

1. Оценка максимально достижимого параллелизма, закон Амдаля. Понятие ускорения и эффективности параллельных алгоритмов. Анализ масштабируемости параллельных вычислений.
Абсолютно параллельных алгоритмов, за исключением тривиальных случаев, не бывает. Как правило, алгоритм параллельной программы представляет собой последовательность параллельных и последовательных участков, т.е. распределение данных (параллельная часть) и их обработку на всех или отдельных процессах (последовательно-параллельная часть). Поэтому естественно, чем меньше время выполнения последовательных участков, тем параллельный алгоритм теоретически должен бать эффективнее. Например, если алгоритм таков, что на первом и последнем этапах – работа последовательна и составляет 10%, центральная часть алгоритма параллельна и составляет 90% всей работы, то это ещё не означает, что мы получим высокую эффективность такого параллельного алгоритма.
Достижению максимального ускорения может препятствовать существование в выполняемых параллельных вычислениях последовательных расчетов, которые не могут быть распараллелены. Обосновывает этот факт закон Амдаля (Amdahl).
Зако́н Амдала(англ.Amdahl's law, иногда такжеЗакон Амдаля-Уэра) — иллюстрирует ограничение ростапроизводительностивычислительной системыс увеличением количествавычислителей.
«В случае, когда задача разделяется на несколько частей, суммарное время её выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента».[1]Согласно этому закону, ускорение выполнения программы за счётраспараллеливанияеё инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.
Закон Амдаля
Пусть процессоры однородны по производительности. Т0 – время выполнения последовательной части параллельного алгоритма, например, генерирование начальных данных и обработка полученного при решении задачи результата.
Т1, Т2, ... Тp – время последовательной работы, выполняемой каждым процессором без взаимодействия между собой. Тогда время выполнения задачи на p процессорах определяется неравенством:
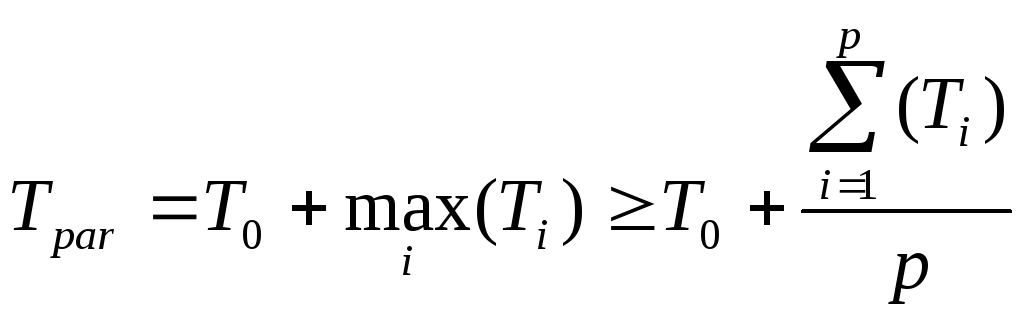 где i=1, 2, ... p.
Равенство получается, когда Тi равны
между собой. Отсюда, подставляя
где i=1, 2, ... p.
Равенство получается, когда Тi равны
между собой. Отсюда, подставляя
![]() =
Tseq
– T0,
где Tseq
есть время выполнения задачи на одном
процессоре, получаем:
=
Tseq
– T0,
где Tseq
есть время выполнения задачи на одном
процессоре, получаем:
Tpar
≥ T0
+
![]() .
Делим на Tseq
и, обозначая через f =
T0
/ Tseq
- долю (fraction) последовательного участка
в общем объеме вычислений, получим:
.
Делим на Tseq
и, обозначая через f =
T0
/ Tseq
- долю (fraction) последовательного участка
в общем объеме вычислений, получим:
![]() .
(1.1)
.
(1.1)
Ускорение (Speedup) – это отношение времени выполнения задачи в последовательном режиме (на 1 процессоре), ко времени выполнения задачи в параллельном режиме (на p процессорах).
S
![]() ,
используя неравенство (1.1), получим
,
используя неравенство (1.1), получим
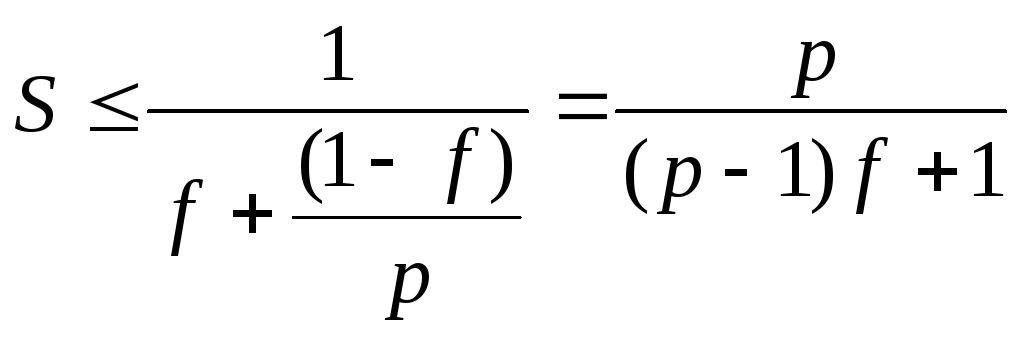 (1.2)
(1.2)
Отсюда видно, что
при f=0 и равенстве Ti
получим S=p, при f >0 и p → ∞, получим
![]() .
Данная функция является монотонно-возрастающей
по p и, значит, достигает максимума на
бесконечности. Следовательно,
ни на каком числе процессоров
ускорение
счета не может превысить обратной
величины доли последовательного участка.
.
Данная функция является монотонно-возрастающей
по p и, значит, достигает максимума на
бесконечности. Следовательно,
ни на каком числе процессоров
ускорение
счета не может превысить обратной
величины доли последовательного участка.
Рассматривая закон Амдаля, мы предполагали, что доля последовательных расчетов f является постоянной величиной и не зависит от параметра n, определяющего вычислительную сложность решаемой задачи. Однако для большого ряда задач доля f=f(n) является убывающей функцией от n, и в этом случае ускорение для фиксированного числа процессоров может быть увеличено за счет уменьшения доли последовательной работы, выполняемой каждым процессором. Иначе говоря, ускорение Sp= Sp(n) является возрастающей функцией от параметра n (данное утверждение часто называют эффектом Амдаля).
Эффективность распараллеливания.
Эффективность распараллеливания – это способность алгоритма использовать все задействованные в выполнении задачи процессоры на 100%. Формула вычисления эффективности:
![]() (1.2)
(1.2)
Т.е. если ускорение S = p (максимально возможное на p процессорной машине), то эффективность распараллеливания задачи равна 100%. Используя закон Амдаля получаем верхнюю оценку эффективности:
E
≤ 100%
![]() (1.3)
(1.3)
Например, E ≤ 52.25% для p=100 и f=0.01 и E ≤ 9.1% для p=1000 и f=0.01.
Вывод. При малой доли последовательной работы увеличение количества процессов приводит к ухудшению параллельной эффективности (причина – с ростом процессов растет количество обменов). Например, если f=0.01 (1%), то Е<100 и использовать для решения параллельной задачи более 100 процессоров нецелесообразно. Для повышения эффективности, как правило, не распараллеливают управляющие части программы или небольшие участки вычислений, которые требуют интенсивной синхронизации процессов.
Для оценки ускорения рассматривают еще одну характеристику, которую называют ускорением масштабирования (scaled speedup). Данная оценка может показать, насколько эффективно могут быть организованы параллельные вычисления при увеличении сложности решаемых задач.
Масштабирование (scalable) – это способность параллельного алгоритма эффективно использовать процессоры при повышении сложности вычислений. Задача является масштабируемой, если при росте числа процессоров алгоритм обеспечивает пропорциональное увеличение ускорения при сохранении постоянного уровня эффективности использования процессоров.
Масштабируемость – это пропорциональное увеличение объема задачи с увеличением числа используемых для ее решения процессоров. Наличие масштабируемости задач является важным свойством тестовых систем оценки производительности параллельных вычислительных систем.
Плохая масштабируемость параллельного приложения на MPP-системе может быть вызвана а) ростом затрат на коммуникации при увеличении числа используемых процессоров; б) неравномерностью распределения вычислительной нагрузки между процессорами.
При увеличении количества процессоров с сохранением размерности задачи увеличивается общее количество вызовов функций MPI в программе. При этом накладные расходы на формирование и отправку сообщений растут, а объем вычислений, приходящихся на один процессор, падает, что и вызывает уменьшение эффективности параллелизации. Все большее негативное влияние в условиях возросшего количества сообщений будет оказывать латентность сети. Для кластеров, узлы которых являются симметричными мультипроцессорами, можно попытаться снизить стоимость коммуникаций, заменив внутри каждого узла многопроцессорную обработку на многопоточную.
Оценим накладные расходы (total overhead), которые имеют место при выполнении параллельного алгоритма T0 = P*Tp − T1 , где T1 - время выполнения последовательного алгоритма задачи, Tp - время выполнения алгоритма задачи на P процессорах.
Накладные расходы появляются за счет необходимости организации взаимодействия процессоров, синхронизации параллельных вычислений и т.п.
Используя введенное обозначение, можно получить новые выражения для времени параллельного решения задачи и соответствующего ускорения:
Tp = (T1 + T0)/P , Sp = T1/ Tp = (P* T1)/( T1 + T0)
Тогда эффективность использования процессоров можно выразить как
EP = Sp/P = T1/ (T1 + T0) = 1/(1+ T1/T0)
Тогда, если сложность решаемой задачи является фиксированной (T1=const), то при росте числа процессоров эффективность, как правило, будет убывать за счет роста накладных расходов T0. При фиксированном числе процессоров, эффективность можно улучшить путем повышения сложности решаемой задачи T1, поскольку предполагается, что при увеличении сложности накладные расходы T0 растут медленнее, чем объем вычислений T1.
Таким образом, при увеличении числа процессоров в большинстве случаев можно обеспечить определенный уровень эффективности при помощи соответствующего повышения сложности решаемых задач. В этой связи, важной характеристикой параллельных вычислений становится соотношение необходимых темпов роста сложности расчетов и числа используемых процессоров.
Также важной характеристикой разрабатываемых алгоритмов является стоимость (cost) вычислений, определяемая как произведение времени параллельного решения задачи и числа используемых процессоров.