

Введення в спеціальність / Додаткова література / data mining with ontologies
.pdfSOM-Based Clustering of Multilingual Documents Using an Ontology
Figure 2. An 6x4 SOM of hexagonal topology
•A vector representing the neuron called neural vector. This vector has the same number of dimensions as the input vectors. After being trained (see the subsection “Learning
Process”next)thecomponentsofthisvector will best reflect the corresponding components of the input vectors belonging to this neuron. It means that a neuron represents a group of similar inputs. During the learning process, the components of a neural vector will change.
In accordance with the symbols and conventions described in the first section, the vector representing a neuron has Mdimensions, which is the number of dimensions of input vectors. If the map has two dimensions, the number of neurons in each dimension is X and Y where X.Y=G (G is the number of groups on the map). The neuron Ck, with 0 ≤ k ≤ G may be represented by indi-
ces x,y:Cx,y, with 0 ≤ x < X, 0 ≤ y < Y where k = x.X + y. The neural vector corresponding to the
neuron Ck or Cx,y is ck or cx,y (the c in lowercase). The jth component in the vector representing the kth neuron is then represented by ckj or cx, y, j.
learning process
The goal of the learning process of the SOM is to gradually build up the neural vectors that best represent groups of inputs. Moreover, because of the particularity of the SOM algorithm a neural vector will be very similar to its neighbor vectors. Short distances in the data space express similarity. The learning process can be divided into five steps:
Figure 3.An example of a map of square topology. The neural vectors have M dimensions. The map has two dimensions with 6 horizontal neurons and 4 vertical ones. Each neuron has a different color. This means that neural vectors are different.
,0 ,0 , , , ,
,0 |
, |
, |
, |
, |
, |
,0 |
, |
, |
, |
, |
, |
0,0 |
0, |
0, |
0, |
0, |
0, |

SOM-Based Clustering of Multilingual Documents Using an Ontology
•Step1:Initializationofneuralvectors.There are many methods to do this task: random initialization,K-meansbasedinitialization, and so forth. Random initialization is the most widely used among these methods. Components of neural vectors will be assigned random numerical values.
•Step 2: For the tth iteration of the learning
process, an input di is randomly chosen among N inputs.
•Step 3: Selection of the best matching
neuron for the input di. A neuron is called best matching when the distance between
the input di and the vector representing that neuron is at its minimum. This neuron is
also called the winner for the input di at tth iteration. We will use the term wtto represent the winner vector at the moment t.
•Step 4: Determination of the winner’s neighborhood and corresponding update of its neighbors.
•Step 5: If the end condition is not met, proceed to the next iteration (t = t+1) and repeat from Step 2.
We put particular emphasis on Step 4 due to its importance. Let us consider how the neural vector ck is updated.
ck(t+1) = ck(t)+g(t).h(ck, wt, t)(di-ck(t)) |
(1) |
In this formula, there are two distances that need to be calculated: local distance and data distance. Local distance is the distance between two neurons on the map, which is usually a twodimensional plane. As it has been explained in
“The structure of a SOM” section, the position ofaneuronneverchanges;thereforethedistance between two neurons remains fixed. In (1), local distance is expressed by g(t).h(ck, wt, t) which is the multiplication of the learning rate g(t) by the neighborhood function h(ck, wt, t). We can see that these two terms are time-dependent. The form of these two functions can be chosen in respect of the following rules:
The learning rate g(t) begins with a high value which then decreases as time increases. This gradual reduction guarantees the termination of the learning process in finite time. Moreover, initial values for each neural vector are far from optimal,soa“strongmovement”towardsoptimal positions should be encouraged by setting a higher learning rate value. Over the course of time, this value becomes smaller so that the movement is lessened, which may prevent the neural vectors from stepping over the optimal positions. This
Figure 4. The form of a Mexican hat
SOM-Based Clustering of Multilingual Documents Using an Ontology
term does not directly concern either local or data distance.
The neighborhood function h(ck,wt,t) starts with a high value which then decreases as time increases. The idea of this function stems from the fact that in the real neural system (in the brain of an animal), when a neuron is excited, other neurons around it will be excited too. They form the neighborhood of the central neuron, and around this neighborhood neurons are inhibited. This term depends strictly on the local distance. To represent this phenomenon, the neighborhood function should have the form of a Mexican hat, see Figure 4.
In general, there are many propositions for the formulaes of these two functions. Here we introduce the most widely used:
The learning rate g(t):
 (t) =
(t) =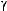 (0).e- t , where g(0) is the initial learning rate, e is a predefined coefficient.
(0).e- t , where g(0) is the initial learning rate, e is a predefined coefficient.
The neighborhood function h(Ck, wt, t):
h(c , w ,t) = e- |
|
ck -wt |
|
|
|
2 |
|
(t) = (0).e- |
t |
|
|
|
|
||||||||
|
|
, where |
|
with |
||||||
|
2. (t)2 |
|||||||||
|
|
|||||||||
k t |
|
|
|
|
|
|
|
|
|
|
σ(0) and ξ are predefined parameters. |
|
|
||||||||
The data distance in (1) is calculated by the term (di-ck(t)) where di is an input vector (as we have seen, it will not change in the learning process) and ck(t) is the vector of the kth neuron at the tth iteration.
Classification
When the learning process is complete, the map can be used for classification. At this time, each neural vector has its own optimal position in the data space so that it can be the representative for a group of input vectors. The objective of classification is to map each input vector to its corresponding neural vector. For an input, we finditsneuronbysearchingfortheneuralvector having the smallest distance to its input vector. Because there are fewer neurons than inputs, several inputs are mapped to the same neuron. These inputs form a group of inputs having the smallest distances to this neuron in comparison to the distances from other neurons.
When the mapping of all the inputs is completed, the kth neuron has a set Ck of indices i of inputs belonging to it and the neural vector ck is
Figure 5. In this example, 13 input data (circles and triangles) are classified into two groups. The data spacehastwodimensionsandafterthelearningprocess,twoneurons(squares)havepositionsasshown in the graph. The line in the figure separates two groups.
0

SOM-Based Clustering of Multilingual Documents Using an Ontology
the center of gravity of these inputs in the data space (see Figure 5).
OntOlOgy
what is an Ontology?
Theterm“ontology”wasfirstusedinphilosophy to imply studies and discussions on existence. In computer science, this term refers to a specification of a conceptualization (Gruber, 1993) so that an ontology is a description (like a formal specification of a program) of the concepts and relationships that exist in a domain.
An ontology is usually defined as a hierarchy of concepts corresponding to the hierarchical data structure within a certain domain. This structure includes the inter-relationships between concepts, which can imply directed, acyclic, transitive and reflexive relations (Hotho et al., 2001). Concepts that are not domain-specific are described in a foundation ontology.
Let us consider the example of an ontology in the domain of “cancer”. There are several types of cancer: breast cancer, lung cancer, stomach cancer, etc. We can say that breast cancer is a type of cancer, that is, “breast cancer” is a subconceptoftheconcept“cancer.”Wecanalsosay that “cancer” is a subconcept of “tumor,” since cancer is a malignant tumor.
Ofcourse,therelationshipsbetweenconcepts in the ontological hierarchy of a given domain are based on their semantic relationships, which are specific to that domain.
Ontology for document representation: related work
In order to use ontologies in text clustering, two preprocessing steps are necessary. First, an ontology describing the target domain has to be built, usingeithertextcorporaormanualdefinitionsor both. Text documents can be indexed through this structure in order to produce vectors representing them. These vectors will be used by a clustering methodasinputs.Toaccomplishthefirsttask,constructing the ontology, several tools may be used to determine the concepts and their relationships. For the second, an indexer is needed to produce characteristic vectors from documents.
Ontologieshavenotlongbeenusedtorepresent text documents. Most research in this direction has been done recently (after 2000). The first of the kind may be that of Hotho et al., (2001). Their approach, named concept selection and aggregation(COSA)usesacoreontologyto,asthename suggests, restrict the set of relevant document features and automatically propose appropriate aggregations. The core ontology is defined as a sign system O: = (L, F, C, H, ROOT) where:
Figure 6. A part of the hierarchical structure of the ontology in the domain of “cancer”
|
Tumor |
Is-A relationship |
|
|
|
|
Cancer |
|
Breast cancer |
Lung cancer |
Stomach cancer |

SOM-Based Clustering of Multilingual Documents Using an Ontology
Figure 7. Application of ontology in document representation
•L is a lexicon that contains a set of terms.
•C is a set of concepts.
•F is a reference function that links a set of terms (which is a subset of L) to the set of concepts they refer to.
•His a heterarchy that contains relations between concepts. For example, H(x,y) means that y is a subconcept of x.
•ROOT is the top concept and belongs to the set C so that H(ROOT,z) for all z belonging to C.
There are two steps in their approach: mapping terms to concepts and generating “abstract concepts.” To map terms to concepts, they use an existing natural language processing tool that does following jobs:
•Identify and extract terms from text documents.
•Use its domain lexicon to map the terms extracted to domain dependent concepts.
This tool can extract a set of concepts from documents. However, the number of concepts for each document is still large enough to produce high dimensional input vectors. They, therefore, proposeaheuristicmethodbasedontheheterarchy H that provides views from concepts so that the number of dimensions of resulting vectors can be reduced. This research is particularly interesting in that it helps lower dimensionality considerably
without loss of information. The results obtained are very encouraging.
Following this proposition, research has been done in applying domain-specific ontologies to text clustering. For example, in (Smirnov et al., 2005) an ontology is used to cluster customers and requests in the area of customer service management. In Wang et al., (2005), the clustering task is based on an ontology in gene expression analysis. Bloehdorn et al., (2005) present the integrated framework OTTO (OnTology-based TextminingframewOrk),whichusestextmining techniques and an ontology in order to improve the efficiency of both unsupervised and supervisedtextcategorization(Bloehdornetal.,2005).
Each documents term vector is extended by new entries for ontological concepts appearing in the document set. Thus each document is represented by the concatenation of the term vector (based on the tf.idf measure) with the concept vector (concept frequency-based). In this approach the dimensionality of the document vector may be high and may contain duplicated features. A term that has a corresponding concept in the concept vector may be present twice.
Otherworksrelatedtoontology-basedfeature selection which relies on set of ontologies associated with the document set have been reported in the literature (Gabrilovich & Markovitch, 2005; Litvak et al., 2005; Wang et al., 2003; Wu et al.,
2003). Experiments with conceptual feature representationsforsupervisedtextcategorizationare
SOM-Based Clustering of Multilingual Documents Using an Ontology
presented in Wang et al. (2003). Gabrilovich and Markovich propose a framework and a collection of algorithms that perform feature generation based on very large scale repositories of human knowledge (Gabrilovich & Markovitch, 2005).
The feature generator is based on the open directory project (ODP) categories called concepts. A hierarchical text classifier is induced that maps pieces of text onto relevant ODP concepts which serve as generated features. Each ODP node has a textual description and an URL which serves as training examples for learning the feature generator. Litvak et al. (2005) presents a methodology for the classification of multilingual Web documentsusingadomainontologydescribedinOWL
(Litvak et al., 2005). A language independent key phrase extractor that integrates an ontology parser for each language is used.
Compared to other implicit knowledge representation mechanisms, an ontology presents several advantages (Wu et al., 2003): (1) it can be interpreted and edited by human beings, (2) noise anderrorscanbedetectedandrefined,(3)itcanbe shared by various applications. The experimental results reported in Wang et al. (2003) show that the domain ontology effectively improves the accuracyofaKNNclassifier.Moreovera“faster convergenceofclassificationaccuracyagainstthe size of training set” is obtained. However, those resultsareobtainedexperimentallyandshouldnot besystematicallygeneralizedforotherclassifiers.
Sebastiani, (1999) states that the experimental results of two classifiers can be compared if the experimentsareperformedonthesamecollection, with the same choice of training set and test set andfinallywiththesameeffectivenessmeasure.
Moreover, even if the use of an ontology presents some advantages, building it is a difficult task.
In medicine, substantial work has been done to develop standard medical terminologies and coding systems. Those standards may be exploited to build or to enrich ontologies (Simonet et al., 2005a).
sOm-Based ClUstering Of mediCal dOCUments Using an OntOlOgy
document representation models for sOm
While preprocessing textual documents, there are two important questions that must be answered before clustering. First, how will a document be represented? Second, how will the importance of a semantic element be calculated? A semantic element can be a stem or a term or a concept or a word category (this depends on the representation model). Many methods can be used to represent a textualdocument.Allthesemethodsmakeuseofa vectorwhosecomponentsdescribethedocument’s content. The vector space model (Salton et al.,
1975) is the basis for this representation. One of the greatest challenges in data mining generally and clustering digital text documents by SOM in particular, is the large vector dimensionality during the processing of a huge set of documents. Eachdocumentcontainsasetofsemanticelements and the number of dimensions of one document vector is different from that of another document. However, in order to compare documents, their vectors must have the same number of dimensions. A certain semantic element may appear in one document but may not in another. To solve this problem, a dictionary has to be built. This dictionary contains all the semantic elements found in the set of documents but none of them appears more than once in the dictionary. Based on the dictionary, a vector will be generated for eachdocument.Thevectorgeneratedhasthesame dimensionality as the dictionary. The importance of a semantic element within a document is based on its frequency of occurrence in that document. If an element is not present in the document, it will be weighted by a value of 0 (it means that this element has no importance at all in the docu-

SOM-Based Clustering of Multilingual Documents Using an Ontology
ment). At the end of this step, we have a set of vectors representing the documents (see Figure 5). There may be other preprocessing tasks such as the calculation of the global importance of the semantic element in the whole corpus and/or normalization to be completed before the set of vectors can be used as inputs for the clustering algorithm.
In a particular case where a semantic element is a term, the method used for calculating the global importance of terms can be TFor TD.IDF
(Salton & Buckley, 1988):
•TF: Term Frequency, that is, the number of occurrences of the term in the document. The greater the TF, the more important the term is for the document. There are cases where a term has high TF value for all the documents in the document collection. It is clear that this term cannot help discriminate different groups of documents. For example, in a collection of medical documents, the word “treatment”willhaveahighTFvalue for all documents in this collection.
•TF.IDF: Term Frequency-Inverse Document Frequency. This method was proposed to overcome the disadvantage of the TF method.
fidf (i, j) =tf (i, j) log dfN( j)
Where i is the index of the current document, j is the index of the current term, tf(i,j) is the TF value of the term j in the document i, df(j) is the number of documents where the term j appears.
Some existing representation methods are very popular for use with SOM. In Honkela et al., (1997), Kohonen and his colleagues proposed, withintheWEBSOMproject,wordcategorymaps that can group words with similar contexts into a category. Instead of being represented by a vector ofwordoccurrences,adocumentischaracterized by a vector of word category occurrences, which hasfewerdimensions.TwotypesofSOMhaveto be used in this approach: one for word categories and one for document clusters. Still within this project, random mapping is proposed to help considerably reduce the number of dimensions for a huge set of documents. At first, a document is fully represented by a vector of word occurrences. This vector is then multiplied by a matrix whose elements are randomly generated so that the resulting vector has lower dimensionality. Because the matrix is random, there is obviously reduced accuracy. Combination of word category maps and random mapping is also considered so
Figure 8. Representing each document as a vector of semantic elements. This vector is built based on the dictionary and the original document.
Dictionary
doc 1
Vector of doc 1
SOM-Based Clustering of Multilingual Documents Using an Ontology
thatfirst,documentsarerepresentedbyvectorsof word category maps then, random mapping is applied. However, the most frequently used method is full representation, that is, semantic elements are words that appear in the document collection. In some cases, stems are used instead of words. A stem is what is left from a word when all the suffixeshavebeenstrippedoff.Forexample,the verb laugh has several inflected forms: laugh, laughs, laughed, laughing, which are all stemmed as laugh. For this reason, using stems can make documentvectorsmorecompactinsizethanthose produced by using words.
Ontology-Based document representation method
We have reviewed several methods for text representation, which are specific to SOM. Some of these are based on the full representation and then processed by mathematical transformations which make it impossible to explain the results obtained. Random mapping for example makes useofarandommatrixsothatresultingvectorsare simply arrays of numbers having no meaning. If two documents fall into one group, the only thing we can say is that their correspondent vectors are similar: there is no conclusion concerning their content. Word category maps may be useful in this case. However, resulting vectors still have many dimensions. Furthermore, context is not sufficient to accurately group words that have the same meaning. Although full representation is widely used, it is a basic method for document representation. Vectors of words or stems represent documents, so the number of dimensions may be very large. This method, also known as the bag-of-words representation method, is not suitable when the document collection is exceptionally voluminous.
Even though results obtained by the preceding methods are encouraging, they have limitations that cannot be resolved especially in the medical domain where multilingual documents
are abundant. For this reason, we use an ontol- ogy-based document representation method. As statedinthethirdsection,theontologymustfirst be constructed. When an ontology is available, documents are indexed in order to be represented by vectors. Indexation process is performed on plain text documents.
the Ontology model
Automatic characterization relies on the identification of terms in texts. The terminology in the ontology must offer a good coverage of the terms used in medical literature. Moreover, in order to manage the multilingual aspect of the ontology, each concept is expressed in several languages. Thus, a term enrichment process has to be performed on the ontology manually and/or automatically. The enrichment process may be based on domain corpora (Simonet et al., 2005b) or medical vocabularies such as UMLS (unified medical language system) metathesaurus1.
Formaly an ontology O is the set (C, Rel, T, L) where:
•C is the set of concepts of the ontology.
•RelistheSubconcept-Superconceptrelation- ships (generally the subsumption relationship).
•T is the set of terms used to denote the concepts in the ontology.
•L is the set of languages used to denote the terms present in T.
For the experiments we have considered for each concept its French and English terms.
A cardiovascular ontology has been built up aspartoftheNOESISprojectbasedontheMeSH
(Medical Subject Headings) thesaurus2 with enrichment from the UMLS metathesaurus. The ontology is still being enriched by vocabulary extracted from articles in the cardiovascular domain. This work is described in Simonet et al. (2005a).
SOM-Based Clustering of Multilingual Documents Using an Ontology
We have also used an ontology for breast cancer (Messai et al., 2006). This ontology has been built manually using terms extracted from a corpus of selected documents. There are more than 1200 concepts in this ontology.
document preprocessing
Since an indexing process is performed on plain text inputs, documents in pdf or HTML format must first be converted.
Convertingdocumentsfrompdfformattoplain text format can naturally preserve the original text. However,insomecases,theremaybesomeerrorsin conversion. These errors depend on the conversion module used. First, long words may be truncated at theendofaline.Forexample,“international”isa longword.Itcanberewrittenlike“international”so that“inter-”isattheendofalinewhile“national” is at the beginning of the following line. When the text is converted, this word will be split into two differentwords.Thishappensveryfrequentlyinpdf documents so that several terms are not counted. Accordingly, the indexing process is not correctly done. Moreover, a document may contain several columns. While converting a document, columns in the resulting document (plain text format) may not appear in the right order. Since a term may contain several words spread over two columns it may occur that the word order within the term is not maintained. Another cause of error is that during conversion, words appearing in the header, the footer, or a legend are inserted between words of a term so that the term does not appear in the resulting document. It is important to note that errors during conversion have a negative impact on the quality of indexation.
document representation process and feature selection
Document indexing is carried out so that vectors of concepts represent documents. The necessary steps are term extraction and concept extraction.
Concepts are not directly present in documents. They may be retrieved by locating the terms which represent the concepts in the ontology. A term is a word or an expression that has fixed meaning.
A list of terms and corresponding frequencies is produced for each document. A concept may be denoted by several terms, possibly in several languages, so that its frequency in a document is computed as the summed frequencies of its denoting terms in the document (Diallo et al., 2006). Following this, the CF-IDF (Concept Frequency-Inversed Document Frequency) is used to measure the importance of concepts in documents. The CF-IDF method is an extension of the TF-IDF measure where CF is the sum of the TFfor all the terms representing the concept. Instead of only using the concept frequency we use the CF.IDFmeasure because it makes it possible to weigh a concept’s importance compared to the whole document collection.
All the concepts present in the ontology will not appear in the documents. For this reason, only concepts that have been used at least once to index thecollectionareconsideredasfeatures.However, there may be some concepts that appear in every document of the collection and they are not useful in clustering documents. These concepts are excluded. The concepts obtained are included in a dictionary called the collection dictionary. Based on this dictionary, characteristic vectors are built for the documents.
When we have all characteristic vectors for every document, the vectors need to be normalizedtoeliminatethelengtheffect.Then,theyall have the same unit length. The similarity between two document vectors is measured by the cosine of the angle of those vectors in THE data space. Each document vector will be compared to A neural vector in the training process by the same method to choose the winner.
After the preprocessing task, we have a set of inputs, which are normalized document vectors.
The inputs will be used in the training process of the SOM.
SOM-Based Clustering of Multilingual Documents Using an Ontology
evalUatiOn
In our experiments we have implemented and compared two feature selection modes: full repre- sentation(dictionaryofstems)andontology-based representation (dictionary of concepts). We have used the ontologies presented in the fourth section and two text corpora. For the second corpus, which concerns breast cancer, only the ontologybased method is used because the documents are in two languages.
document sources
We use two corpora in our experiments. One contains scientific articles in the cardiovascular domain and the other concerns articles on breast cancer. The former contains only articles in English and can be found and downloaded from the website http://www.biomedcentral.com, while the latter includes texts both in English and in French that have been downloaded from several sources.
The corpus on cardiovascular diseases contains 430 documents grouped in the following seven sections:
•Cardiovascular diabetology (41 documents)
•Cardiovascular ultrasound (44 documents)
•BMC cardiovascular disorders (94 documents)
•Current interventional cardiology reports (119 documents)
•Current controlled trials in cardiovascular medicine (120 documents)
•Thrombosis journal (25 documents)
•Nutrition journal (11 documents)
Sections for the documents have been chosen by the authors of the articles during submission and have been reviewed by the editors. According tothesubmissionprocedure,theclassificationof the documents in sections has been accomplished
carefully. We have therefore chosen these sections as predefined groups of our experiments
Thesedocumentsareinthepdffileformat.The number of words in each document ranges from 1,200 to 8,000. The average number of words is more than 4,100. There may be from five to 15 pages for a document.
The corpus on breast cancer contains 440 documents in English and 574 in French. The collection contains documents in plain text or HTML format. Sources of documents are also veryvariedandthereisnopredefinedgroup.The corpuswasfirstusedtoextractconceptstobuild the ontology on breast cancer. For this reason, there are documents of many types: definitions, generalinformation,currentevents,andscientific articles on breast cancer. Most of the documents are short.
results
For the corpus on cardiovascular diseases, with seven predefined groups of documents, we have used a 7×7 square map, that is, 49 possible clusters on the SOM. The preclassification of documents into groups has been done manually. We will compare the clusters obtained by the SOM to these predefined clusters.
Suppose that we have documents from many predefined groups falling into one cluster of the SOM.Wecanthensaythatthemaintopicofthis cluster is that of the predefined group having the most documents in the cluster. For example, if there are seven documents on two topics “Cardiovascular diabetology” (four documents) and “Cardiovascular ultrasound” (three documents), then the cluster is said to have the topic “Cardiovascular diabetology.” We can say that there are four hit documents and three miss documents for the cluster. In (Kohonen, 1998), alldocumentsthat represented a minority newsgroup at any Grid pointwerecountedasclassificationerrors(p.68). In our experiments, newsgroups are replaced by predefined sections.