

ТЕХНОЛОГІЇ МЕНЕДЖМЕНТУ ЗНАНЬ
.pdfпроцесу набуття знань. Марк Мусен, ініціатор і розробник Protégé, так його описав:
Protégé-|: запускається на машинах Xerox LISP.
Обмежене застосування – можливий лише один метод прийняття рішень.
Protégé/Win: інтегрованіший набір інструментів. Запускається під MS Windows. Мала кількість користувачів у світі.
|
|
|
Protégé-|| об'єднує предметно |
|||
|
|
|
незалежні методи прийняття |
|||
|
|
|
рішень і автоматичну ґенерацію |
|||
Opal |
|
форм. Запускається на |
||||
|
машинах NeXTStep. |
|||||
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Protégé-2000: Охоплює модель знань ОКВС і АРІ для можливого розширення.
Запускається під будь-якою системою з Java VM. Ріст кількості користувачів через постійні Зустрічі Групи Споживачів Protégé
Protégé-OWL: На основі мови подання онтології OWL Ґрунтується на іншій логічній моделі, яка дає змогу давати визначення поняттям так само, як вони описані. Запускається під будь-якою системою з Java VM.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1988 |
1990 |
1992 |
1994 |
1996 |
|
1998 |
2000 |
2002 |
||
Рис. 7.4. Хронологія розвитку Protégé
Protégé – це не експертна система, а також не є програмою, яка безпосередньо будує експертні системи; натомість Protégé – це інструмент, що допомагає розробникам експертних систем створювати свої інструменти, спеціально пристосовані для набуття знань в конкретних прикладних областях.
Protégé-II розширив первинний двокроковий процес: генерування інструменту набуття знань і його використання для реалізації бази знань, увівши додаткові кроки, пов’язані з методами пошуку розв’язку задач.
З часом коло споживачів Protégé зростало, надходили нові ідеї та пропозиції, і тому настав час знову перебудувати Protégé. Отримавши нові вимоги до змін, розробники усвідомили, що революційна перебудова системи буде ефективнішою, ніж подальший розвиток Protégé/Win. У Protégé-2000 було введено три основні покращення. Поперше, Protégé-2000 містив реконструкцію основної моделі знань
221
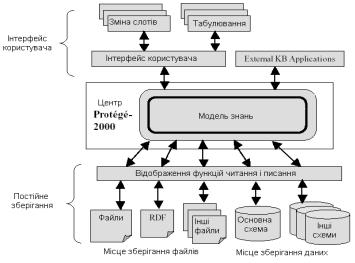
Protégé. Щоб поліпшити виразність баз знань, розробники Protégé співпрацювали з іншими розробниками експертних систем, щоб узгодити більш консенсусну модель відображення знань. Метою було дати змогу системам Protégé на основі знань взаємодіяти з іншими системами. По-друге, щоб покращити практичність і відповідність нової моделі знань, Protégé-2000 був побудований як єдина цілісна прикладна програма. І по-третє, щоб забезпечити більшу гнучкість і краще розподілити зусилля для розвитку, спроектований Protégé-2000 заснований на змінній архітектурі, підтримуваній мовою програмування Java. Нова архітектура Protégé-2000 наведена на рис. 7.5. В основу цієї архітектури покладено модель знань, котра взаємодіє з усіма об’єктами бази знань (екземпляри, класи тощо), використовуючи інтерфейс прикладного програмування (Application Programming Interface – API) Protégé. Це дало змогу незалежним розробникам вбудовувати окремі компоненти, які розширюють та змінюють функціональні можливості Protégé.
Рис. 7.5. Архітектура Protégé-2000
Окрім того, розробники Protégé-2000 створили новий інтерфейс, який спрощував споживачам роботу зі створення бази. Якісною зміною, що відбулася в Protégé-2000 порівняно з попередніми версіями
222
Protégé, є масштабованість – можливість нарощування системи в межах уніфікованої архітектури та краща пристосованість до розроблення великих баз знань.
Для розширення кола споживачів і для забезпечення постійного розвитку системи вирішено зробити Protégé-2000 загальнодоступною. Користь від такого кроку полягала у тому, що Protégé стала привабливою для розробників, які в іншому випадку, можливо, будували б подібні системи з нуля.
Фактично, найбільші перешкоди для подальшого розвитку Protégé мають, швидше, організаційний, ніж технічний характер. Для підтримки співтовариств користувачів та дописувачів Protégé, розробники створили і підтримують жваве “Protégé-обговорення” за допомогою електронного листування, витрачають значну кількість часу та зусиль, відповідаючи на запитання і забезпечуючи технічну підтримку.
7.2.2. Protégé-OWL. Мова Web онтологій OWL
Чергова модернізація Protégé-2000 полягала у введенні в основу Protégé нової мови подання знань – OWL. У результаті споживачі отримали потужний інструмент побудови онтологій баз знань з новими можливостями – Protégé-OWL.
OWL (Ontology Web Language – мова опису онтологій у Web) –
це найновіше розроблення стандартних мов для онтологій, зокрема Web-онтологій. Її розробляли як альтернативу DAML, отже, без деяких її недоліків. Ця мова орієнтована саме на відображення онтологій, а не семантики загалом. OWL будується на основі стандартів RDF і RDFS і збагачує останні новими можливостями для опису властивостей і класів. Наприклад, застосовуючи OWL, можна стверджувати, що класи не перетинаються, вказувати кардинальність та визначати еквівалентність заданих класів. OWL складається з ширшої системи типів порівняно з іншими подібними мовами.
Редактор Protégé-OWL характеризується гнучкістю та модульністю (наявна система плагінів (plug-in) і застосовується в області інженерії онтологій (Ontology Engineering), здобуття знань (Knowledge Acquisition) та автоматичного виведення (Automated Reasoning). Protégé підтримує введення бази знань будь-якою природною мовою, але сам інструмент пропонується лише англійською. Редактор також
223

підтримує будь-яку базу даних з драйвером JDBC 1.0, що уможливлює підтримку більшості реляційних баз даних (Oracle, MySQL, Microsoft
SQL Server, Microsoft Access).
Protégé-OWL дає змогу описувати класи з використанням нових можливостей. Зокрема, мова OWL має великий набір операторів і ґрунтується на логічній моделі, яка дає змогу давати визначення поняттям так, як вони описані. Тому складні комплексні поняття у визначеннях можуть бути створені з простіших. До того ж, логічна модель дозволяє використовувати механізм міркувань (reasoner), котрий може перевірити, чи твердження і визначення в онтології є взаємно послідовними, а також розпізнати відповідність визначень певним поняттям. Завдяки цьому механізму підтримується правильність ієрархії бази знань.
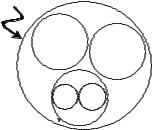
Уредакторі Protégé-OWL забезпечена можливість вибору однієї
зтрьох розроблених зараз версій мови OWL: OWL-Lite, OWL-DL, OWL-Full (рис. 7.6).
Рис. 7.6. Взаємозв’язок трьох підмов OWL
Визначальною особливістю кожної з версій є міра їх виразності. OWL-Lite є найменш виразною підмовою, проте найпростішою з синтаксисного погляду. Її найкраще використовувати для побудови простої ієрархії класів та застосування обмежень.
OWL-DL є значно виразнішою підмовою порівняно з OWL-Lite. Вона ґрунтується на логіці опису (description logics), і підтримує тих користувачів, які хочуть максимальної виразності без втрати повноти обчислень. Завдяки цьому можливо здійснювати автоматичне виведення висновків (процес міркування). Також можна обчислити ієрархію класифікації і здійснити перевірку неузгодженостей в онтології. OWL DL об’єднує всі мовні конструкції OWL з обмеженнями, на
224
зразок розділення типу (клас не може бути властивістю, а властивість не може бути індивідом або класом).
OWL-Full використовується в ситуаціях, де дуже висока виразність важливіша, ніж потреба в обчислювальних можливостях мови. Вона забезпечує максимальну синтаксичну свободу стандарту RDF без обчислювальних гарантій. Разом з тим вона використовує всі переваги попередніх двох підмов. Отже, розробники онтологій, використовуючи OWL, повинні вирішити, яку з підмов краще використати для вирішення конкретних завдань.
Загалом OWL як мова Web-онтологій розв’язує такі задачі і забезпечує:
синтаксис опису понять, зручний для всіх користувачів мережі Інтернет – людей та програмних агентів;
максимальну виразність механізмів опису понять та зв’язків між ними; механізми еволюції описів і спільного використання онтологій в
середовищі Інтернету.
Ще одна з переваг редактора Protégé – безкоштовне розповсюдження (freeware). Інструмент доступний для завантаження на офіційному сайті проекту: http://protege.stanford.edu.
7.2.3. Основні терміни та поняття у Protégé-OWL
У центрі більшості онтологій перебувають класи. Останні версії Protégé та інші фреймові системи описують онтології декларативно, явно визначаючи класову ієрархію та належність індивідних концептів до відповідних класів. Онтології, побудовані в OWL, мають подібні компоненти до онтологій на основі фреймів. Проте, на відміну від інших, термінологія OWL ґрунтується на поняттях індивідних концептів або об’єктів (найчастіше використовується саме це поняття) та властивостей, які загалом відповідають в Protégé, відповідно, екземплярам класів і слотам.
Для уникнення неузгодженості в табл. 7.1 наведено основні терміни (перший рядок) та їх синоніми (другий рядок), які найчастіше трапляються в літературі для опису онтологій.
225
|
|
|
Таблиця 7.1 |
|
Терміни та їх синоніми |
|
|
|
|
|
|
Клас |
Властивість |
|
Об’єкт |
|
|
|
|
Концепт, |
Зв’язок, слот, атрибут, |
|
Індивідний концепт, |
категорія, тип, |
роль, обмеження, |
|
екземпляр класу, |
терм, сутність |
асоціація |
|
ресурс |
|
|
|
|
Об’єкти – це окремі екземпляри предметної області. Важлива різниця між Protégé і OWL полягає в тому, що OWL не використовує однозначне присвоєння імен – Unique Name Assumption (UNA). Це означає, що дві різні назви можуть фактично посилатися на той самий об’єкт. Наприклад, назви “Королева Елізабет”, “Королева” та “Елізабет Віндзор” можуть означати той самий об’єкт. В OWL має бути чітко визначено, що об’єкти є однаковими чи відмінними один від одного, в іншому випадку назви можуть стосуватися тих самих або різних об’єктів.
Властивості – це бінарні зв’язки між об’єктами (властивості зв’язують разом два окремі об’єкти). Наприклад, властивість “мати колір” зв’язує об’єкт “Золото” з об’єктом “Жовтий”, або властивість “використовується в” зв’язує об’єкт “Золото” з об’єктом “електротехніка” (рис. 7.7).
Жовтий
|
|
|
|
|
ір |
|
|
|
|
л |
|
|
|
|
о |
|
|
|
|
к |
|
|
|
|
є |
|
|
|
|
а |
|
|
|
|
|
м |
|
|
|
|
|
Золото
використовується в
Електротехнiка
Рис. 7.7. Подання властивостей об’єкта
У Protégé властивості подаються слотами, в описовій логіці – ролями, в UML та інших об’єктно-орієнтованих поданнях – зв’язками. Властивості можуть бути оберненими, тобто мати інверсію. Наприклад, інверсія до властивості об’єкта “має колір” – “бути кольором”. Властивості можуть бути функціональними (обмежені єдиним значенням), транзитивними або симетричними. Ці характеристики детально розглянемо нижче.
226
Класи в OWL можна розглядати як множини, що містять об’єкти, котрі описують формально (математично) для точного подання їх членства в певному класі. Класи можна організовувати в ієрархію класпідклас – таксономія. OWL-підклас означає необхідність введння. Наприклад, об’єкти “Чавун” і “Сталь” (рис. 7.8) належать до класу “Залізовуглецеві сплави”, котрий, своєю чергою, разом з “Металокерамічними сплавами” та “Сплавами на основі кольорових металів” є підкласом “Сплавів”. У разі побудови глибшої ієрархії, об’єкти “Чавун” і “Сталь” можна розглядати як окремі класи зі своїми підкласами та об’єктами.
Сплави
Метало керамічні На основі
кольорових
металів
Чавун Сталь
Залізо  вуглецеві
вуглецеві
Рис. 7.8. Подання структури класів
В OWL-класах створюють описи, які конкретизують умови, котрим повинен відповідати об’єкт, щоб увійти до складу екземплярів класу. Детальніше про створення описів належності об’єктів до певних класів засобами Protégé-OWL описано в наступних параграфах.
7.2.4. Методика розроблення онтології засобами Protégé
Перед тим, як приступити безпосередньо до проектування онтології, варто звернути увагу на деякі фундаментальні правила її розроблення, які у багатьох випадках можуть допомогти у процесі ухвалення проектних рішень:
1)онтологія – це модель реального світу, і поняття в ній повинні відображати цю реальність;
2)не існує єдиного правильного способу моделювання предметної області – завжди є життєздатні альтернативи; найкраще рішен-
227
ня часто залежить від вимог до кінцевого продукту та очікуваних модернізацій;
3)розроблення онтології – це обов’язково ітеративний процес, тобто постійно відбувається наповнення й уточнення;
4)поняття в онтології мають бути максимально близькими до реальних об’єктів (фізичних чи логічних) та їх властивостей.
Нижче наведено загальну методику побудови онтологій, котру можна реалізувати засобами Protégé. Ця методика складається з семи кроків.
Крок 1. Визначення області та масштабу онтології. Роботу над розробленням онтології треба почати з визначення її обсягу та області застосування. Для цього спочатку розробляють питання компетентності для перевірки відповідності онтології заданій предметній області, які надалі виконуватимуть функції лакмусового папірця, даючи уявлення про повноту поданої інформації та рівень її деталізації.
Крок 2. Можливість використання наявних онтологій. Варто врахувати, що над задачею створення онтології, наприклад, в області матеріалознавства, працював ще хтось. Тоді треба перевірити можливість адаптації наявних онтологічних систем для нашої конкретної предметної області. В іншому випадку роботу треба розпочинати з нуля. Сьогодні є доступними багато розроблених онтологій в різних предметних областях. Вони можуть бути успішно імпортовані в середовище проектування, вибране розробником.
Крок 3. Перелік важливих термінів в онтології. Корисно скласти список всіх термінів та їх властивостей, які містять основну інформацію про задану предметну область. Наприклад, у число важливих термінів, пов’язаних з матеріалознавством, входять металознавство, залізовуглецеві сплави, метали, їх пластична деформація; матеріали, напівпровідники, донорні домішки та хімічна чистота елемента; пористість порошкових матеріалів тощо. На початку важливо отримати повний список термінів, не турбуючись про те, наприклад, чи є поняття класом чи властивістю.
Наступні два кроки найважливіші у процесі проектування онтології: це розроблення ієрархії класів і визначення властивостей понять (слотів), які тісно між собою переплетені. Тому їх можна виконувати паралельно.
Крок 4. Визначення класів та їх ієрархії. Існує декілька підходів для побудови ієрархії класів: згори–донизу, знизу–догори та комбіно-
228
ваний процес. На основі власного досвіду та ряду інструкцій з розроблення онтологій зазначимо типові помилки, які допускають розробники, проектуючи ієрархію понять.
1.Вводити в ієрархію одне і те саме поняття як в однині, так і у множині, зробивши перше підкласом другого. Найкращий спосіб уникнути такої помилки – завжди використовувати імена класів або в однині, або у множині.
2.Не розрізняти клас і його ім’я: класи відображають поняття предметної області, а не слова, які позначають ці поняття.
3.Сприймати синоніми як представники різних класів.
4.Створювати цикли в ієрархії класів. Вважається, що в ієрархії
єцикл, коли в деякого класу А є підклас В, і в той самий час В – надклас А.
Крок 5. Визначення властивостей класів. Після визначення певної кількості класів необхідно описати внутрішню структуру понять. На кроці 3 були вибрані класи зі створеного списку термінів. Більшість термінів, що залишилися, ймовірно, будуть властивостями цих класів. Усі підкласи класу успадковують властивість цього класу.
Крок 6. Визначення фацетів властивостей. Властивості можуть мати різні фацети, які описують тип і коефіцієнт (потужність) значення властивості, діапазон та інші характеристики, які може мати властивість.
Потужність властивості визначає, скільки значень може мати ця властивість. У деяких системах розрізняють тільки одиничну потужність (лише одне значення) і множинну потужність (будь-яку кількість значень). Можна встановити мінімальну потужність – 0. Це встановлення означатиме, що для певного підкласу слот не може мати значень. Фацет описує тип значення слота, які типи значень (рядок, число, число з плаваючою комою, ціле число) можна присвоїти властивості. Нумеровані властивості визначають список конкретних дозволених значень властивості.
Крок 7. Створення екземплярів. Останній крок – це створення окремих екземплярів класів в ієрархії. Для визначення окремого екземпляра класу необхідно: 1) вибрати клас; 2) створити окремий екземпляр цього класу і 3) ввести значення слотів.
Розроблення онтологій відрізняється від проектування класів і зв’язків в об’єктно-орієнтованому програмуванні. Об’єктно-орієнто- ване програмування зосереджується, головно, на методах класів –
229
програміст ухвалює проектні рішення на основі операторних властивостей класу, тоді як розробник онтології ухвалює ці рішення, ґрунтуючись на структурних властивостях класу. Як результат, структура класу і відношення між класами в онтології відрізняються від структури подібної предметної області в об’єктно-орієнтованій програмі.
Створення й експлуатація онтології
Сьогодні у світі гостро стоїть питання створення інтелектуальних систем в певних галузях науки та промисловості, які могли б значною мірою спростити інженерам та науковцям пошук і доступ до величезних об’ємів інформації. Багато наявних онтологій призначені для використання у промисловості у складі інтелектуальних систем, функцією яких є прийняття рішень під час вирішення конкретних завдань. Як приклад можна навести побудову та використання онтології у складі системи керування знаннями в металопромисловості в Тайвані. Ця онтологія використовується в системі керування знаннями на етапі маніпулювання і підтримки задачі керування та пошуку. Однак вона охоплює лише певну частину області матеріалознавства – металургію, а також не забезпечує повного подання властивостей матеріалів, хоча достатньо в повній мірі містить знання про методи та технології їх виготовлення. Існує мало універсальних інтелектуальних систем, онтологія яких охоплювала б всю предметну область науки, в якій працює ця система, а в наукових дослідженнях треба мати якнайповнішу інформацію про об’єкт досліджень. Тому інтелектуальна система має забезпечити користувачу вичерпну інформацію, при цьому необхідно передбачити своєчасне поновлення бази знань новими знаннями.
Розроблена онтологія слугуватиме ядром бази знань для інтелектуальної системи, яка забезпечуватиме пошук та семантичне розпізнавання інформації, що надходить, зокрема з мережі Інтернет, нагромадження і класифікацію отриманої інформації та її використання в наукових дослідженнях. Використання такої системи в поєднанні з можливостями Інтернету дасть змогу науковцям та інженерам з певної ПО різних наукових установ мати доступ до інформації, здійснювати швидкий та ефективний пошук і отримувати експертні висновки від інтелектуальної системи на основі запитів. Особливістю бази знань розроблюваної інтелектуальної системи є можливість динамічного наповнення її новими знаннями та наявність алгоритмів оптимізації
230