

ШевцовИСТ / 1 ,2
.docx
1
Характеристика объекта проектирования

Рассматриваемый автовокзал расположен в непосредственной близости к железнодорожному вокзалу, что создает дополнительное удобство для жителей и гостей города. Здание автовокзала двухэтажное: на первом этаже расположено 3 билетных кассы, справочная служба, диспетчерская, помещение дежурного по вокзалу, здравпункт, зал ожидания, камеры хранения, бытовые помещения, банкомат и терминалы оплаты, на втором этаже – административные помещения, пункты общественного питания, киоски с печатной и сувенирной продукцией, комната матери и ребенка, для водителей и пассажиров имеются комнаты длительного ожидания.
Возле здания автовокзала разбит уютный сквер, где можно провести время в ожидании своего рейса.
Предприятие постоянно старается расширять спектр оказываемых пассажирам услуг и улучшать их качество. На автовокзале внедрена автоматизированная система управления (АСУ). Благодаря этой системе все вносимые изменения в расписание рейсов и условия проезда стали мгновенно доступны на всех рабочих местах. Это повысило качество и скорость работы справочной службы и кассиров, а время продажи билетов составляет менее 1 мин. Также созданы новые услуги - бронирование билетов по телефону и продажа билетов через интернет.
Режим работы автовокзала с 5:30 до 23:30. Билетные кассы работают с 6:00 до 22:00. От платформ автовокзала отходят автобусы пригородного, междугороднего и международного сообщения. Всего насчитывается 70 маршрутов.
Списочное количество сотрудников автовокзала составляет 28 человек.
Схема первого этажа автовокзала представлена в приложении А.
2 Статистическая обработка исходных данных
Исходные данные числа справочных запросов по дням года представлены в приложении В. Статическая обработка данной выборки выполнена с помощью компьютера, результаты представлены в приложении Г.
Исходные данные количества проданных билетов по дням года представлены в приложении Б. Статическая обработка данной выборки выполнена по методике, описанной ниже.
Существует
множество методик для установления
закона распределения случайной величины.
Так как объем статистической выборки
достаточно велик (n=365),
статистическая обработка осуществляется
с помощью метода группирования.
Случайными называются явления (величины), исход (значение) или протекание которых при одинаковом комплексе условий заранее не предсказуем, однако при многократном их воспроизведении становится возможным заметить некоторые закономерности. Данные закономерности в дальнейшем подвергаются анализу, на основании которого можно выдвинуть гипотезу о законе распределения случайной величины. Последующие исследования подтверждают либо опровергают выдвинутую гипотезу.
Целью такого комплексного исследования случайного явления (величины) – статистической обработки данных – является использование полученных результатов для прогнозирования (предсказания) поведения данного явления и принятия соответствующих технических, организационных, управленческих и прочих решений в условиях неопределенности.
Статистическая обработка данных может осуществляться вручную (с использованием известных разработанных методик) и машинным способом (с использованием ЭВМ).
Первым шагом при статистической обработке данных является их упорядочение по возрастанию, т.е. построение вариационного ряда. Стоит отметить, что представленные исходные данные в gриложении Б – неубывающая последовательность, поэтому их упорядочения не требуется.
Второй шаг – группировка упорядоченных статистических данных. Стоит отметить, что представленные в Приложении Б данные являются дискретными величинами, однако из-за очень редкой повторяемости их значений по отношению к их количеству целесообразно группировать их как непрерывную случайную величину ξ – по интервалам.
С этой целью определяется количество интервалов одинаковой длины:
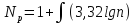 ,
(2.1)
,
(2.1)
где int – целая часть дробного числа;
n – объем выборки, n=365.
При
этом должно
выполняться условие
 ,
иначе принимают значение соответствующей
границы условия.
,
иначе принимают значение соответствующей
границы условия.
Величину (длину) интервала определяют по следующей формуле:
 ,
(2.2)
,
(2.2)
где
 – величина размаха исходных данных.
– величина размаха исходных данных.
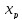 определяется
по формуле:
определяется
по формуле:
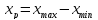 ,
(2.3)
,
(2.3)
Где
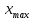 – максимальный элемент выборки;
– максимальный элемент выборки;
 – минимальный
элемент выборки.
– минимальный
элемент выборки.
Границы интервалов определяются по следующим формулам:
-
верхняя:
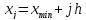 ;
(2.4)
;
(2.4)
-
нижняя:
 ,
(2.5)
,
(2.5)
где j – номер интервала.
Середина
интервалов определяется по формуле:
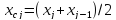 (2.6)
(2.6)
Относительная частота (вероятность) появления значений случайной величины ξ в интервале определяется по формуле:
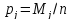 ,
(2.7)
,
(2.7)
где
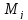 – частота появления значений случайной
величины в интервале, определяется
путем подсчета.
– частота появления значений случайной
величины в интервале, определяется
путем подсчета.
Ниже представлены расчеты по формулам (2.1)–(2.3):
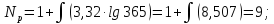


Расчет границ и относительной частоты по формулам (2.4)–(2.7) представлен для первого интервала:

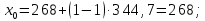
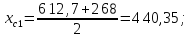
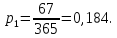
Дальнейшие расчеты сведены в таблицу 2.1.
Таблица 2.1 – Интервальный статистический ряд
|
Номер интервала |
Нижняя граница |
Верхняя граница |
Середина |
Частота
|
Относительная
частота
|
||
|
1 |
268 |
612,7 |
440,35 |
67 |
0,184 |
||
|
2 |
612,7 |
957,4 |
785,05 |
118 |
0,323 |
||
|
3 |
957,4 |
1302,1 |
1129,75 |
76 |
0,208 |
||
|
4 |
1302,1 |
1646,8 |
1474,45 |
35 |
0,096 |
||
|
5 |
1646,8 |
1991,5 |
1819,15 |
25 |
0,069 |
||
|
6 |
1991,5 |
2336,2 |
2163,85 |
23 |
0,063 |
||
|
7 |
2336,2 |
2680,9 |
2508,55 |
11 |
0,030 |
||
|
8 |
2680,9 |
3025,6 |
2853,25 |
7 |
0,019 |
||
|
9 |
3025,6 |
3370,3 |
3197,95 |
3 |
0,008 |
||
|
Сумма: |
365 |
1,000 |
|||||
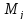

На
основании данных таблицы 2.1 строится
гистограмма (рисунок 2.1), наглядно
представляющая статистический ряд.
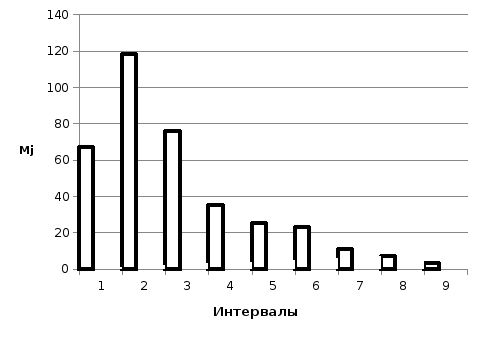
Рисунок 2.1 – Гистограмма статистического ряда
На рисунке 2.2 представим эмпирическую функцию плотности распределения f’(x) случайной величины ξ, а на рисунке 2.3 – эмпирическую функцию распределения F’(x).
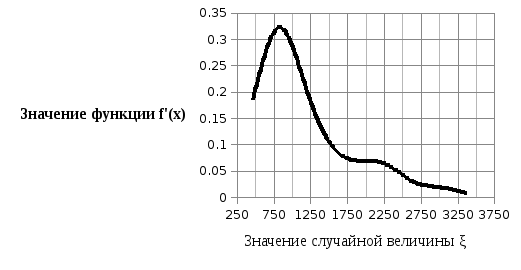
Рисунок 2.2 – Эмпирическая функция плотности распределения f’(x) случайной величины ξ
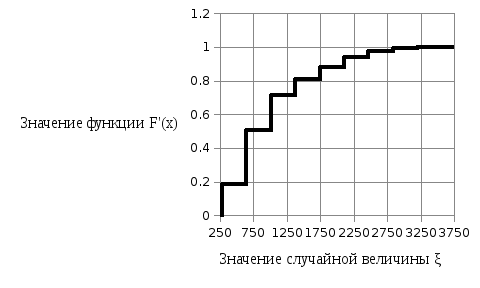
Рисунок 2.3 – Эмпирическая функция распределения F’(x) случайной величины ξ
Анализируя
рисунки 2.1–2.3, можно выдвинуть гипотезу
о логарифмически-нормальном законе
распределения случайной величины ξ,
характеризующей количество проданных
билетов. Альтернативная гипотеза Ha
заключается в том, что случайная величина
ξ не распределяется по логарифмически-нормальному
закону.
Функция плотности гипотетического распределения f(x) случайной величины ξ, распределенной по логарифмически-нормальному закону, определяется по формуле:
 ,
(2.8)
,
(2.8)
где
 – математическое ожидание логарифма
случайной величины ξ;
– математическое ожидание логарифма
случайной величины ξ;
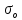 – среднеквадратическое
отклонение логарифма случайной величины
ξ;
– среднеквадратическое
отклонение логарифма случайной величины
ξ;
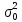 – дисперсия
логарифма случайной величины ξ.
– дисперсия
логарифма случайной величины ξ.
Математическое
ожидание логарифма случайной величины
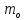 определяется по следующей формуле:
определяется по следующей формуле:
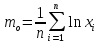 .
(2.9)
.
(2.9)
Среднеквадратическое
отклонение
 логарифма случайной величины ξ
определяется по формуле:
логарифма случайной величины ξ
определяется по формуле:
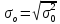 .
(2.10)
.
(2.10)
Дисперсия
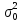 логарифма случайной величины ξ
рассчитывается по формуле:
логарифма случайной величины ξ
рассчитывается по формуле:
 .
(2.11)
.
(2.11)
Математическое
ожидание
 определяется по следующей формуле:
определяется по следующей формуле:
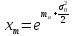 .
(2.12)
.
(2.12)
Среднеквадратическое
отклонение
 определяется по формуле:
определяется по формуле:
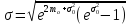 .
(2.13)
.
(2.13)
Коэффициент вариации рассчитывается по формуле:
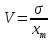 .
(2.14)
.
(2.14)
Функция распределения F(x) случайной величины ξ определяется по формуле:
 .
(2.15)
.
(2.15)
Проверка
выдвинутой гипотезы будет производиться
на основании критерия «значимости»
 Пирсона. Здесь α
– уровень значимости статистического
критерия; v
– число степеней свободы, которое
определяется по формуле:
Пирсона. Здесь α
– уровень значимости статистического
критерия; v
– число степеней свободы, которое
определяется по формуле:
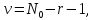 (2.16)
(2.16)
где
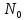 – количество интервалов статистического
ряда после его преобразования;
– количество интервалов статистического
ряда после его преобразования;
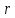 –
количество параметров функции
гипотетического распределения,
–
количество параметров функции
гипотетического распределения,
 .
.
Уровень значимости α статистического критерия – вероятность совершения ошибки 1-го рода, т.е. вероятность отклонения верной нулевой гипотезы Ho. Примем значение уровня значимости α=0,025.
При
проверке выдвинутой гипотезы критическое
значение
 сравнивается с выборочным значением
статистического критерия значимости
сравнивается с выборочным значением
статистического критерия значимости
 ,
рассчитанным по формуле:
,
рассчитанным по формуле:
 ,
(2.17)
,
(2.17)
где
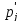 –
теоретическая вероятность попадания
в j-ый
интервал случайной величины ξ,
распределенной по гипотетическому
закону распределения.
–
теоретическая вероятность попадания
в j-ый
интервал случайной величины ξ,
распределенной по гипотетическому
закону распределения.
Если
значение
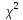 меньше
меньше
 ,
то выдвинутая гипотеза считается верной.
,
то выдвинутая гипотеза считается верной.
Теоретическая
вероятность
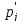 для логарифмически-нормального
распределения определяется через
функцию Лапласа
для логарифмически-нормального
распределения определяется через
функцию Лапласа
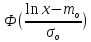 по формуле:
по формуле:
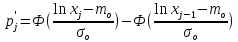 .
(2.18)
.
(2.18)
Значения функции Лапласа выбираются по специальным таблицам. При этом следует помнить, что функция Лапласа нечетная.
Также следует выполнить ряд преобразований статистического ряда распределения:
-
интервалы, частота Mj которых меньше 5, объединяются с одним из ближайших интервалов;
-
нижняя граница крайнего левого интервала принимает значение минус ∞, а верхняя граница крайнего правого интервала – плюс ∞.
Таким образом, преобразованный статистический ряд принимает следующий вид (таблица 2.2).
Таблица 2.2 – Преобразованный статистический ряд
|
Номер интервала |
Нижняя граница |
Верхняя граница |
Середина |
Частота
|
Относительная
частота
|
||
|
1 |
-∞ |
612,7 |
– |
67 |
0,184 |
||
|
2 |
612,7 |
957,4 |
785,05 |
118 |
0,323 |
||
|
3 |
957,4 |
1302,1 |
1129,75 |
76 |
0,208 |
||
|
4 |
1302,1 |
1646,8 |
1474,45 |
35 |
0,096 |
||
|
5 |
1646,8 |
1991,5 |
1819,15 |
25 |
0,069 |
||
|
6 |
1991,5 |
2336,2 |
2163,85 |
23 |
0,063 |
||
|
7 |
2336,2 |
2680,9 |
2508,55 |
11 |
0,030 |
||
|
8 |
2680,9 |
+∞ |
– |
10 |
0,027 |
||
|
Сумма: |
365 |
1,000 |
|||||

Далее
производится расчет по формулам
(2.9)–(2.14) и (2.16) (расчет по формулам (2.9) и
(2.11) произведен с использованием программы
StatGraphics
Plus
v5.0.1.
Статистические характеристики выборки
представлены в таблице 2.3.
Таблица 2.3 – Статистические характеристики выборки
|
Показатель |
Значение |
|
Математическое ожидание |
1113,26 |
|
Медиана |
938 |
|
Мода |
445,3 |
|
Стандартное отклонение |
613,462 |
|
Дисперсия выборки |
376335 |
|
Эксцесс |
1,019 |
|
Минимум |
268 |
|
Максимум |
3370 |
|
Сумма |
406340 |
|
Размах выборки |
3102 |
|
Коэффициент вариации |
0,551 |
По формуле (2.18) производится расчет для первого интервала:
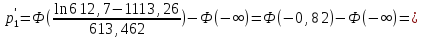
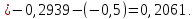
Дальнейшие расчеты сведены в таблицу 2.4.
Таблица
2.4–
Расчет
теоретических частот
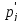
|
Номер интервала |
Нижняя граница |
Верхняя граница |
Теоретическая
частота
|
|
|
1 |
-∞ |
612,7 |
0,2061 |
|
|
2 |
612,7 |
957,4 |
0,1952 |
|
|
3 |
957,4 |
1302,1 |
0,2204 |
|
|
4 |
1302,1 |
1646,8 |
0,1861 |
|
|
5 |
1646,8 |
1991,5 |
0,1158 |
|
|
6 |
1991,5 |
2336,2 |
0,0531 |
|
|
7 |
2336,2 |
2680,9 |
0,0181 |
|
|
8 |
2680,9 |
+∞ |
0,0052 |
|
|
Сумма: |
1,0000 |
|||
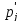
На
основании данных таблицы 2.4 по формуле
(2.17) рассчитывается выборочное значение
статистического критерия значимости
 :
:




Критическое
значение
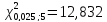 критерия «значимости» Пирсона больше
расчетного
критерия «значимости» Пирсона больше
расчетного
 .
Таким образом, выдвинутая гипотеза о
логарифмически-нормальном распределении
случайной величины ξ, характеризующей
количество продаваемых в день билетов,
считается верной и принимается для
дальнейших расчетов.
.
Таким образом, выдвинутая гипотеза о
логарифмически-нормальном распределении
случайной величины ξ, характеризующей
количество продаваемых в день билетов,
считается верной и принимается для
дальнейших расчетов.
Статистическая обработка данных приложения В выполнена с помощью программного обеспечения StatGraphics Plus v5.0.1. Результаты обработки представлены в приложении Г.
Данные приложения Г позволяют сделать вывод о нормальном распределении случайной величиной, характеризующей количество справочных запросов в день.
