

ГОСЫ / Paral_programirovanie_otvety_3vopros
.pdf8. Общая характеристика механизма передачи данных. Понятие алгоритма маршрутизации и методов передачи данных.
Очевидно, что временные задержки при передаче данных по каналам связи при взаимодействии процессов влияют на эффективность параллельных вычислений.
Алгоритмы маршрутизации определяют путь передачи данных от процессора-источника до процессора получателя сообщения. Решение задачи передачи данных включает создание:
−оптимальных, определяющих кратчайшие пути передачи данных, и неоптимальных алгоритмов маршрутизации;
−детерминированных и адаптивных методов выбора маршрутов (адаптивные алгоритмы определяют пути передачи данных в зависимости от существующей загрузки коммуникационных каналов).
Кчислу наиболее распространенных оптимальных алгоритмов относится класс методов покоординатной маршрутизации (dimension-ordered routing), в которых поиск путей передачи данных осуществляется поочередно для каждой размерности топологии сети коммуникации.
Например, для двумерной решетки такой подход приводит к маршрутизации, при которой передача данных сначала выполняется по одному направлению (например, по горизонтали до достижения вертикали процессоров, в которой располагается процессор назначения), а затем данные передаются вдоль другого направления (данная схема известна под названием алгоритма XY-маршрутизации).
Для гиперкуба покоординатная схема маршрутизации может состоять, например, в
циклической передаче данных процессору, определяемому первой различающейся битовой позицией в номерах процессоров, на котором сообщение располагается в данный момент времени и на который сообщение должно быть передано.
Методы передачи данных
Время передачи данных между процессорами определяет длительность выполнения параллельного алгоритма в многопроцессорной вычислительной системе. Основные характеристики, описывающие время передачи данных включает:
− время начальной подготовки (tн) характеризует длительность подготовки сообщения для передачи, поиска маршрута в сети и т.п.;
21
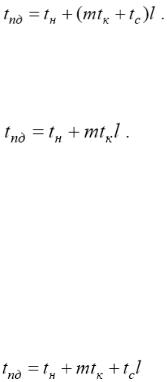
− время передачи служебных данных (tс) между двумя соседними процессорами (т.е.
для процессоров, между которыми имеется физический канал передачи данных); к
служебным данным может относиться заголовок сообщения, блок данных для обнаружения ошибок передачи и т.п.;
− время передачи одного слова данных по одному каналу передачи данных (tк);
длительность подобной передачи определяется полосой пропускания коммуникационных каналов в сети.
К числу наиболее распространенных методов передачи данных относятся два основные способа коммуникации.
Первый – выполняет передачу сообщений как неделимых (атомарных) блоков информации (store-and-forward routing or SFR). В этом случае процессор-отправитель готовит весь объем данных для передачи, определяет процессор, которому следует направить данные,
и запускает операцию пересылки данных. Процессор-получатель сообщения, сначала осуществляет прием полностью всех пересылаемых данных и только затем приступает к пересылке принятого сообщения далее по маршруту. Время пересылки данных tпд для метода передачи сообщения размером m байт по маршруту длиной l определяется выражением
При достаточно длинных сообщениях временем передачи служебных данных можно пренебречь и выражение для времени передачи данных может быть записано в более простом виде
Второй способ - выполняет передачу пересылаемых сообщений в виде блоков информации меньшего размера (пакетов), в результате чего передача данных может быть сведена к передаче пакетов. В этом случае (cut-through routing or CTR) принимающий процессор может осуществлять пересылку данных по дальнейшему маршруту непосредственно сразу после приема очередного пакета, не дожидаясь завершения приема данных всего сообщения. Время пересылки данных при использовании метода передачи пакетов будет определяться выражением
22
В большинстве случаев метод передачи пакетов приводит к более быстрой пересылке данных; кроме того, данный подход снижает потребность в памяти для хранения пересылаемых данных для организации приема-передачи сообщений, а для передачи пакетов могут использоваться одновременно разные коммуникационные каналы. С другой стороны,
реализация пакетного метода требует разработки более сложного аппаратного и программного обеспечения сети, может увечить накладные расходы (время подготовки и время передачи служебных данных); при передаче пакетов возможно возникновения конфликтных ситуаций (дедлоков).
23
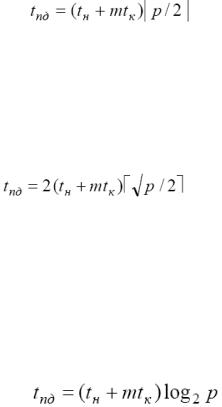
9. Анализ трудоемкости основных операций передачи данных на примере выполнения парных межпроцессорных обменов и коллективной операции широковещательной передачи данных.
1) Передача неделимых данных от одного процессора всем остальным процессорам сети
Операция передачи данных от одного процессора всем остальным процессорам сети (one- to-all broadcast or single-node broadcast) является одним из наиболее часто выполняемых коммуникационных действий. Подобные операции используются при реализации матрично-
векторного произведения, решении систем линейных уравнений при помощи метода Гаусса др.
Передача сообщений для кольцевой топологии Процессор-источник рассылки может передать данных сразу двум своим соседям, которые, в свою очередь, приняв сообщение,
организуют пересылку далее по кольцу. Время выполнения рассылки в этом случае будет определяться как
Для топологии решетки-тора, рассылка может быть выполнена в 2 этапа. На первом этапе выполняется передача сообщения всем процессорам сети, располагающимся на той же горизонтали решетки, что и процессор-источник; на втором этапе процессоры, получившие копию данных, рассылают сообщения по своим соответствующим вертикалям. Время выполнения рассылки в этом случае будет определяться как
Для гиперкуба рассылка может быть выполнена в N- этапной процедуры передачи. На первом этапе процессор-источник передает данные одному из своих соседей (например, по первой размерности) – в результате после первого этапа имеется два процессора, имеющих копию пересылаемых данных. На втором этапе два процессора, получившие данные,
пересылают сообщение своим соседям по второй размерности и т.д. Время выполнения рассылки в этом случае будет определяться как
Лучшие показатели имеет топология типа гиперкуба.
24
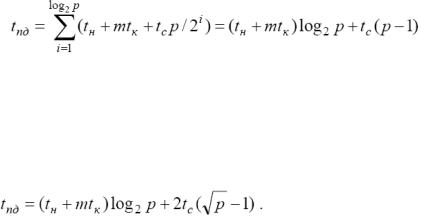
2) Передача пакетов данных от одного процессора всем остальным процессорам сети
Для топологии кольца алгоритм рассылки может быть получен путем логического представления кольцевой структуры сети в виде гиперкуба. На первом этапе, процессор-
источник сообщения передает данные процессору, находящемуся на расстоянии p/2 от исходного процессора. На втором этапе оба процессора, уже имеющие рассылаемые данные после первого этапа, передают сообщения процессорам, находящиеся на расстоянии p/4 и т.д.
Время выполнения рассылки в этом случае будет определяться как
(при достаточно больших сообщениях, временем передачи служебных данных можно пренебречь).
Для топологии решетки-тора алгоритм рассылки аналогичен методу передачи неделимых сообщений. Время выполнения рассылки в этом случае будет определяться как
Для гиперкуба алгоритм рассылки алгоритм рассылки также аналогичен методу передачи неделимых сообщений.
3) Передача неделимых данных от всех процессоров всем процессорам сети
Операция передачи данных от всех процессоров всем процессорам сети (allgather, broadcast) является обобщением двухточечной операции передачи. Подобные операции широко используются при реализации матричных вычислений.
Множественную рассылку можно реализовать выполнением соответствующего набора двухточечных операций. Однако это не оптимальный подход для многих топологий сети,
поскольку часть операций двухточечных передачи может быть выполнена параллельно.
При выполнении передачи сообщений для кольцевой топологии каждый процессор может выполнять рассылку своего сообщения одновременно (в выбранном направлении по кольцу). В любой момент времени каждый процессор выполняет прием и передачу данных;
завершение операции множественной рассылки произойдет через (p-1) цикл передачи данных. Время выполнения операции рассылки равно:
25
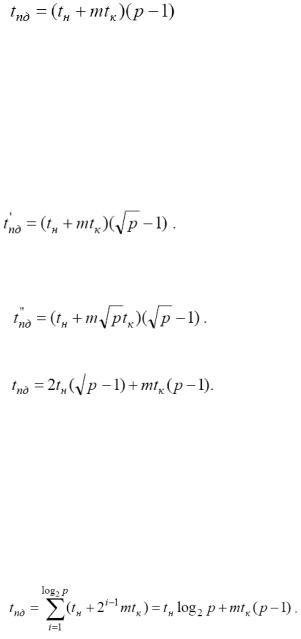
Для топологии типа решетки-тора множественная рассылка сообщений может быть выполнена обобщением алгоритма, передачи данных для кольцевой структуры сети по следующей схеме. На первом этапе выполняется передача сообщений раздельно по всем процессорам сети, располагающимся на одних и тех же горизонталях решетки (в результате на каждом процессоре одной и той же горизонтали формируются укрупненные сообщения размера 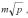 , объединяющие все сообщения горизонтали). Время выполнения этапа
, объединяющие все сообщения горизонтали). Время выполнения этапа
На втором этапе рассылка данных выполняется по процессорам сети, образующим вертикали решетки. Длительность этого этапа
Общая длительность операции рассылки определяется соотношением:
Для гиперкуба алгоритм множественной рассылки сообщений может быть получен путем обобщения алгоритма передачи данных для топологии типа решетки на размерность гиперкуба N. В этом случае, схема коммуникации состоит в следующем. На каждом этапе i, 1≤ i≤N, выполнения алгоритма используются все процессоры сети, которые обмениваются своими данными со своими соседями по i размерности и формируют объединенные сообщения. Время операции рассылки может быть получено при помощи выражения
4) Передача пакетов данных от всех процессоров всем процессорам сети.
Применение более эффективного для кольцевой структуры и топологии решетки-тора метода передачи данных не приводит к улучшению времени выполнения операции множественной рассылки, поскольку обобщение алгоритмов выполнения операции двухточечных обменов на случай множественной рассылки приводит к перегрузке каналов передачи данных (т.е. к существованию ситуаций, когда в один и тот же момент времени для передачи по одной и той линии передачи имеется несколько ожидающих пересылки пакетов данных). Перегрузка каналов приводит к задержкам при пересылках данных, что и не позволяет проявиться всем преимуществам метода передачи пакетов.
26

10. Анализ трудоемкости основных операций межпроцессорных обменов на примере выполнения коллективных операций передачи данных по схеме “от всех – всем” с рассмотрением обобщенного варианта.
Обобщенная передача данных (all to all) от всех процессоров всем процессорам сети представляет собой общий случай коммуникационных действий. Необходимость в выполнении подобных операций возникает в параллельных алгоритмах быстрого преобразования Фурье, транспонирования матриц и др.
Рассмотрим способы выполнения обобщенной множественной рассылки для разных методов передачи данных.
1) Передача неделимых сообщений.
Для кольцевой топологии каждый процессор выполняет передачу исходных сообщений своему соседу (в выбранном направлении по кольцу). Затем процессоры выполняют прием пришедших к ним данных, где среди принятой информации выбирают свои сообщения, после чего выполняет дальнейшую рассылку оставшейся части данных. В этом случае время выполнения передач данных равна:
Для топологии решетки-тора на первом этапе выполняется передача сообщений раздельно по всем процессорам сети на одной горизонтали решетки, при этом каждому процессору по горизонтали передаются только те исходные сообщения, что должны быть направлены процессорам соответствующей вертикали решетки. В результате, на каждом процессоре собираются p сообщений, предназначенных для рассылки по одной из вертикалей решетки. На втором этапе передача данных выполняется по процессорам вертикали решетки. Время выполнения передач данных равно:
Для гиперкуба алгоритм передачи сообщений можно рассматривать как обобщение выполнения передачи данных для топологии решетки на размерность гиперкуба N. Здесь схема коммуникации состоит в следующем. На каждом этапе i, 1≤i≤N, выполнения алгоритма все процессоры сети, обмениваются своими данными с соседними по i размерности процессорами и формируют объединенные сообщения. При этом, каждый процессор такой пары посылает только те сообщения, которые предназначены для соседних процессоров.
27
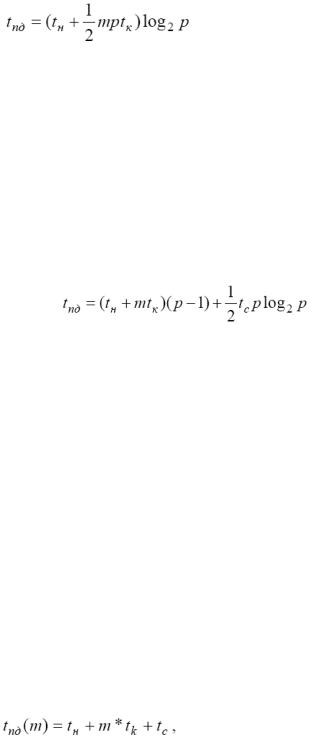
Время выполнения передач данных равна:
2) Передача пакетов.
Использование метода передачи пакетов не приводит к улучшению временных характеристик для операции обобщенной передачи данных. Например, для топологии
гиперкуб передача может быть выполнена за p-1 последовательных итераций. На каждой итерации все процессоры разбиваются на взаимодействующие пары процессоров. Разбиение на пары может быть выполнено таким образом, чтобы передаваемые между разными парами процессоров сообщения не использовали одни и те же пути передачи данных. В этом случае время выполнения передач данных равно:
Оценка трудоемкости операций передачи данных для кластерных систем
Топология кластерных вычислительных систем представляет собой полный граф, в
котором, имеются определенные ограничения на одновременность выполнения коммуникационных операций. Например, при использовании концентраторов передача данных одновременно может выполняться только между двумя процессорными узлами;
переключатели могут обеспечивать взаимодействие нескольких непересекающихся пар процессоров.
В кластерных системах в качестве основного способа выполнения коммуникационных операций используется метод передачи пакетов (реализуемый, как правило, на основе протокола TCP/IP).
1. Для кластерной системы с топологией в виде полного графа и пакетным способом передачи сообщений, трудоемкость операции коммуникации между двумя процессорными узлами равна (модель А)
оценка подобного вида следует из соотношений для метода передачи пакетов при единичной длине пути передачи данных, т.е. при l = 1. Это модель, в которой предполагается, что время
подготовки данных 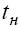 - постоянно (не зависит от объема передаваемых данных), время
- постоянно (не зависит от объема передаваемых данных), время
передачи служебных данных 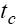 не зависит от количества передаваемых пакетов и т.п.
не зависит от количества передаваемых пакетов и т.п.
28

Однако эти предположения не соответствуют действительности и временные оценки,
получаемые в результате использования модели, могут не обладать необходимой точностью.
2. Поэтому более точная формула будет иметь следующий вид (модель В):
,
где  - количество пакетов, на которое разбивается передаваемое
- количество пакетов, на которое разбивается передаваемое
сообщение, величина  определяет максимальный размер пакета, который может быть передан по сети (по умолчанию для операционной системы MS Windows в сети Fast Ethernet
определяет максимальный размер пакета, который может быть передан по сети (по умолчанию для операционной системы MS Windows в сети Fast Ethernet
=1500 байт), а 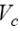 - объем служебных данных в каждом из пересылаемых пакетов (для протокола TCP/IP, ОС Windows 2000 и сети Fast Ethernet =78 байт). Величина
- объем служебных данных в каждом из пересылаемых пакетов (для протокола TCP/IP, ОС Windows 2000 и сети Fast Ethernet =78 байт). Величина
 характеризует аппаратную составляющую латентности и зависит от параметров
характеризует аппаратную составляющую латентности и зависит от параметров
используемого сетевого оборудования, значение  задает время подготовки одного
задает время подготовки одного
байта данных для передачи по сети. Величина латентности  увеличивается линейно в зависимости от объема передаваемых данных. При этом
увеличивается линейно в зависимости от объема передаваемых данных. При этом
предполагается, что подготовка данных для передачи второго и всех последующих пакетов может быть совмещена с пересылкой по сети предшествующих пакетов и латентность, тем самым, не может превышать величины
Помимо латентности, в приведенных формулах оценки времени коммуникационной операции можно уточнить также правило вычисления времени передачи данных
что позволяет теперь учитывать эффект увеличения объема передаваемых данных при росте числа пересылаемых пакетов за счет добавления служебной информации (заголовков пакетов).
29
Вопросы по курсу “Параллельное программирование”.
1. Интерфейс передачи сообщений (MPI). Основные понятия и определения.
MPI является библиотекой функций обмена данными между процессами, реализованной для языков С и Fortran. Головной организацией проекта MPI является Аргоннская национальная лаборатория США. После появления первой версии стандарта MPI в мае 1994
года MPI получил широкое распространение. В настоящее время стандарт MPI адаптирован для большинства суперЭВМ и кластеров.
Под параллельной программой в рамках MPI понимается множество одновременно выполняемых процессов, имеющих раздельные адресные пространства. Каждый процесс параллельной программы порождается на основе копии одного и того же программного кода
(модель SPMP - одна программа множество процессов single program multiple processes).
Программный код, представленный в виде исполняемой программы, должен быть доступен в момент запуска параллельной программы на всех используемых процессорах.
Количество процессов и число используемых процессоров определяется в момент запуска параллельной программы средствами среды исполнения MPI и в ходе вычислений меняться не может (в стандарте MPI-2 предусматривается возможность динамического изменения количества процессов). Все процессы программы последовательно нумеруются от 0 до p-1,
где p есть общее количество процессов. Номер процесса называется рангом процесса.
Процессы параллельной программы объединяются в группы. Под коммуникатором в MPI
понимается специально создаваемый служебный объект, объединяющий в своем составе группу процессов, используемых при выполнении операций передачи данных.
Коммуникаторы таким образом, ограничивают "пространственную" область коммуникации. Коммуникаторы разделяются на два вида: интра-коммуникаторы
(внутригрупповые коммуникаторы), предназначенные для операций в пределах отдельной группы процессов, и интер-коммуникаторы (межгрупповые коммуникаторы),
предназначенные для выполнения двух точечных обменов между процессами, входящими в две группы процессов.
30