

6.4. Кластеризация данных
6.4.1. Принцип организации кластеров
Кластеризация является методом совместного хранения родственных данных (таблиц). Кластер – это структура памяти, в которой хранится набор таблиц (в одних и тех же блоках данных). Эти таблицы должны иметь общие столбцы, используемые для соединения (например, первичный ключ таблицы ТОВАРЫ и внешний ключ таблицы ПОСТАВКИ, рис. 6.6,б).
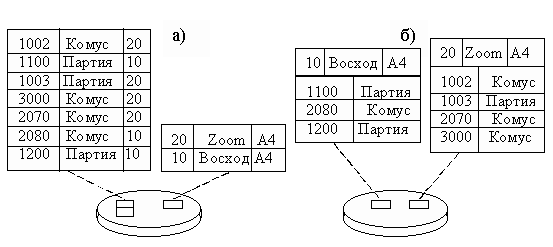
Рис. 6.6. Некластеризованные (а) и кластеризованные (б) данные
Кластерный ключ – это столбец или набор столбцов (полей записи), общих для кластеризуемых таблиц. Каждая таблица, созданная в кластере, должна иметь столбцы, соответствующие типам и размерам столбцов кластерного ключа. Количество столбцов в кластерном ключе ограничено (например, для Oracle8 это ограничение равно 16).
Совместное хранение означает, что на одной странице или в одном блоке памяти хранятся данные из всех кластеризованных таблиц, имеющие одинаковое значение кластерного ключа. Физически это обычно реализуется так: в начале страницы (блока) хранится запись из таблицы, для которой кластерный ключ является первичным (или уникальным), а вслед за ней располагаются записи из другой таблицы (таблиц), имеющие те же значения кластерного ключа. Фактически, данные хранятся в виде соединения таблиц по значениям кластерного ключа. В этом случае выигрыш по времени для выполнения соединения таблиц по сравнению с раздельно хранимыми таблицами составляет 3-6 раз.
Если все данные, относящиеся к одному значению кластерного ключа, не помещаются в одном блоке, то выделяется новый блок памяти и предыдущий блок хранит ссылку на него. Но если система позволяет изменять размер блока (в частности, СУБД Oracle), при создании кластера желательно установить размер блока, исходя из оценки среднего количества записей с одинаковыми значения кластерного ключа.
Значения кластерного ключа таблицы могут обновляться, но, так как расположение записи зависит от этого значения, обновление может вызвать физическое перемещение записи. Поэтому часто обновляющиеся атрибуты не являются хорошими кандидатами на вхождение в кластерный ключ.
Два основных преимущества кластеров:
Уменьшается обмен с диском, улучшается время доступа к кластеризованным таблицам и их соединение.
Значение кластерного ключа хранится только один раз для кластера вне зависимости от того, сколько строк различных таблиц имеют это значение кластерного ключа, за счёт чего достигается экономия памяти.
С другой стороны, наличие кластеров обычно увеличивает время выполнения операции добавления записи (INSERT), т.к. требует от системы дополнительных временных затрат на просмотр блоков данных для поиска того блока, куда нужно поместить новую запись. (Наличие кластеров прозрачно для пользователей и приложений.)
6.4.2. Использование кластеров
Кластеры обычно строятся для таблиц, часто используемых в соединении друг с другом, например, связанных отношением "один-ко-многим". Не стоит создавать кластер:
если данные в кластерном ключе этих таблиц часто обновляются;
если часто требуется полный просмотр отдельной таблицы.
если суммарные данные таблиц с одним и тем же значением кластерного ключа занимают больше одного блока данных.
Изменение столбцов кластера требует гораздо больше системных ресурсов, чем обновление некластеризованных данных, так что выигрыш от ускорения поиска данных оказывается меньше, чем затраты на физическое перемещение строк.
Полный просмотр индивидуальных таблиц кластера требует больше времени, чем просмотр некластеризованных таблиц, т.к. физически требуется обратиться к большему числу блоков. Если по отдельности некластеризованные таблицы занимают n1 и n2 блока соответственно, то вместе они будут занимать (n1+n2) блоков, и для полного просмотра каждой из них придётся обращаться к диску (n1+n2) раз.
Часто для окончательного определения целесообразности создания кластера в конкретной ситуации ставят эксперименты и измеряют производительность БД.