.
КЛАССИФИКАЦИЯ МУЛЬТИПРОЦЕССОРНЫХ СИСТЕМ
1.Конвейерные и векторные процессоры
2.Машины типа SIMD 3.Многопроцессорные машины с SIMD-процессорами (MSIMD) 4.Машины типа MIMD
4.1.Мультипроцессорные системы с общей памятью
4.2.Мультипроцессорные системы с локальной памятью и многомашинные системы
МУЛЬТИПРОЦЕССО РНЫЕ СИСТЕМЫ С ОБЩЕЙ ПАМЯТЬЮ
Мультипроцессорная когерентность кэш-памяти. Проблема когерентности (согласованности) кэш-памяти состоит в необходимости гарантировать, что любое считывание элемента данных дает последнее по времени записанное в него значение. Существуют два класса протоколов когерентности кэш-памяти.
Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы).
Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно кэши расположены на общей (разделяемой) шине и контроллеры всех кэшей наблюдают за шиной (просматривают ее) для определения того, не содержат ли кэши информацию об изменении сотояния соответствующего блока.
13. Матричные процессоры
Наиболее распространенными из систем класса один поток команд – множество потоков данных (SIMD) являются матричные системы, которые лучше всего приспособлены для решения задач, характеризующихся параллелизмом независимых объектов илиданных. Организация систем подобного типа, на первый взгляд, достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд и большое число процессорных элементов, работающих параллельно и обрабатывающих каждая свойпоток данных. Таким образом, производительность системы оказывается равной сумме производительностей всех процессорных элементов. Однако на практике чтобы обеспечить достаточную эффективность системы при решении широкого круга задач, необходимо организовать связи
между процессорными элементами с тем, чтобы наиболее полно загрузить их работой. Именно характер связей между процессорными элементами и определяет разные свойства системы.
14. Векторные конвейерные процессоры
В векторных машинах пары операндов, принадлежащие двум разным векторам, подаются на функциональное устройство (включающее множество одинаковых функциональных
элементов) одновременно, и со всеми парами элементов векторов проводят одновременно функциональные преобразования.
Упрощенная
схема
векторной
машины
•Типичное использование векторного конвейера – это процесс, вырабатывающий по двум исходным векторам А и В результирующий вектор С для арифметической операции С = А + В. В этом случае на конвейер поступает множество одинаковых команд.
•По мере вычисления адресов, пары операндов могут непрерывно вводиться в
арифметическое устройство. В такой конвейерной архитектуре требуются регистры (или управляющие векторы), хранящие необходимую информацию до тех пор, пока можно начать выполнение команды.
•Векторная команда реализуется с помощью управляющего вектора. Если i-й разряд управляющего вектора установлен в 1, то операция Ci = Аi + Вi выполняется и Сi записывается в результирующий вектор. Где i – изменяется от 1 до L (L - длина вектора).
•Для предварительной подготовки преобразуемых векторов используются векторные регистры, на которые собираются подлежащие обработке вектора.
Для того чтобы выполнить ту же обработку на последовательном конвейере, потребовалось бы использовать его L раз.
Эквивалентом оценки tvp в последовательном конвейере является величина
tsq = tfs +(L - 1) tbs ,
где tsq, tfs и tbs — соответственно время обработки на последовательном конвейере, время его разгона и время обработки на самой медленной его ступени. Сравнивая tvp и tsq, получаем, что эффективность векторного конвейера будет выше последовательного (время обработки на векторном конвейере будет меньше, чем на последовательном), то есть и ts + tf + tb tfs +(L - 1) tbs , в случае, если L 1 + (ts + tf + tb - tfs)/tbs . Установлено, что знаменатель дроби в правой части неравенства, как правило, составляет около одной десятой числителя, что соответствует значению L 10.
условия для векторной обработки программ
Для векторизации необходимы векторы-аргументы плюс независимые операции над ними. Кандидаты для векторизации - это самые внутренние циклы программы.
Пример векторизуемого фрагмента, для которого выполнены все указанные условия:
Do i = 1,n
C(i) = A(i) + B(i)
End Do
Пример невекторизуемого фрагмента (очередная итерация не может начаться, пока не закончится предыдущая):
Do i = 1,n
C(i) = C(i-1)+ B(i)
End Do
•15.ассоциативный процессор
В ассоциативной памяти параллельный поиск идет сразу по большой группе ячеек и в итоге поисковому признаку может удовлетворять содержимое нескольких ячеек. Возможности выполнения различных видов поиска и разнообразие структур ассоциативной памяти объясняют, почему для обозначения этого устройства существует так много синонимов: память с параллельным поиском, запоминающее устройство с многозначным ответом, память с распределенной логикой, логико-запоминающее устройство и т.д. Одновременность в работе —неотъемлемое свойство ассоциативного запоминающего устройства (АЗУ). В АЗУ поиск идет по всем элементам сразу. Ассоциативное запоминающее устройство, дополненное логикой и микропрограммным управлением, называют ассоциативным процессором (АП).
Базовая структура пословно организованного ассоциативного процессора. В основе архитектур ассоциативных процессоров с пословной организацией лежит параллелизм на уровне слов, и в большинстве конфигураций обработка слов выполняется последовательно по разрядам.
Базовая структура пословно организованного ассоциативного процессора
16.Закон Амдала(ЛАЛАЛАЛАЛ)
•Предположим, что в программе доля операций, которые нужно выполнять последовательно, равна S, где 0 ≤ S ≤ 1. Крайние случаи в значениях S соответствуют полностью параллельным
(S = 0) и полностью последовательным (S = 1) программам.
Для того, чтобы оценить, какое ускорение U может быть получено на компьютере из N процессоров при заданном значении S, можно воспользоваться законом Амдала:
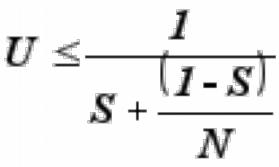 Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно.
Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно.
СЛЕДСТВИЕ
•Для того чтобы ускорить выполнение программы в U раз необходимо ускорить не менее, чем в U раз не менее, чем
(1-1/U)-ю часть программы.
Таким образом, для эффективного использования мультипроцессорных систем (МПС) необходимо тщательное согласование структур алгоритмов и программ с особенностями архитектуры параллельных вычислительных систем.
17. Концепция вычислительных систем с управлением потоком данных
Существуют трудности, связанные с решением проблемы автоматизации параллельного программирования.
Поэтому актуальны исследования новых методов построения высокопроизводительных ВС, одними из которых являются ВС с управлением потоком данных, или потоковые ВС.
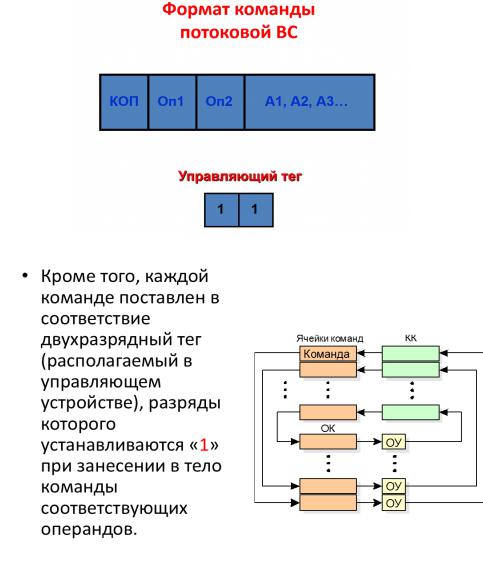
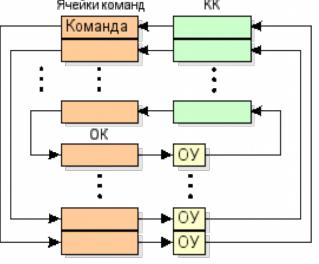
•В системах с управлением потоками данных предполагается наличие большого числа специализированных операционных устройств (ОУ) для определенных видов операций (сложения, умножения и т.п., отдельных для разных типов данных). Данные снабжаются указателями их готовности к обработке (тегами), на основании которых данные загружаются в соответствующие свободные операционные блоки. При достаточном количестве операционных блоков может быть достигнут высокий уровень распараллеливания вычислительного процесса.
•Принципиальное отличие потоковых машин состоит в том, что команды выполняются не в порядке следования команд в тексте программы, а по мере готовности их операндов.
 Процессор с упр. Потоком данных
Процессор с упр. Потоком данных
•«Потоковая программа» размещается в массиве ячеек команд. Команда наряду с кодом операции содержит поля, куда заносятся готовые операнды, и поле, содержащее адреса команд, в которые должен быть направлен в качестве операнда результат операции.
18. Понятие о марковском случайном процессе, потоки событий, классификация СМО
Понятие марковского процесса - Случайный процесс, протекающий в системе, называется Марковским, если для любого момента времени t0 вероятностные характеристики процесса в будущем зависят только от его состояния S0 в данный момент t0 и не зависят от того, когда и как система пришла в это состояние.
t |
t |
0 |
о е |
|
|
|
|
|
t |
t 0 |
П р о ш л |
|
|
|
|
|
|
Б у д у щ е е |
|||
|
0 |
|
Н |
t |
0 |
( |
S |
0 |
) |
|
|
|
|
а |
с т о |
я |
щ |
е е |
|
||
К понятию марковского процесса.
Потоки событий - Потоком событий называется последовательность однородных событий, следующих одно за другим в случайные моменты времени.
 - с л у ч а й н а я в е л и ч и н а
- с л у ч а й н а я в е л и ч и н а
Важнейшей характеристикой потока событий является его интенсивность – среднее число событий, приходящихся на единицу времени. Интенсивность может быть как постоянной, так и переменной, зависящей от времени t.
Поток событий называется простейшим (или стационарным пуассоновским), если он обладает сразу тремя свойствами: стационарен, ординарен и без последействия.
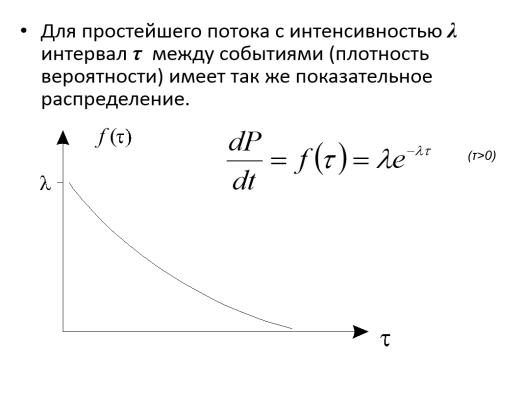
Величина λ в приведенной формуле называется параметром показательного закона. Если интервал Т между событиями
T = 1/ λ ,
то такой интервал называют коротким.
Для простейшего потока характерно, что короткие интервалы между событиями более вероятны, чем длинные; ≈ 63 % промежутков времени между событиями имеют длину меньше короткой.
Классификация СМО
Системы массового обслуживания делятся на типы (или классы) по ряду признаков. Первое деление: СМО с отказами и СМО с очередью. В СМО с отказами заявка, поступившая в момент, когда все каналы заняты, получает отказ, покидает СМО и в дальнейшем процессе обслуживания не участвует. Примеры СМО с отказами встречаются в телефонии: заявка на разговор, пришедшая в момент, когда все каналы связи заняты, получает отказ и покидает СМО необслуженной. В СМО с очередью заявка, пришедшая в момент, когда все каналы заняты, не уходит, а становится в очередь и ожидает возможности быть обслуженной. На практике чаще встречаются (и имеют большее значение) СМО с очередью; недаром теория массового обслуживания имеет второе название: «теория очередей».
Нередко встречается так называемое обслуживание с приоритетом — некоторые заявки обслуживаются вне очереди. Приоритет может быть как абсолютным — когда заявка с более высоким приоритетом «вытесняет» из-под обслуживания заявку с низшим (например, пришедший в парикмахерскую клиент высокого ранга прогоняет с кресла обыкновенного клиента), так и
относительным — когда начатое обслуживание доводится до конца, а заявка с более высоким приоритетом имеет лишь право на лучшее место в очереди.
Существуют СМО с так называемым многофазовым обслуживанием, состоящим из нескольких последовательных этапов или «фаз» (например, покупатель, пришедший в магазин, должен сначала выбрать товар, затем оплатить его в кассе, затем получить на контроле).
Кроме этих признаков, СМО делятся на два класса: «открытые» и «замкнутые». В открытой СМО характеристики потока заявок не зависят от того, в каком состоянии сама СМО (сколько каналов занято). В замкнутой СМО — зависят. Например, если один рабочий обслуживает группу станков, время от времени требующих наладки, то интенсивность потока «требований» со стороны станков зависит от того, сколько их уже неисправно и ждет наладки. Это — пример замкнутой СMO.
19.Уравнения Колмогорова
•Уравнения Колмогорова - особого вида дифференциальные уравнения, в которых неизвестными функциями являются вероятности состояний.
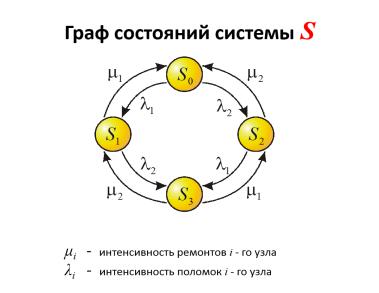
•Пусть техническое устройство S состоит из двух узлов и является Марковской системой с дискретными состояниями и непрерывным временем. Изменение состояний происходит под воздействием простейших потоков случайных событий.
•Возможные состояния системы можно перечислить:
S0 – оба узла исправны;
S1 - первый узел ремонтируется, второй исправен;
S2 - второй узел ремонтируется, первый исправен;
S3 – оба узла ремонтируются.
Вероятностью i-го состояния называется вероятность Pi (t) того, что в момент t система будет находиться в состоянии Si .

Имея в своем распоряжении размеченный граф состояний, можно с помощью уравнений Колмогорова найти все вероятности состояний Pi (t) как функции времени.
Правило составления дифференциальных уравнений Колмогорова
Влевой части каждого из уравнений стоит производная вероятности данного состояния.
Вправой части – сумма произведений вероятностей всех состояний, из которых идут стрелки в данное состояние, на интенсивности соответствующих потоков событий; минус суммарная интенсивность всех потоков, выводяших систему из данного состояния, умноженная на вероятность данного состояния.
Правило составления алгебраических уравнений Колмогорова
Влевой части каждого из уравнений стоит суммарная интенсивность всех потоков, выводящих систему из данного состояния, умноженная на вероятность данного состояния.
Вправой части – сумма произведений вероятностей всех состояний, из которых идут стрелки в данное состояние, на интенсивности соответствующих потоков событий.
20. Схема гибели и размножения.
Граф состояний для схемы гибели и размножения
|
1 |
2 |
3 |
k |
k 1 |
n |
S 0 |
S 1 |
S 2 |
|
S |
k |
S n |
|
1 |
2 |
3 |
k |
k 1 |
n |
Особенность этого графа в том, что все состояния системы можно вытянуть в одну цепочку, в которой каждое из внутренних состояний (S1,S2,...,Sn-1) связано прямой и обратной стрелкой с каждым из соседних состояний – правым и левым, а крайние состояния (S0,Sn) – только с одним соседним состоянием. Термин «схема гибели и размножения» ведет начало от биологических задач, где подобной схемой описывается изменение численности популяции.
Пользуясь графом состояний системы, составим и решим алгебраические уравнения Колмогорова для финальных вероятностей состояний.
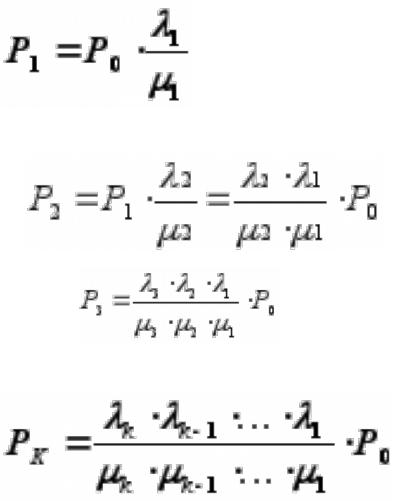
Для состояния S0: |
|
P0 λ1 = P1 μ1 |
|
Для состояния S1: |
|
P1 (μ1 + λ2)=P0 λ1 +P2 μ2 |
Или, с учетом уравнения для S0, для |
состояния S1 окончательно: |
|
P1 λ2 = P2 μ2 |
|
• Очевидно, для состояния S2 получим: |
|
P2 λ3 = P3 μ3 |
|
•Из уравнения для состояния S0 выразим P1 через P0:
•C учетом полученного для вероятности Р1, для вероятности Р2 будем иметь:
•
•Для Р3:
И вообще, для любого k (от 1 до n)
Таким образом, все вероятности состояний выражаются через P0.
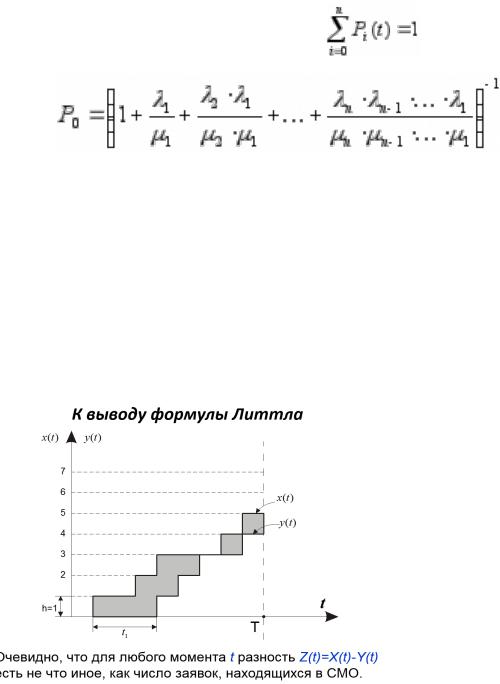
Подставив эти выражения в нормировочное условие |
и вынеся P0 за скобку, |
получим:
21. Формула Литтла.
Формула Литтла связывает среднее число заявок Lсист , находящихся в системе массового обслуживания, и среднее время пребывания заявки в системе Wсист.
Рассмотрим любую СМО и связанные с нею два потока событий, определяемых как: x(t) – число заявок, прибывших в СМО до момента t ;
y(t) – число заявок, покинувших СМО до момента t .
Рассмотрим очень большой промежуток времени Т и вычислим для него среднее число заявок, находящихся в СМО.
Среднее число заявок, находящихся в СМО будет равно интегралу от функции Z(t) на этом
промежутке, деленному на длину интервала Т: 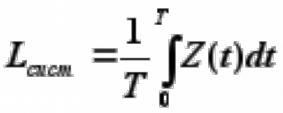
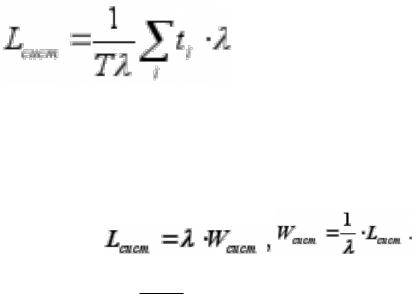
•Интеграл представляет собой не что иное,
представляет собой не что иное,
как площадь фигуры, заштрихованной на предыдущем рисунке, состоящей из прямоугольников высотой, равной единице и основанием ti.
Поэтому 
•Разделим и умножим правую часть выражения для Lсист на интенсивность λ:
Величина 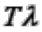 есть не что иное, как среднее число заявок, пришедших за время Т.
есть не что иное, как среднее число заявок, пришедших за время Т.
Если мы разделим сумму всех времен ti на среднее число заявок, то получим среднее время пребывания заявки в системе Wсист.
и есть формула Литтла - для любой СМО, при любом характере потока заявок, при любом распределении времени обслуживания, при любой дисциплине обслуживания среднее время пребывания заявки в системе равно среднему числу заявок в
системе, деленному на интенсивность потока заявок.
Таким же образом выводится вторая формула Литтла, связывающая среднее время пребывания
заявки в очереди Wоч и среднее число заявок в очереди Lоч: 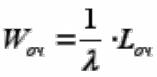
22. Задача Эрланга
Многоканальная СМО с отказами (задача Эрланга)
Задача ставится так: имеется n каналов, на которые поступает поток заявок с интенсивностью. Поток обслуживания одним каналом имеет интенсивность (величина, обратная среднему времени обслуживания tob).
Требуется найти финальные вероятности состояний СМО, а также характеристики ее эффективности:
•А – абсолютную пропускную способность, то есть среднее число заявок, обслуживаемых в единицу времени;
•Q – относительную пропускную способность, то есть среднюю долю обслуженных системой заявок;
•Ротк - вероятность отказа, то есть вероятность того, что заявка покинет СМО необслуженной;
• |
– среднее число занятых каналов. |
Решение. Состояние системы массового обслуживания S будем нумеровать по числу заявок, находящихся в системе (в данном случае оно совпадает с числом занятых каналов):
•S0 – в СМО нет ни одной заявки;
•S1 - в СМО находится одна заявка (один канал занят, остальные свободны);
•. . . . .
•Sk - в СМО находится k заявок (k каналов заняты, остальные свободны)
•Sn - в СМО находятся n заявок (все n каналов заняты).

Обозначим и будем называть величину ρ приведенной интенсивностью потока заявок. Ее смысл - среднее число заявок, приходящих за среднее время обслуживания одной заявки. Пользуясь этим обозначением, перепишем полученные формулы в виде
и будем называть величину ρ приведенной интенсивностью потока заявок. Ее смысл - среднее число заявок, приходящих за среднее время обслуживания одной заявки. Пользуясь этим обозначением, перепишем полученные формулы в виде
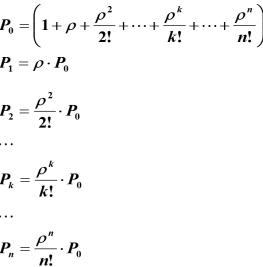
Полученные формулы для финальных вероятностей состояний анализируемой СМО называются формулами Эрланга - в честь основателя теории массового обслуживания.
По финальным вероятностям можно вычислить характеристики эффективности СМО.
23. Одноканальная СМО с неограниченной очередью
Пусть имеется одноканальная СМО с очередью, на которую не наложено никаких ограничений (ни по длине очереди, ни по времени ожидания). На эту СМО поступает поток заявок с интенсивностью λ; поток обслуживаний имеет интенсивность μ, обратную среднему времени обслуживания заявки tоб.
•Требуется найти финальные вероятности состояний СМО, а также характеристики ее эффективности:
Lсист- среднее число заявок в системе;
Wсист- среднее время пребывания заявки в системе;
Lоч- среднее число заявок в очереди;
Wоч- среднее время пребывания заявки в очереди;
Рзан- вероятность того, что канал занят (степень загрузки канала).
Что касается абсолютной пропускной способности А и относительной Q, то вычислять их нет надобности: в силу того, что очередь не ограничена, каждая заявка рано или поздно будет обслужена, поэтому А = λ , по той же причине Q=1.
Решение. Состояния системы будем нумеровать по числу заявок, находящихся в СМО:
•S0- канал свободен;
•S1- канал занят, очереди нет;
•S2- канал занят, одна заявка стоит в очереди; и т.д. Теоретически число состояний ничем не ограничено.

S 0 |
S 1 |
S 2 |
S k |
Граф состояний имеет вид:
Это - схема гибели и размножения, но с бесконечным числом состояний. По всем стрелкам слева направо поток заявок с интенсивностью λ переводит систему в состояния слева направо, а справа налево - поток обслуживаний с интенсивностью μ. Если ρ≥1, то канал с заявками не справляется, очередь растет до бесконечности. Если ρ <1, то задача вполне разрешима. Воспользуемся формулами для финальных вероятностей из схемы гибели и размножения, но для бесконечного числа состояний.
Подсчитаем финальные вероятности :
Ряд в формуле представляет собой геометрическую прогрессию со знаменателем ρ. Известно, что при ρ 1 ряд расходится; при ρ < 1 ряд сходится. Теперь предположим, что это условие
выполнено, и ρ < 1. Суммируя прогрессию в предыдущей формуле, получаем
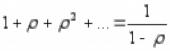 ,
, 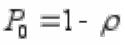
вероятности P1, P2,...,Pk,... найдутся по формулам: 
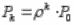
откуда с учетом того, что
найдем окончательно:
P1 (1 )
P2 2 (1 )
Pk k (1 )
Найдем среднее число заявок в СМО как дискретную случайную величину – число заявок в системе. Эта величина имеет возможные значения 0,1,2,...,k,... с вероятностями P0, P1,..., Pk,... Ее математическое ожидание Lсист определяется как

Найдем среднее число заявок в очереди Lоч. Будем рассуждать так: число заявок в очереди равно числу заявок в системе минус число заявок, находящихся под обслуживанием. Число заявок под обслуживанием может быть либо нулем (канал свободен), либо единицей (канал занят). Математическое ожидание такой случайной величины равно вероятности того, что канал занят (Рзан). Очевидно, Рзан равно
единице минус вероятность P0 того, что канал свободен: 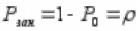

24. Многоканальная СМО с неограниченной очередью
Тот же подход, что и для одноканальной СМО, используется и для решения задачи для многоканальной СМО с неограниченной очередью. Состояния системы:
•S0- все каналы свободны;
•S1- один канал занят, очереди нет;
•S2- занято два канала;
• ....................................
•Sn- заняты все n каналов;
•Sn+1- заняты все n каналов, одна заявка стоит в очереди;
•...................................
•Sn+r- заняты все n каналов, r заявок стоит в очереди;
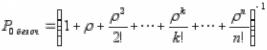 ,
,
 ,
,
Пусть условие ρ/n < 1 выполнено. Применяя формулы для схемы гибели и размножения, найдем финальные вероятности. В выражении для P0 будет стоять ряд членов, содержащих факториалы,
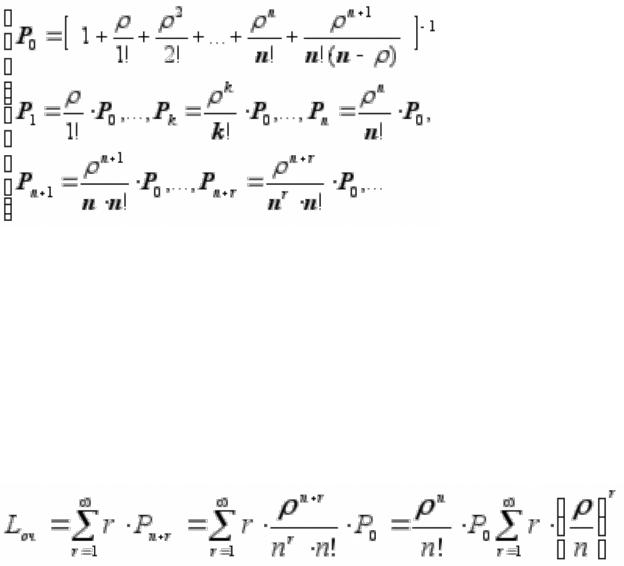
плюс сумма бесконечно убывающей геометрической прогрессии со знаменателем ρ/n . Суммируя ее, найдем
Теперь найдем характеристики эффективности СМО. Из них легче всего находится среднее число
занятых каналов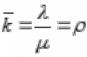
Найдем среднее число заявок в системе Lсист и среднее число заявок в очереди Lоч. Из них
легче вычислить второе по формуле 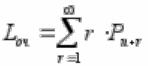 выполняя соответствующие преобразования по образцу одноканальной СМО с неограниченной очередью, получим:
выполняя соответствующие преобразования по образцу одноканальной СМО с неограниченной очередью, получим:
Пусть 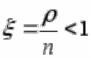 , тогда
, тогда 

Прибавляя к Lоч среднее число заявок под обслуживанием (оно же - среднее число занятых
каналов) |
, получаем: |
Деля, по формуле Литтла, выражение для Lсист и |
Lоч на λ , |
получим средние времена пребывания заявки в очереди и в системе: |
|
 И
И 
25. Управление ресурсами однопроцессорных систем оперативной обработки данных (алгоритмы SPT и RR)
Алгоритм SPT
В системах оперативной обработки в качестве основного критерия эффективности используется средне время обслуживания заявок. Нетрудно видеть, что в случае, когда времена решения задач априори известны, минимальное среднее время ответа дает алгоритм SPT (Shortest- processing-task-first), назначающий задачи на решение в порядке убывания времени решения ti, то

есть t1 t2 ... tL . При этом время ответа ui для задачи zi есть ui= tj, где tj- время ожидания , ti -
собственно время решения и среднее время ответа есть |
. |
|
|||
Покажем, |
что u* действительно |
минимальное |
значение среднего времени |
||
обслуживания. Для |
того |
чтобы показать, что u* действительно минимально среди u для |
всех |
||
перестановок, достаточно показать, что применение к произвольной перестановке ( 1,..., L) любой |
|||||
парной транспозиции, |
меняющей местами |
элементы k и l, |
где t l t k и l>k, может |
лишь |
|
уменьшить исходное значение u, соответствующее перестановке ( 1,..., L), |
где i - номер задачи, |
||||||
назначаемой |
на |
решение i-й по |
порядку, i=I,L. |
Действительно, |
пусть |
задачи |
с |
номерами k и l поменялись местами. Тогда для полученной перестановки среднее время обслуживания равно
Нетруд
но видеть, что
,
так как l > k, а t l t k. Следовательно, перемещение вперед задачи с меньшим временем решения приводит к уменьшению среднего времени обслуживания. В перестановке (1, ... ,L) при условии, что t1 ... 7tL, нельзя сделать ни одной такой улучшающей транспозиции, а потому u* есть
минимальное среднее время обслуживания и алгоритм SPT дает оптимальное решение рассматриваемой задачи.
Алгоритм RR
В реальных системах оперативной обработки априорная информация о временах решения задач, как правило, отсутствует. Чтобы воспользоваться принципами планирования на основе алгоритма SPT, в систему вводятся средства, обеспечивающие выявление коротких и длинных работ непосредственно в ходе вычислительного процесса.
Простейшее правило планирования работ, обеспечивающее выполнение указанного требования, задается алгоритмом циклического обслуживания, или, иначе, алгоритмом RR (Round– Robin). Работа алгоритма иллюстрируется рисунком 1.
Заявки на выполнение работ поступают с интенсивностью в очередь , откуда они выбираются и исполняются процессором Пр. Для обслуживания отдельной заявки отводится постоянный квант времени q, достаточный для

выполнения нескольких тысяч операций. Если работа была выполнена за время q, она покидает систему. В противном случае она вновь поступает в конец очереди и ожидает предоставления ей очередного кванта процессорного времени.
Оценим среднее время ожидания и пребывания работ в системе с циклическим планированием. Воспользуемся для этого аппаратом теории массового обслуживания. Для упрощения последующих выкладок предположим, что длительность кванта - не постоянная величина, а случайная, распределенная по экспоненциальному закону с тем же средним значением q. Примем также, что на вход системы поступает простейший поток с
интенсивностью работ в единицу времени, и с вероятностями или (1- ) работа не будет или соответственно будет завершена в текущем кванте. Из последнего предположения следует, что вероятность того, что работа будет выполнена точно за k квантов (не завершена за первые k- 1 квантов и завершена в k-том варианте), описывается геометрическим распределением
pk= k-1(1- ), k=1,2,...
со средним
Таким образом, если известны средняя трудоемкость работ
 и длительность
и длительность q
q кванта, то
кванта, то
|
|
|
|
|
|
|
|
среднее количество |
|
квантов, с одной стороны, равно |
/ |
q |
, а с другой – полученному выше |
||
|
|
|
|
|
|
|
|
выражению, то есть |
|
|
|
|
|
|
Определим среднее время ответа для работы J, требующей ровно единиц времени обработки. Пусть m – наименьшее целое, при котором mq (то есть m – число квантов,
достаточное для обслуживания заявки). Рассмотрим состояние системы на момент поступления работы J. При поступлении работы J в системе в среднем находится W1 других работ. Значение N1 определяется как среднее число заявок в системе с бесприоритетным обслуживанием, на вход которой заявки поступают с интенсивностью
n
(с учетом интенсивности поступления заявок на дообслуживание в последующих тактах) и обслуживаются по экспоненциальному закону со средним q. Для определения W1 требуется найти распределение вероятностей {pk} того, что в очереди будет ровно k заявок. Тогда
W1= kpk.
Для определения pk составим систему дифференциальных уравнений Колмогорова с помощью графа переходов (рисунок 2).
( q)
Вместо этой хрени лучше , помоему Это : Принципиальное отличие потоковых машин состоит в том, что команды выполняются здесь не в порядке их следования в тексте программы, а по мере готовности их операндов. Как только будут вычислены операнды команды, она может захватывать свободное операционное устройство и выполнять предписанную ей операцию. В этом случае последовательность, в которой выполняются команды, уже не является детерминированной.
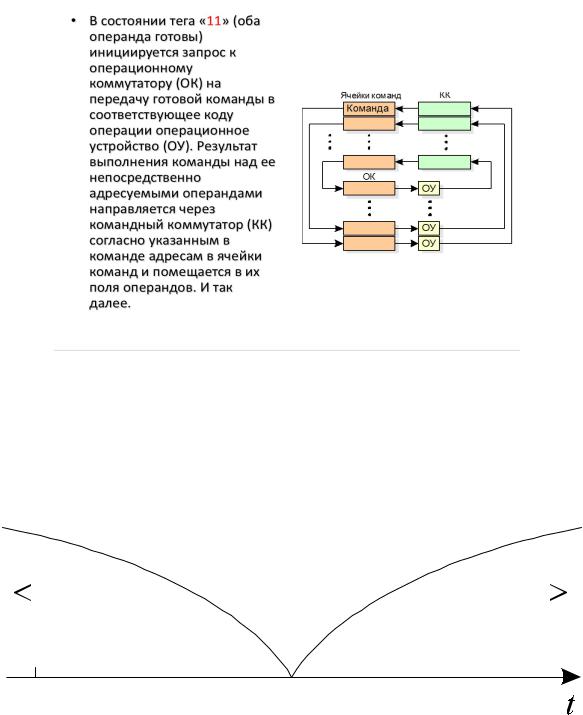
Потоковая программа размещается в массиве ячеек команд (рис).
Схема работы процессора с управлением потоком данных
Команда наряду с кодом операции содержит поля, куда заносятся готовые операнды, и поле, содержащее адреса команд, в которые должен быть направлен в качестве операнда результат операции. Кроме того, каждой команде поставлен в соответствие двухразрядный тег (располагаемый в управляющем устройстве), разряды которого устанавливаются в «1» при занесении в тело команды соответствующих операндов. В состоянии тега «11» (оба операнда готовы) инициируется запрос коперационному коммутатору (ОК) на передачу готовой команды в соответствующее коду операции операционное устройство (ОУ).
Результат выполнения команды над ее непосредственно адресуемыми операндами направляется через командный коммутатор (КК) согласно указанным в команде адресам в ячейки команд и помещается в поля операндов. Далее указанная процедура циклически повторяется, причем управление этим процессом полностью децентрализовано и не нуждается в счетчике команд.
Управление ресурсами вычислительных систем. Алгоритм SPT
В системах обработки данных в качестве основного критерия эффективности используется среднее время обслуживания заявок.
При оперативной обработке вычислительных задач невозможно проводить одновременно и их сортировку. Задачи с различной длительностью решения поступают на процессор в случайном порядке. В связи с этим невозможно использоватьрежим SPT (Shortest-Processing-Task-first), назначающий задачи на решение в порядке убывания времени их решения.
В реальных системах оперативной обработки информация о времени решения задач, как правило, отсутствует. Чтобы воспользоваться принципами планирования на основе алгоритма SPT, в систему вводятся средства, которые выявляют короткие и длинные работы непосредственно в ходе вычислительного процесса.
Управление ресурсами вычислительных систем, алгоритм RR(Round-Robin)?
Алгоритм RR(Round-Robin - алгоритм циклического обслуживания).
Заявки на выполнение работ поступают с интенсивностью λ в очередь О, откуда они выбираются и исполняются процессором CPU. Для обслуживания отдельной заявки отводится постоянный квант времени q, достаточный для выполнения нескольких тысяч операций. Если работа была выполнена за время q, она покидает систему. В противном случае она вновь поступает в конец очереди и ожидает предоставления ей очередного кванта процессорного времени.
26. Планирование вычислительного процесса (алгоритмы LPT и Макнотона)
Алгоритм Макнотона
Рассмотрим систему с n идентичными процессорами, с помощью которой необходимо решить L независимых задач; каждая задача решается одним процессором в течение времени ti , где i = 1 , ., L. Требуется найти алгоритм, который для каждого данного пакета (набора) задач строил бы расписание решения задач на процессорах системы, обеспечивающее минимально возможное время решения. При этом достигается максимально возможная производительность системы.
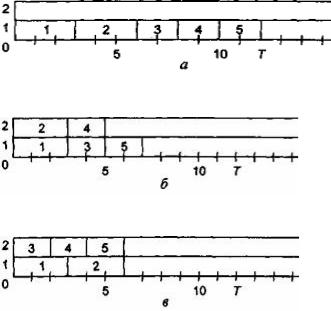
Пример: в двухпроцессорной системе и при наборе задач с временем их решения 3; 3; 2; 2; 2 возможны различные варианты назначения задач на решение.
a)работает один процессор
b)работают два процессора
c)алгоритм Макнотона
Рис Варианты расписаний для двухпроцессорной системы
Минимальное общее время решения задач достигается в варианте в), для которого время решения пакета задач совпадает с соответствующим оптимальным значением T = Tопт = Q и в данном случае равно величине
Q = max {max ti, (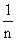 )·∑ti}.
)·∑ti}.
Величина Q является нижней границей для оптимального значения Tопт.
Длина любого расписания T ≥max ti — максимального из времен решения задач пакета, в то же время T ≥ (
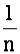 ·∑ti) длины расписания в том случае, когда до момента завершения решения последней из задач пакета ни один процессор не простаивает, т.е. все процессоры имеют 100 %-ную загруженность.
·∑ti) длины расписания в том случае, когда до момента завершения решения последней из задач пакета ни один процессор не простаивает, т.е. все процессоры имеют 100 %-ную загруженность.
В общем случае даже при n =2 задача поиска оптимального значения T очень сложная задача, т.к. все известные алгоритмы ее решения имеют трудоемкость, экспоненциально зависящую от L.
Однако, если допустить возможность прерывания решения задач пакета до завершения их обслуживания, то могут быть предложены алгоритмы, приводящие к расписанию оптимальной длины Tопт.
При этом считается, что после прерывания решение задачи может быть возобновлено с точки прерывания на любом процессоре, не обязательно на том, на котором задача решалась первоначально.
Число прерываний должно быть по возможности меньшим, так как с каждым актом прерывания связаны потери машинного времени на загрузку-выгрузку задач из оперативной памяти.
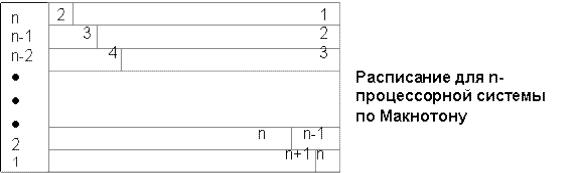
Рассмотрим алгоритм Макнотона построения оптимального по длине расписания с не более чем n- 1 прерываниями.
Алгоритм Макнотона заключается в предварительном упорядочении задач по убыванию времени решения и назначении задач последовательно по порядку номеров одну за другой на процессоры системы справа налево от уровня Q.
Примем: n= 2, L = 4, время решения задач: 5; 4; 3; 2. (N задачи 1;2;3;4)
Тогда Q = max {5, ½ • (5 + 4 + 3 + 2)} = 7;
расписание, в соответствии с алгоритмом Макнотона, имеет вид, таблицы.
2-й процессор |
2 |
|
1 |
1-й процессор |
4 |
3 |
2 |
В данном примере число прерываний=1 (прерывание в задаче N=2, со временем=4 ).
Покажем, что n-1 (максимальное число прерываний для расписания, полученного в соответствии с алгоритмом Макнотона)является достижимой границей числа прерываний.
Для доказательства этого построим такой пример пакета задач, для которого алгоритм Макнотона дает расписание с числом прерываний n-1.
Пусть: L = n + 1 и ti = n, i =1,…, n + 1.
Тогда: Q = max {n ,(1/n)·(n + 1)n} = n + 1, а расписание, получаемое в соответствии с алгоритмом Макнотона, имеет вид:
Число прерываний в этом случае, как видно, равно (n –1), что и требовалось показать.
Покажем, что любое оптимальное расписание для этого пакета задач также имеет не менее n -1 прерываний. Очевидно, что в любом оптимальном расписании ни один процессор не простаивает на интервале [0, n + 1]. Предположим, что сущес-твует некоторое оптимальное расписание с числом прерываний, меньшим n -1. Тогда по крайней мере два процессора ( для определенности возьмем Рk и Pu) обслуживают заявки без прерываний. Очевидно, эти процессоры обслуживают некоторые задачи Zik и Ziu в интервале [0, n] без прерываний,
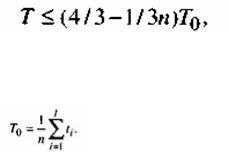
(если решение этих задач начинается позже момента времени t = 0, значит, до этого момента на этих процессорах решались некоторые другие задачи, решение которых прерывается в моменты начала решения задач Zik и Ziu). Найдутся моменты времени t, t', такие, что n ≤ t < t’ ≤ n + 1, и в интервале [t, t’] хотя бы один процессор простаивает, а потому рассматриваемое решение не может быть оптимальным.
Так как мы пришли к противоречию, делаем вывод о том, что предположение о числе прерываний, меньшем n-1, в оптимальном расписании ложно.
Алгоритм LPT
Рассмотрим систему, содержащую n идентичных процессоров, на которой необходимо решить без прерываний набор из L независимых задач с временами решения ti ,
где i = 1 , ., L. Получение расписания с минимальным временем решения и в этом случае является трудной задачей. Один из наиболее эффективных и нетрудоемких алгоритмов организации таких вычислений
— алгоритм LPT
(Longest-ProcessingTaskfirst — самая длинная задача решается первой),
являющийся частным случаем алгоритма критического пути для независимых задач.
Суть этого алгоритма - в назначении задач в порядке убывания времени решения на освобождающиеся процессоры. Сотрудником фирмы BellLaboratories, США, Грэхемом в 1967 г. был получен следующий результат: при использовании алгоритма LPT для распределения любого пакета П независимых задач без прерываний, в системе с n идентичными процессорами справедливо:
где Т — время решения пакета П при распределении задач алгоритмом LPT;
tо — длина оптимального расписания.
Приведенная оценка является наилучшей.
За счет чего увеличивается производительность мультипроцессорных систем по сравнению с однопроцессорными системами?
Вычислительные системы, содержащие несколько процессоров, связанных между собой и с общим для них комплектом внешних устройств, называются мультипроцессорными системами (МПС).
Производительность МПС увеличивается по сравнению с однопроцессорной системой за счет того, что мультипроцессорная организация создает возможность для одновременной обработки нескольких задач или параллельной обработки различных частей одной задачи.
27. Производительность МПС с общей и индивидуальной памятью
В МПС с общей памятью каждый из процессоров имеет доступ к любому модулю памяти, которые могут функционировать независимо друг от друга и в каждый момент времени обеспечивать одновременные обращения в целях записи или чтения слов информации, число которых определяется числом модулей.