

Acid-свойства транзакций
Характеристики транзакцийописываются в терминах ACID.
Atomicity, Consistency, Isolation, Durability – неделимость(атомарность),согласованность(целостность),изолированность,устойчивость(живучесть).
Транзакция неделима в том смысле, что представляет собой единое целое. Все ее компоненты либо имеют место, либо нет. Не бывает частичной транзакции. Если может быть выполнена лишь часть транзакции, она отклоняется.
Транзакция является согласованной, потому что не нарушает бизнес-логику и отношения между элементами данных, что обеспечивает целостность данных. Это свойство очень важно при разработке клиент-серверных систем, поскольку в хранилище данных поступает большое количество транзакций от разных подсистем и объектов. Если хотя бы одна из них нарушит целостность данных, то все остальные могут выдать неверные результаты.
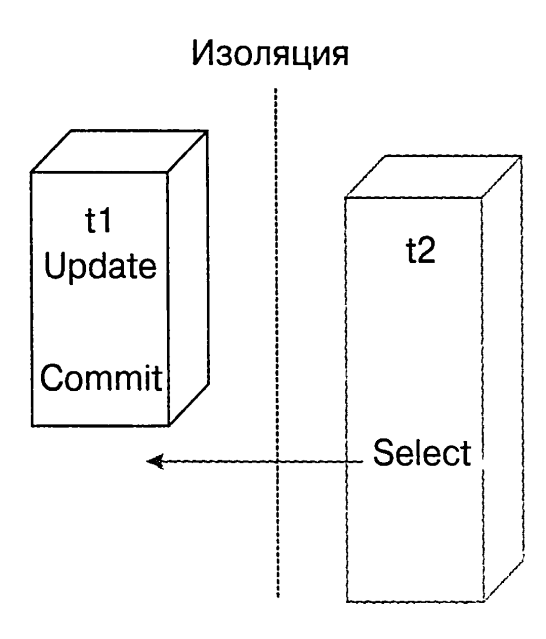
Транзакция всегда изолирована, поскольку ее результаты самодостаточны. Они не зависят от предыдущих или последующих транзакций – это свойство называется сериализуемостью и означает, что транзакции в последовательности независимы (каждая транзакций отделена от эффекта других транзакций).
Транзакция устойчива. После своего завершения она сохраняется в системе и выполняется фиксация транзакции, означающая, что ее действие постоянно даже при сбое системы. При этом подразумевается некая форма хранения информации в постоянной памяти как часть транзакции. Ядро базы данных должно быть спроектировано так, чтобы даже в случае выхода из строя устройства данных, БД можно было восстановить до состояния последней подтвержденной перед сбоем транзакции.
Указанные выше правила выполняет СУБД-сервер.
СБОИ ТРАНЗАКЦИЙ
Изолированность между транзакциями может быть далеко несовершенной, и это может проявляться, как:
грязное чтение;
неповторяющееся чтение;
фантомные строки.
грязное чтение – самым опасным изъяном в работе транзакции является видимость ее работы для других транзакций до момента подтверждения. Если некоторая транзакция может прочитать неподтвержденные обновления другой, то такой эффект называют грязным чтением.
 эффект
грязного чтения возникает, когда
транзакция2 может прочитать неподтвержденные
обновления, выполненные транзакцией1
эффект
грязного чтения возникает, когда
транзакция2 может прочитать неподтвержденные
обновления, выполненные транзакцией1
неповторяющееся чтение возникает, когда одна транзакция может видеть подтвержденные обновления другой, в то время, когда полная изоляция предполагает, что одна транзакция никогда не влияет на другую. Если изоляция полная, то транзакция не может увидеть внешние изменения, происходящие с данными во время ее работы. Чтение некоторой строки в транзакции должно приводить к одним и тем же результатам: если два последовательных чтения одной и той же строки дают разные результаты, то такой тип ошибки транзакции называют неповторяющимся чтением.
 когда
подтвержденные изменения транзакции1
видны в транзакции2, этот эффект называют
неповторяющимся чтением
когда
подтвержденные изменения транзакции1
видны в транзакции2, этот эффект называют
неповторяющимся чтением
фантомные строки являются наименее серьезной ошибкой транзакции. Подобно неповторяющемуся чтению, фантомные строки возникают, когда обновления, выполненные одной транзакцией, приводят к изменению набора данных, возвращаемого инструкцией SELECT другой транзакции.
 когда
состав строк, возвращаемый инструкцией
SELECT,
изменяется в результате работы другой
транзакции, этот эффект называют
фантомными строками
когда
состав строк, возвращаемый инструкцией
SELECT,
изменяется в результате работы другой
транзакции, этот эффект называют
фантомными строками
УРОВНИ ТРАНЗАКЦИИ
СУБД справляется со всеми тремя видами ошибок транзакций, изолируя транзакции друг от друга. Уровни изоляции можно сравнить с высотой ограды между транзакциями – они позволяют устанавливать критерии допустимости ошибок. В спецификации ANSI-SQL определены четыре уровня изоляции:
|
Уровень изоляции |
Грязное чтение |
Неповторяющееся чтение |
Фантомные строки |
Блокировка записи |
|
|
возможность видеть неподтвержденные изменения другой транзакции |
возможность видеть подтвержденные изменения другой транзакции |
отбор предложением Select дополнительных строк, внесенных другой транзакцией |
первая операция записи блокируется второй |
|
Read Uncommited наименее жесткий |
допустимо |
допустимо |
допустимо |
нет |
|
Read Сommited принят по умолчанию |
запрещено |
допустимо |
допустимо |
нет |
|
Repeatable Read |
запрещено |
запрещено |
допустимо |
нет |
|
Serializable наиболее жесткий |
запрещено |
запрещено |
запрещено |
нет |
|
Snapshot |
запрещено |
запрещено |
допустимо |
да |
SQL Server реализует уровни изоляции с помощью блокировок. Так как блокировки влияют на производительность, то следует искать компромисс между установленным уровнем изоляции и производительностью. Принятый по умолчанию уровень изоляции Read Commited является своеобразным балансом, подходящим большинству проектов.
Уровень 1. Read Uncommited - наименее строгий уровень изоляции не предотвращает никаких ошибок транзакций. Он подобен отсутствию забора, так как на самом деле не изолирует транзакции. Установка этого уровня транзакции является аналогом указанию SQL серверу не выполнять блокировки. Этот режим лучше всего подходит для отчетов и приложений чтения данных.
Уровень 2. Read Сommited - позволяет избежать самой опасной ошибки транзакций, но не нагружает систему излишними блокировками.
Уровень 3. Repeatable Read - предотвращая грязное чтение и неповторяющееся чтение, этот уровень обеспечивает повышенную изоляцию транзакций без чрезмерных блокировок, характерных для уровня изоляции 4.
Уровень 4. Serializable - наиболее строгий уровень изоляции, позволяющий избежать всех ошибок транзакций. Он больше всего подходит базам данных, для которых абсолютная целостность транзакций важнее производительности. Обычно этот уровень изоляции используется в банковских, бухгалтерских базах, а также в очень загруженных приложениях продаж. Использование уровня изоляции Serializable равносильно установке и удержанию блокировки на всем протяжении транзакции. При этом абсолютная изолированность транзакций может привести к серьезному снижению производительности системы.
Выйдя за пределы стандарта ANSI, разработчики SQL Server добавили еще один уровень изоляции – Snapshot, который создает еще одну копию данных в своем собственном физическом пространстве. Эта копия абсолютно изолирована от других транзакций. Уровень изоляции Snapshot реализует блокировку на уровне базы данных. Как правило, конфликт конкуренции происходит между процессами чтения и записи. В случае Snapshot изоляции создается мгновенный снимок данных для обновления, во время обновления операции чтения продолжают работать с исходными данными. Как только обновление будет подтверждено, будет записана измененная копия данных. Но если второй процесс записи попытается обновить ресурс, который в данный момент уже обновляется, то первый процесс будет заблокирован. Уровень изоляции Snapshot использует версионность строк, записывая их копии во временную базу.
ТРАНЗАКЦИИ в РБД
Если данные хранятся в одной централизованной БД, то транзакция к ней рассматривается как локальная. В РБД транзакция, выполнение которой заключается в обновлении данных на нескольких узлах сети, называется глобальнойилираспределенной транзакцией. Распределенная транзакция включает в себя несколько локальных транзакций, каждая из которой завершается двумя путями – фиксируется или откатывается. Распределенная транзакция фиксируется только в том случае, когда зафиксированы все локальные транзакции, составляющие ее, то есть когда каждая локальная транзакция будет подтверждена локальным процессором данных DP.
Для реализации распределенной транзакции предусмотрен протокол двухфазной фиксации(two-phasecommit). Для описания протокола используется следующая модель.
Имеется ряд независимых транзакций-участников распределенной транзакции, выполняющихся под управлением транзакции-координатора. Решение об окончании распределенной транзакции принимается координатором – менеджером транзакций TM. После этого выполняется первая фаза завершения транзакции, когда координатор передает каждому из участников сообщение "подготовиться к завершению". Получив такое сообщение, каждый участник переходит в состояние готовности, как к немедленному завершению транзакции, так и к ее откату. В терминах СУБД это означает, что буфер журнала с записями об изменениях базы данных участника выталкивается во внешнюю память, но синхронизационные захваты не снимаются. После этого каждый участник, успешно выполнивший подготовительные действия, посылает координатору сообщение "готов к завершению". Если координатор получает такие сообщения ото всех участников, то он начинает вторую фазу завершения, рассылая всем участникам сообщение "завершить транзакцию", и это считается завершением распределенной транзакции. Если не все участники успешно выполнили первую фазу, то координатор рассылает всем участникам сообщение "откатить транзакцию", и тогда эффект воздействия распределенной транзакции на состояние баз данных отсутствует.
Если связь с локальным узлом потеряна в интервал времени между моментом, когда координатор принимает решение о фиксации транзакции, и моментом исполнения команды на локальном узле, то координатор будет продолжать попытки завершить транзакцию, пока связь не будет восстановлена.
Если один или более узлов не выполняют операцию завершения, то необходимая информация по восстановлению БД будет находиться в журнале транзакций.
В качестве координатора выступает транзакция, выполняющаяся в главном узле, т.е. та, по инициативе которой возникли дополнительные транзакции. Для откатов транзакций используется базовый механизм контрольных точек сохранения. Протокол двухфазного завершения оптимизирован, чтобы сократить число необходимых сообщений.
Согласованность состояния баз данных при параллельном выполнении нескольких транзакций обеспечивается механизмами блокировок и временных отметок:
механизм блокировки создает такие условия, что график параллельного выполнения транзакций будет эквивалентен некоторому варианту последовательного выполнения этих транзакций (в режиме ожидания последующей транзакцией завершения предыдущей)
механизм обработки временных меток гарантирует, что график параллельного выполнения транзакций будет эквивалентен конкретному варианту последовательного выполнения этих транзакций в соответствии с их временными отметками (альтернатива - приоритеты)
Основной проблемой является проблема возможных распределенных тупиков, которые могут возникнуть между несколькими распределенными транзакциями, выполняющимися параллельно. Тупик, как правило, является следствием взаимоблокировки транзакций. Например, транзакция1 должна выполнить обновление ресурсов A и B, блокирует ресурс A для транзакции2 и обнаруживает, что ресурс B уже заблокирован транзакцией2. В свою очередь транзакция2 тоже пытается выполнить операции с ресурсами A и B, блокирует B для транзакции1 и обнаруживает, что ресурс A уже заблокирован. Обе транзакции оказываются в состоянии взаимоожидания, которое может не разрешиться никогда. Для обнаружения распределенных тупиков применяется распределенный алгоритм, не нарушающий требования автономности узлов сети и минимизирующий число передаваемых по сети сообщений и необходимую процессорную обработку.
Основная идея алгоритма состоит в том, что в каждом узле периодически производится анализ возможности существования тупика с использованием информации о связях транзакций по ожиданию ресурсов, локальной в данном узле и полученной от других узлов. При проведении этого анализа обнаруживаются либо циклы ожиданий, что означает наличие тупика, либо потенциальные циклы, которые необходимо уточнить в других узлах. Эти потенциальные циклы отображаются в виде специального вида строк. Строка представляет собой список транзакций. Все транзакции упорядочены в соответствии со значениями своих идентификаторов - номеров транзакций. Строка передается для дальнейшего анализа в следующий узел только в том случае, если номер первой транзакции в строке меньше номера последней транзакции. (Это оптимизация, уменьшающая число передаваемых по сети сообщений). Этот процесс продолжается до обнаружения тупика.
Если обнаруживается тупик, он разрушается за счет уничтожения (отката) одной из транзакций, входящей в цикл. В качестве жертвы выбирается транзакция, выполнившая к этому моменту наименьший объем работы. Эта информация также передается по сети вместе со строками, описывающими связи транзакций по ожиданию.
Информационное обеспечение КИС
ИНФОРМАЦИОННОЕ ОБЕСПЕЧЕНИЕ КИС
Информационным ядром КИС является Интегрированная Информационная База - БД, которая представляет собой совокупность взаимосвязанных данных, хранящихся c такой минимальной избыточностью, которая допускает их использование оптимальным образом для множества пользователей и приложений.
Основным способом организации корпоративных данных является создание централизованных и распределенных БД. Главным критерием выбора способа организации БД является достижение минимальных трудовых и стоимостных затрат на проектирование структуры ИБД, программного обеспечения системы ведения и поддержки БД, а также на расширение функциональных возможностей ПО БД при возникновении новых задач.
Современные корпоративные информационные системы, в общем случае, имеют распределенную структуру, состоящую из локальных сетей под управлением сервера, в центральном и региональных офисах. Объединение сетей происходит по каналам связи — либо выделенным, либо организованным на базе глобальных сетей общего пользования.
При удаленном доступе к информационным ресурсам должны быть приняты все меры для обеспечения конфиденциальности передаваемой информации.
Наиболее вероятны следующие угрозы:
нарушение конфиденциальности и подлинности информации, хранимой и обрабатываемой на серверах локальных сетей и передаваемой по сетям передачи данных, в результате получения несанкционированного доступа к этой информации и возможности ее модификации;
нарушение функционирования объектов корпоративной информационной системы в результате несанкционированных программных воздействий на оборудование и серверы локальных сетей.
Программное Обеспечение КИСможно разделить на два класса:
1. ПО поддержки жизнеобеспечения КИС (центральный сервер, распределенные серверы, СУБД-серверы, Web-сервер, ПО сетевых коммуникаций, штатные и сервисные службы и т.п.)
2. Корпоративные приложения, которые, как правило, имеют дело со сложными данными большого объема и бизнес-правилами, логика которых неоднозначна. Тем не менее, разработчик КИС должен стремиться к типовым решениям. КП подразумевают необходимость долговременного (иногда в течение десятилетий) хранения данных. Данные нередко переживают несколько поколений прикладных программ, предназначенных для их обработки, аппаратно-технических средств, ОС и компиляторов. Даже в тех случаях, когда компания осуществляет революционные изменения в парке ВТ, коммуникаций и сопутствующего ПО, данные не только не уничтожаются, но тщательно переносятся в новую среду, в конечном итоге в систему баз данных, и становятся актуальными корпоративными данными.
------------------------------------------------------------------------------------------------------------------
Базовые подходы к автоматизации деятельности корпорации (предприятия)
Первый подход подразумевает регистрацию, обработку и хранение информации на одном централизованном сервере БД всеми пользователями системы, в том числе действующими на удаленных рабочих местах – это способ удаленной обработки информации.
При реализации второго подхода регистрация и обработка информации выполняются на нескольких серверах БД, установленных на каждом узловом «территориальном» объекте – это способ распределенной обработки информации.
1.Централизованный подход - удаленная обработка информации
Основным достоинством первого подхода (удаленная обработка данных) является то, что он подразумевает наличие лишь одного центрального сервера БД. Централизованный подход можно реализовать в нескольких вариантах: