

ГОСЫ / Paral_programirovanie_otvety_3vopros
.pdfслучаях вызов начала посылки сообщения является локальным: он заканчивается немедленно, безотносительно к состоянию других процессов.
Если при вызове операции приема обнаруживается нехватка некоторых системных
ресурсов, тогда он не может быть выполнен и возвращает код ошибки.
Не блокирующие передачи могут соответствовать блокирующим приемам и наоборот.
Дескриптор запроса (request)
Все не блокирующие вызовы и блокирующая операция приема создают объект
коммуникационного запроса и связывают его с дескриптором запроса (request). Дескриптор запроса является коммуникационным объектом. Когда операция передачи или приема завершена, дескриптор запроса устанавливается в MPI_REQUEST_NULL, при этом статусный объект (status), связанный с этим запросом, инициализируется (присваиваются значения элементам структуры status).
Между дескриптором запроса и статусом существует взаимно однозначное соответствие.
Если операция отправки или получения данных не закончилась, дескриптор запроса (request)
является активным, иначе имеет значение MPI_REQUEST_NULL. |
|
||||
Состояние статуса |
может |
соответствовать пришедшему |
сообщению или быть empty |
||
(пусто), в этом случае tag = MPI_ANY_TAG, |
error |
= MPI_SUCCESS, |
source = |
||
MPI_ANY_SOURCE. |
|
|
|
|
|
Завершение обмена |
|
|
|
|
|
Чтобы завершить |
не |
блокирующий обмен, |
используются функции |
MPI_Wait |
|
(MPI_Waitall) и MPI_Test (MPI_Testall). Если операции передачи и приема сообщений не
блокирует работу процесса, то операции завершения обменов являются блокирующими.
Функции завершения обмена с одной стороны необходимы для правильной работы
MPI (указывая, что статусный объект установлен, приемный буфер содержит принятое сообщение и процесс-получатель может обращаться к нему), с другой стороны гарантирует,
что бмен завершен и можно использовать данные из буфера обмена (процесса отправителя или получателя) не опасаясь того, что они будут испорчены.
Функции блокирующих и не блокирующих обменов могут использоваться совместно в любых комбинациях.
41
Семантика не блокирующих коммуникаций
Очередность. Операции не блокирующих коммуникаций упорядочены согласно порядку вызовов функций передачи и приема сообщений. Т.е. сообщения уходят из передающего процесса в порядке вызовов функций передачи. Очевидно, что на принимающий процесс сообщения могут приходить в произвольном порядке, в зависимости от топологии вычислительной системы (чем дальше узлы, длиннее коммуникационный путь, тем больше время доставки сообщения), исключение составляет выполнение программы на двух процессах, в этом случае сообщения не обгоняют друг друга. Все приходящие сообщения выстраиваются в очередь, каждое из них имеет служебную информацию: размер сообщения
(кол-во байт), номер процесса отправки и тег. Принимающий процесс выполняет вызовы функций приема сообщений, с аргументами кол-ва и типа принимаемых элементов (по ним определяется размер принимаемой информации в байтах), номером процесса, от которого принимается сообщение и тегом. По ним из очереди пришедших сообщений выбирается требуемое. Соответствующий дескриптор запроса request устанавливается в
MPI_REQUEST_NULL, а полям структуры status присваиваются значения.
42
5. Коллективные операции передачи данных. Основные определения. Принцип взаимодействия процессов при выполнении барьерной синхронизации и широковещательного обмена.
Под коллективными операциями в MPI понимаются операции над данными, в которых принимают участие все процессы в группе, определяемой одним коммуникатором. В
противном случае, происходит ошибка, и выполнение параллельной программы прекращается. Коммуникатор обеспечивает контекст для коллективных операций в группе.
Вызов коллективной функции на процессе возвращает управление сразу после того, как только его участие в коллективной операции завершено. Завершение вызова не означает, что другие процессы в группе завершили коллективную операцию, а только показывает, что процесс-отправитель может обращаться к буферу обмена. Таким образом, вызов коллективной операции имеет эффект синхронизации всех процессов в группе. Это утверждение не относится к барьерной функции (MPI_Barrier), которая при вызове блокирует процесс до тех пор, пока все процессы в группе не вызовут ее, выполняя тем самым явную синхронизацию.
Используемые в коллективных операциях типы данных, должны совпадать у процесса-
отправителя и процесса получателя. Условия соответствия типов для коллективных операций более строгие, чем аналогичные условия для парного обмена. А именно для коллективных операций количество посланных данных должно точно соответствовать количеству данных,
описанных в процессе-получателе. Коллективные операции могут иметь один процесс-
отправитель или получатель или отправителями/получателями являются все процессы в группе. Различные коллективные операции (широковещание, сбор данных) имеют единственный процесс-отправитель или процесс-получатель. Такой процесс называются корневым (root).
Некоторые аргументы в коллективных функциях определены как “существенные только для корневого процесса” и игнорируются для всех других участников операции.
Вызовы коллективных операций могут использовать те же коммуникаторы, что и парный обмен, при этом MPI гарантирует, что сообщения, созданные коллективными операциями, не будут смешаны с сообщениями, созданными парным обменом. Ключевым понятием в коллективных функциях является группа участвующих процессов, но в качестве явного аргумента выступает коммуникатор. Коммуникатор понимается как идентификатор группы,
связанный с контекстом. Не разрешается использовать в качестве аргумента
коллективной функции интер-коммуникатор (коммуникатор, соединяющий две группы).
43
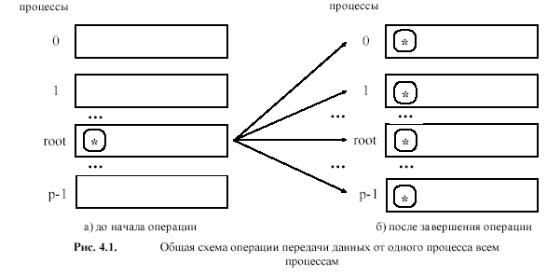
1.Барьерная синхронизация
Вряде ситуаций независимо выполняемые в процессах вычисления необходимо синхронизировать. Так, например, для измерения времени начала работы параллельной программы необходимо, чтобы для всех процессов одновременно были завершены все предварительные действия, перед окончанием работы программы все процессы должны завершить свои вычисления и т.п.
Синхронизация процессов, т.е. одновременное достижение процессами тех или иных точек
процесса вычислений, обеспечивается при помощи функции MPI:
MPI_Barrier (MPI_Comm comm)
Функция барьерной синхронизации блокирует вызывающий процесс, пока все процессы
группы не вызовут ее. В каждом процессе управление возвращается только тогда, когда все
процессы в группе вызовут данную операцию.
2. Широковещательная передача
Функция MPI_BCAST посылает сообщение из одного процесса всем процессам группы,
включая себя.
MPI_Bcast (buffer, count, datatype, root, comm )
IN/OUT buffer - адрес начала буфера |
IN count - количество записей в буфере (целое) |
IN datatype - тип данных в буфере |
IN root - номер корневого процесса (целое) |
IN comm - коммуникатор
44
Функция MPI_Bcast осуществляет рассылку данных из буфера buf, содержащего count
элементов типа type с процесса, имеющего номер root, всем процессам, входящим в
коммуникатор comm. Следует отметить, что:
1.Функция MPI_Bcast определяет коллективную операцию и, тем самым, при выполнении необходимых рассылок данных вызов функции MPI_Bcast должен быть осуществлен всеми процессами указываемого коммуникатора,
2.Указываемый в функции MPI_Bcast буфер памяти имеет различное назначение в разных процессах. Для процесса с рангом root, с которого осуществляется рассылка данных,
вэтом буфере должно находиться рассылаемое сообщение. Для всех остальных процессов указываемый буфер предназначен для приема передаваемых данных.
45
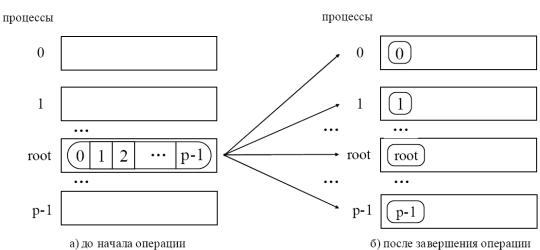
6. Принцип взаимодействия параллельных процессов при выполнении коллективных операций сборки и рассылки данных.
Коллективная операция рассылки данных от одного процесса всем (распределение данных) отличается от широковещательной рассылки тем, что корневой процесс передает всем процессам различные данные.
Общая схема операции обобщенной передачи данных от одного процесса всем процессам
При вызове этой функции процесс с рангом root выполняет передачу данных всем другим процессам в группе. Каждому процессу будет отправлено scount элементов. Процесс с рангом
0 получит блок данных буфера sbuf из элементов с индексами от 0 до scount-1, процессу с рангом 1 будет отправлен блок из элементов с индексами от scount до 2* scount-1 и т.д. Тем самым, общий размер отправляемого сообщения должен быть равен scount * p элементов, где p есть количество процессов в группе.
Т.к. функция MPI_Scatter - коллективная, ее вызов должен быть выполнен в каждом процессе группы. При выполнении операции рассылки данных корневой процесс из буфера отправки передает каждому процессу в группе, включая себя равные по размеру блоки данных. Сообщения выбираются из буфера отправки корневого процесса в порядке возрастания номеров процессов, т е. j-ый блок данных будет отправлен процессу с ранком j.
Буфер отправки игнорируется всеми некорневыми процессами. Значения sendcount и sendtype, должны быть одинаковыми для всех процессов, таким образом, количество посланных и полученных данных для корневого и каждого другого процесса должно попарно совпадать. Также одинаковыми на всех процессах должны быть аргументы root и comm.
46
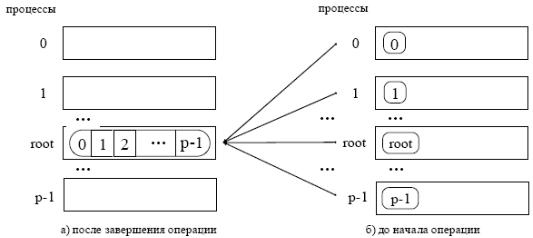
Корневой процесс использует все аргументы функции, остальные процессы используют только аргументы recvbuf, recvcount, recvtype, root, comm.
Коллективная операция сбора данных от всех процессоров в одном является обратной операцией рассылки.
При выполнении операции сборки данных MPI_GATHER каждый процесс, включая корневой, посылает содержимое своего буфера в корневой процесс. Корневой процесс получает сообщения, располагая их в порядке возрастания номеров процессов, т.е. данные,
посланные процессом j, помещаются в j-ый блок приёмного буфера корневого процесса. Для того, чтобы разместить все поступающие данные, размер приемного буфера rbuf должен быть равен scount * p элементов, где p есть количество процессов в группе. Функция MPI_Gather
также определяет коллективную операцию, и ее вызов при выполнении сбора данных должен быть выполнен в каждом процессе группы.
Значения sendcount, sendtype у процесса j должны быть такими же, как значения recvcount, recvtype корневого процесса. Таким образом, количество посланных и полученных данных для корневого и каждого другого процессов должно попарно совпадать.
В корневом процессе используются все аргументы функции, в то время как у остальных процессов используются только аргументы sendbuf, sendcount, sendtype, root, comm.
Аргументы comm и root должны иметь одинаковые значения во всех процессах.
47
7. Принцип взаимодействия параллельных процессов при выполнении обобщенных коллективных операций сборки и рассылки данных.
К обобщенным коллективным операциям сборки и рассылки данных относятся функции
MPI_Scatterv(…), MPI_Gatherv(…), MPI_Allgather(…),MPI_Alltoall(…).
В отличие от MPI_Gather при использовании функции MPI_Gatherv разрешается принимать от каждого процесса переменное число элементов данных, поэтому в функции
MPI_Gatherv аргумент recvcounts, является массивом, каждый элемент массива определяет количество принимаемых данных для каждого процесса.
Выполнение MPI_Gatherv будет давать такой же результат, как если бы каждый процесс,
включая корневой, посылал корневому процессу сообщение: MPI_Send(sendbuf, sendcount, sendtype, root, …), а принимающий процесс выполнил n операций приема:
MPI_Recv(recvbuf+displs[i]*extern(recvtype), recvcounts[i], recvtype, i, …), где extent(recvtype) это протяжённость типа (количество байт), получаемая с помощью вызова
MPI_Type_extent().
Сообщения помещаются в буфер принимающего процесса в порядке возрастания номеров процессов, от которых они приходят, то есть данные, посланные процессом i, помещаются в i-ю часть принимающего буфера recvbuf на корневом процессе. i-я часть recvbuf начинается со смещения displs[i].
В принимающем процессе используются все аргументы функции MPI_Gatherv, а на всех других процессах используются только аргументы sendbuf, sendcount, sendtype, root, comm.
Переменные comm и root должны иметь одинаковые значения во всех процессах.
Операция рассылки является противоположной операцией сборки. MPI_Scatterv
функционально расширяет MPI_Scatter, допуская передачу переменного количества данных для каждого процесса, обладает большей гибкостью при выборке передаваемых данных из корневого процесса. Количество передаваемых данных должно быть равно количеству получаемых, попарно между каждым процессом и корнем. Допустимо различие типов между посылающим и принимающим процессами. Например, передача 3 элементов типа
MPI_DOUBLE может быть принята 24 элементами типа MPI_BYTE.
48

MPI_Allgather можно рассматривать, как выполнение каждым процессом операции
MPI_Gather, где все процессы получают результат, а не только корень. J-ый блок данных посылается каждым процессом и принимается каждым процессом в j-ый блок буфера
recvbuf.
MPI_ALLTOALL является расширением MPI_ALLGATHER на случай, когда каждый процесс посылает конкретные данные каждому получателю. J-ый блок, посылаемый процессом i, будет получен процессом j и помещён в i-ый блок буфера recvbuf.
Значения sendcount, sendtype в каждом процессе должны быть одинаковыми. Т.е.
количество посланных данных должно быть равно количеству полученных данных между каждой парой процессов. Допустимо различие типов между посылающим и принимающим процессами.
Результат выполнения операции эквивалентен случаю, если бы каждый процесс передал сообщение каждому процессу (включая себя), вызвав
MPI_SEND(sendbuf + i sendcount extent(sendtype), sendcount, sendtype, i, ...),
и принял сообщение от каждого процесса, вызвав
MPI_RECV(recvbuf + i recvcount extent(recvtype), recvcount, recvtype, i, ...).
49
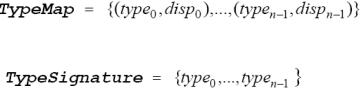
8.Понятие производных типов данных MPI. Конструирование производных типов данных.
Операции обмена MPI используют только непрерывный буфер, содержащий последовательности элементов одного типа. Однако часто возникает необходимость передавать сообщения, которые содержат значения различных типов или посылать несмежные данные. Один из способов передачи таких данных – это упаковать разные по типу данные в один буфер на стороне отправителя и распаковать обратно на стороне получателя сообщения. (MPI содержит функции упаковки и распаковки данных: MPI_Pack и MPI_Unpack) Однако это не эффективно, поскольку требуется дополнительная операция копирования из памяти в память на передающем и принимающем процессах. Другой, более оптимальный способ - создание производных типов данных. Такой механизм, позволяет передавать данные различной структуры и размера, выполняя эту передачу непосредственно из памяти, т.е. без дополнительного копирования. Аналогично тому, как создаются производные типы данных в Си, производные типы данных MPI, конструируются с использованием специальных конструкторов из базовых типов либо из ранее созданных типов данных.
В общем случае описываемые значения не обязательно непрерывно располагаются в памяти. Задание типа данных в MPI выполняется созданием карты типа (type map) в виде последовательности базовых типов данных и смещением адреса в памяти относительно начала некоторого базового адреса, т.е.
Часть карты типа с указанием только типов значений называется сигнатурой типа:
Сигнатура типа описывает, какие базовые типы данных образуют производный тип данных MPI. Смещения карты типа определяют, где находятся значения данных.
Например, пусть в сообщение должны входить значения переменных:
double a; /* адрес 24 */ double b; /* адрес 40 */ int n; /* адрес 48 */
Тогда производный тип для описания таких данных должен иметь карту типа следующего вида:
50