

Оценка однородности данных.
Разбейте случайным образом переменную, взятую для анализа однородности на два массива. При этом нужно использовать генератор случайных чисел – функцию Rnd. Создайте дополнительную переменную. Щелкните дважды по полю заголовка переменной. Откроется окно, описывающее свойства переменной. Обозначьте созданную переменную какR1.В полеДлинное имя (метка или формула) – Long Name (label or formula…)напишите следующую формулу:
=Rnd(1).

Функция Rnd(1)строит случайные числа, равномерно распределенные на отрезке [0,1]. После нажатияОKпрограмма проведет вычисления, и в ячейках переменнойR1 будут занесены случайные числа на отрезке [0,1] с количеством значащих цифр, указанных в спецификациях переменной.
Создайте новую переменную New. ЗадайтеФормат отображения (Display Format)–Числовой (Number), спецификацииКоличество знаков (Сolumn width)– 3-5,После запятой (Decimals)– 0. В полеДлинное имя (метка или формула) – Long Name (label or formula…)напишите следующую формулу:
=(R1<0.5)*1+(R1>=0.5)*0
и нажмите ОК. Сравните переменныеR1иNew. Теперь переменнаяNew является категорирующей переменной. Абсолютно случайно массив данных разбит на две выборки наблюдений, где в первом случаеNew=0, а во второмNew=1.
Проведите дополнительные вычисления по определению критических точек распределений Стьюдента (t-критерий) и Фишера (F-критерий). Откройте окноОсновная статистика/Таблицы (Basic Statistics/Tables)и вызовите окноВероятностный калькулятор (Probability Calculator). Нажмите кнопкуОК.
В появившемся окне Подсчет распределения вероятности(Probability Distribution Calculator)отметьте позициюt (Student).В строкеdfзадайте число степеней свободыn1+n2-2, гдеn1иn2– число наблюдений в первом и втором массивах. Другими словами,n1иn2– число строк в таблице исходных данных. Задайтесь уровнем значимостиα=0,05.Установите двухстороннюю критическую область (см. [5] §12 стр. 305 - 307). Для этого сделайте следующие установки: отметьте пунктДвойной критерий (Two-tailed), 1-Совокупный p (1-Cumulative p) иИнверсия (Inverse) . Отметьте пунктСоздать график (Create Graph). Задайтеp=0,05.

Далее нажмите кнопку Подсчет
(Compute)и снимите значение критической точки![]() .
Полученный в результате график сохраните
для отчета.
.
Полученный в результате график сохраните
для отчета.

В окне Подсчет распределения вероятности
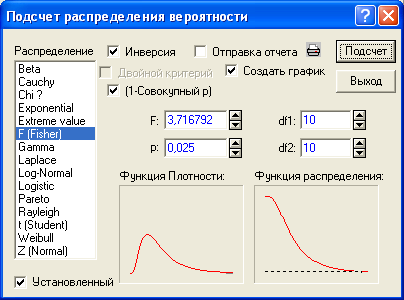
(Probability Distribution Calculator)отметьте позициюF
(Фишер) - F(Fisher).В строкахdf1иdf2 задайте число
степеней свободыn1-1 и
n2-1 , гдеn1-объем выборки, по которой вычислена
большая дисперсия,n2–
объем выборки, по которой найдена меньшая
дисперсия(см. [5] §8 стр.
288 - 292). Задайтесь уровнем
значимостиα=0,05. Сделайте
следующие установки в
окне Подсчет
распределения вероятности (Probability
Distribution Calculator):
отметьте1-Совокупный p
(1-Cumulative p)
иИнверсия (Inverse).
Задайтеp =![]() ,
и отметьте опциюCоздать
график (Create Graph).
,
и отметьте опциюCоздать
график (Create Graph).
Далее нажмите Подсчет
(Сompute)и снимите значение правой критической
точки![]() .
Полученный в результате график сохраните
для отчета.
.
Полученный в результате график сохраните
для отчета.

Аналогично, задайте p
=![]() ,
нажмите кнопкуПодсчет
(Сompute)и снимите значение левой критической
точки
,
нажмите кнопкуПодсчет
(Сompute)и снимите значение левой критической
точки![]() .
Полученный в результате график сохраните
для отчета.
.
Полученный в результате график сохраните
для отчета.

Теперь вернитесь в окно Основная статистика / Таблицы (Basic Statistics/Tables). Выберите опциюt-критерий для независимых выборок (t-test, independent, by groups)

Нажмите ОК.В открывшемся окнеt-критерий для независимых выборок (t-test for Independent Samples by Groups…) щелкните по кнопкеПеременные (Variables).
Выберите в открывшемся окне переменную New, отметьте ее как группирующую (правое окно), а несколько переменных для анализа отметьте как зависимые переменные (левое окно). НажмитеОК.

Далее в основном окне в позициях Код для группы 1 (Code for Group 1)задайте значение 1, а в позиции Код для группы 2 (Code for Group 2)поставьте 0. Нажмите кнопкуРасчет (Summary) для вывода результатов. В результате сформируется таблица следующего содержания:
|
|
Mean 0 |
Mean 1 |
t-value |
df |
P |
Valid N |
Valid N |
Std.Dev. |
Std.Dev. |
F-ratio |
p |
|
Var2 |
47,75720 |
46,90458 |
0,14546 |
106 |
0,884621 |
68 |
40 |
29,21907 |
29,74916 |
1,036613 |
0,879994 |
|
Var3 |
4,56383 |
5,40338 |
-1,40470 |
106 |
0,163034 |
68 |
40 |
2,79872 |
3,31596 |
1,403786 |
0,220469 |
Надписи по столбцам соответственно имеют вид:
имя переменной
средние по группам (Mean 0, Mean 1)
t-значение (t-value)
число степеней свободы (df)
вероятность (р)
число наблюдений групп 1 и 2(Valid N)
стандартное отклонение групп 1 и 2 (Std.Dev)
F-критерий
вероятность (р)
Используя [5] §8 - §12 стр. 288-305, данные главы Краткие теоретические сведения, вычисленные значения критических точек распределений Стьюдента (t-критерий) и Фишера (F-критерий) и данные расчетной таблицы, сделайте вывод об однородности данных в двух выборках для каждой исследуемой переменной.
Проверим справедливость гипотезы: «средние в двух выборках равны» при малых выборках нормальных и одинаковых дисперсиях.
1-й этап. Проверим справедливость гипотезы: «дисперсии в двух выборках равны» имеет распределение Фишера-Снедекора. При уровне значимости αгипотеза верна, если
![]() (2)
(2)
Где: ![]() - значениеF-критерия;
- значениеF-критерия;
![]() взять из п.14.
взять из п.14.
2-й этап. Проверим справедливость гипотезы: «средние в двух выборках равны» . Если
![]() , (1)
, (1)
то гипотеза отвергается.
Визуализируйте результаты данных расчетов, используя диаграммы размаха. Для этого в основном меню выберите элемент Графики (Graphs), затемГрафики входных данных (Graphs of Input Data), затемТочечный блок (Box-Whisker), затемСреднее/SE/SD (Mean/SE/SD):

Нажмите Окдля построения графика.
Сохраните основные таблицы и построенные графики, используя рекомендации п. 9.