

ТЕХНОЛОГІЇ МЕНЕДЖМЕНТУ ЗНАНЬ
.pdfНа першому рівні відбувається введення інформації з певного джерела (від людей, з джерел даних, таких як бази даних, Інтернет тощо).
На другому рівні відбувається продукування, на якому дані записуються в базу даних, цифрові файли чи пошукову машину. Основною проблемою є те, що група чи проект вводять одну і ту саму інформацію по-різному. Як результат отримують багато жорсткозв’язаних систем.
Третім рівнем процесу може бути (а може й не бути) інтеграція, яка залежить від складності інформаційної структури комплексу. Оскільки всі інформаційні системи є жорстко-зв’язаними, то зазвичай інтеграція цих систем для отримання цілісної картини є не дуже хорошим рішенням. Відповідно, процес інтеграції систем не міститиме повторюваних частин, тобто кожен раз інтеграцію треба буде починати спочатку. Якщо навіть існує інтеґраційне рішення, то корпорації платять великі гроші інтеграторам за дуже дорогу інформаційну систему, що інтегруватиме інші системи.
Четвертий рівень процесу – пошук знань серед внутрішніх ресурсів корпорації (необов’язково враховуючи інтеграційну систему). Це довготривалий та, за суттю, майже випадковий процес. Понад усе, часто інформація, яку шукають, може бути недостатньо релевантною через свою загальність.
Наступний рівень – це утворена програма з результатів пошуку. З цієї системи можна отримати зазвичай презентацію чи звіт. Після того, як новий продукт створений, результати звітів можуть зберігатися, але зазвичай вони ще складніше класифікуються, ніж жорсткозв’язані системи. Ще одною проблемою в системах такого роду є версифікація документів, адже перебирати щоразу документи у всіх системах нереально, а явну версифікацію запроваджувати для всіх файлів теж дуже складно. Ну і нарешті, останньою постає проблема повторного використання даних.
Як результат така система знань має дуже складну структуру, і тому її важко інтегрувати з іншими системами. Інтегруючи, треба дотримуватися такого правила: системи не можуть розпізнавати одна одну, якщо вони не працюють через однаковий контракт. Інформаційний контракт декларує способи взаємодії систем так, що одна система підтримує контракт, а інша, знаючи про його існування, використовує цей контракт як вхідний інтерфейс системи. Загалом такий контракт треба спеціально описувати. У випадку з онтологіями сама онтологія є контрактом між двома системами, які інтегруються.
191

1. |
Втрачені дані |
|
ВВІД |
||
|
2.
ПРОДУКУВАННЯ
??
ПОШУКИ 
?? |
3. |
|
ІНТЕГРАЦІЯ |
||
|
пошук
4.
ДОСЛІДЖЕННЯ
??
Нова, дорога жорсткозв‟язана система
|
|
|
|
|
|
|
|
|
|
|
|
із |
|
|
|
ії |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
л |
|
|
|
ц |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
а |
|
|
|
а |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
н |
|
|
|
м |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
а |
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
ий |
|
|
|
|
|
ор |
|
|
|
|
|
|
|
|||
|
|
|
|
н |
|
|
|
|
|
|
ф |
|
|
|
|
|
|
|
|
||
|
|
|
ч |
|
|
|
|
їін |
|
|
|
|
|
|
|
|
|
||||
|
|
у |
|
|
|
|
о |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
Р |
|
|
|
|
н |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
е |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
айд |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
зн |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
єї |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
всі |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Зберігати для |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
наступних пошуків? |
4. |
Спільне написання звіту |
ЗВІТ |
|
|
|||||||||||||||||
ПРОГРАМА |
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Втрачені дані |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
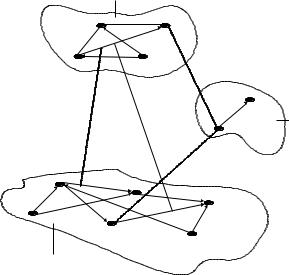
Рис. 6.3. Процес роботи зі знаннями в типових системах
Тепер онтології все частіше використовують в реальних проектах. Переваги онтологій:
використання єдиних термінів у біохімічних знаннях пришвидшує розроблення, а також дає можливість передавати знання;
онтології забезпечують додаткові можливості з формування і тестування наукових тез, з опрацювання даних природною мовою, з інтеграції даних.
Одним з прикладів проектів, які використовують онтології для роботи з біохімічними знаннями, є GONG. Він був спрямований на генерацію генетичної онтології GO (Gene Ontology).
Іншими прикладами розроблених онтологій в галузі біохімії є онтологія DOLCE та онтологія Ontology Works. Вони містять
192
формальні визначення базових елементів в біохімії (процесів, подій, випадків, типів тощо).
Отже, проекти GONG, DOLCE та інші описують частину загальних характеристик біологічних даних. Основною метою роботи була оцінка складності використання загальноприйнятих технік моделювання за допомогою онтологій. Автори переконують, що використання онтологій допоможе описувати різноманітні аспекти біохімії та молекулярної біології розподілено та дистанційно. Біохімічні онтології використовують як основу побудови баз даних для зберігання інформації. Як результат роботи створений спеціальний стандарт XML – SBML (Systems Biology Markup Language), який використовується для обміну інформацією між імітаційними моделями біохімічних реакцій.
У[144] описане використання онтологій у блогах з відкритим кодом. Проект VIStology’s IBlogs призначений розробити розподілену інтелектуальну систему для автоматичного моніторингу блогів. У проекті розроблені онтологія Blog та онтологія News Event. Вони дають можливість отримувати знання з блогів і передавати їх у вигляді стрічок новин RSS.
Автори підводять підсумки своєї роботи: проект IBlogs робить перші кроки в побудові технології, яка повинна вирішити проблему аналізу, інтерпретації та агрегації вмісту блогів. Проект демонструє, що використання онтологій є корисним для перегляду інформації про блоги та взаємозв’язки між його складовими – публікаціями, у вигляді невеликих заміток про нові події, методи, технології тощо.
Стаття про моделювання знань в системі EON [6] описує як використовувати систему для побудови інформаційних моделей знань про пацієнтів, медичні спеціальності та про медичні рішення і дії у відповідних випадках. Система EON має складну серверну структуру, складається з багатьох компонентів, обмін між якими здійснюється за допомогою онтологій.
За визначенням авторів, система EON створена для структурування інформації про пацієнтів, медичні концепції та загальні знання.
Уцій системі клінічні рекомендації можуть бути інтерпретовані для читання пацієнтами чи для формування таксономічних ієрархій медичних термінів.
Устатті [42] описано, як за допомогою онтологій та правил можна порівнювати різні ступені та оцінки у різноманітних системах
193
оцінювання. Наводиться приклад порівняння оцінок у північно-аме- риканських (оцінки від “F” до “A+”), східноєвропейських (оцінки від “2” до “5”) та інших вузах.
На основі GO (Gene Ontology), яка згадувалася раніше, розроблені засоби для анотації біомедичних даних. Ці засоби є основаними на онтологіях і дають можливість не лише індексувати біомедичні ресурси, але й давати доступ до інформації про них на Web-сторінках. Архітектура системи побудована так, щоб вона інтеґрувалася з Webпорталом з одного боку, і щоб видобувала знання з різнотипних ресурсів, з іншого.
Упідсумку роботи над GO (Gene Ontology) описана реалізація прототипу системи анотування, основаної на онтологіях. Завдання системи – описати велику кількість біомедичних ресурсів для створення каталогу анотованих елементів. Ресурси NCBO (National Center for Biomedical Ontology) складені в найбільшу бібліотеку біомедичних ресурсів, і система анотування дає змогу користувачеві знаходити різноманітну біомедичну інформацію, використовуючи одну точку входу, тобто єдиний репозиторій знань і, отже, не витрачати час на пошук біомедичних ресурсів у Webі. Система здатна опрацьовувати метадані з множинами генетичних виразів, радіологічних рисунків, клінічних звітів тощо, перетворюючи їх у відповідні онтології.
Усередовищах eHealth використовуються онтології для поширення клінічних знань та даних про онкологічні дослідження. В eHealth описано процес створення онтологій, які повинні максимально відповідати реаліям в сучасних дослідженнях та відображеннях знань. Причини вибору онтологій як засобу відображення знань:
логічна структура, яку можна алгоритмічно опрацьовувати; пряма відповідність термінів та знань; інтероперабельність (можливість взаємодії мереж).
Висновки, зроблені авторами, є такими. Середовища eHealth надають зручні та корисні утиліти для роботи з біомедичними онтологіями. Досягнуто консенсусу між розробниками у великій кількості аспектів, пов’язаних з описом знань, алгоритмами роботи тощо.
Абсолютно очевидним є той факт, що онтології набули найбільшого використання в біомедичній галузі. Основною причиною є те, що знання в медицині є неточними та часто слабко формалізованими. До початку використання онтологій в медицині існувала велика кількість
194
аплікацій, які по різному трактували одні і ті самі поняття. Сьогодні ситуація істотно покращилась завдяки можливості загального доступу до знань. Системи стали менш залежними одна від одної. Цього намагалися досягти розробники онтологій. Також онтології починають активно застосовувати для добре досліджених предметних областей, наприклад, блогів, об’єднань людей, форумів тощо.
6.2. Моделі онтології й онтологічної системи
Вище вже наголошувалося, що поняття онтології припускає визначення і використання взаємозв’язаної та взаємоузгодженої сукупності трьох компонентів: таксономії термінів, визначень термінів і правил їх опрацювання. Враховуючи це, введемо таке визначення поняття моделі онтології.
Під формальною моделлю онтології О розумітимемо впоряд-
ковану трійку такого вигляду:
О = <С, R, F>,
де С – скінченна множина концептів (понять, термінів) предметної області, яку задає онтологія О; R – скінченна множина відношення між концептами (поняттями, термінами) заданої предметної області; F – скінченна множина функцій інтерпретації (аксіоматизація), заданих на концептах чи відношеннях онтології О.
Зазначимо, що природним обмеженням, яке накладається на множину С, є його скінченність і непустота. Інша справа з компонентами F і R у визначенні онтології О. Зрозуміло, що і в цьому разі F і R мають бути скінченними множинами. Розглянемо окремі випадки, коли ці множини порожні.
Нехай R = Ø і F= Ø. Тоді онтологія О трансформується у простий словник:
О = V = <С, {}, {}>.
Така вироджена онтологія може бути корисна для специфікації, поповнення і підтримки словників ПО, але онтологічні словники мають обмежене використання, оскільки не вводять експліцитно значення термінів. Хоча в деяких випадках, коли використовувані терміни належать до дуже вузького (наприклад, технічного) словника, і їх значення вже наперед добре узгоджені в межах певного (наприк-
195
лад, наукового) об’єднання, такі онтології застосовують на практиці. Відомими прикладами онтології цього типу є індекси машин пошуку інформації в мережі Інтернет.
Інша ситуація у разі використання термінів природної мови або в тих випадках, коли спілкуються програмні агенти. У цьому разі необхідно характеризувати передбачуване значення елементів словника за допомогою відповідної аксіоматизації, мета використання якої – вилучення небажаних моделей і в тому, щоб інтерпретація була єдиною для всіх учасників спілкування.
Інший варіант відповідає випадку R=Ø, але F≠Ø. Тоді кожному елементу множини термінів із С може ставитися у відповідність функція інтерпретації f з F. Формально це твердження можна записати так.
Нехай С = С1 С2, причому С1 С2 = Ø, де С1 – множина термінів, що інтерпретуються; С2 – множина інтерпретаційних
термінів. Тоді
(с С1, у¹, у², ....., у k С2),
такі що
с = f ( y¹, y²,…, y k ),
де f є F.
Те, що перетин множин С1 і С2 – порожня множина унеможливлює циклічні інтерпретації, а введення на розгляд функції k арґументів покликано забезпечити повнішу інтерпретацію. Тип відображення f із F визначає виразну потужність і практичну корисність цього виду онтології. Так, якщо припустити, що функція інтерпретації задається оператором присвоєння значень (С1 : = С2, де С1 – ім’я інтерпретації С2), то онтологія трансформується в пасивний словник Vр:
О = Vр = <С1 С2, {},{:=}>.
Такий словник пасивний, оскільки всі визначення термінів із С1 беруться з уже наявної та фіксованої множини С2. Практична цінність його вища, ніж простого словника, але недостатня, наприклад, для відображення знань у задачах опрацювання інформації в Інтернеті через динамічний характер цього середовища.
Щоб урахувати останню обставину, припустимо, що частина інтерпретаційних термінів із множини С2 задається процедурно, а не
196
декларативно. Значення таких термінів “обчислюється” щоразу під час їх інтерпретації.
Цінність такого словника для задач опрацювання інформації в середовищі Інтернет вища, ніж у попередньої моделі, але все ще недостатня, оскільки елементи, що інтерпретуються з С1, ніяк не зв’я- зані між собою, отже, виконують лише функцію ключів входження в онтологію.
Для відображення моделі онтології, яка потрібна для розв’я- зування задач опрацювання інформації в Інтернеті, очевидно, вимагається відмовитися від припущення R = Ø.
Отже, припустимо, що множина відношень на концептах онтології не порожня, і розглянемо можливі варіанти її формування.
Для цього введемо в розгляд спеціальний підклас онтології – просту таксономію, а отже:
О = Т0 = < С, {IS-A}, {} >.
Під таксономічною структурою розумітимемо ієрархічну систему понять, зв’язаних між собою відношенням IS-A (“бути елементом класу”).
Відношення IS-A має фіксовану наперед семантику і дає змогу організувати структуру понять онтології у вигляді дерева. Такий підхід має свої переваги і недоліки, але загалом є адекватним і зручним способом для відображення ієрархії понять.
Результати аналізу окремих випадків моделі онтології наведені в табл. 6.1.
|
|
|
|
Таблиця 6.1 |
|
Класифікація моделей онтології |
|
||
|
|
|
|
|
Компонент |
R = Ø |
R= Ø |
R = Ø |
R={IS-A} |
и моделі |
F =Ø |
F ≠ Ø |
F ≠ Ø |
F = Ø |
Формальне |
<С,{},{}> |
<С1 С2 {},F> |
<Сı (С2΄ |
<С,{IS-A}, {}> |
визначення |
|
|
ρ2΄), {}, F > |
|
|
|
|
|
|
Пояснення |
Словник |
Пасивний |
Активний |
Таксономія |
|
ПО |
словник ПО |
словник ПО |
понять ПО |
|
|
|
|
|
Далі можна узагальнити окремі випадки моделі онтології так, щоб забезпечити можливість:
197
відображення множини концептів С у вигляді мережевої структури; використання достатньо великої множини відношень, яка об’єднує не
тільки таксономічні відношення, але і відношення, що відображають специфіку конкретної предметної області, а також засоби розширення множини R;
використання декларативних і процедурних інтерпретацій і відношень, зокрема можливість визначення нових інтерпретацій.
Тоді можна ввести в розгляд модель розширюваної онтології і досліджувати її властивості. Проте, враховуючи технічну спрямованість цього підручника, ми не робитимемо цього, а охочих ознайомитися з такою моделлю скеруємо до роботи [44]. Як показано в цій роботі, модель розширюваної онтології є достатньо могутньою для специфікації процесів формування просторів знань в середовищі Інтернет. Разом з тим і ця модель є неповною через свою пасивність навіть там, де визначені відповідні процедурні інтерпретації та введені спеціальні функції поповнення онтології. Адже єдиною точкою керування активністю в такій моделі є запит на інтерпретацію певного концепту. Цей запит виконується завжди однаково й ініціює запускання відповідної процедури. А власне виведення відповіді на запит чи пошук необхідної для цього інформації залишається поза моделлю і повинен реалізовуватися іншими засобами.
З огляду на вищесказане, а також необхідність експліцитної специфікації процесів функціонування онтології, введемо в розгляд поняття онтологічної системи.
Під формальною моделлю онтологічної системи 0 розуміють триплет вигляду:
0 = < O meta , {O domain }, Ξ inf >,
де O meta – онтологія верхнього рівня (метаонтологія); {О domain } – множина предметних онтологій і онтологій задач предметної області;
Ξ inf – модель машини виведення, асоційованої з онтологічною системою 0 .
Використання системи онтологій і спеціальної машини виведення дає змогу розв’язувати в такій моделі різні задачі.
Збагачуючи систему моделей {О domain }, можна враховувати побажання користувача, а змінюючи модель машини виведення,
198
вводити спеціалізовані критерії релевантності, що одержують у процесі пошуку інформації, і формувати спеціальні репозиторії нагромаджених даних, а також поповнювати, за необхідності, використовувані онтології.
У моделі 0 є три онтологічні компоненти: метаонтологія; предметна онтологія; онтологія задач.
Як йшлося вище, метаонтологія оперує загальними концептами і відношеннями, які не залежать від конкретної предметної області. Концептами метарівня є загальні поняття, такі як “об’єкт”, “властивість”, “значення” тощо. Тоді на рівні метаонтології отримуємо інтенсіональний опис властивостей предметної онтології й онтології задач. Онтологія метарівня є статичною, що дає можливість забезпечити тут ефективне виведення.
Предметна онтологія O domain містить поняття, що описують конкретну предметну область, відношення, семантично значущі для заданої предметної області, і множину інтерпретацій цих понять і відношень (декларативних і процедурних). Поняття предметної області специфічні в кожній прикладній онтології, але відношення – універсальні. Тому як базис зазвичай виділяють такі відношення моделі предметної онтології, як part_of, kind_of, contained_in, member_of, see_also і деякі інші.
Відношення part_of, визначене на множині концептів, є відношенням належності і показує, що концепт може бути частиною інших концептів. Воно є відношенням виду “частина–ціле” і за властивостями близьке до відношення IS-A і може бути задане відповідними аксіомами. Аналогічно можна ввести й інші відношення виду “частина–ціле”.
Відношення see_also має іншу семантику й інші властивості. Тому доцільно вводити його не декларативно, а процедурно, подібно до того, як це роблять, визначаючи нові типи в мовах програмування, де підтримують абстрактні типи даних:
X see_also Y:
see_also member_of Relation {
if ((X is_a Notion) & (Y is_a Notion) & (X see_also Y)) if (Operation connected_with X) Operation connected_with Y}.
Зазначимо, що і відношення see_also “не цілком” транзитивне.
Так, якщо припустити, що (X1 see_also Х2) & (Х2 see_also X3), то
199
можна вважати, що (X1 see_also Х3). Проте у міру збільшення довжини ланцюжка об’єктів, зв’язаних цими відношеннями, справедливість транзитивного перенесення властивості connected_with зменшується. Тому у разі відношення see_also ми маємо справу не з відношенням часткового порядку (як, наприклад, у разі відношення IS-A), а з відношенням толерантності. Однак для простоти це обмеження може бути перенесене з визначення відношення у функцію його інтерпретації.
Метаонтологія
Онтологія задач
Онтологія ПО
Рис. 6.4. Взаємозв’язок між онтологіями онтологічної системи
Аналіз різних предметних областей показує, що введений вище набір відношень є достатнім для початкового опису відповідних онтологій. Зрозуміло, що цей базис є відкритим і може поповнюватися залежно від предметної області і цілей, що стоять перед прикладною системою, в якій така онтологія використовується.
Онтологія задач як поняття містить типи розв’язуваних задач, а відношення цієї онтології, як правило, специфікують декомпозицію задач на підзадачі. Разом з тим, якщо прикладною системою розв’язується єдиний тип задач (наприклад, задачі пошуку релевантного запиту інформації), то онтологія задач може в такому разі описуватися слов-
200