

spz / spz
.pdfСистемне програмне забезпечення. |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FreePtr |
h(A1) n1 |
|
|
A1 |
- |
|
||
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
n2 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
||
n3 |
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n4 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n5 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FreePtr |
h(A2) n1 |
|
|
A1 |
|
|
|
|||
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
n2 |
- |
|
A2 |
- |
|
|
|
|
|
n3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n4 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n5 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
FreePtr |
n1 |
|
|
|
|
A1 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
||
h(A3) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n2 |
|
|
|
|
A2 |
- |
|
|
|
|
|
n3 |
- |
|
|
A3 |
- |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n4 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n5 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2
|
|
|
|
|
|
|
|
|
|
|
FreePtr |
n1 |
|
|
|
|
A1 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
n2 |
|
|
|
|
A2 |
- |
|
|
|
|
|
n3 |
- |
|
|
A3 |
- |
|
|
|
|
||
h(A4) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n4 |
|
|
|
|
A4 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n5 |
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
4
Системне програмне забезпечення. |
11 |
|||
h(A5) |
n1 |
|
A1 |
FreePtr |
|
|
|||
|
n2 |
|
A2 |
|
|
n3 |
- |
A3 |
- |
|
n4 |
|
A4 |
- |
|
n5 |
- |
A5 |
- |
|
5 |
|
|
|
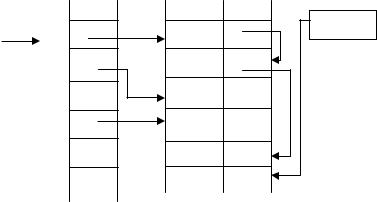
Рис. Заповнення хеш-таблиці і таблиці ідентифікаторів з використанням методу ланцюжків
На мал. 13.6 проілюстроване заповнення хеш-таблиці і таблиці ідентифікаторів для приклада, що раніше був розглянутий на мал. 13.5 для найпростішого рехешування. Після розміщення в таблиці для пошуку ідентифікатора А1 буде потрібно 1 порівняння, для А2 — 2 порівняння, для А3
— 1 порівняння, для А4 — 1 порівняння і для А5 — 3 порівняння (порівняєте з результатами простого рехешуровання).
Метод ланцюжків є дуже ефективним засобом організації таблиць ідентифікаторів. Середній час на розміщення одного елемента і на пошук елемента в таблиці для нього залежить тільки від середнього числа колізій, що виникають при обчисленні хеш-функції. Накладні витрати пам'яті, зв'язані з необхідністю мати одне додаткове поле покажчика в таблиці ідентифікаторів на кожен її елемент, можна визнати цілком виправданими. Цей метод дозволяє більш ощадливо використовувати пам'ять, але вимагає організації роботи з динамічними масивами даних.
Комбіновані способи побудови таблиць ідентифікаторів
Вище в прикладі була розглянута дуже примітивна хеш-функція, що ніяк не можна назвати задовільною. Гарна хеш-функція розподіляє ідентифікатори, що надходять на її вхід рівномірно на всі наявні в розпорядженні адреси, так що колізії виникають не настільки часто. Існує велика безліч хеш-функцій. Кожна з них прагне розподілити адреси під ідентифікатори по своєму алгоритмі, але ідеального хешировання досягти не вдається.
У реальних компіляторах практично завжди так чи інакше використовується хеш-адресація. Алгоритм застосовуваної хеш-функції звичайно складає «ноу-хау» (розроблювачів компілятора). Звичайно при розробці хеш-функції творці компілятора прагнуть звести до мінімуму кількість виникаючих колізій не на всій множині можливих ідентифікаторів, а на тих їхніх варіантах, що найбільше часто зустрічаються у вхідних програмах. Звичайно, узяти до уваги всі припустимі вхідні програми неможливо.
Системне програмне забезпечення. |
12 |
Найчастіше виконується статистична обробка імен ідентифікаторів, що зустрічаються, на деякій множині типових вихідних програм, а також приймаються в увагу угоди про вибір імен ідентифікаторів, загальноприйняті для вхідної мови. Гарна хеш-функція — це крок до значного прискорення роботи компілятора, оскільки звертання до таблиць ідентифікаторів виконуються багаторазово на різних фазах компіляції.
Те, який конкретно метод застосовується в компіляторі для організації таблиць ідентифікаторів, залежить від реалізації компілятора. Той самий компілятор може мати навіть декілька різних таблиць ідентифікаторів, організованих на основі різних методів.
Як правило, застосовуються комбіновані методи. У цьому випадку, як і для методу ланцюжків, у таблиці ідентифікаторів організується спеціальне додаткове поле посилання. Але на відміну від методу ланцюжків воно має трохи інше значення. При відсутності колізій для вибірки інформації з таблиці використовується хеш-функція, поле посилання залишається порожнім. Якщо ж виникає колізія, то через поле посилання організується пошук ідентифікаторів, для яких значення хеш-функції збігаються по одному з розглянутих вище методів: неупорядкований список, упорядкований список або бінарне дерево. При добре побудованій хеш-функції колізії будуть виникати рідко, тому кількість ідентифікаторів, для яких значення хеш-функції збіглися, буде не настільки велике. Тоді і час пошуку одного серед них буде незначним (у принципі при високій якості хеш-функції підійде навіть перебір неупорядкованому списку).
Такий підхід має переваги в порівнянні з методом ланцюжків: для збереження ідентифікаторів зі співпадаючими значеннями хеш-функції використовуються області пам'яті, що не перетинаються з основною таблицею ідентифікаторів, а виходить, їхнє розміщення не приведе до виникнення додаткових колізій. Недоліком методу є необхідність роботи з динамічно поділюваними областями пам'яті. Ефективність такого методу, очевидно, у першу чергу залежить від якості застосовуваної хеш-функції, а в другу - від методу організації додаткових сховищ даних.
Хеш-адресація — це метод, що застосовується не тільки для організації таблиць ідентифікаторів у компіляторах. Даний метод знайшов своє застосування й в операційних системах, і в системах керування базами даних.
НЕ 3.2.ФОРМАЛЬНІ МОВИ ТА ГРАМАТИКИ
.
Ланцюжки і ланцюжки символів. Способи завдання мов. Операції над ланцюжками символів. Поняття мови. Визначення формальної мови. Визначення грамматики. Класифікація граматик. Способи задання схем грамтик Символічна, форма Наура-Бекуса, ітераційна форма й синтаксичні діаграми. Чотири типи граматик по Хомському. Правила побудови граматики із ланцюжка символів. Зв'язок регулярних множин, регулярних граматик та кінцевих автоматів. Алгоритм побудови КА по заданій граматиці.
Формальні |
граматики - це математичний апарат, |
що |
|
дозволяє |
||||||||||
математично |
грамотно |
створювати |
мови |
програмування |
й писати |
|||||||||
компілятори для цих мов. |
|
|
|
|
|
|
|
|
|
|
||||
Між |
природними й |
формальними |
мовами |
прірва. |
Тому |
збіг |
||||||||
термінології |
краще |
вважати випадковим... |
|
|
|
|
|
|
|
|||||
Формальну мову можна задати як |
|
якусь множину слів. |
Слово, |
це |
||||||||||
послідовність |
символів. Будь-яка |
комп'ютерна програма |
в цьому випадку |
|||||||||||
теж сприймається як слово. Пробіли в ній - спеціальні символи, |
для яких на |
|||||||||||||
клавіатурі виділена сама довга клавіша. |
|
|
|
|
|
|
|
|
||||||
Словами |
даної |
мови |
може |
бути |
далеко |
не |
будь-яка абракадабра, |
|||||||
доступна |
клавіатурі. |
А |
тільки |
лексично |
й синтаксично |
правильні |
||||||||
програми. |
Бездоганна з погляду граматики |
програма |
може |
бути марною, |
||||||||||
безглуздою або навіть шкідливою. Але за правильну роботу програми формальна граматика й компілятор не відповідають.
Для того, щоб задати граматику, треба задати множини ТЕРМІНАЛЬНИХ і НЕТЕРМІНАЛЬНИХ символів.
Термінальні символи це символи які використовуються в мові.
Нетермінальні |
(проміжні) символи - це |
|
символи, |
які |
|||||||
використовуються в створенні (породженні) |
слів мови. |
А |
створюються |
||||||||
слова |
за граматичними правилами. І кожне слово - |
програма, |
записана |
||||||||
винятково термінальними символами. |
|
|
|
|
|
|
|
||||
Далі задаються ГРАМАТИЧНІ |
ПРАВИЛА. |
|
|
|
|
|
|||||
Застосування |
правила |
полягає |
в |
заміні в |
|
перетворюваному |
|||||
рядку |
якоїсь послідовності |
символів, що співпадає з |
лівою |
частиною |
|||||||
якогось правила або |
правою |
частиною (послідовністю |
символів) |
цього |
|||||||
правила. |
|
|
|
|
|
|
|
|
|
|
|
Уведемо ще один термін - СЕНТЕНЦійНА ФОРМА. Справа в тому, |
|||||||||||
що при побудові програм у |
формальних граматиках завжди танцюють від |
||||||||||
одного |
початкового |
нетермінального |
символу. Позначимо |
цей |
|
символ |
|||||
<програма>. |
Замість |
цього |
символу |
по одному із граматичних правил |
|||||||
відбувається |
підстановка відповідної правої |
частини, |
що |
може |
містити |
||||||
послідовність |
із якихось нетермінальних і термінальних символів. |
Такий |
|||
процес називається БЕЗПОСЕРЕДНІМ ПОРОДЖЕННЯМ. |
|
|
|||
Кожний |
з нетермінальних |
символів, що з'явилися, |
може |
бути |
|
замінений |
по |
підходящому граматичному правилу якимось |
ланцюжком |
||
символів. |
Тобто початковий |
нетермінальний символ |
<програма> |
||
послідовно перетворюється в усе більший ланцюжок символів. І так аж до того моменту, коли в послідовності символів залишаться тільки термінальні символи. Тобто буде отримане слово даної мови (по іронії долі називане РЕЧЕННЯМ). Всі послідовності символів, які в процесі безпосередніх породжень перебувають між початковим нетермінальним символом і кінцевим реченням й називаються сентенціальними формами.
Компілятор, одержавши програму, виконує зворотну роботу.
Отримане речення він згортає за граматичними правилами (тепер рухаючись від правої частини правила до лівого) початкового символу <програма>.
Звичайно існує величезна кількість варіантів як породження, так і згортання. Якщо згортання зазнало невдачі, то повинні досліджуватися інші варіанти. Слово буде визнано не приналежним даній мові (граматиці), якщо жоден з варіантів згортання не приведе до удачі. Оскільки такий перебір варіантів на практиці як правило неприйнятний, то й граматики намагаються довільного виду. А раз немає ніяких обмежень, то там може бути все, що завгодно й, отже, аналізувати їх неможливо. Так що мати з ними справа безглуздо.
Є досить груба, але, однаково, корисна в першому наближенні класифікація граматик, що належить Хомському. Він їх ділить на три типи, якщо не вважати нульового. До нульового він відносить граматики із граматичними правилами
Граматики першого типу називають КОНТЕКСТНО-ЗАЛЕЖНИМИ (або просто КЗ). У більшості випадків розумно прийняти загальне обмеження, що правило заміняє строго один нетермінальний символ. Відмінна риса Кз-правил у тім, що заміна нетермінального символу на рядок допускається, коли цей символ перебуває в деякім оточенні інших символів (у контексті).придумувати не випадкові, а з корисними властивостями. А способи згортання (розпізнавання) використовують ці гарні властивості, щоб мінімізувати або взагалі виключити блукання.
Наприклад, нетермінальний символ <оператор> може бути замінений на нетермінальний символ <порожній оператор>, якщо в преутвореному рядку перед символом <оператор> був інший символ, за яким безпосередньо слідував <оператор>. А інакше таку заміну робити не можна.
Представте наприклад, правило офіціанта. Здійснювати заміну брудної
тарілки |
на |
виписаний |
рахунок |
можна при наявності спустошеного |
|||||
келиха. |
В |
іншому |
контексті (при повному келиху [гранованій склянці] |
||||||
поруч) |
замість брудної |
тарілки клієнтові пропонується нова закуска. |
|
||||||
Для того, щоб граматика ставилася до типу КЗ досить, щоб хоча б одне |
|||||||||
правило було саме першого |
типу. |
(Інші можуть бути інших типів, |
крім |
||||||
нульового). |
|
|
|
|
|
|
|
|
|
Граматики другого типу називають КОНТЕКСТНО-ВІЛЬНИМИ (або |
|||||||||
просто КВ). Кожне |
правило |
може |
застосовуватися без |
оглядки |
на |
||||
контекст. Замість брудної тарілки |
- |
нова закуска (без усяких додаткових |
|||||||
умов)... |
Граматики |
різних |
типів |
|
можуть породжувати ту |
саму мова. |
|||
Компілятори диктують вимогу приводити граматику до типу КВ. Звичайно в рамках уже цього типу накладаються додаткові обмеження, що дозволяє істотно спростити граматичний розбір у компіляторі.
Граматики останнього третього типу називаються АВТОМАТНИМИ або РЕГУЛЯРНИМИ. Це пов'язане з тим, що вони породжуються й розпізнаються автоматами (цю математичну модель асоціюють не з Калашниковим, а із прізвищами математиків-логіків Милі Мура
Трахтенбротта й т.п.) |
і регулярними виразами. |
|
|
|
|
||||
Звичайно автоматні граматики використаються на рівні лексики. |
|||||||||
Лексема, у звичайному розумінні - це |
словникова |
одиниця. |
Тим не менш, |
||||||
з погляду компілятора це "символ", |
як тільки "словом" буде вся програма. |
||||||||
У цьому випадку, наприклад, |
345.08 може бути розпізнаний як один символ |
||||||||
- дійсне число. |
|
|
|
|
|
|
|
|
|
Лексичний |
аналіз у |
компіляторі |
передує синтаксичному аналізу... |
||||||
Існують знамениті команди UNIX lex |
і |
yacc, |
що |
дозволяють |
|||||
автоматизувати |
процес написання лексичного й синтаксичного аналізаторів |
||||||||
компілятора. |
|
|
|
|
|
|
|
|
|
1. ФОРМАЛЬНІ МОВИ Й ГРАМАТИКИ |
|
|
|
|
|
|
|||
Точний |
опис |
правил |
побудови |
вхідних |
текстів |
називається |
|||
синтаксисом мови, а правила тлумачення, що описують зміст текстів називаються семантикою мови.
Формальна мова можна представити як множина речень, побудованих за певними правилами. Спосіб побудови речень формальної мови й правила побудови можуть бути визначені за допомогою формальних граматик. При цьому множина правил побудови називають схемою граматики, а порядок побудови визначається за допомогою поняття виведення. Як правило, за допомогою правил граматики можна будувати різні виведення, результатом яких є правила речень мови. Тому формальні граматики часто називають граматиками, що породжують, а виведення - процесом породження.

1.1. Визначення формальної граматики й мови
Первинними й найпростішими поняттями, необхідними для визначення формальної мови й граматики, є поняття алфавіту й слова в алфавіті.
Визначення: Кінцева множина символів, неподільних у даному розгляді, називається словником або алфавітом, а символи, що входять у множину, - буквами алфавіту.
Наприклад, алфавіт A = {a, b, c, +, !} містить 5 букв, а алфавіт B = {00, 01, 10, 11} містить 4 букви, кожна з яких складається із двох символів.
Визначення: Послідовність букв алфавіту називається словом або ланцюжком у цьому алфавіті. Число букв, що входять у слово, називається його довжиною.
Наприклад, в алфавіті A слово =ab++c має довжину l( ) = 5, а слово=00110010 в алфавіті B має довжину l( ) = 4.
Якщо задано алфавіт A, то позначимо A* множини усіляких ланцюжків, які можуть бути побудовані з букв алфавіту A. При цьому передбачається, що порожній ланцюжок, що позначимо знаком $, також входить у множини A*. Порожній ланцюжок – це ланцюжок, що не містить ні однієї букви. Приєднання до деякого ланцюжка порожнього ланцюжка, праворуч або
ліворуч від від неї, не змінює ланцюжок .
$ = $ =
Для визначення множини всіляких ланцюжків, побудованих із символів алфавіту А, що не містять порожнього ланцюжка, використовують позначення А+.
Визначення: Формальною граматикою Г називається наступна сукупність чотирьох об'єктів:
Г = { VТ, VA, <I>, R },
де VT - термінальний алфавіт (словник); букви цього алфавіту
називаються
термінальними символами; з них будуються ланцюжки,
породжувані граматикою; для позначення букв термінального словника, які називають
також термінальними символами, надалі вмовимося використовувати
рядкові букви латинського алфавіту;
VA - нетермінальний, допоміжний алфавіт (словник); букви
цього

алфавіту використовуються при побудові ланцюжків; вони можуть входити в проміжні ланцюжки, але не повинні входити в результат побудови;
умовимося для позначення нетермінальних символів використовувати
ідентифікатори, що складаються із прописних букв латинського алфавіту й
взяті в кутові дужки;
<I> - початковий символ або аксіома граматики <I> VA.
R - множина правил виведення або правил, що породжують,
,
де і - ланцюжка, побудовані з букв алфавіту VТ VA, що
називають повним алфавітом (словником) граматики Г.
У множині правил граматики можуть також входити правила з порожньою правою частиною виду <Е> . Щоб уникнути невизначеності через відсутність символу в правій частині правила, умовимося використовувати символ порожнього ланцюжка, записуючи таке правило у вигляді <Е> $.
Правила виведення граматики використовуються для побудови ланцюжків.
Визначення: Нехай r = - правило граматики Г и = ' " - ланцюжок символів,
причому ', " (Vт VA) *. Тоді ланцюжок = ' " може
бути отриманий з ланцюжка шляхом застосування правила r (тобто заміною в m ланцюжка на ).
У цьому випадку говорять, що ланцюжок безпосередньо виведений з ланцюжка і позначають .
Визначення: Якщо задано сукупність ланцюжків = (0, 1,...,n), таких що
існує
послідовність безпосередніх виведень:
0 1, 1 2, ... ,n-1 n,
те таку послідовність називають виведенням n з 0 у
граматиці Г і позначають
0 * n.
Визначення: Множина кінцевих ланцюжків термінального алфавіту Vт
граматики Г,
виведених з початкового символу <I>, називається мовою,
породжуваною

граматикою Г и позначається L( Г).
L( Г ) = {VТ* | <I> * }.
Розглянемо кілька прикладів, що ілюструють уведені поняття:
Приклад 1:
Задано граматику Г1.1, потрібно визначити мову, яка породжується цією граматикою:
Г1.1: VТ = {a, b, c}, VА = {<I>}, R = {<I> abc}.
Схема граматики містить одне правило, тому Г1.1 породжує мову з одного слова
L(Г1.1) = {abc}.
Приклад 2:
Задано граматику Г1.2 і потрібно визначити мову, яка породжується цією граматикою.
Г1.2 : VТ = {a, b, c}, VА = {<I>, <B>, <C>} R = { <I> a<B>,
<B> <C>d, <B> dc,
<C> $}.
Побудуємо всі виведення в цій граматиці. Це можна зробити двома способами. Спочатку застосуємо правила 1,2,4, а потім побудуємо друге виведення, використовуючи правила 1 і 3. У результаті одержимо:
<I> a<B> a<C>d ad,
<I> a<B> adc.
Отже мова, породжувана цією граматикою, складається із двох ланцюжків
L(Г1.2) = {adc, ad}.
Приклад 3:
Задано граматику Г1.3 і потрібно визначити мову, яка породжена цією граматикою.
Г1.3 : VА = {<I>, <A>}, VТ= {0, 1}, R = {<I> 0<A>1,
<A> 0<A>1, <A> $}.
Схема наведеної граматики містить три правила. Друге правило містить нетермінальний символ <А> як у лівій, так і в правій частині правила. Такі

правила називають рекурсивними. Застосування такого правила до ланцюжка, що містить нетермінал <А>, приводить до одержання нового ланцюжка, у яку знову входить <А>. Таким чином, заміну нетермінала <А> правою частиною правила можна виконувати багаторазово, що дозволяє будувати як завгодно довгі ланцюжки. Щоб виведення із застосуванням рекурсивного правила не було нескінченним, у схемі граматики повинне бути хоча б одне правило із символом <А> у лівій частині. Таке правило завершує рекурсію, крім <А> з виведеного ланцюжка. У розглянутій граматиці для завершення виведення використовується правило <А> $. Розглянемо побудову виведення за допомогою правил граматики Г1.3. Застосовуючи перше і третє правила, одержуємо:
<I> 0<A>1 01.
Застосувавши перше, друге, а потім третє правило, маємо
<I> 0<A>1 00<A>11 0011.
Застосувавши друге правило k раз, одержимо в результаті ланцюжок, що містить k нулів і k одиниць. Отже, мова, породжувана граматикою Г1.3, містить усілякі ланцюжки, у яких число нулів дорівнює числу одиниць.
Приклад 4:
Задано граматику Г1.4 і потрібно побудувати мову, породжуваний цією граматикою.
Г1.4 : VТ= {a, b}, VА = {<I>, <A>}, R = { <I> a<A>, <A> b<A>}.
Спроба побудови виведення в цій граматиці приводить нас до ланцюжка:
<I> a<A> ab<A> abb<A> …,
яка виявляється нескінченною. У розглянутій граматиці відсутнє правило, що дозволяє завершити рекурсію, тому за допомогою правил цієї граматики не можна побудувати ні одного кінцевого ланцюжка. Інакше кажучи, граматика Г1.4 породжує порожню мову.
Визначення: Якщо мова, породжувана граматикою Г, не містить ні однієї кінцевої
ланцюжка (кінцевого слова), то вона називається порожньою.
1.2.Типи формальних граматик
Утеорії формальних мов виділяються 4 типи граматик, яким відповідають 4 типи мов. Ці граматики виділяються шляхом накладення обмежень на правила граматики.
Граматики типу 0, які називають граматиками загального виду, не мають ніяких обмежень на правила породження. Будь-яке правило