

Методические указания и порядок выполнения лабораторной работы «Элементы первичной обработки данных»
Основная цель работы: изучение методов первичной обработки статистической информации и приобретение практических навыков предварительного анализа данных с использованием прикладного программного обеспечения.
Краткие теоретические сведения
Кроме определения описательных статистик и подгонки вероятностных распределений реальным данным при первичной обработке существует еще несколько важных этапов работы с данными: визуализация, оценка однородности распределения и проведение анализа резко выделяющихся наблюдений.
Визуализация
Визуализация – это важный этап работы с данными. Многие закономерности, не видимые в таблицах в численном виде, отчетливо проявляются на графиках.
В программе STATISTICA 6.0 кроме гистограмм и простых диаграмм рассеивания используются также другие различные графики. Среди них наиболее распространенные:
различные виды диаграмм рассеивания;
нормальные вероятностные графики;
диаграммы размаха;
линейные графики;
диаграммы пропущенных значений и интервалов.
Ограничимся рассмотрением только двумерных графиков.
Двумерные диаграммы рассеивания– используются для визуального исследования зависимости между двумя переменнымиXиY(например, двумя курсами акций, курсом доллара и курсом гривны, рекламой и объемом продаж и т.д.) Данные изображаются точками в двумерном пространстве. Эти графики позволяют:
оценить графически взаимосвязь переменных. Если переменные сильно связаны, то множество точек данных принимает определенную форму, например, точки ложатся около прямой или криволинейной линии. Если переменные не связаны, то точки образуют, так называемое, «облако рассеяния» на значительной площади графика;
оценить графически однородность данных. Если данные на диаграмме рассеивания группируются около различных средних (компактно укладываются группами на различных участках графика), то данные не однородны;
определить форму зависимостей, вокруг которых группируются данные, чтобы потом можно было выбрать подходящий тип преобразований данных для их «линеаризации» или выбора подходящего нелинейного уравнения подгонки;
оценить наличие выбросов (резко выделяющихся наблюдений).
При оценке данных используются простые диаграммы рассеивания, составные диаграммы, комбинированные диаграммы рассеивания с гистограммами и т.д.
Нормальные вероятностные графики – позволяют визуально исследовать насколько распределение данных близко к нормальному. Если наблюдаемые значения распределены нормально, то все значения на таком графике должны располагаться близко к прямой линии. Если значения не являются нормально распределенными, то будет наблюдаться отклонение от прямой линии.
Диаграммы размаха – характеризуют диапазоны значений выбранной переменной и строятся отдельно для групп наблюдений.
Центр (медиана или среднее) и статистики диапазонов или вариации (например, квартили, стандартные ошибки или стандартные отклонения) вычисляются для каждой группы наблюдений.
Диаграммы размаха позволяют оценить однородность данных и наличие аномальных наблюдений с точки зрения отклонения от среднего или моды.
Линейные графики – представляют собой двухмерные линейные графики одной или многих переменных, на которых отдельные точки соединены линиями. Линейные графики дают простой способ наглядного представления последовательности большого числа значений (например, рыночных цен на акции в зависимости от времени).
Если в последовательности данных очень много наблюдений и они существенно различаются, то необходимо сглаживание такого временного ряда для обнаружения общей структуры последовательности данных. Линейные графики служат для визуализации данных и полезны при изучении временных рядов, сравнении нескольких временных рядов между собой и т.д.
Диаграммы пропущенных значений и интервалов – дают возможность исследовать шаблон распределения или распределения пропущенных данных. Эти диаграммы применяются для определения количества пропущенных значений данных, а также для выяснения является ли распределение данных более или менее случайным или в их расположении можно обнаружить некоторую закономерность. Часто эти диаграммы называют «картами» файла данных.
Все указанные графики, а также множество других их видов можно построить, воспользовавшись пунктом меню Графики (Graphs)программыSTATISTICAV.6.0.
Оценка однородности данных.
(Предварительно необходимо ознакомиться с [5] §8 - §12 стр. 288-307)
Гипотеза однородностисостоит в том, что генеральные совокупности, из которых извлечены выборки, одинаковы. Другими словами, если выборки однородны, то они имеют одинаковые, причем неизвестные, непрерывные функции распределения. Для нормальных совокупностей задача однородности часто связана с оценкой средней в группах. Такие задачи часто возникают на практике. Например, сравнение средних доходов в разных группах людей, сравнение средних показателей для разных групп объектов и т.д. Возможны два варианта организации данных: можно иметь дело с независимыми и зависимыми группами наблюдений. Если выборка случайно разбита на группы, то, скорее всего, они независимы. Если есть две группы, которые основываются на одной и той же выборке объектов наблюдений (например, пациенты до и после лечения, посещения на сайт до и после рекламы), то тогда выборки зависимые.
Обычно, проводя группировку данных, преследуют цель выделить группы однородных объектов (реальные исходные данные, как правило, неоднородны). Следует отметить, что на вопрос: как в общем случае провести группировку данных? – нет однозначного ответа. В каждом конкретном случае при изучении данных сравниваются различные способы группировки, и интуитивно находится нужный вариант. Поэтому оценка на однородность необходимый этап любого статистического исследования.
При оценке двух групп на однородность проводят оценку равенства средних и дисперсий выборок.
Для оценки равенства средних обычно используется t-критерий (критерий Стьюдента). Для двух групп статистикаt-критерия равна
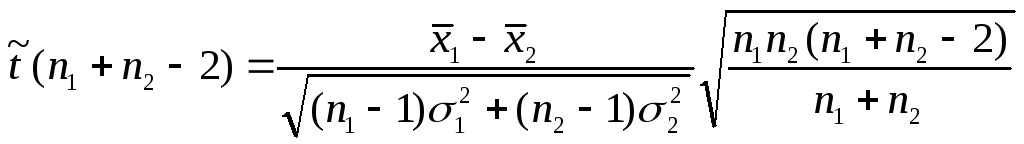
где
![]() ,
,![]() -
количество наблюдений в первой и второй
выборках;
-
количество наблюдений в первой и второй
выборках;![]() - средние;
- средние;![]() - выборочные дисперсии.
- выборочные дисперсии.
Известно, что статистика
![]() при справедливости гипотезы: «средние
в двух выборках равны» имеет распределение
Стьюдента
при справедливости гипотезы: «средние
в двух выборках равны» имеет распределение
Стьюдента![]() с
с![]() степенями свободы. Поэтому большие по
абсолютной величине значения
степенями свободы. Поэтому большие по
абсолютной величине значения![]() свидетельствуют
против гипотезы о равенстве средних
значений, т.е. если
свидетельствуют
против гипотезы о равенстве средних
значений, т.е. если
![]() , (1)
, (1)
то гипотеза отвергается.
Статистический критерий равенства или однородности дисперсий двух нормальных выборок основан на статистике
 ,
,
Известно, что статистика
![]() при справедливости гипотезы: «дисперсии
в двух выборках равны» имеет распределение
Фишера-Снедекора. При уровне значимостиαгипотеза верна, если
при справедливости гипотезы: «дисперсии
в двух выборках равны» имеет распределение
Фишера-Снедекора. При уровне значимостиαгипотеза верна, если
![]() , (2)
, (2)
иначе она отвергается.
Процедура оценки однородности двух выборок реализована в модуле Основная статистика/Таблицы (Basic Statistics/Tables).
Анализ резко выделяющихся наблюдений.
Удобнее всего анализ резко выделяющихся наблюдений (выбросов) основывать на изучении информации представленной в графическом виде. С этой целью следует использовать уже упоминавшиеся диаграммы рассеяния и размаха.