

Перспективы развития бд и субд
Современные базы данных являются основой многочисленных информационных систем. Информация, накопленная в них, является чрезвычайно ценным материалом, и в настоящий момент широко распространяются методы обработки баз данных с точки зрения извлечения из них дополнительных знаний, методов, которые связаны с обобщением и различными дополнительными способами обработки данных. Базы данных в данной концепции выступают как хранилища информации, это направление называется "Хранилища данных" (Data Warehouse).
Для работы с "Хранилищами данных" наиболее значимым становится так называемый интеллектуальный анализ данных (ИАД), или data mining, — это процесс выявления значимых корреляций, образцов и тенденций в больших объемах данных.
Вопрос20! Многомерная модель
В бизнес-приложениях наибольший интерес представляет интеграция методов интеллектуального анализа данных с технологией оперативной аналитической обработки данных (On-Line Analytical Processing, OLAP). OLAP использует многомерное представление агрегированных данных для быстрого доступа к важной информации и дальнейшего ее анализа.
Однако хоть идеи многомерной модели возникли одновременно с реляционной, но в ту пору практической реализации таких моделей не было. И лишь в 90-х годах ХХ века к ним стал проявляться интерес. Это было вызвано появлением статьи Э. Кодда, в которой он сформулировал 12 требований к системам класса OLAP (Online Analytical Processing – оперативная аналитическая обработка), связанных с возможностью представления и обработки многомерных массивов.
Информация в многомерной модели представляется в виде многомерных массивов, называемых гиперкубами. В одной базе данных, построенной на многомерной модели, может храниться множество таких кубов, на основе которых можно проводить совместный анализ показателей. Конечный пользователь в качестве внешней модели данных получает для анализа определенные срезы или проекции кубов, представляемые в виде обычных двумерных таблиц или графиков.
Основными понятиями для многомерной модели являются: агрегируемость, историчность, прогнозируемость.
Агрегируемость данных означает рассмотрение и возможность анализа данных на разных уровнях обобщения: для пользователя, аналитика, руководителя. Историчность данных обозначает привязку их ко времени и высокий уровень неизменности (статичности) данных и их взаимосвязей. Временная привязка позволяет выполнять запросы, имеющие значения даты и времени. А статичность – использовать специализированные методы загрузки, хранения, выборки. Прогнозируемость данных предполагает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных – это, прежде всего, многомерное логическое представление структуры данных при их описании и в операциях манипулирования ими, а не многомерность их визуализации. По сравнению с реляционной моделью многомерная организация данных обладает более высокой информативностью. Для того чтобы убедиться в этом, рассмотрим многомерное представление данных и сопоставим его с реляционным (рис. 24-25).
Выпуск продуктов цехом по кварталам года
|
Наименование продукта |
Квартал |
Выпуск |
|
Сыр |
I |
20 |
|
Сыр |
II |
30 |
|
Сыр |
III |
25 |
|
Сыр |
IV |
15 |
|
Творог |
I |
20 |
|
Творог |
II |
25 |
|
Масло |
III |
15 |
а) Реляционное представление
Выпуск продуктов цехом по кварталам
|
Наименование продукта |
Выпуск по кварталам | |||
|
I |
II |
III |
IV | |
|
Сыр |
20 |
30 |
25 |
15 |
|
Творог |
20 |
25 |
|
|
|
Масло |
|
|
15 |
|
б) Многомерное представление (срез)
Рис. 24. Реляционное и многомерное представление данных
В примере на рис. 14 каждое значение выпуска однозначно определяется комбинацией временного измерения (квартал), названием выпускающего цеха и наименованием товара.
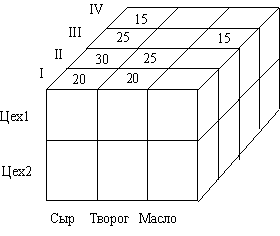
Рис. 25.Пример трехмерной модели
В современных многомерных системах используется обычно два варианта (схемы) организации данных: гиперкубическая и поликубическая. В гиперкубическойсхеме все показатели определяются одним и тем же набором измерений и даже при наличии нескольких гиперкубов в базе все они имеют одинаковую размерность и совпадающие измерения. Приполикубическойорганизации в базе может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером поликубической системы является серверOracleExpressServer.
Для многомерной модели применяются специальные операции: Срез, Сечение, Вращение, Агрегация, Детализация.
Срез– это подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Так, в нашем примере можно ограничить значение наименования продукта продуктом Сыр. В этом случае получим срез в виде двумерной таблицы выпуска этого продукта по кварталам года цехами предприятия (рис. 26).
Выпуск сыров цехами по кварталам года
|
Номер цеха |
Квартал I |
Квартал II |
Квартал III |
Квартал IV |
|
Цех 1 |
20 |
30 |
25 |
15 |
|
Цех 2 |
10 |
25 |
30 |
35 |
Рис. 26.Срез многомерной модели
Вращениеизменяет порядок измерений при визуальном представлении данных. Вращение применяется обычно при двумерном представлении данных. Так, в примере на рис. 13 вращение приведет к изменению вида таблицы, так, что по оси ОХ будет Наименование продукта, а по осиOY– Выпуск по кварталам (таблица 2).
Таблица 2
|
Кварталы |
Наименование продукта | ||
|
Сыр |
Творог |
Масло | |
|
I |
20 |
20 |
- |
|
II |
30 |
25 |
- |
|
III |
25 |
- |
15 |
|
IV |
15 |
- |
- |
Операцию вращения можно обобщить и на многомерный случай для изменения порядка следования измерений, например, перестановки местами двух произвольных измерений.
АгрегацияиДетализацияозначают соответственно переход к более общему и более детальному представлению данных. Для понимания сути операции агрегации положим, что имеется гиперкуб, в котором кроме измерений, приведенных на рис. 24, имеются еще подразделение Участок. В этом случае в гиперкубе будет иерархияЦех – Участок.Допустим, в гиперекубе определено, сколько произведено продукции каждым из участков цеха 1. Тогда, поднимаясь на более высокую ступень иерархии, с помощью операцииАгрегацияможно определить выпуск и для всего цеха 1.
Достоинством многомерной модели является удобство и эффективность анализа больших объемов данных, имеющих временную связь, а также быстрота реализации сложных нерегламентированных запросов. Недостаток этой модели в громоздкости в случае ее использования для решения стандартных задач оперативной обработки. Она, по сравнению с реляционными, не эффективно использует память, так как в ней резервируется место для всех значений, даже если некоторые из них будут отсутствовать (рис. 25). Обычно многомерную модель применяется, когда объем базы не велик и гиперкуб использует стабильный по времени набор измерений.
Многомерные модели поддерживают следующие системы: Essbase(фирмаArborSoftware),MediaMulti-matrix(фирмаSpeedware),OracleExpressServer(фирмаOracle),Cache(фирмаInterSystems).
Системы OLAP обеспечивают аналитикам и руководителям быстрый последовательный интерактивный доступ к внутренней структуре данных и возможность преобразования исходных данных с тем, чтобы они позволяли отразить структуру системы нужным для пользователя способом. Кроме того, OLAP-системы позволяют просматривать данные и выявлять имеющиеся в них закономерности либо визуально, либо простейшими методами (такими как линейная регрессия), а включение в их арсенал нейросетевых методов обеспечивает существенное расширение аналитических возможностей.