

Тема 6. Методи аналізу рядів розподілу
План вивчення теми
6.1.Поняття та основні складові рядів розподілу. Види рядів розподілу, основні методи їх побудови
6.2.Характеристики центру розподілу і порядкові статистики (середня, мода, медіана, їх взаємозв’язок; квантилі розподілу - квартилі, квінтилі, децилі, перцентилі) та їх роль в аналізі закономірностей розподілу
6.3.Характеристики вимірювання варіації ознак - абсолютні та відносні міри варіації (розмах варіації, середнє лінійне та середнє квадратичне відхилення, коефіцієнти варіації). Варіація альтернативної ознаки
6.4.Характеристики форми розподілу: коефіцієнти асиметрії та ексцесу
6.5.Показники диференціації та концентрації
Після вивчення теми студенти повинні:
знати: в чому полягають аналітичні функції рядів розподілу, основні їх види та методи побудови; методологічні аспекти вимірювання закономірностей розподілу: центру розподілу, варіації ознак, форми розподілу й диференціації та концентрації;
уміти: аналізувати закономірності розподілу, оцінювати, відповідно до мети дослідження, ступінь варіації ознак і однорідність сукупності, симетричність і рівномірність розподілу, оцінювати інтенсивність структурних зрушень; виявляти закони розподілу тощо.
Бібліографічний список: [7 – 10; 17 - 22 ]
6.1. Поняття та основні складові рядів розподілу. Види рядів розподілу, основні методи їх побудови
Статистичний ряд розподілу – упорядкований розподіл одиниць сукупності, що вивчається, на групи за певною варіативною ознакою. Наприклад, розподіл працівників підприємства за рівнем кваліфікації. В даному разі варіативною ознакою буде кваліфікація працівника (якісна ознака). Якщо вивчати обсяги виготовленої продукції або проданих товарів, то варіативною ознакою буде кількість продукції чи товарів або їх вартість (кількісна ознака). Статистичний ряд розподілу характеризує склад явища, що вивчається, дозволяє судити про однорідність чи неоднорідність сукупності, закономірності розподілу, межі варіації одиниць сукупності тощо.
Ряди розподілу, які побудовані за атрибутивними ознаками, називаються атрибутивними. В таких рядах порядок розташування елементів сукупності,
що вивчається, не має значення. Наприклад, розподіл працівників підприємства за професією. Ряди розподілу, які побудовані за кількісними ознаками в порядку зростання чи зниження їх значень, називаються варіаційними.
64
Ряд розподілу складається з двох елементів: варіанти та частоти. Числові значення кількісної ознаки (варіанти) можуть бути додатними і від’ємними, абсолютними і відносними. Наприклад, якщо досліджується ефективність діяльності фірми чи підприємства, то додатна величина характеризує поліпшення, а від’ємна – погіршення роботи; якщо досліджуються результати економічної діяльності фірми чи підприємства, то додатна величина характеризує прибутки, а від’ємна – збитки.
Частоти – це числа, що показують, скільки разів зустрічається та чи інша варіанта в ряді розподілу (якщо мова йде про дискретну величину), або скільки варіант потрапляють в певний інтервал (якщо мова йде про неперервну величину). Підсумок всіх частот складає обсяг сукупності і визначає кількість елементів всієї сукупності, що вивчається.
Іноді у варіаційних рядах замість частот використовують частки – це частоти, подані у вигляді відносних величин (як частина одиниці або у відсотках). Підсумок часток відповідно дорівнює одиниці або 100 %. Заміна частот частками дозволяє порівнювати варіаційні ряди з різним обсягом сукупностей.
Варіаційні ряди залежно від характеру варіації поділяються на дискретні та інтервальні. Дискретні варіаційні ряди ґрунтуються на ознаках, виражених дискретними величинами. Наприклад, розподіл сімей за числом дітей у сім’ї.
Інтервальні варіаційні ряди ґрунтуються на ознаках, виражених неперервними величинами або дискретними величинами, значення яких варіюють у досить широких межах і можуть бути наведені у вигляді інтервалів. Наприклад, такі ознаки, як вартість товару або його вагу, зручніше наводити інтервальними варіаційними рядами.
Для графічного зображення рядів розподілу застосовуються такі діаграми, як полігон, гістограма та кумулятивний полігон.
Якщо первинний ряд містить велику кількість варіант, то його безпосередній розгляд не дає уявлення про розподіл одиниць за значеннями ознаки в сукупності. Тому першим кроком в упорядкуванні первинного ряду є його ранжирування, тобто розподіл всіх варіант в порядку зростання або зниження числового значення ознаки.
Варіаційний ряд розподілу прийнято оформляти у вигляді таблиці, що складається з двох граф чи двох рядків; в одній наведені варіанти (ліва графа, якщо таблиця має вертикальне розташування, і верхній рядок, якщо таблиця розташовується горизонтально), в іншій наводяться частоти або частки.
Побудова дискретного варіаційного ряду з невеликим числом варіант не викликає ніяких ускладнень. Наприклад, розподіл студентів академічної групи за оцінкою, яку вони одержали на іспитах з певної дисципліни (табл. 6.1).
Для побудови ряду розподілу неперервних величин, або дискретних, наведених у вигляді інтервалів, необхідно виявити оптимальну кількість груп (інтервалів), на які слід розтинати сукупність, що вивчається.
Питання щодо кількості груп і розміру інтервалів слід вирішувати з урахуванням багатьох обставин, перш за все залежно від мети дослідження, значення ознаки, що вивчається та таке інше. Чим більше створено груп, тим менший розмір інтервалу, і навпаки.
65

Таблиця 6.1
Розподіл студентів групи ЕП-06-3 за результатами здачі іспиту з дисципліни “Статистика” (дані умовні)
Оцінка (х) |
2 |
3 |
4 |
5 |
Разом |
|
|
|
|
|
|
|
|
Кількість |
4 |
6 |
14 |
6 |
30 |
|
студентів (f) |
||||||
|
|
|
|
|
Кількість груп залежить від обсягу сукупності, що вивчається, і ступеню коливання групувальної ознаки. Якщо обсяг сукупності невеликий, то не можна створювати велику кількість груп, бо групи будуть містити малу кількість елементів. Але нове, прогресивне, поки воно ще не стало масовим, завжди проявляється в малому числі фактів, і статистика повинна враховувати ці випадки. Таким чином, у процесі вирішення питання щодо чисельності груп треба керуватися знанням суті явища, що вивчається. На кількість груп суттєво впливає ступінь коливання групувальної ознаки: чим він більше, тим більше груп треба створювати. Приклад інтервального ряду розподілу наведено в табл. 6.2.
Таблиця 6.2
Розподіл книжок за їх ціною у книжковому відділі магазину на 01.01.2008 (дані умовні)
Ціна книги, |
6,00 – |
54,80 |
– |
103,60 – |
152,40 – |
201,20 – |
Разом |
|
грн. (х) |
54,80 |
103,60 |
152,40 |
201,20 |
250,00 |
|||
|
||||||||
Кількість |
248 |
115 |
|
96 |
51 |
30 |
540 |
|
книг, шт. ( f) |
|
|||||||
|
|
|
|
|
|
|
||
Для дискретних рядів розподілу застосовується графік у вигляді полігону.
Наприклад, розподіл робітників складального цеху за кваліфікацією, наведений нижче в таблиці, можна подати у вигляді полігону розподілу – лінійна діаграма.
Розподіл робітників складального цеху за кваліфікацією
Розряд |
І |
ІІ |
ІІІ |
ІV |
V |
VІ |
Разом |
|
|
|
|
|
|
|
|
|
|
Кількість |
2 |
3 |
7 |
8 |
5 |
3 |
28 |
|
робітників |
||||||||
|
|
|
|
|
|
|
66

Для графічного зображення інтервальних рядів розподілу застосовується гістограма, вигляд якої наведено на рис. 6.1. Наприклад, розподіл товару за ціною, , наведений нижче в таблиці, можна подати у вигляді гістограми.
Ціна дитячого |
До 25 |
25 – 50 |
50 – 75 |
75 і більше |
Разом |
|
одягу, грн. |
||||||
|
|
|
|
|
||
Кількість товару, |
20 |
9 |
6 |
5 |
40 |
|
шт. |
||||||
|
|
|
|
|
Кількість товару, f
20 |
20 |
|
|
|
|
|
|
|
|
|
|
15 |
|
|
|
|
|
10 |
|
9 |
|
|
|
|
|
6 |
|
|
|
|
|
|
5 |
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
0 |
25 |
50 |
75 |
100 , |
грн. |
|
|
Ціна товару, грн |
|
|
|
Рис. 6.1. Розподіл дитячого одягу у крамниці за його ціною
Для побудови кумулятивного полігону використовуються суми накопичених частот (або суми накопичених часток, якщо в ряді розподілу замість частот використовуються частки). У цьому разі за віссю абсцис відкладаються значення ознаки, а за віссю ординат – кумулятивні частоти. Кумулятивні частоти (частки) одержуються накопиченим підсумком, тобто до попереднього значення додається наступне і значення одержаної суми відкладається на осі ординат. Максимальне значення характеризує обсяг сукупності або дорівнює одиниці у разі застосування накопичених часток.
Кумулятивний полігон можна побудувати у вигляді ламаної лінії (для дискретної ознаки) або у вигляді ступінчатої гістограми (для неперервної ознаки).
Для побудови кумулятивного полігону, наприклад, для дискретного ряду розподілу, наведеного в табл. 6.1, спочатку слід обчислити суму накопичених частот. Цей показник обчислюється за формулою:
i |
|
|
Si = fi 1 |
fi , |
(6.1) |
i 1 |
|
|
де Si – сума накопичених частот до і-ї ознаки включно; fi – значення частоти і-ї ознаки.
Визначивши суми накопичених частот для кожної ознаки, табл. 6.1 матиме такий вигляд:
67

Таблиця 6.3
Розподіл студентів групи ЕП-06-3 за результатами здачі іспиту з дисципліни “Статистика” (дані умовні)
Оцінка (х) |
2 |
3 |
4 |
5 |
Разом |
|
|
|
|
|
|
|
|
Кількість студентів (f) |
4 |
6 |
14 |
6 |
30 |
|
|
|
|
|
|
|
|
Сума накопичених |
4 |
10 |
24 |
30 |
× |
|
частот (Si) |
||||||
|
|
|
|
|
Графічне зображення ряду розподілу побудованого за накопиченими частотами матиме вигляд кумулятивного полігону. Аналогічно будується кумулятивний полігон для інтервального ряду розподілу. У даному разі табл. 6.2 матиме вигляд, наведений у табл. 6.4. і графічно - на рис. 6.2.
Таблиця 6.4
Розподіл книжок за їх ціною у книжковому відділі магазину на 01.01.2008 (дані умовні)
Ціна книги, грн. (х) |
6,00 – |
54,80 |
– |
103,60 – |
152,40 – |
201,20 – |
Разом |
|
54,80 |
103,60 |
152,40 |
201,20 |
250,00 |
||||
|
|
|||||||
Кількість книг, шт. |
248 |
115 |
|
96 |
51 |
30 |
540 |
|
( f) |
|
|||||||
|
|
|
|
|
|
|
||
Сума накопичених |
248 |
363 |
|
459 |
510 |
540 |
× |
|
частот (Si) |
|
|||||||
|
|
|
|
|
|
|
||
Накопичена частота
Sі540 510 480 450 420 390 360 330 300 270 240 210 180 150 120 90 60 30 0
6 |
54,80 |
103,60 |
152,40 |
201,20 |
250,00 |
х |
Ціна книги, грн.
Рис. 6.2. Кумулятивний полігон, побудований за розподілом книжок за їх ціною у книжковому відділі магазину на 01.01.2008
68
На рис. 6.2 кумулятивний полігон виділено жирною лінією. Як видно, у даному разі кумулятивний полігон починається не з центру системи координат, а з точки на осі абсцис, яка відповідає нижній межі першого інтервалу ряду розподілу.
Основні принципи та методика побудови рядів розподілу наведено у підрозділі 3.3. «Методологічні засади побудови статистичних групувань» теми 3.
6.2. Характеристики центру розподілу і порядкові статистики (середня, мода, медіана, їх взаємозв’язок; квантилі розподілу - квартилі, квінтилі, децилі, перцентилі) та їх роль в аналізі закономірностей розподілу
Виявлення закономірностей зміни частот залежно від зміни варіативної ознаки, що покладена в основу групування і є основою аналізу варіаційних рядів розподілу. При такому аналізі найчастіше використовують такі групи показників:
характеристики центру розподілу;
характеристики розміру варіації;
характеристики форми розподілу.
Центром розподілу називається значення варіативної ознаки, навколо якого групуються інші варіанти. До характеристик центру розподілу належать
середня, мода, медіана, чверть (квартиль) і десята частина (дециль).
Види та методика визначення середньої величини детально розглянуто у попередній темі. Для повнішого розкриття властивостей ряду розподілу визначають моду Мо, медіану Ме, квартилі Qu1, Qu2, Qu3 та децилі – від D1 до D9.
Мода (Мо) – значення варіанти, яке найчастіше повторюється в ряду розподілу. У дискретних рядах моду легко відшукати візуально, безпосередньо за найбільшим значенням частоти або частки.
В інтервальному ряді за тим самим принципом визначається модальний інтервал, тобто інтервал, частота якого має найбільше значення. Якщо треба більш точно встановити модальний рівень, його обчислюють за формулою:
Mo x Mo |
hMo |
|
( f |
Mo f Mo 1 ) |
|
, |
|
( f Mo f Mo 1 ) ( f Mo f |
Mo 1 ) |
||||||
|
|
|
|
||||
де Мо – мода |
|
|
|
|
|
|
|
х Мо – нижня межа модального інтервалу h Mo – ширина модального інтервалу
f Mo – частота модального інтервалу
f Mo – 1 – частота попереднього (перед модального) інтервалу f Mo + 1 – частота наступного (після модального) інтервалу.
Слід зауважити, що ця формула використовується для інтервальних варіаційних рядів з рівними інтервалами. Визначення моди в ряді розподілу із нерівними інтервалами має свої особливості.
Для визначення моди за інтервальним варіаційним рядом з нерівними інтервалами в аналітичному вираженні перегруповують вихідний варіаційний ряд на ряд з рівними інтервалами або замість частот використовують відносні
69
частоти. Для визначення моди графічним способом будують гістограму відносних частот. Основу прямокутників становлять розміри інтервалів, а висоту – відношення відповідної частоти до ширини інтервалу. Для кожного інтервалу визначається відносна частота за формулою:
w i fi , h i
де wi – відносна частота i–го інтервалу; fi – частота i–го інтервалу;
hi – ширина i–го інтервалу.
Принцип визначення моди лишається тим самим, що й для інтервального варіаційного ряду з рівними інтервалами.
Графічним методом мода визначається за допомогою гістограми. Графічним методом мода визначається так: на гістограмі (рис. 6.3) беремо
прямокутник з найбільшою висотою, лівий верхній кут цього прямокутника (точка B) з’єднуємо з лівим верхнім кутом прямокутника, розташованого праворуч (точка D), а верхній правий кут найбільшого прямокутника (точка С) з’єднуємо з правим верхнім кутом прямокутника, розташованого ліворуч (точка А); з перетину прямих АС і BD (точка М) на вісь абсцис опускаємо перпендикуляр, який і визначить значення моди.
f
50
40 |
В |
С |
|
|
|
30 |
|
M |
|
|
|
А |
////// |
|
|
|
|
20 |
|
|
|
|
|
D |
|
D |
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
Х |
50 |
100 |
Мо 150 |
200 |
250 |
Рис. 6.3. Визначення моди графічним методом
Медіана (Ме) – варіанта, що ділить упорядкований варіаційний ряд на дві, рівні за обсягом частини. Наприклад, якщо в ряді розподілу робітників за віком Ме = 30, це означає, що половина робітників мають вік менше 30 років, половина – старші за цей вік.
Визначаючи медіану, використовують кумулятивні частоти Sfi або частки Sdi. У дискретному ряді медіанним буде значення ознаки, кумулятивна частота якого перевищує половину сукупності, тобто Sfi ≥ 0,5 fi (для кумулятивної частки Sdi ≥ 0,5). Кумулятивні частоти визначаються доданням наступного значення частоти до суми значень попередніх частот. При цьому не має значення які інтервали у варіаційному ряді розподілу: рівні чи нерівні.
70

В інтервальному ряді за цим принципом визначають медіанний інтервал. Значення медіани, як і значення моди, обчислюють за інтерполяційною
формулою:
Me x Me |
hMe |
(0,5 f i |
S f Me 1 |
) |
, |
f Me |
|
||||
|
|
|
|
||
де Ме – медіана |
|
|
|
|
|
хМе – нижня межа медіанного інтервалу hMe – ширина медіанного інтервалу 0,5 f i – половина сукупності
S fMe - 1 – сума накопичених частот до медіанного інтервалу f Ме – частота медіанного інтервалу.
Медіану можна визначити графічним способом, використовуючи для цього кумулятивний полігон. Медіана графічним способом визначається так: для визначення медіани графічним методом використовують графік, побудований на основі накопичених частот або часток. Цей графік має вигляд кумулятивної гістограми із вбудованою кумулятою. На осі ординат відкладають точку, що дорівнює половині суми частот. З цієї точки проводять лінію, паралельну осі абсцис до її перетину з лінією кумулятивного полігону (точка А). З точки А на вісь абсцис опускають перпендикуляр, координата якого і буде медіаною. Приклад графічного визначення медіани наведено на рис. 6.4.
Результати розрахунків свідчать про те, що типовим рівнем ціни товару є
x = 44 грн.; половина одиниць товару мають значення ціни, що дорівнює або менше ніж 46 грн., а інша половина - дорівнює або більше ніж 46 грн.
Рис. 6.4. Визначення медіани графічним методом
В аналізі закономірностей розподілу крім медіани використовуються також й інші структурні (або порядкові) характеристики, які ділять всі одиниці розподілу на рівні за чисельністю групи. Вони отримали загальну назву
71

квантилі. Частинним випадком квантилів є, насамперед, квартилі, квінтилі, децилі та перцентилі (діле сукупність на сто рівних частин).
Квартилі – це варіанти, які ділять обсяг сукупності на чотири рівних частини. Існують три квартилі. У загальному вигляді значення і-го квартиля визначається за формулою:
|
|
і |
fi |
|
SQuі 1 |
||
Quі x Quі |
hQuі |
4 |
|||||
|
|
|
, |
||||
|
fQuі |
|
|||||
|
|
|
|
|
|||
де Quі – і-й квартиль;
xQu і – нижня межа і-го квартильного інтервалу;
h Qu і – ширина інтервалу, де розташований і-й квартиль;fi / 4 – чверть сукупності;
SQu і – 1 – сума накопичених частот до інтервалу, де розташований і-й квартиль; fQu і – частота інтервалу, де розташований і-й квартиль.
і – порядковий номер квартиля.
Слід зауважити, що в тому разі, якщо перший квартиль (або інший структурний показник: медіана, квінтиль чи дециль) потрапляють до першого інтервалу, то попередня сума накопичених частот дорівнює нулю. Квартилі так само як медіану можна визначити графічним способом за допомогою кумулятивного полігону. Для цього за віссю ординат відкладають відповідні точки, з яких проводять лінії паралельно осі абсцис до перетину з кумулятивним полігоном (відповідно точки А, В, С). Далі з точок (А, В, С) опускають перпендикуляри на вісь абсцис та отримують відповідні значення квартилів (див. рис. 6.5).
Sf
300 |
* |
270 |
|
|
|
|
|
|
|
|
|
|
240 |
|
|
|
|
|
|
|
|
|
|
210 |
|
|
|
|
|
С |
|
|
|
|
180 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
150 |
|
|
В |
|
|
|
|
|
|
|
120 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
90 |
А |
|
|
|
|
|
|
|
|
|
60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
Qu1 |
|
Qu2 |
|
|
Qu3 |
|
|
|
|
0 |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
X |
|
50 |
100 |
150 |
200 |
250 |
300 |
350 |
400 |
450 |
500 |
|
Рис. 6.5. Визначення квартилів графічним способом
72
Квінтилі – це варіанти, які ділять обсяги сукупності на п’ять рівних частин. Існує чотири квінтиля. Значення і-го квінтиля визначається за формулою:
Qwі x Qwі |
hQwі |
0,2і fі |
SQwі 1 |
|
|
|
, |
||
|
|
|||
|
|
fQwі |
||
де Qwі – перший квінтиль;
xQw і – нижня межа першого квінтиля;
h Qw і – ширина інтервалу, де розташований перший квінтиль; 0,2 fi – одна п’ята сукупності;
і – порядковий номер квінтиля;
SQw і – 1 – сума накопичених частот до інтервалу, де розташований перший квінтиль;
fQw і – частота інтервалу, де розташований перший квінтиль.
Графічним способом визначення квінтилів виконують аналогічно представленню квартилів.
Децилі – це варіанти, які ділять обсяги сукупності на десять рівних частин. Існує дев’ять децилів, що визначаються за формулою, яка в загальному вигляді має таке вираження:
Dei |
xDei |
hDei |
0,1i fi |
SDei 1 |
|
|
|
, |
|||
|
|
||||
|
|
|
fDei |
||
де і – порядковий номер дециля; xDe i – нижня межа і-го дециля;
h De i – ширина інтервалу, де розташований і-й дециль; 0,1 fi – одна десята сукупності;
SDe i – 1 – сума накопичених частот до інтервалу, де розташований і-й дециль; fDe i – частота інтервалу, де розташований і-й дециль.
Децилі також можна визначити графічним способом за допомогою кумулятивного полігону.
6.3. Характеристики вимірювання варіації ознак - абсолютні та відносні міри варіації (розмах варіації, середнє лінійне та середнє квадратичне відхилення, коефіцієнти варіації). Варіація альтернативної ознаки
Варіація, тобто коливання, мінливість будь-якої ознаки є властивістю статистичної сукупності. Здатність ознаки змінювати індивідуальні значення називається варіабельністю. Вона зумовлена дією безлічі взаємопов’язаних причин, серед яких є основні та другорядні. Основні причини формують центр розподілу. Другорядні причини впливають на форму розподілу.
73

Для виміру та оцінки варіації використовують систему абсолютних та відносних характеристик. До абсолютних характеристик належать: розмах варіації, середнє лінійне відхилення, середнє квадратичне відхилення та дисперсія. До відносних характеристик варіації належать різноманітні коефіцієнти, найбільш поширене використання серед яких мають коефіцієнти варіації, що побудовані на відношенні абсолютних характеристик з середньою арифметичною. Кожна з названих характеристик має певні аналітичні переваги під час вирішення тих чи інших завдань статистичного аналізу.
Методика обчислення характеристик варіації залежить від виду ознаки Х та наявних даних (первинні чи похідні, згруповані чи ні).
Розмах варіації – різниця між найбільшим і найменшим значеннями ознаки, розраховується за формулою:
R = X max – X min,
де X max – максимальне значення ознаки X min – мінімальне значення ознаки.
Розмах варіації характеризує межі, в яких змінюється кількісне значення ознаки. Цей показник встановлює крайні числові значення варіант, що складають досліджувану сукупність.
В інтервальному ряді розподілу розмах варіації визначають як різницю між верхньою межею останнього інтервалу та нижньою межею першого. Проте, якщо інтервал відкритий, для обчислення розмаху варіації використовується середина інтервалу. Звичайно, спочатку інтервал має бути закритим згідно з відповідними правилами.
Крім розмаху варіації, у практиці статистичного аналізу широко застосовують інші абсолютні характеристики варіації, що ґрунтуються на відхиленнях індивідуальних значень ознаки від середньої арифметичної.
Оскільки відповідно до першої властивості середньої арифметичної( Х і – Х ) = 0, то при розрахунку такого роду характеристик використовують або модулі, або квадрати відхилень. У результаті маємо такі характеристики варіації: середнє лінійне відхилення, середнє квадратичне відхилення та дисперсію. Розрахункові формули цих показників наведені в табл. 6.5.
Якщо статистична сукупність надана у вигляді інтервального варіаційного ряду, то для розрахунку показників варіації використовуються розрахункові формули за зваженою формою. При цьому замість індивідуального значення ознаки обирається середина відповідного інтервалу.
Середнє лінійне відхилення являє собою середню відстань між середньою арифметичною величиною та відповідними індивідуальними значеннями окремих ознак, а це завжди додатна величина. Саме тому у формулах відхилення кожної варіанти від середньої арифметичної береться за модулем.
Дисперсія являє собою середній квадрат відхилень, є відповідні властивості дисперсії і вона пов’язана з середнім квадратичним відхиленням таким співвідношенням:
74


 D
D 
 2 ,
2 ,
де – середнє квадратичне відхилення D = 2 – дисперсія.
Таблиця 6.5
Показники варіації та формули для їх розрахунку
Назва показника |
|
|
|
Розрахункова формула за даними |
||||||||||||||||||||||||||||
не згрупованими |
згрупованими |
|||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||
Середнє |
лінійне |
|
|
|
|
|
|
xi |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xi |
|
|
|
fi |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
x |
||||||||||||||||||
|
|
|
|
|
|
|
|
l |
|
|||||||||||||||||||||||
l |
||||||||||||||||||||||||||||||||
відхилення |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
fi |
|||||||||||||||
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Середнє |
квадратичне |
|
|
|
|
|
|
|
x |
|
|
|
2 |
|
|
|
|
|
|
xi |
|
|
2 fi |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
||||||||||||||||
|
|
|
|
|
|
x |
|
|
|
|||||||||||||||||||||||
відхилення |
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
fi |
|||||||||||||
|
|
|
|
|
n |
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
2 ( xi |
|
|
|
|
|
|
|
|
|
|
|
|
|
( xi |
|
|
) 2 fi |
|||||||||||||
Дисперсія |
|
x |
) 2 |
2 |
|
|
x |
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
fi |
||||||||||||||
хі – індивідуальні значення окремої ознаки, варіанти
х – середня арифметична (середнє значення ознаки) n – обсяг сукупності, кількість ознак у сукупності fi – частота відповідної ознаки.
При порівнянні варіації різних ознак або однієї ознаки у різних сукупностях використовуються відносні характеристики: коефіцієнти варіації. До них належать:
лінійний коефіцієнт варіації, який обчислюється за формулою:
V l |
|
|
l |
|
, |
або V l |
|
|
|
l |
|
|
·100 %, |
|
|
|
|||||||||||
|
x |
|
|
|
|
|
|||||||
|
|
|
|
||||||||||
|
|
|
|
|
|
|
x |
||||||
де l – середнє лінійне відхилення
х– середня арифметична;
квадратичний коефіцієнт варіації, який обчислюється за формулою:
V |
|
|
або V |
|
|
||||||
|
|
|
, |
|
|
|
·100 %, |
||||
|
|
|
|
|
|
||||||
|
|
|
|
||||||||
|
|
|
x |
|
|
|
x |
||||
де – середнє квадратичне відхиленнякоефіцієнт осциляції, який обчислюється за формулою:
R
V R x ,
де R – розмах варіації.
75

Чим менше середнє відхилення, тим більш типова середня, тим більш однорідна сукупність. Найчастіше квадратичний коефіцієнт варіації використовують як критерій однорідності сукупності, він є ознакою надійності середньої.. У симетричному, близькому до нормального, розподілі Vσ = 0,33.
Для малих сукупностей розрізняють такі значення відносних коливань: Vσ < 10% - незначне коливання, сукупність однорідна, значення
середньої є типовим рівнем ознаки в даній сукупності;
10 % ≤ Vσ ≤ 33% - середнє коливання, сукупність в межах однорідності, значення середньої можна вважати типовим рівнем ознаки в даній сукупності;
Vσ > 33% - високий рівень варіації, сукупність неоднорідна, значення середньої неможна вважати типовим рівнем ознаки в даній сукупності.
Середнє квадратичне відхилення також пов’язане з середнім лінійним відхиленням. За правилом мажорантності середніх > l . Якщо обсяг сукупності досить великий і розподіл ознаки наближається до нормального, то між середнім квадратичним та середнім лінійним відхиленнями існує такий взаємозв’язок:
= 1,25 l , |
або |
l = 0,8 . |
|
||||||
Для нормального розподілу варіативної ознаки справедливе також |
|||||||||
твердження, що R = 6 . Значення ознаки в межах ( |
|
|
|
|
) мають 68,3 % обсягу |
||||
х |
|||||||||
сукупності, у межах ( |
|
|
2 ) – 95,4 |
%, а в межах ( |
|
|
3 ) – 99,7 %. Це відоме |
||
х |
х |
||||||||
“правило трьох сигм”. |
|
|
|
|
|
|
|
||
Дисперсія, або середній квадрат відхилення ( 2 ), посідає особливе місце в статистичному аналізі соціально-економічних явищ. Завдяки своїм математичним властивостям, вона має важливе значення не лише під час вивчення варіації, але є невід’ємним і важливим елементом інших статистичних методів аналізу, зокрема, вибіркового, дисперсійного та кореляційнорегресійного.
Дисперсію використовують не лише для оцінки варіації, а й для вимірювання взаємозв’язків, для перевірки статистичних гіпотез тощо.
Для ознак метричної шкали дисперсія є базою для обчислення середнього квадратичного відхилення, оскільки 
 D
D 
 2 , і залежно від наявних даних може бути простою (для не згрупованих даних):
2 , і залежно від наявних даних може бути простою (для не згрупованих даних):
2 ( xi x) 2 n
або зваженою (для згрупованих даних):
2 ( xi x) 2 fi ,
fi
де хі – індивідуальні значення окремої ознаки, варіанти
х – середня арифметична (середнє значення ознаки)
76

n – обсяг сукупності, кількість ознак у сукупності fi – частота відповідної ознаки.
Дисперсія має певні математичні властивості:
1. Якщо кожну варіанту зменшити або збільшити на одну й ту саму величину А, дисперсія не зміниться. Математично це записується у такому вигляді:
x i A x A 2 D . n
2. Якщо кожну варіанту збільшити або зменшити в k разів, то дисперсія зміниться в k 2 разів:
k x i k x 2 k 2 D . n
3. Якщо частоти замінити частками, дисперсія не зміниться. Математично це виражається так:
|
|
|
|
|
|
|
2 |
( xi x) 2 fi |
= (х і – |
|
) 2d i. |
||
х |
||||||
|
fi |
|
|
|
||
Нескладними алгебраїчними перетвореннями можна довести, що дисперсія – це різниця квадратів, а саме різниця між середнім квадратом і квадратом середньої величини:
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
2 x 2 |
|||||
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
x , |
|||||
де |
|
|
|
– середній квадрат значень ознаки |
|
|
|
||||||
x 2 |
|
|
|
||||||||||
|
|
|
2 – квадрат середньої величини. |
|
|
|
|||||||
|
|
x |
|
|
|
||||||||
|
|
|
|
Середній квадрат значень ознаки розраховується за формулою: |
|||||||||
|
|
|
|
|
|
|
|
x i2 |
|
|
|
||
|
|
|
|
|
x |
2 |
|
|
|
|
|||
|
|
|
|
|
|
|
, |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
||||
n
де х і – значення окремої ознаки
n – обсяг сукупності (кількість ознак).
Дисперсія альтернативної ознаки обчислюється як добуток часток за формулою:
2 d1 d0 ,
де d 1 – частка елементів сукупності, яким властива ознака
d 0 – частка решти елементів, у яких відсутня ознака (d 0 = 1 – d 1).
Дисперсія альтернативної ознаки широко використовується під час проектування вибіркових обстежень, обробці даних соціологічних опитувань, статистичному контролі якості продукції тощо.
77

6.4. Характеристики форми розподілу: коефіцієнти асиметрії та ексцесу |
||||||||||||||||
Різноманітність статистичних сукупностей – передумова різних форм |
||||||||||||||||
співвідношення частот і значень варіативної ознаки. За своєю формою роз- |
||||||||||||||||
поділи поділяються на одновершинні (див. рис. 6.7) та багатовершинні (коли |
||||||||||||||||
розподіл має дві, три та більше вершин). Наявність двох і більше вершин (див. |
||||||||||||||||
рис. 6.8) свідчить про неоднорідність сукупності, про поєднання в ній груп з |
||||||||||||||||
різними рівнями ознаки. У такому разі необхідно більш ретельно |
||||||||||||||||
проаналізувати наявну вихідну інформацію, перегрупувати дані, виділивши |
||||||||||||||||
однорідні групи. Розподіли якісно однорідних сукупностей, як правило, |
||||||||||||||||
одновершинні. Серед одновершинних розподілів є симетричні та асиметричні |
||||||||||||||||
(скошені), гостровершинні та плосковершинні. |
|
|
|
|
|
|
||||||||||
4 |
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
1 |
3 |
5 |
7 |
9 |
11 |
13 |
15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Рис.6.7. Одновершинний розподіл |
Рис. 6.8. Багатовершинний розподіл |
|||||||||||||||
У симетричному розподілі рівновіддалені від центра значення ознаки |
||||||||||||||||
мають однакові частоти, при цьому середня, мода та медіана мають однакові |
||||||||||||||||
значення x |
= Мо = Ме в асиметричному – вершина розподілу зміщена. Напрям |
|||||||||||||||
асиметрії протилежний напряму зміщення вершини. Якщо вершина зміщена |
||||||||||||||||
вліво, то це правостороння асиметрія. У цьому випадку x |
> Me > Mo. Якщо |
|||||||||||||||
вершина зміщена |
вправо, |
то |
це |
лівостороння |
асиметрія. |
В |
цьому |
випадку |
||||||||
x < Me < Mo. Асиметрія (див. рис. 6.9) виникає внаслідок обмеженої варіації в |
||||||||||||||||
одному напрямі або під впливом домінуючої причини розвитку, яка веде до |
||||||||||||||||
зміщення центру розподілу. Очевидно, що в симетричному розподілі А = 0, при |
||||||||||||||||
правосторонній асиметрії A > 0, при лівосторонній – A < 0. |
|
|
|
|
||||||||||||
Найпростішою мірою асиметрії є відхилення від середньої арифметичної |
||||||||||||||||
медіани чи моди. В симетричному розподілі характеристики центра мають |
||||||||||||||||
однакові значення |
x |
= Мо = Ме |
в асиметричному – між ними існують певні |
|||||||||||||
розбіжності. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
78 |
|
|
|
|
|
|
|
|

3,5 |
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
2,5 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
1,5 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
0,5 |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Рис. 6.9. Види розподілу:
- |
симетричний розподіл (Мо = Ме = х ); |
||
- |
правостороння (додатня ) асиметрія (Мо < Ме < |
|
); |
х |
|||
–- лівостороння (від’ємна) асиметрія (Мо > Ме > х ).
Стандартизовані відхилення, які мають назву коефіцієнта асиметрії, характеризують напрям та міру скошеності розподілу і розраховуються за формулами:
A |
x Mo |
або . A |
x Me |
; |
|
|
|
|
|
Якщо має місце відхилення коефіцієнта асиметрії від нуля в той чи інший бік, то можна вести мову про більшу чи меншу асиметрію. Вважають, що при
A |
|
0,25 |
асиметрія низька при 0,25< |
A |
0,5 |
- помірна, або середня при |
A |
|
>0,5 |
- асиметрія висока. |
|
|
|
|
|
|
|
Характеристики центру розподілу ґрунтуються на моментах розподілу. Момент розподілу – це середня k-го ступеня відхилень x a . Залежно від величини а моменти поділяють на первинні (а = 0), центральні a x і умовні (a = const). Ступінь k визначає порядок моменту. В загальному вигляді центральний момент k-го порядку розраховується за формулою:
M k xi x k fі ,
fі
де хі – значення окремої варіанти;
x – середня арифметична; k – ступінь моменту;
fi – частота окремої варіанти.
Для того, щоб характеристика скошеності не залежала від масштабу вимірювання ознаки для порівняння ступеня асиметрії різних розподілів, використовують стандартизований момент третього ступеня. В такому разі коефіцієнт асиметрії визначається за формулою:
79
|
M |
|
|
xi |
|
|
|
3 fi |
|
A |
3 |
|
x |
, |
|||||
3 |
3 |
fi |
|
||||||
|
|
|
|
||||||
де М3 – центральний момент третього порядку;– середнє квадратичне відхилення.
Гостровершинність розподілу відображає скупченість значень ознаки навколо середньої величини та називається ексцесом. Для вимірювання ексцесу використовують коефіцієнт, побудований за допомогою стандартизованого моменту четвертого порядку, який розраховується за формулою:
|
M |
|
|
xi |
|
|
|
4 fi |
|
E |
4 |
|
x |
, |
|||||
4 |
4 |
fi |
|
||||||
|
|
|
|
||||||
де М4 – центральний момент четвертого порядку.
Якщо Е = 3, то розподіл уважається нормальним, при E < 3 – плосковершинний, при E > 3 - розподіл має гостровершинну форму. Термін «ексцес» грецького походження (kurtosis), тому назви форми ексцесу походять від цього кореня слова (див. рис.6.10):
5 |
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
Рис.6.10. Види розподілу:
– нормальний (мезокуртичний) (Е = 3);
– гостровершинний (стрічкокуртичний) (Е > 3);
– плосковершинний (платокуртичний) (Е < 3).
Наведений графік свідчить, що для стрічкокуртичної кривої характерне розміщення більшості одиниць сукупності поблизу центра. У випадку платокуртичної кривої (форма силуету – плато) варіанти значно віддалені від центру розподілу. Помірне розміщення навколо центра розподілу варіант визначає форма ексцесу у вигляді мезокуртичної кривої. На практиці часто в одному розподілі поєднуються всі названі особливості, а саме: одновершинний розподіл може бути симетричним та гостровершинним, або плосковершинним з лівосторонньою асиметрією, або гостровершинним з правосторонньою асиметрією тощо.
80
6.5. Показники диференціації та концентрації
Процеси і явища в промисловому і сільськогосподарському виробництві, фінансовій та комерційній діяльності, демографічній, соціальній або політичній галузях, що вивчаються статистикою, як правило, характеризуються внутрішньою структурою, яка із часом може змінюватися. Динаміка структури викликає зміну внутрішнього змісту досліджуваних об’єктів і їх економічну інтерпретацію, приводить до змін встановлених причинно-наслідкових зв’язків. Тому вивчення структури і структурних зрушень займає дуже важливе місце
вкурсі статистики.
Устатистиці під структурою розуміють сукупність одиниць, яким притаманна певна стійкість внутрішньо групових зв’язків при збереженні основних ознак, що характеризують цю сукупність як ціле.
Одним із найважливіших завдань держави є забезпечення сталого соціально-економічного розвитку на основі пропорційного співвідношення між окремими підсистемами. Тому останнім часом все більше уваги приділяється питанням теорії та практики аналізу пропорційності (або нерівномірності) розподілу як одного із напрямів обґрунтування взаємозв’язків розподілів,
зокрема: ресурсів та їх використання; чисельності населення і споживання матеріальних благ і послуг; доходів і витрат; попитом і пропозицією та ін.
Практичний аналіз потребує дослідження і врахування у процесі управління пропорційності як двох взаємопов’язаних показників (результативної та факторної) ознак, так і однієї результативної оцінки з кількома факторними. За групову ознаку можуть при цьому слугувати окремі регіони, галузі, види діяльності, групи фізичних та юридичних осіб і т. ін.
Основні напрямки вивчення нерівномірності розподілу в різних соціально-економічних явищах:
оцінка структури аналізованих сукупностей з використанням квантилів розподілу для виявлення різного рівня диференціації;
визначення узагальнюючих характеристик концентрації та локалізації. Мірою оцінки розшарування сукупності слугує коефіцієнт децильної
диференціації. Коефіцієнт децильної диференціації, що є відношенням розмірів дев’ятого і першого дециля (наприклад, відношення мінімального середньодушового доходу 10% найбагатшого населення до максимального середньодушового доходу 10% найменш забезпеченого населення), дорівнює:
VD |
|
D9 |
, або |
VD |
|
D9 |
·100 %, |
|
D1 |
D1 |
|||||||
|
|
|
|
|
|
де D9 – дев’ятий дециль D1 – перший дециль.
Але цей показник не зовсім точно вимірює рівень диференціації, так як співставляються, наприклад, мінімальна величина активів 10% самих великих банків із максимальною величиною активів 10% самих маленьких банків. Точніше рівень диференціації можна оцінити, співставляючи середні рівні
81
активів 10% самих великих і 10% самих маленьких банків. Цей показник називають фондовим коефіцієнтом Кф.
Ступінь нерівномірності розподілу досліджуваної ознаки, не пов’язаний ні з обсягом сукупності, ні з чисельністю окремих груп, називають концентрацією. При дослідженні нерівномірності розподілу досліджуваної ознаки за територією поняття “концентрація” замінюють поняттям “локалізація”. Централізація означає зосередженість (скупченість) обсягу ознаки у окремих одиниць (наприклад, капіталу в окремих комерційних банках, продукції якогось виду на окремих підприємствах і т. ін.).
Узагальнюючий показник централізації ІZ розраховується за формулою:
|
|
|
|
2 |
|
|
|
|
|
|
|
n |
|
mi |
|
|
|
I Z |
|
, |
|||
n |
|
||||
i 1 |
|
|
m |
|
|
|
|
i |
|||
|
|
i 1 |
|
|
|
де mi – значення ознаки і-ої одиниці сукупності ;
n
mi - обсяг ознаки всієї сукупності;
i 1
n - обсяг сукупності (кількість одиниць, що входять у сукупність).
Максимального значення ІZ досягає тільки за умови, що сукупність складається тільки із однієї одиниці, якій належить весь обсяг ознаки. Мінімальне значення цього показника наближається до нуля, але ніколи його не досягає.
Оцінка нерівномірності розподілу між окремими складовими сукупності ґрунтується на порівнянні часток двох розподілів – за кількістю елементів сукупності di і обсягом значень ознаки Di.. Якщо розподіл значень ознаки рівномірний, то di = Di, а відхилення часток свідчать про певну нерівномірність, яка вимірюється коефіцієнтами локалізації та концентрації.
Особливу групу показників диференціації доходів становлять коефіцієнти концентрації доходів. Вони належать до системи оцінок, відомої як методологія Парето – Лоренца – Джині, що знайшла широке застосування в міжнародній соціальній статистиці. Італійський економіст і соціолог В. Парето (1848 – 1923) установив, що між рівнем доходів і числом їх одержувачів існує зворотна залежність, названа в літературі «законом Парето». Американський статистик і економіст О. Лоренц (1876 – 1959) розвив цей закон, запропонувавши його графічне зображення у вигляді кривої лінії, яка дістала назву «кривої Лоренца». Італійський статистик і економіст К. Джині (1884 – 1965) розробив методику розрахунку коефіцієнта концентрації доходів, названого його ім’ям.
Крива Лоренца дає графічне уявлення про ступінь нерівномірності розподілу сукупного доходу за групами населення. Рівномірний розподіл доходу це такий розподіл, коли певній частці населення відповідає точно така сама частка сукупного доходу. На графіку Лоренца, побудованого в координатах: вісь абсцис - частки населення, вісь ординат - частки доходу, лінією рівномірного доходу є діагональ квадрата. Крива лінія, побудована за фактичними показниками рівня доходу різних
82
груп населення, відбиває реальний розподіл сукупного доходу серед груп населення. Чим більше ця лінія відхиляється від діагоналі, тим більш нерівномірно розподілений дохід у суспільстві, а отже, тим вища його концентрація [13, с. 414 - 417].
Коефіцієнт локалізації визначається для кожної складової сукупності за формулою:
Li |
|
Di |
100 |
або Li = dрез / dфак , |
|
di |
|||||
|
|
|
|
де di (dфак ) - частка i-ої групи розподілу за кількістю елементів сукупності (частка факторної ознаки);
Di (dрез ) - частка i-ої групи розподілу за обсягом значень ознаки (частка результативної ознаки)..
Таким чином, коефіцієнт локалізації показує відношення частки результативної ознаки до частки факторної. Якщо Li < 1, то це означає, що на і-ий регіон припадає менше результативної ознаки порівняно із пропорційною часткою факторної ознаки, і навпаки. У складі коефіцієнтів локалізації вирізняються дві групи зі значеннями Li < 1 та Li > 1, тобто із від’ємними та додатними значеннями пропорційності розподілу по конкретній групі.
Для визначення їхнього впливу на загальну концентрацію по кожній групі розраховуються суми модулів:
D –= Σ |dрез – dфак | та D + = Σ |dрез – dфак |.
Далі визначається частка цих сум у загальній сумі відхилень:
М – = D – / Σ |dрез – dфак | та М + =D + / Σ |dрез – dфак |.
Визначені показники дають характеристику ролі цих груп у формуванні як від’ємних, так і додатних характеристик розподілу та використовуються під час розроблення відповідних управлінських рішень. На основі цих характеристик розподілу досліджують і багатофакторну пропорційність, використовуючи комбіновану модель, у яку входять одна результативна ознака і сукупність факторних ознак. Це дає змогу зокрема ранжирувати факторні ознаки за мірою взаємозв’язку та впливу на розподіл результативної ознаки.
Коефіцієнт концентрації (коефіцієнт Лоренца), як відносна характеристика нерівності в розподілі доходів, є узагальнюючою для сукупності характеристикою відхилення розподілу від рівномірного і визначається за формулою:
|
k |
|
|
|
|
|
|
|
|
|
|
||
KЛ |
0,5 |
|
d |
i |
D |
. |
|
i 1 |
|
|
i |
|
|
|
|
|
|
|
|
Чим ближче значення цього показника до 1 (100%), тим вищий рівень концентрації,тобто існує повна нерівність розподілу за досліджуваною ознакою, при значенні КЛ = 0 розподіл ознаки за всіма одиницями сукупності є рівномірним. При визначенні цього коефіцієнта можна оперувати як частками
83
одиниці, так і відсотками. Порівняння структур на основі відхилень часток дозволяє вимірювати диференціацію сукупності за даними інтервальних рядів із нерівними інтервалами та атрибутивних рядів розподілу.
Найбільш відомим показником концентрації є коефіцієнт Джині, який зазвичай використовують для вимірювання диференціації або соціального розшарування. У загальному вигляді його розраховують за формулою:
k |
Dн |
k |
|
G 1 2 di |
di |
D , |
|
i 1 |
i |
i 1 |
i |
|
|
де di - частка i-ої групи розподілу за кількістю елементів сукупності; Di - частка i-ої групи розподілу за обсягом значень ознаки;
Dні – накопичена частка i-ої групи розподілу за обсягом значень ознаки..
Якщо частки представлені у %, то попередню формулу можна перетворити:
для 10% розподілу –
k
G 110 0,2 Dн ;
i 1 i
для 20% розподілу –
k
G 120 0,4 Dн .
i 1 i
Коефіцієнт Джині змінюється в тих же межах, що і коефіцієнт Лоренца.
Наприклад, цей коефіцієнт може використовуватися для аналізу рівня концентрації доходів у окремих груп населення. Чим ближче значення до 1, тим вища концентрація доходів у окремих груп населення; чим ближчий він до 0, тим вищий рівень рівності в розподілі сукупного доходу суспільства.
Оцінювання інтенсивності структурних зрушень
Визначення структурних зрушень окремих частин сукупності та узагальнюючих характеристик структурних зрушень в цілому по сукупності базується на відносних показниках структури (див. лекцію до теми №4 "Узагальнюючі статистичні показники"), що являють собою співвідношення окремих частин і цілого. При цьому вони можуть бути представлені як частка (коефіцієнт) або питома вага (%). Як часткові, так і узагальнюючі показники структурних зрушень можуть відображати або “абсолютну” зміну структури у процентних пунктах чи долях одиниці, або її відносну зміну у процентах чи коефіцієнтах. “Абсолютна” зміна показана в лапках, тому що цей показник є абсолютним за методологією розрахунку, а не за суттю та одиницями виміру. До таких показників відносять:
“абсолютний” приріст питомої ваги і - ої частини сукупності;
темп зростання питомої ваги ( відносна зміна) і - ої частини сукупності;
84
середній “абсолютний” приріст питомої ваги і - ої частини сукупності;
середній темп зростання питомої ваги ( відносна зміна) і - ої частини сукупності за кілька періодів часу;
лінійний і квадратичний коефіцієнти “абсолютних” структурних зрушень;
квадратичний коефіцієнт відносних структурних зрушень;
лінійний коефіцієнт “абсолютних” структурних зрушень за n періодів
“Абсолютний” приріст питомої ваги і - ої частини сукупності показує на скільки процентних пунктів збільшилася (+) або зменшилася (-) ця структурна частина в j – ий період часу порівняно із (j – 1) періодом:
|
di |
dij dij 1 , |
||
де dij |
- питома вага (частка) і - ої частини сукупності в j – ий період часу; |
|||
dij-1 |
- питома вага (частка) і - ої частини сукупності в (j – 1) період часу. |
|||
|
Темп зростання питомої ваги ( відносна зміна) і - ої частини сукупності |
|||
є співвідношенням : |
|
|
|
|
|
Tp di |
|
dij |
100,%. |
|
|
|||
|
|
|
dij 1 |
|
Темп зростання питомої ваги представляють у %, це завжди додатна величина. Але, якщо в сукупності мали місце якісь структурні зрушення, то частина темпів зростання буде більшою за 100%, а частина - меншою.
Якщо сукупність, що досліджується, представлена даними не за два, а за три і більше періодів, то з’являється необхідність у визначенні середніх показників структурних зрушень. Так, середній “абсолютний” приріст питомої ваги і - ої частини сукупності визначають як середню арифметичну просту із послідовно визначених абсолютних приростів за кожен період часу. При цьому слід пам'ятати, що сума середніх абсолютних приростів питомої ваги для всіх k структурних частин сукупності, так як і сума їх приростів за один часовий інтервал, завжди повинна дорівнювати нулю.
Середній темп зростання питомої ваги ( відносна зміна) і - ої частини сукупності за кілька періодів часу визначається за формулою середньої геометричної простої.
Узагальнюючими показниками структурних зрушень у випадках, коли виникає необхідність оцінити структурні зрушення у соціально-економічному явищі в цілому за якісь окремі часові періоди або у кількох структур, що належать до окремих об’єктів за один і той же часовий період, є лінійний та квадратичний коефіцієнти “абсолютних” структурних зрушень, які визначають за формулами:
85

лінійний коефіцієнт “абсолютних” структурних зрушень
|
|
|
|
k |
dij dij 1 |
|
|
|
|
|
|
|
|
|
|
|
||||
d d |
0 |
|
i 1 |
|
, |
|
|
|
|||||
1 |
|
|
k |
|||
|
|
|
|
|
||
де k – кількість структурних частин сукупності;
dij - питома вага (частка) і - ої частини сукупності в j – ий період часу; dij-1 - питома вага (частка) і - ої частини сукупності в (j – 1) період часу.
квадратичний коефіцієнт “абсолютних” структурних зрушень
|
|
k |
|
|
d |
|
2 |
|
|
|
|
d |
ij |
ij 1 |
|
||
σd d |
|
i 1 |
|
|
|
|||
|
|
|
|
|
|
. |
||
|
|
|
k |
|
|
|||
1 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Лінійний та квадратичний коефіцієнти “абсолютних” структурних зрушень (у процентних пунктах) дозволяють отримати зведену оцінку швидкості зміни питомої ваги окремих частин сукупності. Для зведеної характеристики інтенсивності зміни питомої ваги окремих частин сукупності використовують квадратичний коефіцієнт відносних структурних зрушень:
|
|
k |
|
|
d |
|
2 |
|
|
|
d |
ij |
ij 1 |
|
|
||
σ |
|
|
|
|
|
100 , |
||
|
|
dij 1 |
|
|||||
d1 |
/d 0 |
i 1 |
|
|
|
|
||
Цей показник відображає той середній відносний приріст питомої ваги (у відсотках), який спостерігався за період, що досліджується.
Для зведеної оцінки структурних зрушень у досліджуваній сукупності в цілому за весь часовий інтервал, що охоплює кілька тижнів, місяців, кварталів чи років, найбільш доцільно використовувати лінійний коефіцієнт
“абсолютних” структурних зрушень за n періодів (у процентних пунктах):
|
|
|
|
|
k |
din di1 |
|
|
|
|
(n) |
|
|
|
|
|
|
|
|||||
|
d d |
|
i 1 |
|
, |
||
|
|
|
|||||
|
1 |
0 |
|
k(n 1) |
|||
|
|
|
|
|
|
||
де din |
- питома вага (частка) і - ої частини сукупності в останній період часу; |
||||||
di1 |
- питома вага (частка) і - ої частини сукупності в 1 - ий період часу. |
||||||
Цей показник може використовуватися як для порівняння динаміки двох і більше структур, так і для аналізу динаміки однієї і тієї ж структури за різні за тривалістю періоди часу.
Для забезпечення порівнянності структур одного об’єкта в динаміці іноді доводиться перегруповувати дані, тобто перегруповувати статистичні
86

матеріали, раніше зведені в групи. Це дає змогу забезпечити порівнянність структур двох сукупностей за однією й тією ж самою ознакою у часі або просторі.
Перегрупування здійснюється зменшенням або збільшенням кількості раніше утворених груп. Розрізняють два способи вторинного групування:
просте укрупнення інтервалів;
перегрупування за часткою окремих груп в загальному їх підсумку (пропорційний дольовий перерозподіл).
Якщо межі інтервалів первинного і вторинного групування збігаються, то частоти інтервалів, що об’єднуються, просто підсумовуються.
Вважається, що в межах інтервалу розподіл частот (або часток) підпорядковується рівномірному закону розподілу. Це припущення дає можливість розбивати інтервал первинного групування пропорційно співвідношенню частин ширини розбитого інтервалу і обчислювати відповідні значення частот.
За аналогією з коефіцієнтом концентрації при порівнянні структури одного об’єкта за двома ознаками або структур двох об’єктів розраховують коефіцієнт подібності (схожості) структур:
P 1 0,5 d j dk .
де dj та dk - питома вага (частка) відповідно j - ої та k - ої сукупності. Якщо структури однакові, Р = 1. Чим більші відхилення структур, тим
менше значення коефіцієнта Р.
87
Змістовий модуль 3. АНАЛІЗ ЗАКОНОМІРНОСТЕЙ ДИНАМІКИ
Тема 7. Аналіз інтенсивності динаміки
План вивчення теми
7.1.Поняття та складові елементи рядів динаміки (часових рядів). Передумови й об’єктивні умови для побудови рядів динаміки
7.2.Види рядів динаміки та їх особливості
7.3.Статистичні характеристики часових рядів: абсолютний приріст, темп зростання, темп приросту, абсолютне значення 1% приросту; їх взаємозв’язок
7.4.Середні характеристики часового ряду
7.5.Оцінка прискорення (уповільнення) розвитку. Порівняльний аналіз динамічних рядів; коефіцієнти випередження та еластичності, умови їх використання
Після вивчення теми студенти повинні:
знати: в чому полягають передумови й об’єктивні умови для побудови рядів динаміки (часових рядів); зміст статистичних характеристик (абсолютних і відносних) рядів динаміки, їх взаємозв’язок;
уміти: обґрунтовано використовувати на практиці основні статистичні характеристики (абсолютні та відносні) для аналізу інтенсивності динаміки, проводити порівняльний аналіз динамічних рядів.
Бібліографічний список: [7 – 10; 17 - 22 ]
7.1.Поняття та складові елементи рядів динаміки (часових рядів). Передумови й об’єктивні умови для побудови рядів динаміки
Суспільно-економічні явища безперервно змінюються. Протягом певного часу – місяць за місяцем, рік за роком змінюється кількість населення, обсяг та структура суспільного виробництва, рівень продуктивності праці тощо. Вивчення поступального розвитку й змін суспільних та економічних явищ – одне з основних завдань статистики.
Для кращого розуміння і аналізу зміни досліджуваних явищ у часі статистичні дані, що їх характеризують, необхідно систематизувати у хронологічному порядку і вже потім аналізувати. У статистиці це виконується за допомогою рядів динаміки або ще їх називають часовими рядами.
Отже, ряди динаміки – це ряди чисел, що характеризують закономірності зміни суспільних явищ і процесів у часі, тобто це сукупність значень статистичних показників , розташованих у хронологічному порядку.
Кожний ряд динаміки складається з двох елементів:
числових значень статистичних показників (рівнів ряду) – y;
періодів або моментів часу, яким відповідають рівні ряду – t.
88
Таким чином, під час вивчення динаміки важливі не лише числові значення рівнів, а й їх послідовність. Як правило, часові інтервали між рівнями однакові (доба, тиждень, місяць, квартал, півріччя, рік тощо). Якщо прийняти за одиницю довжину певного інтервалу, послідовність рівнів можна записати у вигляді:
у1, у2 , у3 , у4 , . . . , уn ,
де у – рівень динамічного ряду
n – кількість рівнів (довжина динамічного ряду).
Ряди динаміки дозволяють охарактеризувати розвиток явища в часі, виявити тенденції зміни, а також за цими даними побудувати прогноз на наступний період лише в тому разі, коли вони правильно побудовані.
Основними правилами побудови й аналізу рядів динаміки є:
1.Періодизація розвитку.
2.Порівнянність рівнів ряду.
3.Відповідність розміру інтервалу інтенсивності розвитку явища.
4.Підпорядкованість динамічного ряду у часі.
Періодизація розвитку означає розтин явища, яке вивчається, у часі на однорідні етапи, в межах яких показник підкоряється одному закону розвитку. По своїй суті періодизація розвитку – це типологічне групування у часі.
Порівнянність рівнів ряду повинна витримуватися за колом об’єктів, які підлягають дослідженню за територією (просторова порівнянність) за одиницями виміру за часом реєстрації за методологією розрахунків тощо.
Рівні рядів динаміки формуються в результаті зведення та групування статистичних даних, а також їх обробки за різні проміжки часу. Головне, щоб рівні характеризували дійсну зміну величини показника, а не були пов’язані із змінами їх обчислення. Важливо, щоб зміни в явищі, яке аналізується за допомогою рівнів динамічного ряду, були обумовлені природою самого явища,
ане змінами, наприклад, у методиці обчислення показників чи іншими причинами, які можуть істотно вплинути на рівень показника ряду динаміки.
Ряд динаміки об’єктивно відображає тенденцію розвитку лише за умови порівнянності між собою його рівнів. Порівнянність всіх рівнів ряду між собою є основною вимогою при побудові рядів динаміки. Порівнянність рівнів ряду повинна забезпечуватися:
за періодами часу;
за критичним моментом (для явищ із сезонними коливаннями);
за територією;
за колом охоплюваних одиниць (наприклад, зміна підпорядкованості об’єктів, відомчої приналежності);
за методологією обчислення показника (наприклад, чисельність робітників на підприємстві в одні роки визначалася на початок кожного року,
ав інші - як середньорічна чисельність);
за одиницями виміру (наприклад, за роки незалежності в Україні як грошова одиниця виміру використовувалися рублі, карбованці. купони, гривні).
Непорівнянність показників ряду динаміки може бути викликана різними причинами і умовами. Такими причинами можуть бути територіальні зміни,
89
зміни кількості підприємств, які входять до одного виробничого об’єднання, зміни одиниці виміру (наприклад, грошова реформа) тощо. Для приведення у порівнянний вигляд використовують прийом "зімкнення рядів динаміки". Його сутність полягає в об'єднанні в один ряд (більш тривалий) двох або кількох рядів динаміки, рівні яких розраховані за різними методологіями або за різними територіальними межами. Виконується це через коефіцієнти перерахунку (1 метод) або шляхом заміни абсолютних величин відносними (2 метод).
Коли рівні ряду за різні періоди часу відрізняютья методикою їх визначення, то зімкнення РД виконують, приводячи обидві їх частини до одніє методики. (Наприклад, якщо одна частина РД представлена моментним показником на початок або на кінець відповідних періодів часу, а друга – інтервальним показником у вигляді середньої величини за відповідний період часу, то для зімкненя такого РД першу частину необхідно теж визначити у вигляді середніх величин – середньорічних, середньоквартальних або середньомісячних).
Для здійснення зімкнення рядів необхідно, щоб для одного з періодів (перехідного) існували дані, які було розраховано за різними методологіями або в різних межах (умови прикладу наведені в таблиці 7.1).
Реалізована продукція об’єднання ”Онікс”, млн. грн. |
Таблиця 7.1 |
||||||
|
|
||||||
|
|
|
|
|
|
|
|
Рік |
1999 |
2000 |
2001 |
2002 |
2003 |
|
2004 |
Продукція 5 |
20 |
26 |
30 |
- |
- |
|
- |
підприємств |
|
||||||
|
|
|
|
|
|
|
|
Продукція 8 |
- |
- |
45 |
50 |
52 |
|
54 |
підприємств |
|
||||||
|
|
|
|
|
|
|
|
1 метод – з використанням коефіцієнтів перерахунку.
Коефіцієнт - сумірник зміни обсягу реалізації продукції за рахунок збільшення кількості підприємств у складі об’єднання ”Онікс” дорівнює:
Ксум = 45 : 30 = 1,5.
Далі коригуємо дані за 1999 та 2000 роки:
Q1999 = 20 · 1,5 = 30 млн. грн.; Q2000 = 26 · 1,5 = 39 млн. грн..
Зімкнений ряд динаміки, за яким можна виконувати аналіз, наведено у таблиці 7.2.
Таблиця 7.2
Динаміка реалізації продукції об’єднанням ”Онікс”, млн. грн. (зімкнений РД із врахованим коефіцієнтом - сумірником)
Рік |
1999 |
2000 |
2001 |
2002 |
2003 |
2004 |
|
Продукція 8 |
30 |
39 |
45 |
50 |
52 |
54 |
|
підприємств |
|||||||
|
|
|
|
|
|
90

2 метод - заміна абсолютних рівнів відносними.
За 1999р. значення буде дорівнювати 20 = 0,667;
30
за 2000 рік - |
26 |
= 0,867 і т.д. |
|
30 |
|||
|
|
Зімкнений за цим методом ряд динаміки, за яким можна виконувати аналіз, наведено у таблиці 7.3.
Таблиця 7.3
Динаміка реалізації продукції об’єднанням ”Онікс”, млн..грн. (зімкнений РД у відносних одиницях)
Рік |
1999 |
|
2000 |
|
|
2001 |
|
2002 |
2003 |
2004 |
|||||||||||
Продукція 8 |
|
20 |
= |
|
26 |
= |
|
30 |
45 |
|
|
|
50 |
= |
|
52 |
= |
|
54 |
= |
|
підприємств |
30 |
|
|
30 |
|
|
|
або |
|
|
=1,000 |
45 |
|
45 |
|
45 |
|
||||
|
|
|
|
30 |
|
||||||||||||||||
=0,667 |
|
0,867 |
|
45 |
|
|
=1,111 |
=1,156 |
1,200 |
||||||||||||
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7.2.Види рядів динаміки та їх особливості
Економічні та соціальні явища дуже різні і тому вони можуть бути представлені у хронологічному порядку у вигляді різних рядів динаміки. Класифікація рядів динаміки за чотирма напрямками представлена на рис. 7.1.
Залежно від статистичної природи показника, який відображає рівень ряду, розрізняють динамічні ряди первинних та похідних показників, абсолютних, середніх та відносних величин.
Ряди динаміки первинних показників – це такі ряди, рівні яких характеризуються даними спостереження.
Ряди динаміки похідних показників – це такі ряди, рівні яких відображені показниками, розрахованими на основі первинних даних.
Ряди динаміки абсолютних величин – це такі ряди динаміки, в яких рівні ряду наведені у вигляді реально існуючих іменованих показників. Вони дають підсумкову характеристику розвитку явища, наприклад, кількість зареєстрованих злочинів обсяг виробленої продукції обсяг проданого товару кількість працюючих на підприємстві тощо.
Ряди динаміки відносних величин – це такі ряди динаміки, в яких всі рівні ряду наводяться у відносних величинах. Вони дають характеристику розвитку явища в їх взаємозв’язку та взаємовідносинах один з одним та виражаються у відсотках, проміле або продециміле. Ці ряди можна використовувати для аналізу структурних зрушень у розвитку явища, які інакше встановити складно. Наприклад,
вивчити зміни питомої ваги певного виду продукції на підприємстві без побудови ряду динаміки відносних величин дуже важко.
Ряди динаміки середніх величин – це такі ряди динаміки, в яких рівні ряду наведені у вигляді середніх показників. Ці ряди дають змогу дослідити зміну середніх показників у часі. Наприклад, за декілька років можна проаналізувати зміну кількості вогнепальної зброї, яка припадає на одну групу
91

злочинців, щоб охарактеризувати зміну озброєності злочинців проаналізувати середню продуктивність праці на підприємстві тощо.
Залежно від характеру явища, яке вивчається, рівні ряду динаміки можуть відноситися або до окремих проміжків часу, або до конкретної дати (моменту) часу. Відповідно до цього динамічні ряди діляться на інтервальні та моментні.
РЯДИ ДИНАМІКИ
За характером |
|
|
рівнів ряду |
Інтервальні |
Моментні |
|
За кількістю показників
Одномірні Багатомірні
Паралельні |
|
Взаємопов’язаних |
|
|
показників |
За повнотою часу
Повні |
Неповні |
Абсолютних величин
За способом вираження рівнів ряду
Відносних величин
Середніх величин
Рис. 7.1. Класифікація рядів динаміки
92
Рівень моментного ряду фіксує стан явища на певний момент часу t.
Наприклад, кількість робітників та службовців підприємства на 1 січня число поданих заяв від абітурієнтів до вищого навчального закладу на 5 липня курс валюти на певну дату тощо.
Відмінною особливістю моментного динамічного ряду є те, що його рівні не можна безпосередньо підсумовувати. Підсумовування рівнів моментного ряду не має сенсу, тому що окремі значення показника можуть бути присутні в декількох рівнях.
В інтервальному ряді рівень виступає як агрегований результат процесу, тобто визначає його обсяг за певний проміжок часу. Кількісне вираження рівня в цьому випадку залежить від тривалості часового інтервалу. Так, виробництво електроенергії за рік значно більше ніж за місяць обсяг продукції, виготовленої на підприємстві за тиждень, менше ніж за місяць урожай, зібраний за день, менше урожаю, зібраного протягом тижня тощо. Слід мати на увазі, що й похідні показники, які обчислюються на основі інтервальних рядів, на відміну від моментних також залежать від тривалості інтервалу часу. Так, середньодобове виробництво електроенергії на душу населення значно менше середньорічного.
Таким чином, характерною особливістю інтервальних рядів динаміки є те, що їх рівні завжди одержуються підсумовуванням рівнів за якісь проміжки часу, тобто величина рівнів інтервального ряду залежить від тривалості проміжку часу, за який обчислюються показники. Чим більший інтервал часу взято, тим більшим буде рівень динамічного ряду. За кількістю показників динамічні ряди діляться на одномірні та багатомірні.
Одномірні динамічні ряди характеризують зміну одного показника. Багатомірні динамічні ряди характеризують зміну двох і більше показників. В свою чергу, багатомірні ряди діляться на два види: паралельні ряди та ряди взаємопов’язаних показників.
За повнотою часу, який відображений у рядах динаміки, їх можна поділити на повні, неповні та накопиченим підсумком (кумулятивні).
Вповних рядах динаміки моменти або періоди часу йдуть один за одним
зрівними інтервалами часу, наприклад, кількість працюючих на перше число
кожного місяця результати фінансово-економічної діяльності підприємства на початок року тощо.
В неповних рядах динаміки така послідовність між проміжками часу не додержується. Прикладом цього може бути вивчення руху кількості працюючих (не кожен день хтось зараховується на роботу і не через якийсь певний час відраховується з роботи) або зміни кількості осіб, які відбувають покарання у вигляді позбавлення волі (вони обов’язково прибувають в місця позбавлення волі по етапу, про цей день хоча й повідомляють заздалегідь адміністрацію виправно-трудового закладу, але не через певні інтервали часу, а за потребою).
У кумулятивних рядах динаміки рівні ряду відображаються результатами розвитку явища за певний час (в органах внутрішніх справ звітність подається лише таким чином: спочатку за січень, потім за два місяці,
93

потім за три, чотири і так далі). Застосування таких рядів дає змогу одразу отримати дані за звітний період з початку року.
7.3.Статистичні характеристики часових рядів: абсолютний приріст, темп зростання, темп приросту, абсолютне значення
1% приросту; їх взаємозв’язок
Рядом динаміки є ряд послідовних рівнів, при співставленні яких між собою можна отримати характеристику швидкості та інтенсивності розвитку явища. У результаті такого порівнювання рівнів отримують систему абсолютних та відносних показників динаміки. Виконання розрахунків при цьому можливо у двох варіантах, які схематично представлені на рис. 7.2.:
o 1-й варіант - кожний рівень ряду динаміки порівнюється безпосередньо з попереднім, і таке порівняння називається порівнянням із змінною базою,
а розраховані показники –ланцюговими характеристиками динаміки.
o 2-й варіант - кожний рівень ряду динаміки порівнюється з одним і тим же попереднім рівнем, який прийнято за базу порівняння. В якості базового рівня вибирають початковий рівень ряду динаміки, або рівень, з якого починається якийсь новий етап розвитку явища. Таке порівняння називається порівнянням з постійною базою, а розраховані показники – базисними характеристиками динаміки.
Розрахунок характеристик ряду динаміки
У0 
Змінна |
У1 |
Постійна |
|
база |
база |
||
порівняння |
У2 |
порівняння |
|
|
... |
|
|
|
... |
|
|
Ланцюгові |
Уi-1 |
Базисні |
|
Уi |
|||
характеристики |
характеристики |
||
динаміки |
Уn |
динаміки |
|
|
|
Рис. 7.2. Ланцюговий та базисний методи розрахунку характеристик ряду динаміки
де У0 – базисний рівень показника; Уt – рівень, що аналізується; Уt-1 – попередній рівень; Уn – кінцевий рівень показника.
Базисні показники характеризують кінцевий результат всіх змін у рівні ряду від періоду, до якого належить базисний рівень, до даного (і-го ) періоду.
94
Ланцюгові показники характеризують інтенсивність зміни рівня від періоду до періоду (або від дати до дати) в межах проміжку часу, що вивчається.
Абсолютний приріст (зменшення) t - це показник ряду динаміки, який характеризує на скільки одиниць змінився поточний рівень показника порівняно з рівнем попереднього або базового періоду. Абсолютний приріст із змінною базою виражає абсолютну швидкість зміни рівнів ряду динаміки. Розраховується абсолютний приріст як різниця двох рівнів динамічного ряду:
ланцюговий |
t |
= |
уt - yt -1, |
базисний |
t |
= |
yt - y0. |
Між ланцюговими та базисними |
показниками існує взаємозв’язок – сума |
||
ланцюгових абсолютних приростів дорівнює кінцевому базисному: |
|||
n |
|
|
|
( yt yt 1) yn y0 |
|||
1 |
|
|
|
Коефіцієнт зростання - це показник ряду динаміки, який показує:
у скільки разів зріс поточний (порівнюваний) рівень показника, що аналізується, порівняно з рівнем попереднього (базового) періоду – якщо значення коефіцієнту зростання Кt > 1;
яку частку становить поточний (порівнюваний) рівень показника до рівня попереднього (базового) періоду періоду – якщо значення коефіцієнту зростання Кt < 1;
що ніяких змін не відбулося - якщо значення коефіцієнту зростання Кt =1.
Коефіцієнт зростання Кt розраховується як відношення рівнів ряду і
виражається коефіцієнтом: |
|
ланцюговий |
К t = yt / y t--1, |
базисний |
К t = yt / y0 . |
Зв’язок між ланцюговими і базисними коефіцієнтами зростання полягає в тому, що добуток ланцюгових коефіцієнтів зростання дорівнює кінцевому базисному:
y1 |
|
y 2 |
|
y n |
|
y n |
. |
y 0 |
y1 |
y n 1 |
|
||||
|
|
|
y 0 |
||||
Темп зростання – це коефіцієнт зростання, але представлений у відсотках, тобто
Тр = Кt ∙ 100,
або для ланцюгових Тр = (yt / y t—1)·100,
для базисних Тр = (yt / y0)·100.
Темп приросту - це показник ряду динаміки, який показує на скільки відсотків змінився поточний (порівнюваний) рівень аналізованого показника
95
порівняно з рівнем попереднього або базового періоду. Його можна визначити як відношення абсолютного приросту до бази порівняння або безпосередньо на основі темпу зростання.
Для ланцюгових характеристик:
Тпр = 100 · t / y t—1 = 100 (yt – yt—1 ) / y t—1 = 100 (Кt – 1) = Тр - 100.
Аналогічно взаємопов’язані і базисні темпи приросту.
Абсолютне значення одного відсотка приросту — це відношення абсолютного приросту до відповідного темпу приросту або одна сота попереднього рівня. Абсолютне значення 1 % приросту показує, чого вартий 1% і розраховується як співвідношення абсолютного приросту й темпу приросту. Алгебраїчно це співвідношення дорівнює 0,01 рівня, взятого за базу порівняння:
А% = t / Тпр =( yt - y t—1)/ 100 (yt - yt—1)/ yt--1 = yt--1 / 100 = 0,01 yt—1.
Для базисних темпів приросту значення А% однакові, тому їх не розраховують.
7.4.Середні характеристики часового ряду
Середній рівень динамічного ряду - середня, обчислена на основі рівнів динамічного ряду. Особливості розрахунку залежать від виду ряду динаміки, він визначається як середня арифметична проста (якщо рівні ряду представлені інтервальними абсолютними величинами), середня арифметична зважена (якщо рівні ряду представлені моментними величинами із нерівними періодами часу між моментами) або середня хронологічна (якщо рівні ряду представлені моментними величинами із рівними періодами часу між моментами).
Середній або середньорічний абсолютний приріст - це показник ряду динаміки, який показує на скільки одиниць у середньому за одиницю часу (щорічно) за певний період змінювався рівень показника, що аналізується. Середній абсолютний приріст розраховується як середня арифметична проста з ланцюгових абсолютних приростів:
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t |
1 |
m |
|
|
|
У |
n |
У |
0 |
|
||
|
|
1 |
(У t |
У t 1 ) або |
|
|
||||||||
|
|
|
|
|
|
|
|
, |
||||||
m |
m |
|
n 1 |
|
|
|||||||||
|
|
|
1 |
|
|
|
|
|
|
|
||||
де m = n - 1 - число ланцюгових абсолютних приростів, n – число періодів (моментів) у ряду динаміки.
Середній або середньорічний темп зростання - це показник ряду динаміки, який показує скільки відсотків у середньому за одиницю часу (щорічно) за певний період становить зміна рівня показника, що аналізується.
Середній або середньорічний темп приросту - це показник ряду динаміки,
який показує на скільки відсотків у середньому за одиницю часу (щорічно) за певний період змінювався рівень показника, що аналізується. Ці показники краще розраховувати після визначення середнього або середньорічного коефіцієнта зростання (росту).
96

Середній коефіцієнт зростання розраховують за формулою середньої геометричної:
|
|
|
|
|
|
m |
|
m |
|
m |
y n |
|
|
|
||||||||
|
|
|
|
|
k |
k1 k 2 ... k m |
km |
|
|
|||||||||||||
|
|
|
|
|
y 0 |
|
|
|||||||||||||||
де m - число ланцюгових коефіцієнтів зростання; |
|
|
|
|||||||||||||||||||
m = n – 1. |
|
|
||||||||||||||||||||
|
Якщо відомий середній коефіцієнт зростання, то середній темп зростання |
|||||||||||||||||||||
та середній темп приросту визначають наступним чином: |
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
yn |
|
|
||
T р k 100%; |
Tпр T p 100% k 1 100% |
1 |
·100%. |
|||||||||||||||||||
m |
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y0 |
|
|
||
7.5.Оцінка прискорення (уповільнення) розвитку. Порівняльний аналіз динамічних рядів; коефіцієнти випередження та
еластичності, умови їх використання
Якщо абсолютна та відносна швидкість динаміки у межах періоду, що вивчається, неоднакова, порівнянням однойменних характеристик за різні інтервали часу вимірюється прискорення (уповільнення) динаміки.
Різниця абсолютних ланцюгових приростів ' = t - t--1 характеризує
абсолютне прискорення (+) чи уповільнення (-) динаміки.
Відносне прискорення — це відношення абсолютного прискорення до абсолютного приросту, прийнятого за базу ( Δ' / іб ) або це темп приросту абсолютного приросту. Розраховується тільки у випадку, якщо абсолютний приріст, прийнятий за базу порівняння, додатне число. Якщо інтервали часу неоднакові, використовують середні абсолютні прирости відповідних інтервалів.
При порівнюванні розвитку двох явищ використовують показники, що являють співвідношення базисних темпів зростання або темпів приросту за однакові відрізки часу за двома рядами динаміки. Ці показники називають
коефіцієнтами випередження:
А |
Б |
, або |
А |
Б |
. |
Кв = Тр |
/ Тр |
Кв = Тпр |
/ Тпр |
За допомогою цих показників порівнюють ряди динаміки, що мають однаковий зміст, але належать до різних територій або об’єктів, а також ряди динаміки різного змісту, що характеризують один і той же об’єкт.
Якщо ряди динаміки взаємопов’язані, тобто рівні їх являють собою фактор х та результат у, із співвідношення темпів приросту цих ознак визначають, на скільки відсотків змінюється результативна ознака у зі зміною факторної ознаки х на 1 %. За економічним змістом співвідношення темпів приросту є коефіцієнтом еластичності :
Кел = Тпр у / Тпр х.
Під час аналізу статистичних характеристик неповних рядів динаміки слід пам’ятати про зв’язок, що існує між базисними та ланцюговими абсолютними приростами та коефіцієнтами росту. Цей взаємозв’язок допомагає визначити характеристики за відсутні у ряді динаміки проміжки часу.
97
Тема 8. Виявлення і вимірювання тенденцій розвитку
План вивчення теми
8.1.Основні компоненти часових рядів. Основні методи виявлення та аналізу тенденцій розвитку
8.2.Рівняння тренду, етапи визначення та обґрунтування найпридатнішого функціонального виду, суть параметрів
8.3.Екстраполяція трендів як один із методів прогнозування рівнів соціально-економічних явищ
Після вивчення теми студенти повинні:
знати: принципи виявлення та аналізу тенденції розвитку, екстраполяції трендів як методу прогнозування рівнів соціально-економічних явищ;
уміти: обґрунтовано використовувати на практиці основні методи виявлення та аналізу тенденцій розвитку, прогнозувати розвиток шляхом екстраполяції тренду.
Бібліографічний список: [7 – 10; 17 - 22 ]
8.1. Основні компоненти часових рядів. Основні методи виявлення та аналізу тенденцій розвитку
Рівні ряду динаміки формуються під загальним впливом великої кількості факторів, дія яких може бути тривалою або короткочасною, вони можуть бути постійно діючими і випадковими, які з’являються під впливом різних обставин. Визначення основної закономірності зміни рівнів ряду у часі потребує її кількісного вираження, більш менш вільного від дії випадкових чинників.
Основна тенденція розвитку явища – це певний напрям його зміни, який характеризується детермінованою складовою ряду динаміки. Але крім впливу основних факторів, які і визначають конкретний вид невипадкової компоненти (тренд), на рівні ряду впливають випадкові фактори, що викликають відхилення фактичних значень рівнів ряду від тренда.
Рівень динамічного ряду можна представити функцією:
yt f (t) (t) ,
де f(t) – тенденція, зумовлена впливом постійно діючих факторів (тренд); ε(t) – величина, що визначає вплив випадкових коливань.
Однак, існує багато явищ, яким, крім вище названих, притаманні ще й так звані сезонні коливання. Рівень таких явищ рік у рік у певні місяці підвищується, а в інші – знижується. Наприклад, витрати палива у веснянолітні місяці значно більші, ніж у осінньо-зимові; виробництво та споживання напоїв або морозива має періодичний характер; перевезення пасажирів автомобільним чи залізничним транспортом; споживання електроенергії
98

у різні години доби, дні тижня, місяці року і т. ін.. Таким чином, компонентами динамічного ряду є тенденції (тренди), випадкові та, можливо, сезонні коливання.
Маючи справу із показниками ряду динаміки дослідник завжди намагається виявити головну закономірність розвитку явища в окремі проміжки часу. Це зводиться до виявлення головної тенденції, звільненої від дії різних випадкових факторів. З цією метою ряди динаміки піддають певній статистичній обробці, яка може бути елементарно простою, або більш складною, із застосуванням математичних методів. Завдання щодо їх використання зводиться до елімінування дії випадкових, другорядних причин, а також встановлення характеру дії основних причин, що визначають динаміку досліджуваного явища.
В деяких випадках тенденцію можна встановити за значеннями рівнів ряду динаміки. Наприклад, якщо рівні постійно збільшуються, чи зменшуються. Основні тенденції – зростання чи зниження – можна поділити за їх характером. Характер основної тенденції має певне графічне зображення
(див. рис. 8.1 – 8.3).
у
t
Рис. 8.1. Рівномірний характер основної тенденції: рівномірне зростання рівномірне зниження.
Характер основної тенденції можна також встановити за допомогою абсолютних ланцюгових приростів. Якщо абсолютні ланцюгові прирости мають додатні значення, динамічний ряд має тенденцію до зростання. Якщо абсолютні ланцюгові прирости мають від’ємні значення, динамічний ряд має тенденцію до зниження. Якщо абсолютні ланцюгові прирости мають однакові значення, то характер тенденції рівномірний (рівномірне зростання чи рівномірне зниження). Якщо кожен наступний ланцюговий приріст більше за попередній, то тенденція має прискорений характер. Якщо кожен наступний ланцюговий приріст менше за попередній, то тенденція має уповільнений характер.
99
0,7 |
|
|
|
|
|
|
|
|
|
|
|
0,6 |
|
|
|
|
|
|
|
|
|
|
|
0,5 |
|
|
|
|
|
|
|
|
|
|
|
0,4 |
|
|
|
|
|
|
|
|
|
|
|
0,3 |
|
|
|
|
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
|
|
|
|
|
|
0,1 |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
Рис. 8.2. Прискорений характер основної тенденції: прискорене зростання  прискорене зниження.
прискорене зниження.
0,7 |
|
|
|
|
|
|
|
|
|
|
|
0,6 |
|
|
|
|
|
|
|
|
|
|
|
0,5 |
|
|
|
|
|
|
|
|
|
|
|
0,4 |
|
|
|
|
|
|
|
|
|
|
|
0,3 |
|
|
|
|
|
|
|
|
|
|
|
0,2 |
|
|
|
|
|
|
|
|
|
|
|
0,1 |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
Рис. 8.3. Уповільнений характер основної тенденції: уповільнене зростання уповільнене зниження.
У разі, коли рівні динамічного ряду коливаються, то наочно виявити тенденцію розвитку явища не можна. Тоді для виявлення основної тенденції розвитку застосовують методи згладжування динамічного ряду або аналітичне вирівнювання ряду динаміки.
До найбільш простих методів згладжування динамічних рядів належать методи ступінчастої середньої та плинної середньої. Метод ступінчастої середньої (укрупнення інтервалів) полягає в тому, що рівні первинного динамічного ряду поєднуються в збільшені інтервали і розраховуються середні в кожному зі створених інтервалів.
Наприклад, утворюється новий динамічний ряд, в якому окремі інтервали
– це об’єднання трьох інтервалів первинного динамічного ряду. В такому разі середня кожного укрупненого інтервалу розраховується так:
100

у1 = (у1 + у2 + у3) : 3
у2 = (у4 + у5 + у6) : 3
у 3 = (у7 + у8 + у9) : 3 і т. д.
Суть методу середньої плинної полягає в тому, що середні обчислюються також за збільшеними інтервалами, але на відміну від попереднього методу здійснюється послідовне пересування меж збільшених інтервалів на один первинний інтервал до кінця динамічного ряду. У такому разі середні інтервалів розраховуються за формулами:
у1 = (у1 + у2 + у3) : 3
у2 = (у2 + у3 + у4) : 3
у 3 = (у3 + у4 + у5) : 3 і т. д.
Якщо значення рівнів похідного (згладженого) динамічного ряду не дають можливості встановити чітку тенденцію, проводять нове згладжування, при цьому беруть ще більші інтервали. Слід зауважити, що для об’єднання беруться інтервали первинного динамічного ряду. Згладжування повторюють доти, доки не виявиться чітка тенденція, або коли не залишиться три укрупнених інтервали, оскільки подальше згладжування вже не має сенсу. Через дві точки завжди можна провести лінію, але при цьому можна отримати результат, протилежний реальному стану.
8.2. Рівняння тренду, етапи визначення та обґрунтування найпридатнішого функціонального виду, суть параметрів
Якщо згладжування ряду динаміки не дає можливості виявити тенденцію розвитку або її характер, то відповідь на це питання можна напевне одержати за допомогою аналітичного вирівнювання заданого (вихідного) динамічного ряду методом найменших квадратів.
Метод аналітичного вирівнювання дає змогу не лише виявити тенденцію розвитку, а й кількісно виміряти її.
Під аналітичним вирівнюванням ряду динаміки у статистиці розуміють побудову функції Y = f(t), яка аналітично виражає залежність значень ознаки Y від часу t. Такі функції, а також їх графіки називають трендовими кривими. За допомогою трендової кривої завжди можна виявити основну тенденцію розвитку явища, що вивчається, а також її характер.
Процес побудови трендової кривої складається з двох етапів:
вибір виду функції f(t)
обчислення параметрів функції f(t).
Вид функції f(t) можна встановити візуально за кореляційним полем з урахуванням економічної (фізичної тощо) суті явища, що вивчається.
Кореляційне поле (див. рис. 8.4) являє собою координатну площину tOy із зображеними на ній точками з координатами (ti, yi).
101

Y
|
|
|
* |
* * |
* * |
|
|
|
* |
* * * |
* |
|
|
|
* * * |
* |
|
|
|
|
* * * * * |
|
|
|
* |
* * |
* * |
|
|
|
* |
* * |
* |
|
|
|
** |
|
|
|
|
* |
* |
|
|
|
|
0 |
t |
Рис. 8.4. Кореляційне поле
На практиці при виборі виду тренду перевага звичайно віддається функціям, параметри яких мають чіткий економічний зміст:
лінійна – у = a + bt – (a – середній початковий рівень ознаки, b – середній абсолютний приріст)
квадратична, або параболічна – y = a + bt + ct 2 – (a – середній
початковий рівень ознаки, b – |
середня початкова швидкість зростання, |
с – середній приріст швидкості зростання) |
|
показникові – y = a·b t |
– (a – середній початковий рівень ознаки, |
b – середній темп зростання).
Після вибору виду залежності її параметри обчислюються за методом найменших квадратів. Цей метод забезпечує такий вибір параметрів тренду, щоб мінімізувати суму квадратів відхилень фактичних значень рівнів ряду від теоретичних рівнів, що розраховані за відповідних значень t.
Найпростішою формулою, що відтворює тенденцію розвитку, є лінійна функція:
y t a 0 a1t
Параметри a0 та a1 згідно методу найменших квадратів знаходяться рішенням системи нормальних рівнянь:
a0 n a1 t ya0 t a1 t 2 yt ,
де y – фактичні рівні ряду
t – порядковий номер періоду або моменту часу.
Розв’язавши цю систему, отримуємо значення параметрів лінійної моделі:
102

a |
n yt y t |
|
a |
|
|
a t , |
|
, |
y |
||||||
|
|||||||
1 |
n t 2 t t |
0 |
|
|
1 n |
||
де у – середній рівень динамічного ряду.
Розрахунок параметрів значно спрощується, якщо за початок відліку часу (t = 0) обрати центральний інтервал. Із використанням спрощеного методу із введенням нумерації періодів часу від умовного нуля значення умовних періодів t залежать від того, парну чи непарну кількість рівнів має динамічний ряд.
Якщо число рівнів парне (наприклад, 6), умовні періоди мають значення, наведені в табл. 8.1.
Таблиця 8.1
Значення параметра t у разі введення умовного нуля для парної кількості рівнів динамічного ряду
Фактичний період |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
|
|
|
|
Умовний період |
– 5 |
– 3 |
– 1 |
1 |
3 |
5 |
|
|
|
|
|
|
|
Якщо число рівнів непарне (наприклад 7), умовні періоди мають значення, наведені в табл. 8.2.
Оскільки мета введення умовного нуля – максимальне спрощення розрахунків, то відстані між сусідніми рівнями динамічного ряду з умовними періодами мають бути мінімальними, проте однаковими впродовж усього ряду. Таким чином, у разі парної кількості рівнів динамічного ряду відстані між будьякими двома рівнями з умовними періодами дорівнюють двом; у разі непарної кількості рівнів динамічного ряду відстані між будь-якими двома рівнями з умовними періодами дорівнюють одиниці. Умовні періоди, розташовані ліворуч умовного нуля, набувають від’ємних значень, а ті, що розташовані праворуч – додатних.
Таблиця8.2
Значення параметра t у разі введення умовного нуля для непарної кількості рівнів динамічного ряду
Фактичний період |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
|
|
|
|
|
|
Умовний період |
– 3 |
– 2 |
– 1 |
0 |
1 |
2 |
3 |
|
|
|
|
|
|
|
|
Незалежно від кількості рівнів у динамічному ряді з умовними періодамиt = 0, а тому система нормальних рівнянь для лінійної моделі тренду матиме такий вигляд:
103
|
|
y n a 0 . |
||
|
|
|
|
|
|
|
yt a |
|
t 2 |
|
1 |
|||
|
|
|
|
|
Тоді параметри а0 та а1 для лінійної моделі тренду розраховуються за формулами:
a 0 |
y |
a1 |
|
yt |
|||
|
; |
|
|
|
. |
||
|
t |
2 |
|||||
|
n |
|
|
|
|
||
Якщо у трендовій моделі використовуються нелінійні функції, то вони приводяться до лінійного вигляду за допомогою певних математичних перетворень. Так, степенева функція призводиться до лінійного вигляду за допомогою логарифмування, гіпербола – заміною змінної.
8.3.Екстраполяція трендів як один із методів прогнозування рівнів
соціально-економічних явищ
Зробити прогноз явища у означає обчислити значення ознаки Y на той майбутній період часу t, який нас цікавить. Очевидно, що будь-який прогноз може бути тільки наближеним і може вважатись реальним тільки за умови збереження у майбутньому тенденції розвитку явища та її характеру. Метод прогнозування на періоди за межами ряду динаміки (на майбутнє або за минулі періоди часу) називають екстраполяцією. Метод прогнозування на періоди пропущених періодів часу в середині ряду динаміки називають інтерполяцією.
Точковий прогноз здійснюється за допомогою екстраполяції трендової моделі, тобто прогнозоване значення явища обчислюється за встановленою формулою. При цьому слід мати на увазі той факт, що рівняння трендової кривої побудоване з використанням умовних періодів, а тому для визначення точкового прогнозу вводиться наступний період. Наприклад, якщо динамічний ряд містить шість періодів, то точкова оцінка розраховується для наступного, сьомого періоду (див. табл. 9.1) якщо динамічний ряд містить сім періодів, то точкова оцінка розраховується для наступного (умовного) четвертого періоду
(див. табл. 9.2).
Інтервальний прогноз являє собою інтервал значень ознаки у, який із заданою ймовірністю покриває (або має покривати) справжнє значення:
y y t t S Yt ,
де уt – точковий прогноз
t – довірче число, яке обирається з таблиць розподілу Стьюдента (якщо кількість рівнів динамічного ряду менше 30) або з таблиць нормального розподілу (якщо кількість рівнів динамічного ряду більша за 30)
SYt – залишкове середнє квадратичне відхилення.
Залишкове середнє квадратичне відхилення розраховується за формулою:
104

S Yt |
|
|
Y Yt 2 , |
|
|
n m |
|
||
де Y – фактичні рівні досліджуваного динамічного ряду
Yt – теоретичні значення трендової моделі у відповідні періоди n – кількість рівнів динамічного ряду
m – число параметрів трендової моделі (для лінійної моделі m = 2).
Такий інтервал називають довірчим інтервалом, а відповідну ймовірність
– довірчою ймовірністю.
На відміну від точкового інтервальний прогноз може розроблятися лише на наступний період .
105
Тема 9. Індексний метод
План вивчення теми
9.1.Суть індексів і їх роль в аналізі соціально-економічних явищ. Класифікація індексів
9.2.Індивідуальні індекси
9.3.Методологічні принципи побудови зведених індексів; агрегатні та середньозважені індекси
9.4.Індексний метод економічного аналізу кількісного впливу чинників на наслідок
9.5.Дослідження динаміки середніх величин індексним методом: індекси середніх величин змінного складу, фіксованого складу і структурних зрушень; їх взаємозв’язок
Після вивчення теми студенти повинні:
знати: сутність і функції індексів; методологічні принципи побудови зведених індексів, умови використання індексів агрегатної форми та середньозважених індексів; системи взаємопов’язаних зведених індексів та індексів середніх величин;
уміти: обґрунтовано використовувати на практиці різні види та системи взаємопов’язаних індексів для аналізу динаміки складних соціальноекономічних явищ; оцінювати абсолютні та відносні ефекти впливу чинників на динаміку індексованих показників.
Бібліографічний список: [7 – 10; 17 - 22 ]
9.1.Суть індексів і їх роль в аналізі соціально-економічних явищ.
Класифікація індексів Індекс - це узагальнюючий відносний показник, що характеризує зміну рівня
будь-якого явища чи процесу в часі, просторі чи порівняно з планом, нормою, стандартом. Індекси найчастіше використовують під час аналізу динаміки складних економічних явищ, які можуть бути представлені певними групами неоднорідних елементів, кількісні характеристики яких безпосередньо не піддаються додаванню.
Як відносна величина індекс подається у формі коефіцієнта або процента (якщо одержану величину коефіцієнта помножити на 100 %). Назва індексу відбиває його соціально-економічний зміст, а числове значення – інтенсивність зміни або ступінь відхилення (від норми, плану, стандарту).
Індекси застосовують для порівняльної характеристики сукупності в часі, для порівняння фактичного рівня з планом, для порівняння рівнів виробництва продукції, цін, продуктивності праці в різних регіонах, на різних підприємствах, для різних товарів. Їх застосовують для оцінки ролі окремих факторів у зміні складних подій та явищ, динаміки середніх показників, зміна яких залежить від структурних зрушень. За допомогою індексу, вираженого у процентах, можна визначити на скільки відсотків змінилося досліджуване явище. Крім того, за допомогою індексу можна визначити не лише відносні зміни, а й абсолютні зміни як явища в цілому (наприклад, зміни товарообігу), так і зміни явища під впливом факторів. Так, зведений індекс цін
106
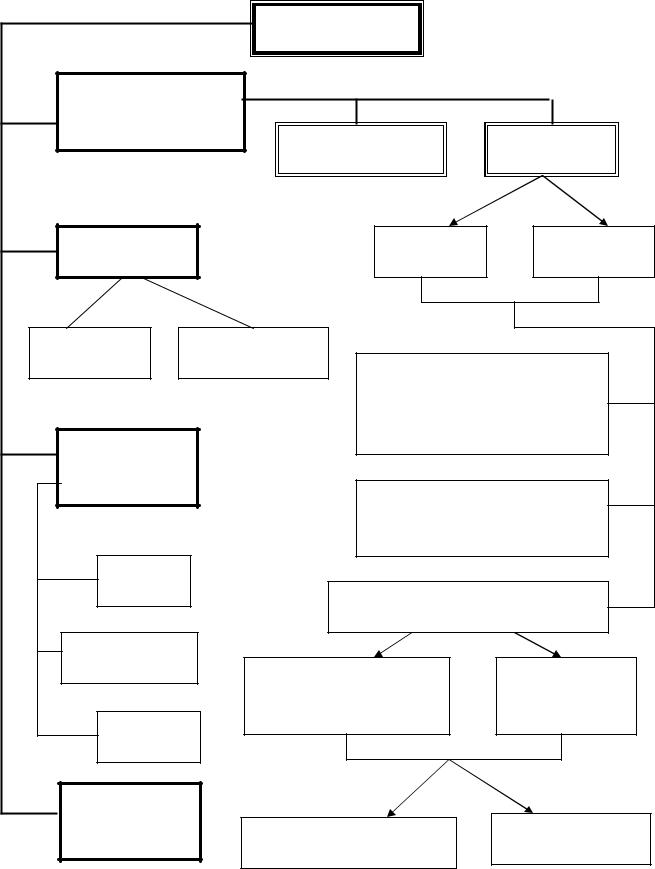
характеризує зміни товарообігу під впливом зміни цін на окремі види товарів, а індекс |
||||
фізичного обсягу характеризує зміни товарообігу під впливом змін кількості проданих |
||||
товарів певного виду. Класифікація індексів наведена на рис. 9.1. |
|
|||
|
|
ІНДЕКСИ |
|
|
За мірою |
|
|
|
|
охоплення явища |
|
|
|
|
чи процесу |
Індивідуальні |
Зведені |
||
|
|
|||
За базою |
|
|
Загальні |
Групові |
порівняння |
|
|
|
|
Динамічні |
Територіальні |
|
|
|
|
|
Індекси середніх величин: |
||
|
|
фіксованого складу; |
||
|
|
змінного складу; |
||
За періодом |
|
|
структурних зрушень |
|
|
|
|
|
|
розрахунку |
|
|
|
|
|
|
|
За формою побудови: |
|
|
|
агрегатні; |
|
|
|
|
|
середньозважені |
|
Річні |
|
|
|
|
|
|
За видом ваги-порівнювача |
||
Квартальні |
|
|
|
|
|
|
з постійними |
|
базисні; |
|
|
вагами; |
|
ланцюгові |
Місячні |
|
із змінними вагами |
|
|
|
|
|
|
|
За об’єктом |
|
|
|
|
дослідження |
|
Індекси об’ємних |
Індекси якісних |
|
|
|
|||
|
|
показників |
показників |
|
Рис. 9.1. Класифікація індексів |
|
|
||
107
Історично індекси створювалися як інструмент вивчення динаміки споживчих цін. Поступово коло показників, що піддавалися індексному аналізу, розширювалося, а методи аналізу вдосконалювались.
Вирізняють дві функції індексів:
1)синтетичну, пов’язану з побудовою узагальнюючих характеристик динаміки чи просторових порівнянь;
2)аналітичну, спрямовану на вивчення закономірностей динаміки, функціональних взаємозв’язків, структурних зрушень.
9.2. Індивідуальні індекси
Індивідуальні індекси - відносні показники, які характеризують зміну в динаміці або відображають співвідношення в просторі якогось одного виду одиниць явища. Індивідуальний індекс позначають і з відповідним умовним позначенням економічного показника, що індексується.
Наприклад:
при індексації кількісних показників
q – кількість проданого товару (фізичний обсяг продукції, що виготовлена) певного виду в натуральному вираженні; Ч, T – середньо облікова чисельність працівників або загальна кількість відпрацьованих людино-годин чи людино-днів; S – розмір посівної площі;
при індексації якісних показників
p – ціна одиниці товару чи продукції; z – собівартість одиниці продукції; t – трудомісткість виробництва одиниці продукції; w – продуктивність праці
– середній випуск продукції в розрахунку на одного працівника чи за один людино-день – w=1/ t; y – урожайність певної культури в центнерах із 1 га.
показники, що отримані як добуток якісного та кількісного показника (результативні показники):
Q = pq –загальна вартість проданого товару певного виду (товарообіг) або вартість випущеної продукції, грн.;
Z = zq – загальна собівартість продукції певного виду, тобто витрати на її виробництво, грн.;
Т = tq – загальні витрати робочого часу на виробництво продукції, год.; ВЗ = ∙у S– валовий збір урожаю, ц.
В індексах, що характеризують динаміку показника, попереднє значення величини, що береться за базу порівняння, позначається підрядковою позначкою "0", а поточне значення - "1".
Наприклад, індивідуальний індекс ціни ір, індивідуальний індекс кількості (фізичного обсягу продукції або продаж) іq, індивідуальний індекс товарообігу або вартості виробленої продукції іpq можуть бути представлені наступним чином (більш детально дивіться табл. 10.1.):
108
i p |
p1 |
; |
iq |
|
q1 |
; |
i pq |
|
p1 q1 |
, |
|
|
|||||||||
|
|
|
||||||||
|
p0 |
|
|
q0 |
|
|
p0 q0 |
|||
При цьому іpq = ір∙ |
іq , |
тобто цю формулу можна розглядати як |
||||||||
двофакторну індексну мультиплікативну модель товарообігу, що характеризує динаміку товарообігу під впливом кожного чинника (р та q) зокрема.
9.3. Методологічні принципи побудови зведених індексів; агрегатні та середньозважені індекси Зведений (загальний) індекс - показник, який характеризує динаміку
складного явища, елементи якого не піддаються безпосередньому підсумовуванню в часі, просторі чи порівняно з планом. Зведені індекси - це співвідношення рівнів показника, до складу якого входять неоднорідні елементи (обсяг продукції, виробленої на підприємстві; ціна одиниці кількох видів товару).
Зведені індекси можуть бути за мірою охоплення явища чи процесу загальними чи груповим, а за формою побудови – агрегатними (основна форма) чи середньозваженими (похідна форма).
Методологічні принципи побудови агрегатних індексів
При агрегуванні сукупності елементів, що мають різні одиниці виміру, їх фізичні обсяги qi приводять до порівнянного виду за допомогою певних показників-сумірників. Використовують сумірники якісного характеру (найчастіше це ціна, собівартість, трудомісткість одиниці продукції), тоді агрегатом буде ∑ piqi, або ∑ ziqi, або ∑ tiqi .
Етапи побудови агрегатного індексу:
1.Записуємо позначення зведеного індексу I.
2.Праворуч від індексу (трохи нижче) - умовне позначення індексованого показника, наприклад, Ір – загальний індекс ціни.
3.Знаки "=", ділення /.
4.У чисельнику і знаменнику ставимо знак суми Σ .
5.У чисельнику записуємо індексований показник, зафіксований на рівні звітного року, а в знаменнику - на рівні базового року.
6.Визначаємо показник, який буде виступати в ролі сумірника, тобто ваги: для індексованих кількісних показників вагою виступають якісні показники, і навпаки - для індексованих якісних показників вагою виступають кількісні показники.
Примітка. Якщо в ролі ваги виступає кількісний показник, то він фіксується на рівні звітного періоду, а якщо якісний – то на рівні базового періоду.
7.У чисельнику і знаменнику записуємо поряд з індексованим показником показник сумірності (ваги) (див. п. 6).
Аналогічно будуються індекси усіх показників (див. табл. 9.1).
109
Зведений індекс товарообігу показує у скільки разів збільшився товарообіг у поточному періоді порівняно з базисним періодом (або яку частку становить товарообіг поточного періоду від його обсягу у базисному періоді, якщо значення індексу менше за "1"):
I pq p1q1p0q0
Агрегатний індекс ціни - на основі даного індексу обчислюють відносну характеристику економії або перевитрат коштів населення на придбання товарів за рахунок зміни цін:
I p p1q1 ,p0q1
де Σ p0 q1 - умовна величина, що показує, яким був би товарообіг у звітному році, якби ціни не змінились.
Агрегатний індекс кількості проданого товару (фізичного обсягу випуску продукції) - показує як змінився товарообіг під впливом зміни кількості реалізованого товару (фізичного обсягу випущеної продукції):
Iq p0q1 .p0q0
Але не завжди за умовами дослідження відомі значення якісних і кількісних показників за базовий та звітний періоди. За відсутності таких даних, коли відомі дані лише про значення результативної ознаки та індивідуальні індекси якісного чи (та) кількісного показника, для аналізу динаміки результативної ознаки в цілому по сукупності та виявлення впливу на неї окремих чинників використовують не агрегатну форму зведеного індексу, а середньозважену.
Агрегатний індекс перетворюють у середній з індивідуальних індексів
(середньозважений індекс), підставляючи у чисельник або знаменник агрегатного індексу замість індексованого показника його вираз, який виводиться з формули відповідного індивідуального індексу.
Наприклад, з урахуванням вищесказаного середньозважені індекси ціни та кількості проданих товарів будуть дорівнювати (див. табл. 10.1):
ip |
|
p1 |
; |
p0 |
|
p1 |
; |
I p |
p1q1 |
= |
|
p1 q1 |
|
, |
|
|
||||||||
|
|
p1 q1 |
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
p0 |
|
|
ip |
|
p0q1 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
i p |
|
|
|
|
|||||||||||||
iq |
|
q1 |
; |
q1 q0 iq ; |
I q |
p0q1 |
|
= |
|
p0q0 iq |
. |
|||||||||||||
|
||||||||||||||||||||||||
|
|
|
|
|||||||||||||||||||||
|
p q |
|
|
|
|
|||||||||||||||||||
|
|
q0 |
|
|
|
|
|
|
0 |
|
|
|
|
p |
0 |
q |
0 |
|
||||||
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|||||
110
Таблиця 9.1 Методика розрахунку індивідуальних і зведених (загальних) індексів
агрегатної та середньозваженої форм
|
Назва |
Індивідуальні |
Загальні індекси |
Загальні індекси |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
індексу |
індекси |
|
|
|
|
|
агрегатні |
середньозважені |
|||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1. |
Індекс кількості |
iq |
|
q1 |
|
|
|
|
|
|
|
Iq |
|
|
p0q1 |
|
|
|
|
iq p0q0 |
|
|||||||||||||||||||||||||||||||||||
проданого товару |
|
|
|
|
|
|
|
|
|
|
|
|
Iq |
|
||||||||||||||||||||||||||||||||||||||||||
q0 |
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
p0q0 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
p0q0 |
||||||||||||||||||||||||||||||||||||||||||||||||
(фізичного обсягу |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||
випущеної продукції) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. |
Індекс цін |
|
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
|
|
|
|
|
|
|
p q |
|
|
|
|
p1 q1 |
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
i p |
|
|
|
|
|
|
|
|
I p |
|
|
|
|
|
|
|
I p |
|
|
|
p1 q1 |
|||||||||||||||||||||||||||||||||
|
|
|
p0 |
|
|
|
|
|
p |
|
|
q |
|
|
|
|||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ip |
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
3. |
Індекс товарообігу |
i pq |
|
|
p1 q1 |
|
I pq |
p1q1 |
|
|
-- |
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||
у фактичних цінах |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
p0 q0 |
p0q0 |
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||
(вартості продукції) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
4. |
Індекс |
iq |
|
q1 |
|
|
|
|
|
Iq |
|
|
z0q1 |
|
|
|
|
|
iq z0q0 |
|
|
|||||||||||||||||||||||||||||||||||
фізичного обсягу |
|
|
|
|
|
|
|
Iq |
|
|||||||||||||||||||||||||||||||||||||||||||||||
q0 |
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
z0q0 |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
продукції |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
z0q0 |
|||||||||||||||||||||||||||||||||||
( по собівартості) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5. |
Індекс |
iz |
|
|
z1 |
|
|
|
|
|
I z |
|
z1q1 |
|
I z |
|
|
z1 q1 |
|
|||||||||||||||||||||||||||||||||||||
собівартості |
z |
|
|
|
|
|
|
|
|
|
z |
|
|
q |
|
|
|
|
|
|
|
z1 q |
||||||||||||||||||||||||||||||||||
продукції |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
1 |
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
iz |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
6. |
Індекс витрат на |
|
|
|
|
|
z |
|
q |
|
|
|
|
|
|
|
z q |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
1 |
|
|
1 |
|
|
|
|
|
|
|
|
|
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
izq |
|
|
|
|
|
I zq |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
виробництво |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
z0q0 |
|
|
|
|
|
|
|
z0q0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
7. |
Індекс |
it |
|
|
|
|
|
t |
1 |
|
|
|
|
|
|
It |
|
|
|
|
|
t1q1 |
|
|
|
|
|
|
|
|
|
t1q1 |
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||
трудомісткості |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
It |
|
|
|
|
|
|
t1q1 |
|
||||||||||||||||||||||||||
продукції |
|
|
|
|
|
|
|
t0 |
|
|
|
|
|
|
|
|
|
|
|
t0q1 |
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
it |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
8. |
Індекс |
iw |
t0 |
|
|
|
|
|
|
|
|
|
|
|
t |
0 |
q |
|
|
|
|
|
|
t1q1 |
||||||||||||||||||||||||||||||||
продуктивності |
|
|
|
|
|
|
|
|
|
Iw |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
t |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
it |
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
t q |
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||
праці ( за |
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
I |
w |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
трудовими |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
1 |
|
|
|
|
|
|
|
|
|
|
t1q1 |
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
витратами) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
9. |
Індекс трудових |
|
|
|
|
|
t |
q |
|
|
|
|
|
|
|
t q |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
1 |
|
|
|
1 |
|
|
|
Itq |
|
|
|
|
|
|
|
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
витрат |
itq |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|||||||||||||||
t0q0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
t0q0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
111

Під час вивчення динаміки широко використовуються індексні ряди. Особливо, якщо під час економічного аналізу зміни величин, що індексуються, вивчають не за два, а за низку послідовних періодів.
База порівняння може бути постійною чи змінною, відповідно, індексні ряди – базисними чи ланцюговими. У системі базисних індексів порівняння рівнів показника, який індексується, в кожному індексі проводять з рівнем базисного періоду, а в системі ланцюгових індексів рівні показника, який індексується, порівнюється з рівнем попереднього періоду. Вибір бази порівняння залежить від мети дослідження. Ряди базисних індексів дають уявлення про загальну тенденцію явища, ряди ланцюгових індексів – докладнішу картину послідовних змін явища у часі.
Базисні та ланцюгові індекси можуть бути як індивідуальними, так і загальними.
Ряди індивідуальних індексів вартості продукції, фізичного обсягу продукції, цін прості у будуванні. Наприклад, візьмемо чотири послідовних періоди – 0, 1, 2 та 3 і побудуємо індексні ряди цін: p0 , p1, p2 , p3.
Базисні індекси: |
ip1|0 |
|
|
p1 |
; |
ip 2 / 0 |
|
p |
2 |
|
; |
ip3 / 0 |
|
p |
3 |
. |
|||
|
p0 |
p |
0 |
|
p |
0 |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Ланцюгові індекси: |
ip1 / 0 |
|
p1 |
|
; |
ip2 / 1 |
|
p2 |
|
; |
ip3 / 2 |
|
p |
3 |
. |
||||
p0 |
|
|
|
p |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
p1 |
|
|
|
2 |
|
|
||||
Між ланцюговими та базисними індивідуальними індексами існує зв’язок, який дає можливість переходити від одних індексів до інших.
Добуток послідовних ланцюгових індивідуальних індексів дорівнює базисному індексу останнього періоду:
ip3 / 0 ip1 / 0 ip2 / 1 ip3 / 2 |
|
p1 |
|
p2 |
|
p3 |
|
p3 |
. |
p0 |
p1 |
p2 |
|
||||||
|
|
|
|
|
p0 |
||||
Відношення базисного індексу звітного періоду до базисного індексу попереднього періоду дорівнює ланцюговому індексу звітного періоду:
|
|
ip3 / 0 |
|
p3 |
|
|
|
|
p3 |
|
|
ip3 / 2 |
|
|
p |
0 |
|
p |
|
|
. |
||
ip2 / 0 |
|
|
|
2 |
p2 |
||||||
|
|
|
|
|
|
p0 |
|
||||
|
|
|
|
|
|
|
|
|
|||
Це правило дає змогу застосовувати так званий ланцюговий метод, тобто визначати невідомий ряд базисних індексів, якщо відомі ланцюгові й навпаки.
112
Розглянемо можливість застосування ланцюгового методу обчислення для агрегатних індексів.
Відомо, що в кожному окремому індексі (якщо аналізується динаміка показника за рахунок змін якогось одного фактора) ваги у чисельнику та знаменнику обов’язково фіксуються на однаковому рівні (поточному чи базисному).
Якщо ж будується ряд індексів, то ваги в ньому можуть бути або постійними для всіх рівнів ряду, або змінними. Розглянемо будування базисних та ланцюгових індексів на прикладі агрегатних індексів цін.
Базисні індекси
Індекси цін Пааше:
I |
|
|
p1q1 |
; I |
|
|
p |
2 q2 |
; ...; I |
|
|
pn qn |
. |
|
p1 / 0 |
p0 q1 |
p2 / 0 |
p0 q2 |
pn / 0 |
p0 qn |
|||||||||
|
|
|
|
|
|
|
||||||||
Індекси цін Ласпейреса:
I |
|
|
p1 q |
0 |
; I |
|
|
p |
2 q0 |
; ...; I |
|
|
pn q0 |
. |
|
p1 / 0 |
p0 q0 |
p2 / 0 |
p0 q0 |
pn / 0 |
p0 q0 |
||||||||||
|
|
|
|
|
|
|
|||||||||
Ланцюгові індекси
Індекси цін Пааше:
I |
|
|
p1q1 |
; I |
|
|
p |
2 q2 |
; ...; I |
|
|
pn qn |
. |
|
p1 / 0 |
p0 q1 |
p2 / 1 |
p1 q2 |
pn / n 1 |
pn 1 qn |
|||||||||
|
|
|
|
|
|
|
||||||||
Індекси цін Ласпейреса:
I |
|
|
p1 q |
0 |
; I |
|
|
p |
2 q0 |
; ...; I |
|
|
pn q0 |
. |
|
p1 / 0 |
p0 q0 |
p2 / 1 |
p1 q0 |
pn / n 1 |
pn 1 q0 |
||||||||||
|
|
|
|
|
|
|
|||||||||
Як бачимо, в базисних агрегатних індексах усі звітні дані порівнюються лише з базисними (зафіксованими на початковому рівні) даними, а в ланцюгових – з попередніми (у даному випадку з суміжними) рівнями.
Період ваг в усіх індексах цін Пааше є плинний (індекси зі змінними вагами), в індексах цін Ласпейреса – зафіксований (індекси з постійними вагами).
Постійні ваги (які не змінюються від одного індексу до іншого) дають можливість вилучити вплив змін у структурі на значення індексу.
Ряди агрегатних індексів з постійними вагами мають перевагу: зберігається зв’язок між ланцюговими та базисними індексами:
p1q0 |
|
p2q0 |
|
p3q0 |
|
p3q0 |
. |
|
p0q0 |
p1q0 |
p2q0 |
p0q0 |
|||||
|
|
|
|
113
Таким чином, використання постійних ваг протягом низки років дозволяє переходити від ланцюгових загальних індексів до базисних і навпаки.
У рядах агрегатних індексів якісних показників, що будуються зі змінними вагами (наприклад, ряд цін Пааше), добуток ланцюгових індексів не дорівнює базисному:
p1q1 |
|
p2q2 |
|
p3q3 |
|
p3q1 |
. |
|
p0q1 |
p1q2 |
p2q3 |
p0q1 |
|||||
|
|
|
|
9.4.Індексний метод економічного аналізу кількісного впливу чинників на наслідок
Економічну сутність мають не тільки самі індекси, але й їхні чисельники та знаменники. Виходячи із системи взаємопов’язаних індексів можна визначити абсолютну зміну результативної величини в цілому та її величину, що сформувалася під впливом якісного або кількісного показника. Абсолютна зміна індексованої величини визначається за схемою, що пов’язана із відповідним індексом у агрегатній формі:
|
pq(q) = р0 ∙q1 |
- р0 q0; |
|
|
pq(p) = р1 q1 |
- |
р0 q1 ; |
pq |
= pq (q) + pq (p) = р1 |
q1 - р0 q0 . |
|
Взаємопов’язані між собою за економічною сутністю показники при їх індексації створюють систему взаємозалежних індексів.
Так як pq = p ∙ q, то маємо систему взаємозалежних індексів
І pq= Ір Іq,
Ірq = ( р1 q1 / р0 q1 ) х ( р0q1 / р0 q0 ) = р1 q1 / р0 q0 ;
І, відповідно, побудований на її основі - індексний факторний аналіз
pq = p q (q) + p q (p) =
=( р1 q1 - р0 q1) - ( р0q1 - р0 q0) = р1 q1 - р0 q0 .
9.5.Дослідження динаміки середніх величин індексним методом: індекси середніх величин змінного складу, фіксованого складу і структурних зрушень; їх взаємозв’язок
Середні величини характеризують узагальнений рівень певної ознаки, тому вони відіграють дуже важливу роль в економічному аналізі динаміки суспільних явищ і процесів. Порівняння середніх величин ознаки за різні періоди часу дає можливість вивчати не тільки масштаби зміни явища у часі, а й вплив чинників на зміну середньої величини. При цьому середня величина
114

змінюється як під впливом значень самого осереднюваного показника, так і під впливом зміни структури сукупності, тобто питомої ваги окремих одиниць сукупності в загальному їх обсязі. З цією метою використовують індексний метод, за яким індекс загальної зміни середньої величини розкладається на добуток двох індексів – фіксованого складу (сталої структури) Іх і структурних зрушень Іd:
I x I x I d
Рівень середньої залежить від значень ознаки хі та співвідношення ваг fi:
|
|
n |
f i |
|
|
|
|
x i |
m |
||
x |
|||||
n |
|
x i d i , |
|||
|
|
1 |
|
|
|
|
|
f |
i |
1 |
|
|
|
|
|
||
|
|
1 |
|
|
|
де fi - частота,
dі - частка i - ї складової сукупності.
Відповідно динаміка середньої визначається зміною значень хі та структурними зрушеннями dі . Оцінка впливу кожного з факторів здійснюється у рамках системи індексів середніх величин: змінного складу, фіксованого складу та структурних зрушень.
Індекс змінного складу (І x ) характеризує відносну зміну середньої величини в цілому за рахунок обох факторів: хі та dі.
|
|
|
|
|
x1 |
|
|
|
x1 f1 |
|
x0 f0 |
. |
|||
I |
|
|
|
|
|
|
|
|
|
: |
|
|
|
x1 d1 : x0 d0 |
|
|
|
|
|
f1 |
f0 |
|
|||||||||
x |
x0 |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||
Індекс фіксованого складу (Іх ) показує зміну середньої величини за |
|||||||||||||||
рахунок зміни тільки значень ознаки xi |
при незмінній структурі сукупності: |
||||||||||||||
|
|
I |
x |
|
x1 f1 |
: |
x0 f1 |
x1 d1 : x0 d1 |
|||||||
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
f1 |
|
f1 |
|
|
||||
Індекс структурних зрушень (Іd) показує зміну середньої за рахунок змін у структурі сукупності й обчислюється за формулою:
I |
d |
|
x0 f1 |
: |
x 0 f 0 |
x 0 d 1 : x0 d 0 |
|
f1 |
f 0 |
||||||
|
|
|
|
В індексі Іх ваги фіксуються на рівні поточного періоду, а у індексі Іd значення х - на рівні базового періоду. Такий принцип зважування забезпечує
зв’язок трьох індексів в систему Ix = Іх ∙ Іd.
Різниця між діленим і дільником кожного індексу дає можливість проаналізувати абсолютний приріст середньої величини в цілому та її
абсолютну зміну під впливом окремих чинників., тобто визначити x , |
x(x) |
||
та |
|
(d). |
|
x |
|
||
115
|
|
|
|
|
|
x1 f1 |
|
x0 |
f0 |
|
|
x1 d1 x0 |
d0 |
||||||||||
х |
|
|
|||||||||||||||||||||
|
f1 |
|
|
f0 |
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
( х ) |
|
x1 f1 |
|
x0 f1 |
x1 d1 x0 d1 |
|||||||||||||||
х |
|||||||||||||||||||||||
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
f1 |
|
|
|
|
|
f1 |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
x |
f |
1 |
|
x |
|
f |
0 |
x 0 d 1 |
x 0 d 0 |
|||||
х ( d ) |
|
|
0 |
|
|
|
0 |
||||||||||||||||
|
|
f1 |
|
|
|
|
f 0 |
|
|||||||||||||||
Різновидом індексів середніх величин є територіальні індекси, в яких середні рівні порівнюються за окремими територіями, об’єктами.
116
Змістовий модуль 4. Методи аналізу взаємозв’язків та подання статистичних даних
Тема 10. Статистичні методи вивчення взаємозв’язків явищ
План вивчення теми
10.1.Сутність та види взаємозв’язків явищ. Графічні методи вивчення кореляційного зв’язку
10.2.Метод аналітичних групувань і дисперсійний аналіз. Оцінювання щільності кореляційного зв’язку за даними аналітичного групування
10.3.Регресійно - кореляційний аналіз взаємозв’язку. Оцінювання щільності та перевірка істотності кореляційного зв’язку на основі рівняння регресії
Після вивчення теми студенти повинні:
знати: суть і види взаємозв’язків явищ; аналітичні можливості й передумови використання методу аналітичних групувань й дисперсійного аналізу, оцінювання щільності та перевірки істотності кореляційного зв’язку на основі рівняння регресії;
уміти: обґрунтовано використовувати на практиці різні методи аналізу взаємозв’язків між явищами відповідно до мети дослідження і наявної інформації.
Бібліографічний список: [7 – 10; 17 - 22 ]
10.1. Сутність та види взаємозв’язків явищ. Графічні методи вивчення кореляційного зв’язку
Закономірності економічних та соціальних процесів характеризуються взаємозв’язками між статистичними показниками. Статистичні показники перебувають у певних відношеннях між собою, виступаючи в ролі незалежних або залежних ознак, між якими існує причинно – наслідковий характер.
Суспільні явища, що впливають на інші явища, називають факторними, їх характеризують факторні ознаки (х). Явища, які змінюються під впливом факторних явищ, називаються результативними, їх характеризують
результативні ознаки (у).
Між явищами може існувати функціональний, стохастичний або кореляційний зв'язок. Функціональний зв'язок між явищами характеризується повною відповідністю між причиною і наслідком, факторною і результативною ознакою, тобто за цього зв'язку кожному можливому значенню факторної ознаки х відповідає чітко визначене значення результативної ознаки у. Такі зв'язки найчастіше зустрічаються у фізичних, хімічних явищах.
117

Стохастичний зв'язок виявляється зміною умовних розподілів, тобто за цього зв'язку кожному значенню ознаки х відповідає певна множина значень ознаки у, які варіюють і утворюють так званий умовний розподіл.
Якщо замінити умовний розподіл середньою величиною y , то утвориться
ознаки х відповідає середнє значення |
результативної ознаки y (які |
|||||||
обчислюються як середня арифметична зважена): |
при якому кожному значенню |
|||||||
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
yj |
f j |
||
|
yj |
|
1 m |
. |
||||
різновид стохастичного зв’язку – кореляційний, |
||||||||
|
|
|
|
|
f j |
|
|
|
|
|
|
|
1 |
|
|
|
|
Поступова зміна середніх |
|
j |
від однієї групи до іншої свідчить про |
|||||
y |
||||||||
наявність кореляційного зв'язку між ознаками. За кореляційного зв'язку, на відміну від функціонального, звичайно немає відомостей про повний перелік усіх ознак-факторів, які впливають на результативну ознаку, а також про точний механізм їх взаємодії з ним у вигляді тієї чи іншої математичної формули, функції.
Функціональні зв'язки виражаються тим чи іншим аналітичним рівнянням, кореляційні зв'язки можуть бути виражені за допомогою аналітичного рівняння лише приблизно.
Якщо залежність результативної ознаки від певної ознаки-фактора може бути виражена рівнянням прямої лінії, то зв'язок називається прямолінійним (лінійним), якщо ж залежність виражається рівнянням якої-небудь кривої (гіперболи, параболи та ін.), то зв'язок називається криволінійним.
Якщо досліджується залежність результативної ознаки тільки від однієї ознаки-фактора, то зв'язок називається однофакторним. Якщо при цьому зв'язок є функціональним, то це свідчить про те, що результативна ознака залежить тільки від певної ознаки. Якщо ж зв'язок є кореляційним, то включення в аналітичне рівняння тільки одного фактора свідчить про те, що від впливу інших факторів ми абстрагуємося, усуваємо їхню дію. Така кореляція називається парною, оскільки при цьому розглядаються тільки дві ознаки.
На відміну від функціональної залежності, кореляційний зв’язок є неповним, тому що залежність між функцією і аргументом у кожній ситуації перебуває під впливом ще й інших факторів. Кореляційна залежність проявляється тільки у масових явищах і може встановлюватися для пари показників (парна кореляція) або для декількох показників (множинна кореляція).
Лінія регресії може мати різні зображення: табличне, аналітичне та графічне. Як правило, графіки мають другорядне, переважно ілюстративне, значення, хоча на етапі теоретичного обґрунтування моделі значно спрощують її вибір.
Одним з найпростіших і наочних прийомів виявлення кореляційної залежності між двома ознаками та оцінки її характеру за незгрупованими
118

даними є графічна побудова так званого кореляційного поля та подальший аналіз його виду.
Для цього у системі координат за віссю абсцис розташовується значення одного показника, а за віссю ординат – іншого. Якщо точки розкидані по полю досить рівномірно, то це свідчить про відсутність зв’язку між показниками
(рис. 10.1).
Проте не завжди вигляд кореляційного поля допомагає визначитися з видом залежності між ознаками. Тоді використовують перебір функцій, тобто обчислюють рівняння регресії різних видів, а потім з них обирають найкраще. Як правило, це рівняння має найбільший коефіцієнт щільності зв’язку між ознаками, що вивчаються.
Y
|
* |
* |
|
* |
|
* |
* |
|
* |
* |
|
* |
|
* |
* |
* |
* |
* |
|
* |
|
* |
* |
* |
|
* |
|
* |
|
* |
* |
|
* |
* |
|
* |
|
* |
* |
|
* |
|
|
* |
* |
* |
|
* |
|
* |
* |
|
|
Х
Рис. 10.1. Кореляційне поле ознак Х та Y
Якщо існує певна залежність між ознаками, на це покаже скупчення точок
(рис. 10.2).
Y
|
|
* |
* * |
* |
* |
|
|
* |
* * * |
* * |
|
|
|
* * * |
* |
* |
|
|
|
* * * * * |
|
|
|
|
* |
* * * * |
|
|
|
* |
* |
* * |
|
|
|
** *
**
Х
Рис. 10.2. Кореляційне поле ознак Х та Y
Характеристикою кореляційного зв’язку є лінія регресії, яка розглядається у двох моделях: аналітичного групування та регресійного аналізу.
119
10.2.Метод аналітичних групувань і дисперсійний аналіз. Оцінювання щільності кореляційного зв’язку за даними аналітичного групування
Виявлення кореляційного зв’язку за допомогою аналітичного групування проводиться за такими етапами:
1. Теоретичне обґрунтування моделі аналітичного групування:
-вибір факторних ознак;
-визначення числа груп k ознаки-фактора xi;
-визначення меж інтервалів групування щодо xi.
Примітка. Групи мають бути достатньо чисельні й чисельність груп має бути приблизно однакова.
2. Оцінка лінії регресії:
-визначення частот (частостей) fi у групах;
-розрахунок у кожній групі за факторною ознакою середніх значень
результативної ознаки yi .
3. Вимірювання щільності зв'язку, що ґрунтується на правилі розкладання загальної дисперсії: загальна дисперсія 2 розкладається на
міжгрупову 2x та середню з групових дисперсій i2 і обчислюється за індивідуальними значеннями ознаки у.
Дисперсія, на відміну від інших характеристик варіації, є адитивною величиною. Тобто, у структурованій сукупності, яка поділена на групи за факторною ознакою Х, дисперсія результативної ознаки Y може бути розкладена на: дисперсію у кожній групі (внутрішньогрупову дисперсію) та дисперсію між групами (міжгрупову). Загальна дисперсія характеризує варіацію ознаки Y за рахунок впливу всіх причин (факторів) міжгрупова – за рахунок впливу фактора Х, покладеного в основу групування внутрішньогрупові – за рахунок усіх інших факторів, крім фактора Х.
Центром розподілу сукупності в цілому є загальна середня, яка обчислюється за формулою:
y y i fi ,
fi
де уі – індивідуальні значення окремої ознаки fi – частота окремої ознаки.
Центром розподілу в окремій j-й групі є групова середня, яка обчислюється за формулою:
120

|
|
|
y i j |
fi j |
, |
|
y j |
|
|||||
fi j |
||||||
|
|
|
|
|||
де уіj – індивідуальне значення окремої ознаки, яка потрапила до j-ї групи fi j – частота окремої ознаки, яка потрапила до j-ї групи.
Загальна дисперсія відображає варіацію ознаки у навколо загальної середньої та розраховується за формулою:
2 ( y i y ) 2 fi .
fi
Групова дисперсія відображає варіацію відносно групової середньої та розраховується за формулою:
|
2 |
|
( y i j |
y |
j |
) 2 fi j |
. |
j |
fi |
|
|
||||
|
|
|
j |
|
|
||
Оскільки в групи об’єднуються певною мірою схожі елементи сукупності, то варіація в групах, як правило, менша, ніж у цілому по сукупності. Якщо причинні комплекси, що формують варіацію в різних групах, неоднакові, то й групові дисперсії відрізнятимуться між собою. Узагальнюючою мірою внутрішньогрупової варіації є середня з групових дисперсій, яка обчислюється за формулою:
2 2j f j ,
f j
де 2j – групова дисперсія j-ї групи fj – обсяг j–ї групи.
Групові середні y j під впливом різних причинних комплексів також
виявляються різними. Мірою варіації групових середніх навколо загальної середньої є міжгрупова дисперсія, яка обчислюється за формулою:
2 y j y 2 f j .
f j
Таким чином, загальна дисперсія складається з двох частин, одна з яких характеризує внутрішньогрупову варіацію, а інша – міжгрупову. Взаємозв’язок між трьома дисперсіями дістав назву правила складання дисперсій, у деяких джерелах це правило називається правилом розкладання варіації. Розглянуті три дисперсії пов’язані таким рівнянням:
2 2 2 .
121

На цьому взаємозв'язку базується визначення коефіцієнта детермінації (або кореляційне відношення), який характеризує, наскільки варіація результативної ознаки залежить від ознаки, яка покладена в основу групування:
2
2 100%.
2
Наприклад, якщо у розподілі робітників фірми за рівнем освіти, результативною ознакою є місячна заробітна плата робітника, а визначений за результатами аналітичного групування і розрахунку міжгрупової та загальної дисперсій коефіцієнт детермінації дорівнює 48%, то це свідчить про те, що рівень заробітної плати робітника даної фірми на 48% залежить від рівня освіти, а на 100-48=52% - від всіх інших чинників, які не враховані у даному групуванні.
Емпіричне кореляційне відношення - це корінь квадратний з коефіцієнта детермінації. За абсолютним розміром він може змінюватись від 0 до 1. Якщо ή = 0, ознака групування не справляє впливу на результативну ознаку. Якщо ή = 1, зміна результативної ознаки цілком зумовлена ознакою групування, тобто між ними є функціональний зв'язок. Характеристика щільності зв’язку за рівнем емпіричного кореляційного відношення наведена у табл. 10.1.
Таблиця 10.1
Залежність між числовим емпіричним кореляційним відношенням та оцінкою щільності зв’язку
Емпіричне кореляційне |
Оцінка щільності зв’язку |
відношення |
|
0 – 0,1 |
Відсутній |
0,1 – 0,3 |
Слабкий |
0,3 – 0,5 |
Помірний |
0,5 – 0,7 |
Відчутний (помітний) |
0,7 – 0,9 |
Щільний (високий) |
0,9 – 0,999 |
Дуже щільний (надто високий) |
Якщо результативна ознака у зовсім не зв'язана з хі , то групові середні yi не будуть змінюватися зі зміною xі, тобто дорівнюватимуть одна одній і
дорівнюватимуть загальній середній y , а міжгрупова дисперсія 2x буде
дорівнювати нулю.
Якщо результативна ознака у функціонально зв'язана з ознакою-фактором xi, то в кожній групі внутрішньогрупова дисперсія i2 буде дорівнювати нулю,
оскільки ознака хі у середині групи не варіює. Середня з групових дисперсій
122

i 2 буде дорівнювати нулю, також згідно з правилом складання дисперсій
2x = 2y
4.Перевірка істотності зв'язку, тобто перевірка істотності відхилень групових середніх, яка здійснюється за допомогою критеріїв математичної статистики.
Перевірка істотності зв'язку ґрунтується на порівнянні фактичного
значення 2 з так званим критичним 21 (є таблиці критичних значень, де α -
рівень істотності).
21 |
є |
тим |
максимально |
можливим |
значенням |
кореляційного |
||||||
відношення, яке може виникнути випадково за |
відсутності |
кореляційного |
||||||||||
зв'язку. |
|
|
|
|
|
|
|
|
|
|
|
|
|
Для |
перевірки |
істотності |
зв'язку використовують також |
||||||||
функціонально пов'язаний із |
2 |
F-критерій (критерій Фішера) (F): |
||||||||||
F = [η2 / ( 1 - η2)]· k2 |
/ k1, |
або |
F |
|
2х |
k2 |
|
|
||||
|
|
|
|
|||||||||
|
|
|||||||||||
|
|
|
|
|
|
|
2 k1 |
|
||||
де k1, k2 - ступені свободи, |
k1= m – 1; |
k2 = n – m; |
|
|||||||||
де n – кількість одиниць сукупності; |
|
|
|
|
|
|
||||||
m – кількість груп за х. |
|
|
|
|
|
|
|
|
||||
Є таблиці критичних значень F-критерію ( F1-α, де α – рівень істотності). |
||||||||||||
Якщо η2 > η1-α2 |
або F > F1-α |
( k1, k2), то зв’язок між результативною і |
||||||||||
факторною ознаками вважається істотним. |
|
|
|
|
|
|
||||||
Якщо |
η2 |
< η1-α2 |
або F |
< F1-α ( |
k1, k2), |
то наявність зв’язку між |
||||||
результативною і факторною ознаками не доведено і зв’язок вважається неістотним, тобто можна стверджувати, що різниця між дисперсіями обумовлена впливом випадкових факторів.
До аналогічного висновку можна прийти за оцінкою надійності кореляційного відношення за t – критерієм Стьюдента, методика визначення якого буде розглянута далі (питання 3 даної теми).
10.3.Регресійно - кореляційний аналіз взаємозв’язку. Оцінювання щільності та перевірка істотності кореляційного зв’язку на
основі рівняння регресії
До основних завдань кореляційно - регресійного аналізу (КРА) належать:
постановка завдання, встановлення наявності зв’язку між досліджуваними ознаками;
вибір найістотніших факторів для аналізу;
123
визначення характеру зв’язку, його напряму і форми, вибір математичного рівняння для вираження існуючих зв’язків;
знаходження параметрів рівняння і показників тісноти зв’язку;
статистична оцінка достовірності отриманих результатів.
Вимоги до сукупності, що досліджується:
сукупність має бути якісно однорідна (основний метод забезпечення однорідності - групування);
сукупність повинна бути достатньо великою за обсягом, щоб у результаті дії закону великих чисел показники регресії і кореляції були достатньо надійними і стійкими, відображали об'єктивні закономірності взаємозв'язку, були вільними від дій випадкових обставин;
спостереження мають бути стохастично незалежними, тобто результати кожного спостереження не повинні залежати від результатів інших спостережень;
кожному значенню ознаки-фактора (xi) відповідає нормальний чи близький до нього розподіл результативної ознаки (у) з однаковою дисперсією.
Первинна обробка вихідної інформації - це перевірка її достовірності та перевірка того факту, який свідчить про збереження у необхідних межах вимог, яким вона має задовольняти (однорідність, незалежність, нормальність розподілу). Перевірка достовірності та збереження вимог, яким має задовольняти вихідна інформація, здійснюється шляхом якісного її аналізу та за допомогою методів і критеріїв математичної статистики: F - критерій Фішера, t - критерій Стьюдента.
Фактори, що включаються до рівняння регресії, мають справляти достатньо суттєвий вплив на результативну ознаку, тобто зв'язок результативної ознаки з кожною факторною ознакою має бути достатньо тісним. Для попередньої перевірки зазначеного вище доцільно використовувати такі методи, як порівняння паралельних рядів та аналітичне групування: просте та комбінаційне.
Однак фактори, що входять до рівняння регресії, не повинні перебувати між собою в лінійному функціональному або дуже тісному кореляційному зв'язку, оскільки тісно пов'язані між собою фактори дублюють один одного та перекручують результати КРА, що призводить до нестійкості коефіцієнтів рівняння регресії.
Для цього необхідно визначити щільність зв'язку кожного фактора з кожним з інших факторів-ознак за допомогою розрахунку парних лінійних коефіцієнтів кореляції, а потім виключити один чи кілька тісно пов'язаних з іншим (іншими) факторами.
Кореляційний аналіз - це метод, за допомогою якого можна отримати кількісне вираження взаємозв'язку соціально-економічних явищ у вигляді
рівняння регресії (рівняння кореляційного зв'язку), тобто у вигляді тієї чи іншої функції, що приблизно виражає залежність середнього значення результативної ознаки від одного чи декількох ознак-факторів:
124
y f ( x, z ,...).
При цьому термін „кореляція” використовується для оцінки щільності зв’язку між ознаками, а термін „регресія” – для опису виду і параметрів функції зв’язку (регресійної моделі). За числом факторних ознак, які входять в регресійну модель, розрізняють однофакторні та багатофакторні моделі.
Залежно від вихідних даних теоретичною лінією регресії можуть бути різні типи кривих або пряма лінія. Особливе місце в обґрунтуванні форми зв’язку при проведенні кореляційного аналізу належить графікам, побудованим у системі прямокутних координат на основі емпіричних даних. Графічне зображення фактичних даних дає наочне уявлення про наявність і форму зв’язку між досліджуваними ознаками.
При побудові графіка на осі абсцис відкладають значення факторної ознаки, а на осі ординат - значення результативної ознаки. Побудований точковий графік називають кореляційним полем (див. рис. 10.1 та 10.2). За характером розміщення точок на кореляційному полі роблять висновок про напрям і форму зв’язку. Якщо точки розкидані по всьому полю, то це свідчить про те, що зв’язок між ознаками відсутній або дуже слабкий. Якщо точки концентруються навколо уявної осі, направленої зліва, знизу, праворуч, вгору, то зв’язок прямий. Якщо ж навпаки зліва, зверху, праворуч, вниз - зв’язок обернений. Характер розміщення точок на кореляційному полі вказує на наявність прямолінійного або криволінійного зв’язку між досліджуваними ознаками, дозволяє добрати відповідне математичне рівняння для кількісної оцінки зв’язку, що існує між ознаками. Зв'язки між двома чинниками аналітично можуть бути виражені у вигляді прямої, степеневої функції, гіперболи та ін.
Оцінювання щільності та перевірка істотності кореляційного зв’язку на основі рівняння регресії
1. У вигляді лінійної функції (пряма лінія), якщо результативна ознака рівномірно зростає (зменшується) зі зростанням (зменшенням) факторної ознаки:
y x a 0 a1 x ,
де ŷх - теоретичне значення результативної ознаки;
а0 і а1 - параметри рівняння прямої (рівняння регресії);
х - індивідуальні значення факторної ознаки.
Параметри рівняння прямої а0 та а1 визначаються шляхом розв'язання системи нормальних рівнянь, одержаних методом найменших квадратів, основною умовою якого є мінімізація суми квадратів відхилень емпіричних значень від теоретичних:
|
min . |
yi y i )2 |
125

Система нормальних рівнянь для знаходження параметрів парної лінійної регресійної моделі має вигляд:
y a |
n a |
x; |
0 |
|
1 |
yx a x a x 2 , |
|
0 |
1 |
де у - індивідуальні значення результативної ознаки.
За незгрупованими даними:
a |
y x2 x xy |
; |
a |
n xy x y |
; |
||||||||||||||||
n x2 x x |
|
|
|
|
|
|
|
|
|||||||||||||
0 |
|
|
1 |
|
|
n x2 x x |
|||||||||||||||
або |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
a |
|
|
|
|
|
|
|
|
|
. |
|||||
|
a |
|
a |
|
; |
xy |
x |
y |
|||||||||||||
|
y |
x |
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
0 |
1 |
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
x2 x 2 |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
||||||||||||
У рівнянні прямої параметр а0 |
економічного змісту не має, це - початок |
||||||||||||||||||||
відліку, або значення при а1 = 0. Параметр а1 є коефіцієнтом регресії, який показує середню зміну результативної ознаки при зміні факторної ознаки на одиницю.
Коефіцієнти регресії є величинами іменованими і мають одиниці вимірювання, що відповідають ознакам, зв’язок між якими вони характеризують. Якщо a1 > 0, то зв’язок прямий, якщо a1 < 0, то зв’язок обернений, якщо a1 = 0, то зв’язок відсутній.
2. У вигляді степеневої функції, якщо значення факторної ознаки знаходяться у порядку геометричної прогресії і відповідні значення результативної ознаки також мають геометричну прогресію:
|
|
a 0 x |
a |
1 . |
y |
|
Для визначення параметрів степеневої функції методом найменших квадратів необхідно привести її до лінійного вигляду шляхом логарифмування:
lg ŷx = lg а0 + а1 lg х.
Одержане рівняння відрізняється від рівняння звичайної (лінійної) регресії тим, що замість y, x та а0 містить їх логарифми. Тому формули параметрів степеневої регресії можна отримати, якщо замінити у формулах розрахунку а0 та а1 рівняння прямої за не згрупованими даними y, x та а0 їх логарифмами. Параметр а1 у цьому випадку показує, на скільки відсотків змінюється в середньому у при зміні х на один відсоток.
126

3. У вигляді гіперболи, якщо результативна ознака зі зростанням (зменшенням) факторної ознаки зростає (зменшується) не нескінченно, а прямує до скінченої границі:
ŷx = а0 + а1 1 . x
Для визначення параметрів рівняння гіперболи методом найменших квадратів, необхідно привести його до лінійного виду. Для цього треба здійснити заміну
1 = х1. x
Побудова множинних регресійних моделей - процес досить трудомісткий. Для вирішення цих завдань існують різні методи, які описані в літературі та містяться у пакетах стандартних програм для ПЕОМ (АРМ-статистика).
При кореляційному зв’язку разом з досліджуваним фактором на результативну ознаку впливають і інші фактори, які не враховуються або не можуть бути враховані кількісно. При цьому дія їх може бути направлена як в сторону підвищення результативної ознаки, так і в сторону її зниження. Тому виникає необхідність визначення тісноти зв’язку між ознаками, у визначенні сили дії досліджуваного фактора на результативну ознаку та в оцінці адекватності моделі. Для цього використовують такі характеристики:
• Лінійний коефіцієнт кореляції (г) використовується тільки для вимірювання щільності зв'язку лінійної форми:
r |
|
n xy |
|
x y |
|||
|
|
|
|
|
|
, |
|
|
|
|
|
|
|
||
n x 2 ( x) 2 |
|
||||||
|
|
||||||
|
|
|
|
n y 2 ( y ) 2 |
|||
|
|
|
|
y |
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
y |
|
|
|
|
x |
|
|
|
|
; |
|||||||||||||||||||||
y |
x |
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||
або r |
; |
|
|
|
|
|
r |
|
|
|
y |
x |
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
n x y |
|
|
|
|
|
|
|
|
|
|
|
|
|
y |
|
|
|
2 x |
|
2 |
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y |
x |
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
r |
|
|
|
|
|
|
|
|
|
, |
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
або |
r a |
; |
|
|
|
|
|
xy |
x |
y |
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
y |
|
|
|
|
|
|
|
|
|
|
|
x |
|
y |
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
xy |
|
|
|
|
|
|
|
|
|
|
|
y |
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|||||||||||||||||
де |
xy |
|
; |
|
|
|
|
|
|
|
|
|
|
; |
|
|
|
|
|
|
|
|
|
x |
; |
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
||||
x |
|
x2 |
|
|
|
2; |
|
|
|
y |
|
|
|
y2 |
|
|
|
2. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
x |
|
|
|
|
|
|
y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
[-1] ≤ r ≤ [+1].
127

Якщо | r | = 1, то між досліджуваними ознаками існує функціональний зв’язок.
Якщо r = 0, то зв’язок відсутній.
Якщо r наближується до - 1, то між досліджуваними факторами існує щільний обернений зв’язок.
Якщо r наближується до + 1, то між досліджуваними факторами існує щільний прямий зв’язок.
За шкалою Чеддока, якщо
1)r = 0,1 – 0,3 , то зв’язок слабкий;
2)r = 0,3 – 0,5 , то зв’язок помірний;
3)r = 0,5 – 0,7 , то зв’язок помітний;
4)r = 0,7 – 0,9 , то зв’язок високий;
5)r = 0,9 – 0,99 , то зв’язок надто високий.
Квадрат теоретичного кореляційного відношення розрахований під час аналізу як лінійної, так і нелінійної регресійної моделі, називається коефіцієнтом детермінації R2 (η2). Він показує, яка частка загальної варіації результативної ознаки визначається досліджуваним фактором.
Теоретичне кореляційне відношення ηR (R) використовується для вимірювання щільності зв'язку між ознаками за будь-якої форми зв'язку, як лінійної, так і нелінійної:
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
||
|
ηR = R = |
y x |
|
1 |
y y 2 |
, |
||
|
|
|
|
|
||||
|
2y |
( y y )2 |
||||||
|
|
|
|
|||||
де 2yx |
- дисперсія, визначена для теоретичних значень результативної ознаки, |
|||||||
які отримані за рівнянням регресії (факторна дисперсія); |
|
|||||||
2y - |
дисперсія, що визначена для емпіричних значень результативної ознаки |
|||||||
(результативна дисперсія).
2y x
2y
|
( y |
|
|
) |
2 |
|
= |
x |
y |
|
; |
||
|
|
|
|
|||
|
n |
|
|
|
||
|
|
|
|
|
|
= |
( y |
|
y |
) 2 |
|
n |
|||
|
|
|||
Теоретичне кореляційне відношення змінюється від 0 до 1. Чим ближче ηr до 1, тим тісніший зв’язок між ознаками. Недолік цього показника – він не показує напрямок зв’язку.
Для оцінки адекватності регресійної моделі застосовують F-критерій Фішера (F) або t-критерій Стьюдента.
128

t-критерій Стьюдента - після побудови регресійної моделі здійснюється перевірка відповідності знаків параметрів напрямові впливу чинників, а також дається оцінка значущості коефіцієнта кореляції за t-критерієм Стьюдента.
Для парної лінійної регресійної моделі розрахункові значення t-критерію обчислюють за формулою
t розр |
r |
|
n |
2 |
|
|
|
|
|
|
|
|
||||
1 |
r 2 |
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
( x |
|
|
|
) 2 |
|
|
|
||
|
|
a 1 |
|
|
|
|
x |
( n |
2 ) , |
|||||||
|
|
|
|
( y |
|
|
|
) |
2 |
|||||||
|
|
|
|
|
|
y |
|
|
|
|
||||||
де (п - 2) — кількість ступенів свободи.
Розрахункові значення t-критерію Стьюдента порівнюють з критичними (табличними) для відповідного числа ступенів свободи: k = n - m (де n — кількість спостережень; m — число параметрів) та прийнятого рівня істотності α.
Якщо емпіричне значення t буде більшим за критичне, то лінійний коефіцієнт кореляції визнається істотним.
Методика визначення F-критерія Фішера (F) представлена при розгляді питання 2 даної теми.
Побудова довірчого інтервалу коефіцієнта регресії. Стандартна похибка коефіцієнта регресії
|
|
( y |
|
|
|
|
1 |
|
. |
|
|
a |
y )2 |
|
|
||||||
|
|
|
|
|
|
(n 2) |
|
|||
|
|
|
|
|
2 |
|
||||
|
1 |
(x x ) |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
Гранична похибка коефіцієнта регресії |
|||||||||
|
a 1 |
|
t / 2 |
|
a 1 |
, |
||||
де t |
-- імовірнісний коефіцієнт, знайдений за |
таблицями розподілу |
||||||||
|
/ 2 |
|
|
|
|
|
|
|
|
|
Стьюдента, для обраного рівня істотності α і V = n – 2 ступенів свободи.
Межі довірчого інтервалу коефіцієнта регресії
а1 – a1 ≤ а1 ≤ а1 + a1 .
129