

Среднее линейное отклонение
Мудрые математики и статистики придумали более надежный показатель, хотя и несколько другого назначения – среднее линейное отклонение. Этот показатель характеризует меру разброса значений совокупности данных вокруг их среднего значения.
Для того, чтобы показать меру разброса данных нужно вначале определиться, относительно чего этот самый разброс будет считаться - jбычно это средняя величина. Дальше нужно посчитать, насколько значения анализируемой совокупности данных находятся далеко от средней. Понятное дело, что каждому значению соответствует некоторая величина отклонения, но нас же интересует общая оценка, охватывающая всю совокупность. Поэтому рассчитывают среднее отклонение по формуле обычной средней арифметической. Но! Но для того, чтобы рассчитать среднее из отклонений, их нужно вначале сложить. И если мы сложим положительные и отрицательные числа, то они взаимоуничтожатся и их сумма будет стремиться к нулю. Чтобы этого избежать, все отклонения берутся по модулю, то есть все отрицательные числа становятся положительными. Вот теперь среднее отклонение будет показывать обобщенную меру разброса значений. В итоге, средне линейное отклонение будет рассчитываться по формуле:
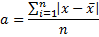
где
a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных,
оператор суммирования, надеюсь, никого не пугает.
Рассчитанное по указанной формуле среднее линейное отклонение отражает среднее абсолютное отклонение от средней величины по данной совокупности.

На картинке красная линия - это среднее значение. Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор фирмы провести статистический анализ длины черенков. Отобрал 10 штук и замерял их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно в среднем на 16 см. Есть, о чем поговорить с работниками. На самом деле я не встречал реального использования данного показателя, поэтому пример придумал сам. Тем не менее, в статистике есть такой показатель.
Дисперсия
Как и среднее линейное отклонение, дисперсия также отражает меру разброса данных вокруг средней величины.
Формула для расчета дисперсии выглядит так:
 (для вариационных
рядов (взвешенная дисперсия) )
(для вариационных
рядов (взвешенная дисперсия) )
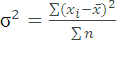 (для несгруппированных
данных (простая дисперсия))
(для несгруппированных
данных (простая дисперсия))
Где:
σ2 –
дисперсия, Xi –
анализируемsq
показатель (значение признака), ![]() –
среднее значение показателя, fi –
количество значений в анализируемой
совокупности данных.
–
среднее значение показателя, fi –
количество значений в анализируемой
совокупности данных.
Дисперсия - это средний квадрат отклонений.
Сначала рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, умножается на частоту соответствующего значения признака, складывается и затем делится на количество значений в данной совокупности.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который используется для других видов статистического анализа.
Упрощенный способ расчета дисперсии

Среднеквадратическое отклонение
Чтобы использовать дисперсию дл анализа данных из нее извлекают квадратный корень. Получается так называемое среднеквадратическое отклонение.
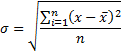
Кстати, стандартное отклонение еще называют сигмой – от греческой буквы, которой его обозначают.
Среднеквадратическое отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными. Как правило, среднеквадратические показатели в статистике дают более точные результаты, чем линейные. Следовательно, среднеквадратическое отклонение является более точным показателем меры рассеяния данных, чем среднее линейное отклонение.