

Введення в спеціальність / Додаткова література / data mining with ontologies
.pdfSOM-Based Clustering of Multilingual Documents Using an Ontology
Table 1 presents the results of the experiments with the ontology. Note that in each cell of the table, there are the following values.
Total number of documents:Number of hits;
Number of misses: (Hits-Misses).
We have the total sum of (Hits-Misses)=68 Table 2 presents the results of the experiments with full representation,
Using the same evaluation method we obtain the total sum of (Hits-Misses)= -3.
Thisresultismuchlowerthantheoneproduced by using the ontology. It means that by using the ontology to represent documents, we can obtain clusters that separate the document collection.
From the point of view of processing time, the number of vector dimensions for full representation is 25,762 and it took several days. With the ontology-based method, the number of vector dimensions is 4,315; the learning process is completed in several hours.
Table 1. Results of the experiment with concept-based representation
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
|
|
|
|
|
|
|
0 |
43: 23; |
8:3; |
28:10; |
14:7; |
24:16; |
4:4; |
5:2; |
|
|
20: +3 |
5: -2 |
18:-8 |
7:0 |
8:+8 |
0:+4 |
3:-1 |
|
1 |
4:3; |
5:3; |
3:2; |
18:5; |
1:1; |
4:4; |
0:0; |
|
1:+2 |
2:+1 |
1:+1 |
13:-8 |
0:+1 |
0:+4 |
0:0 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
2 |
29:23; |
3:2; |
5:5; |
4:4; |
7:7; |
0:0; |
11:5; |
|
|
6:+17 |
1:+1 |
0:+5 |
0:+4 |
0:+7 |
0:0 |
6:-1 |
|
3 |
6:3; |
1:1; |
21:19; |
8:6; |
0:0; |
10:8; |
3:2; |
|
3:0 |
0:+1 |
2:+17 |
2:+4 |
0:0 |
2:+6 |
1:+1 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
4 |
26:9; |
8:5; |
7:6; |
3:1; |
14:7; |
2:2; |
3:2; |
|
17:-8 |
3:+2 |
1:+5 |
2:-1 |
7:0 |
0:+2 |
1:+1 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
5 |
20:8; |
2:1; |
2:1; |
8:5; |
12:7; |
0:0; |
11:6; |
|
12:-4 |
1:0 |
1:0 |
3:+2 |
5:+2 |
0:0 |
5: +1 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
6 |
5:2; |
1:1; |
8:4; |
0:0; |
14:7; |
8:5; |
7:2; |
|
3:-1 |
0:+1 |
4:0 |
0: 0 |
7:0 |
3:+2 |
5:-3 |
||
|
||||||||
|
|
|
|
|
|
|
|
Table 2. Results of the experiment with stem-based representation
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
|
|
|
|
|
|
|
0 |
0:0; |
0:0; |
0:0; |
0:0; |
0:0; |
0:0; |
0:0; |
|
0:0 |
0:0 |
0:0 |
0:0 |
0:0 |
0:0 |
0:0 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
1 |
0:0; |
1:1; |
0:0; |
0:0; |
0:0; |
0:0; |
0:0; |
|
0:0 |
0:+1 |
0:0 |
0:0 |
0:0 |
0:0 |
0:0 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
2 |
0:0; |
16:8; |
10:5; |
13:7; |
10:6; |
0:0; |
0:0; |
|
0:0 |
8:0 |
5:0 |
6:+1 |
4:+2 |
0:0 |
0:0 |
||
|
||||||||
|
|
|
|
|
|
|
|
|
3 |
34:18; |
5:3; |
9:4; |
8:4; |
8:4; |
0:0; |
0:0; |
|
|
16:+2 |
2:+1 |
5:-1 |
4:0 |
4:0 |
0:0 |
0:0 |
|
4 |
27:7; |
9:5; |
27:14; |
14:5; |
16:6; |
0:0; |
0:0; |
|
|
20:-13 |
4:+1 |
13:+1 |
9:-4 |
10:-4 |
0:0 |
0:0 |
|
5 |
20:11; |
12:7; |
6:3; |
5:5; |
18:12; |
4:2; |
0:0; |
|
|
9:+2 |
5:+2 |
3:0 |
0:+5 |
6:+6 |
2:0 |
0:0 |
|
6 |
58:23; |
12:6; |
23:13; |
26:14; |
38:20; |
0:0; |
0:0; |
|
|
35:+12 |
6:0 |
10:+3 |
12:+2 |
18:+2 |
0:0 |
0:0 |
SOM-Based Clustering of Multilingual Documents Using an Ontology
Moreover,SOMtrytominimizethefollowing objective function:
N |
G |
|
|
|
|
||||
F = ∑∑ |
|
|
|
di -ck |
|
|
|
2 |
|
|
|
|
|
||||||
i=1 |
k=1 |
|
|
|
|
||||
ThesmallerthevalueofF,thebettertheSOM can cluster inputs. In our experiments, this value withthefullrepresentationis545.19whilewiththe ontology it is 508.57. This once again implies the better results with the use of the ontology-based document representation method. It means that by using an ontology, coordinates of centers are better distributed in the data space.
For the second corpus, which concerns breast cancer, it is more difficult to evaluate the results because it is in two languages and no predefined document cluster is available. In contrast to the corpus on cardiovascular diseases that contains scientificarticlesandisveryspecific,thissecond corpus contains both general information about breastcancerandspecializedknowledge.Whatwe expect when clustering this corpus is to examine the possibility of representing bilingual documents by concepts taken from an ontology.
Wehavetakentwodocumentsfromthecorpus, one in English, and the other in French. Their titles are similar: “What Are the Risk Factors for Breast Cancer?” and “Généralités et facteurs de risqué.” However, they are clustered in two different groups. The former on risk factors for breast cancer for women is fairly general and synthetic. The latter is more specific and deals with research.
We have examined two other documents that are clustered in one group: “Does Weight Gain
Increase Breast Cancer Risk?” and “Cancer et hormones:del’espoiràlamenace?”Surprisingly, the English document mentions “menopausal hormonetherapy”asatreatmentmethodandthe French document confirms that using hormone can treat breast cancer. However, a document in French, titled “Dix kilos perdus et le risque de cancer du sein diminuerait,” is not clustered in
that group although this document mentions the relationship between body weight and breast cancer as does the English document. This document is rewritten in French from the original document, “Intentional Weight Loss of 20 Pounds or
MoreLinkedtoDecreasedCancerRisk,”written in English. It is not simply a translation from English to French but these documents are still arranged in the same group because both express the same idea.
Evaluation in text clustering in general is a notorious problem. Evaluating the performance of the method in the experiment with the ontology onbreastcancerisevenmoredifficult.However, by manually browsing the results, we observe they are very encouraging.
COnClUsiOn
In comparison to other document representation methods, the ontology-based method has the following advantages:
•It produces characteristic vectors of low dimensionality. The number of dimensions of these vectors is controllable. An ontology is domain-dependent so that not all the concepts appearing in a document are extracted. For this reason, unrelated concepts are not considered and this considerably reduces the number of vector dimensions. On the other hand, a concept may be represented by many terms so that the number of occurrences of that concept may be large. For some ontologies, based on concepts, views are built (see, Hotho et al., 2001). A view can contain several concepts that are related.
•It is an effective approach for clustering multilingual text documents. Terms are language dependent. But concepts are language independent.Forthisreason,atextdocument A in English can be represented by the same vectorasthedocumentBinFrenchthatisA’s
SOM-Based Clustering of Multilingual Documents Using an Ontology
translation. In one language, a concept may also have many terms representing it. So, it is normal that the concept is represented by many terms in many languages. By using concepts, document indexing does not have to be based on one particular language.
•It may provide explanation. When two document vectors are arranged in one group, they must be very similar and thus share many concepts, which it is possible to list. However, when random mapping is applied, it is difficult to know why documents are considered as similar.
Inevitably, there are also some drawbacks to theontology-basedmethod.First,itisdifficultto build and manage an ontology, especially since new concepts and terms constantly appear in specialized domains. Some terms may also be ambiguous and denote several concepts. Moreover, using an ontology for documents indexing is not an easy task. In our experiments, terms are extracted and then mapped to their correspondent concepts. In several cases, a longer term includes a shorter one. When such a case occurs, we extract the former and ignore the latter.
fUtUre researCh direCtiOns
This chapter deals with two main research areas: clustering documents using SOM and characterizing the semantic contents of a document using an ontology.
Short-term research directions include applyingotherclusteringandclassificationtechniques to the same ontology-based indexing scheme, such as hierarchical clustering or text categorization using a naive Bayes classifier (Witschel and Biemann, 2006) or linear support vector machines (Hulth and Megyesi, 2006). Moreover, conceptual indexing could be complemented with relational information found in the ontology structure, especially hyper-/hyponymy relations.
The use of semantic relationships should lead to an improvement of the results.
Another possible research direction would be to investigate the use of multiple ontologies in the clustering task since a single ontology is not sufficienttosupportthetaskofdocumentclusteringin a distributed environment like the Semantic Web
(Shadbolt & al., 2006). Further, in the context of ontology-basedinformationintegration(Wache& al., 2001), it would be interesting to analyse how clustering techniques, involving both schema and instances, may be used to automatically build the global ontology or to generate a mapping between global and local ontologies (Rahm and Bernstein,
2001; Castano & al., 2001).
A last research direction concerns the use of ontologies for information retrieval. An ontology canbeusedtosemanticallycharacterizeboththe documents and the queries (Mihalcea and Moldovan, 2000; Biemann, 2005). Henceforth, the documents to be retrieved do not have to share the same words with the query but rather the same concepts. Using ontologies for conceptual indexing and concept-based querying may therefore make it possible to overcome the drawbacks of current word-based information retrieval techniques (Muller & al., 2004).
referenCes
Bloehdorn, S., Cimiano, P., Hotho, S., & Staab,
S. (2005). An ontology-based framwork for text mining. LDVForum:GLDVJournalforComputational Linguistics and Language Technology, 20(1), 87-112.
Diallo, G., Simonet, M., & Simonet, A. (2006).
An approach to automatic semantic annotation of biomedical texts. In Proceedings of IEA/AIE’06, LNAI 4031 (pp. 1024-1033). Springer-Verlag.
Gabrilovich, E., & Markovitch, S. (2005, August). Feature generation for text categorization using world knowledge. In Proceedings of the
0
SOM-Based Clustering of Multilingual Documents Using an Ontology
19th International Joint Conference in Artificial Intelligence (pp. 1048-1053).
Gruber, T. R. (1993). A translation approach to portable ontologies. KnowledgeAcquisition,5(2), 199-220.
Honkela, T., Kaski S., Lagus, K., & Kohonen, T. (1997, June). WEBSOM: Self-organizing maps of document collections. In Proceedings of WSOM’97, Workshop on Self-Organizing Maps.
Helsinki University of Technology, Neural Networks Research Centre, Espoo, Finland.
Hotho, A., Maedche, A., & Staab, S. (2001, Au- gust).Ontology-basedtextclustering.InProceed- ingsoftheIJCAI-2001WorkshopofTextLearning, Beyond Supervision. Seattle, USA.
Kohonen, T. (1982). Self-organized formation of topologically correct feature maps. Biological Cybernetics, 43, 59-69.
Kohonen, T. (1998). Self-organization of very large document collections: State of the art.
In L. Niklasson, M. Bod, & T. Ziemke, (Eds.),
Proceedings of ICANN98, the 8th International Conference on Artificial Neural Networks (Vol.
1, pp. 65-74). London: Springer.
Kohonen, T., Kaski, S., Lagus, K., Salojärvi,
J., Honkela, J., Paatero, V., et al. (2000). Self organization of a massive document collection.
IEEE Transactions on Neural Networks, 11(3) 574-585.
Litvak, M., Last, M., & Kisilevich, S. (2005, October).Improvingclassificationofmultilingual Web documents using domain ontologies. The Second International Workshop on Knowledge
Discovery and Ontologies. Porto, Portugal.
Messai,R.,Simonet,M.,&Mousseau,M.(2006).
A breast cancer terminology for lay people.
European Journal of Cancer EJC Supplements. 4(2), 179-180.
Salton, G., Wong, A., & Yang, C. S. (1975). A vector space model for automatic indexing. Communications of the ACM, 18(11), 613-620.
Salton,G.,&Buckley,C.(1988).Term-weighting approachesinautomatictextretrieval.Information Processing and Management, 24, 513-523
Sebastiani, F. (1999). A tutorial on automated text categorization. In A. Amandi & Zunino
(Eds.), Proceedings of ASAI-99, 1st Argentinian Symposium on Artificial Intelligence (pp 7-35). Buones Aires.
Simonet,M.,Bernhard,D.,Diallo,G.,&Gedzelman, S. (2005a). Building an ontology of cardio- vasculardiseasesforconcept-basedinformation retrieval. Computers in Cardiology, Lyon.
Simonet,M.,Bernhard,D.,Diallo,G.,Gedzelman, S.,Messai,R.,&Patriarche,R.(2005b,December
14-16). An environment for ontology design and enrichment from texts. In Proceedings of SWAP 2005, the 2nd Italian Semantic Web Workshop, Trento, Italy, CEUR Workshop Proceedings, ISSN 1613-0073.
Smirnov, A., Pashkin, M., Chilov, N., Levashova,
T., Krizhanovsky, A., & Kashevnik, A. (2005). Ontology-based users and requests clustering in customer service management system. In V. Gorodetsky, J. Liu, & V. Skormin (Ed.), Autonomousintelligentsystems:Agentsanddatamining.
AIS-ADM.
Wang,B.B.,McKay,I.,Abbass,H.A.,&Barlow,
M. (2003). A comparative study for domain ontology guided feature extraction. In Proceedingsof the26th AustralianComputerScienceConference (ACSC-2003) (pp. 69-78). Adelaide, Australia. Australian Computer Society, Inc.
Wang, H., Azuaje, F., & Bodenreider, O. (2005).
An ontology-driven clustering method for supporting gene expression analysis. In Proceedings of the 18th IEEE Symposium on Computer-Based Medical Systems (pp. 389-394).
SOM-Based Clustering of Multilingual Documents Using an Ontology
Wu, S. H., Tsai, T. H., & Hsu, W. L. (2003). Text categorization using automatically acquired domain ontology. In Proceedings of IRAL2003 Workshop on Information Retrieval with Asian Languages, Sapporo, Japan.
additiOnal reading
Biemann, C. (2005) Semanticindexingwithtyped terms using rapid annotation in methods and applications of Semantic indexing. Workshop at the 7th International Conference on Terminology and Knowledge Engineering. Copenhagen, Denmark.
Castano, S., DeAntonellis,V.,DeCapitani,&di Vimercati,S.(2001).Globalviewingofheteregeneous data sources. IEEETransactionsonKnowledge and Data Engineering, 13(2), 277-297.
Hulth, A., & Megyesi, B.B. (2006). A study on automatically extracted keywords in text categorization. In Proceedings of the International ConferenceoftheAssociationforComputational Linguistics (pp. 537-544).
Maedche, A., & Zacharias, V. (2002) Clustering ontology-based metadata in the Semantic Web. In
ProceedingsoftheJointConferences13thEuropeanConferenceonMachineLearning(ECML’02) and 6th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD’02), LNAI, Finland, Helsinki. Springer.
Mihalcea, R., & Moldovan, D. (2000). Semantic indexing using WordNet senses. In Proceedings of ACL Workshop on IR and NLP, Hong Kong.
Muller, H.M., Kenny, E.E., & Sternberg, P.W.
(2004). Textpresso: An ontology-based information retrieval and extraction system for biological literature. PLoS Biol., 2(11), E309.
Rahm,E.,&Bernstein,P.A.(2001).Asurveyof approaches to automatic schema matching. VLDB Journal, 10(4), 334-350.
Shadbolt,N.,Berneers-Lee,T.,&Hall,W.(2006).
The Semantic Web Revisited. IEEE Intelligent Systems, 3(2), 96-101.
Wache,H.,Vogele,T.,Visser,U.,Stuckenschmidt, H., Schuster, G., Neumann, H., & Hubner, S. (2001). Ontology-based integration of information: A survey of existing approaches. In H. Stuckenschmidt (Ed.), IJCAI-01Workshop:Ontologies and Information Sharing (pp. 108-117).
Witschel, H.F., & Biemann, C.(2006). Rigorous dimensionality reduction through linguistically motivated feature selection for text categorization. In S. Werner (Ed.), Proceedings of the 15th
NODALIDA Conference, Joensuu 2005 (pp. 197-204).
endnOtes
1Medical Subject Heading Browser http:// www.nlm.nih.gov/mesh/MBrowser.html
2The Unified Medical Language System. http://umlsks.nlm.nih.gov
SOM-Based Clustering of Multilingual Documents Using an Ontology
Section II
Findings
Chapter V
Ontology-Based Interpretation
and Validation of
Mined Knowledge:
Normative and Cognitive Factors in
Data Mining
Ana Isabel Canhoto
Henley Management College, UK
aBstraCt
The use of automated systems to collect, process, and analyze vast amounts of data is now integral to the operations of many corporations and government agencies, in particular it has gained recognition asastrategictoolinthewaroncrime.Datamining,thetechnologybehindsuchanalysis,hasitsorigins in quantitative sciences. Yet, analysts face important issues of a cognitive nature both in terms of the input for the data mining effort, and in terms of the analysis of the output. Domain knowledge and bias informationinfluence,whichpatternsinthedataaredeemedasusefuland,ultimately,valid.Thischapter addresses the role of cognition and context in the interpretation and validation of mined knowledge. We propose the use of ontology charts and norm specifications to map how varying levels of access to information and exposure to specific social norms lead to divergent views of mined knowledge.
intrOdUCtiOn
Data mining has been described as a process where ‘the interrogation of the data is done by
thedataminingalgorithmratherthanbytheuser. Dataminingisaselforganizing,datainfluenced
(…) approach to data analysis. Simply put, what data mining does is sort through masses of data
Copyright © 2008, IGI Global, distributing in print or electronic forms without written permission of IGI Global is prohibited.
Ontology-Based Interpretation and Validation of Mined Knowledge
touncoverpatternsandrelationships,thenbuild models to predict behaviour’ (Chan & Lewis,
2002). This description suggests that the use of data mining techniques tend to minimize the influence that analysts have in the process. Yet, as many practitioners would point out, the reality is very different: even though data mining is a largely quantitative and automated process, the analyst, and hence subjectivity, still plays a crucial role in several steps. Far from being a straightforward and objective process, data mining requires the use of ‘intuition and creativity as well as statistical know-how, and you have to hope you have identified the right things to test’
(Humby et al., 2003).
This chapter looks at the role of the analyst in interpreting and validating the results of a data mining exercise. It suggests that, while the data mining community has long identified ways in which the analyst influences the data mining exercise, it has dedicated little attention, so far, to the understanding of the reasons why, and the mechanism how, this happens. As a result, the same literature has limited prescriptive and corrective value for subjectivity in data mining. We respond to the call for further research into the cognitive aspects of data mining (e.g., Chung & Gray, 1999; Kohavi et al., 2002; Pazzani, 2000), by proposing a framework to capture the cognitive and contextual elements shaping the process.
Nowadays,numerousorganizationsroutinely capture and mine customer records to develop profiles of who their users are and what they do in order to inform future decision making. The areas of application range from improving service or performance, to analyzing and detecting terrorist activities (Hosein, 2005). Technologies, such as RFID and mobile technology, are likely to augment the mass of information that must be coped with, and accelerate the extension of profiling to ever more areas of social life. Therefore, the technical process of development of a profile—data mining—is a problem domain of central significance bound up in the growing
debate on the role of profiling in the information society (Hildebrandt & Backhouse, 2005). This chaptercontributestoanunderstandingofhowthe process, despite being highly automated, is still likely to be affected by cognitive and contextual elements, which may fundamentally affect the effectiveness of the exercise and its outcomes. In the next section, the author presents, in broad terms, the ongoing discussion regarding the nature of data mining, as well as to what extent the analyst may interfere in the process. Then, two theories that specifically deal with subjectivity intheinterpretationandclassificationofvarious stimuli—classificationtheoryandsemiotics—are presented, compared, and contrasted. It is noted that these two theories complement each other in the sense that classification theory analyzes the cognitive process, whereas semiotics analyzes the contextual factors affecting that same process. Following from this, the author proposes a framework to capturetheeffectof affordances and social norms in shaping the cognitive process of the data mining analyst. The framework is applied to a short case study, and suggestions are given regarding areas for further research into the role of subjectivity in data mining.
BaCkgrOUnd
The processing of data in a data mining exercise includes several steps ranging from data selection and preparation to the interpretation of the emerging results. The input to the data mining process is a collection of data objects organized in a database, and the actual data interrogation processwillusuallystartwiththespecificationof the problem domain and an understanding of the goalsoftheproject.Thefollowingstagecomprises an assessment of the existing knowledge, as well as of the data that needs to be collected. The target dataset resulting from this stage is treated and, later, interrogated in order to digpiecesofknowledge from the database (Bruha, 2000). The final
Ontology-Based Interpretation and Validation of Mined Knowledge
stage consists of examining the outcomes of the data mining process, and interpreting and using the resulting information. At the end of the data mining process, the analyst has to judge whether the outcomes are possible, internally consistent, and plausible. The results typically raise further questions,sometimesinconflictwithpreviously existing knowledge, often leading to the generation of new hypotheses and the start of a new data mining cycle.
Data mining researchers have long identified two means in which the user influences data mining. One way is personal bias, such as syntactic and support constraints introduced during the process about the search space, the rules to apply and, ultimately, which patterns in the data are deemed useful or interesting (Agrawal et al.,
1993; Fayyad et al., 1996; Pazzani et al., 2001).
Another factor is domainknowledge, which refers to the information available at the beginning of the data mining process and that impacts on the questions asked from the exercise, the selection of data and/or proxies for the exercise and, ultimately, acceptance of the mined output (Anand et al., 1995; Kohavi et al., 2002; Maojo, 2004).
Furthermore, because data mining is an iterative process, with frequent feedback loops in which
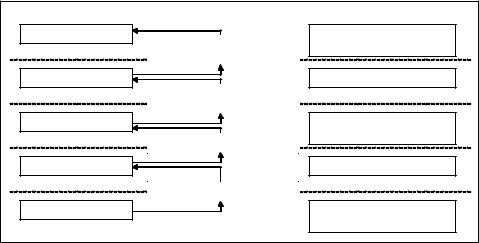
informationfeedsbackandinfluencespriorsteps in the process (Chung & Gray, 1999), the opportunities for users to influence the process are multiplied. Figure 1 illustrates how the analyst may interfere in the data mining process. The column on the left outlines the various stages of a data mining exercise. The column in the center provides examples of actions that the analyst may take, at each stage, and that impact on previous stages,forinstance,inthefinalstage,theanalyst examines the outcome of the data analysis. If the analystissatisfiedwiththeoutcome,aparticular action may be taken, for instance making an offer to a customer or reporting a suspected criminal to a law enforcement agency. If the analyst is dissatisfied with the outcome, he or she may move back to the previous stage in the process, and refine the query by changing a particular threshold, for instance. Finally, the column to the right provides examples of decisions that the analyst makes at each stage, and which impact on the result of that stage. For instance, in order to search through the data, the analyst needs to choose a model. Fayyad et al. (1996) noted that while researchers develop and advocate rather complex models, practitioners often use simple models that provide ease of interpretability. Such
Figure 1. Iterative and interactive nature of data mining
Stages
Problem specification
Data selection
Processing
Data analysis
Interpret outcome
Iteration
e.g.: choose subset of original problem domain
e.g.: select alternative data source
e.g.: further data processing
e.g.: fine tune algorithm
Interaction
e.g.: business user imparts domain knowledge
e.g.: analyst’s choice of proxies
e.g.: analyst’s criteria for attribute mining
e.g.: choice of model
e.g.: capacity to analyse all rules

Ontology-Based Interpretation and Validation of Mined Knowledge
decision has a big impact on the data analysis stage because it determines both the robustness of the model and its interpretability.
In response to the call by Pazzani (2000),
Chung and Grey (1999), and others for research into the cognitive aspects of data mining, the author reviews the conceptual understanding of theseissues,intheclassificationtheoryliterature. The next section examines how analysts’ mental schemas are formed and what the impact is for action in organizations.
COgnitiOn and COnteXt
Researchers in organizational sciences provided significant evidence that mental schemas have strong effect on perceptual processes and action in organizations (Boland et al., 2001; Carson et al., 2003; Elsbach et al., 2005; Heracleous & Barrett, 2001). Researchers in the field of classification theory (Markman & Gentner, 2001; Mervis&Rosch,1981;Rosch,1975,1978;Rosch & Mervis, 1975) concluded that individuals categorize on the basis of how close something is to the ‘prototype’ or ideal member of a category.
What determines that a material or social object is classified as a member of a given category is not some quality of the object, instead it is the resemblance of the object to the prototype for that particular category. Consequently, research
Figure 2. Typology of schemas
into classification processes requires from the researcher a focus on the mental prototypes of the individual, rather than on the attributes of the objects. Prototypes consist of very persistent templates—the schemas—that structure cognition by identifying the prominent elements of a situation and by describing the causal relations betweenthem(Elsbachetal.,2005;Fiske&Taylor, 1991; Markman & Gentner, 2001). Elsbach et al. (2005), building on the work of Fiske and
Taylor (1991), identified several common forms of schemas, summarized in Figure 2.
The information stored in the schemas is a summary of the most typical features of members in a given category, and individuals classify new exemplars on the basis of their similarity to stored exemplars—for instance, the observation that among the category ‘dogs known to have seriously injured or killed human beings’ the pit bull breed is overrepresented, led several countries and municipalities to ban the ownership of pit bulls as pet dogs, even though not all pit bulls are dangerous and they can even be, according to some experts, extremely gentle (Gladwell, 2006).
Once categories are established, individuals use them to infer features of a new situation following an inductive process—Canhoto and Backhouse
(2005) report the case of a female personal assistant at Goldman Sachs, in London, who, in the spring of 2004, was convicted of stealing £4.3m from her bosses, through fraud and forgery, and
Form |
Description |
|
|
|
|
Person schema |
Specific template about how people behave and think |
|
|
e.g., One’s freshman chemistry professor |
|
Role schema |
General template about the behaviors of individuals occupying formal roles |
|
e.g., Police officers |
||
|
||
|
|
|
|
Abstract template about how sequences of common events proceed |
|
Event schema |
e.g., How a tropical storm progresses over time from a Level-1 tropical depression to |
|
|
a Level-5 hurricane |
|
|
|
|
|
Concrete template about the relationship between certain types of actions, events or |
|
Rule schema |
concepts |
|
|
e.g., How to ask a question in class |
|
|
|