

V. Системы управления базами данных План
Общие сведения о СУБД.
Место БД при различной архитектуре вычислительной системы.
Модели данных.
Язык манипулирования данными для реляционной модели – SQL.
Концепции и возможности СУБД ACCESS.
Концепции и возможности СУБД Oracle.
Информация о СУБД MySQL.
Информация о СУБД Sybase.
Информация о СУБД Interbase.
Сравнение СУБД Postgres и MySQL.
Заключение.
Общие сведения о субд
Первые СУБД появились в конце семидесятых годов. К концу восьмидесятых годов СУБД стали основным инструментом для организации быстрого и эффективного доступа к данным. Компонентами системы БД являются СУБД, БД, описание схемы БД, язык описания данных (ЯОД), язык манипулирования данными (ЯМД). Дадим определения, используемых терминов.
База данных – это данные, организованные в виде набора записей определенной структуры и хранящиеся в файлах, где помимо самих данных, содержится описание их структуры.
СУБД – это программно–технологический комплекс, интегрирующий аппаратные средства, БД на технических носителях, программное обеспечение управления БД в самом широком смысле этого термина (операции выборки, линейных преобразований БД и других), а также программируемую логику и набор процедур.
Схема – коллекция объектов БД, содержащих таблицы, индексы, кластеры, представления, снимки – журналы репликации, последовательности, синонимы, пакеты. При проектировании больших БД выделяются подсхемы.
ЯОД – позволяет описать БД в терминах, принятых в конкретной СУБД
ЯМД – позволяет управлять данными (выбирать, сортировать, создавать и др.).
Индекс – дополнительно созданная таблица в БД, состоящая из индекса и ключевых полей основной таблицы, отсортированная по одному из них, позволяет извлекать данные быстро и эффективно.
Кластер – набор таблиц, которые физически хранятся как одна и имеют общие столбцы.
Кэш – область оперативной памяти, выделяемой для приложения, позволяет осуществить быстрый доступ к данным по ранее выполненным запросам.
Объекты схемы – это абстракция (логическая структура) составляющих базы данных.
Пакет – набор процедур, функций, переменных, констант, исключений и др.
View представление – виртуальная таблица, в состав атрибутов которой включены атрибуты из одной или более таблиц.
Процедура – это набор SQL – команд, который выполняет определенную задачу. Процедура может иметь входные параметры, но не имеет выходных.
Репликация – процесс синхронизации в распределенной БД снимков и представлений, на основе которых они созданы.
Снимки – это таблица, содержащая результат запроса с удаленной ЭВМ.
Транзакция – логически завершенный фрагмент последовательности действий (одна или более SQL–команд, завершенных фиксацией или откатом).
Триггер – блок инструкций SQL. Это механизм, позволяющий создавать процедуры, которые будут автоматически запускаться при выполнении команд INSERT, UPDATE или DELETE.
Характеристики некоторых СУБД даны в табл.15.
Таблица 15
Характеристики субд
|
Характеристики |
ORACLE |
IBM DB2 |
MS SQL |
SYBASE |
|
Язык программирования |
Java, Delphi, PL/SQL |
Java, SQL 2000 |
Transact-SQL |
Java, Transact-SQL |
|
XML– библиотеки |
Да |
Да |
Да |
Да |
|
Объектно–ориентированное проектирование |
Да (через SQL) |
Да (через SQL) |
Нет |
Да (через Java) |
|
Мультимедийные типы данных |
Да |
Да |
Ограниченно |
Ограниченно |
|
Enterprise JavaBeans |
Да |
Нет |
Нет |
Нет |
|
CORBA |
Да |
Нет |
Нет |
Нет |
|
Макс. размер таблиц |
Не ограничено |
64 Гбайт |
|
Не ограничено |
|
Макс. число таблиц |
Не ограничено |
Практически не ограничено |
Не ограничено |
Не ограничено |
|
Макс. число таблиц на одно соединение |
Не ограничено |
31 |
Не ограничено |
Не ограничено. |
|
Макс. число пользователей |
Не ограничено |
Практически не ограничено |
Не ограничено |
Не ограничено |
|
Рекомендуемая емкость оперативной памяти |
Изменяемая величина |
Локал: 550Кб. Удаленный: 250 Кб |
- |
50 Кбайт |
Направление развития реляционных СУБД в последние годы заметно меняется. Если в предыдущее десятилетие они развивались, чтобы обеспечить быстрый доступ к алфавитно – цифровым данным, то теперь часто нужно хранить еще графические и звуковые данные. Существенно изменилась аппаратная среда – она стала сетевой. С развитием Web – технологий появилась необходимость поддерживать HTML – страницы, 3-, 4- и n-мерные данные. И все это можно создавать на основе БД.
Место БД при различной архитектуре вычислительной системы
Долгое время использовался централизованный (персональный) вариант применения СУБД. Централизованная архитектура: СУБД и БД размещаются и функционируют на одном компьютере, а пользователи получают доступ к БД через терминал.
В архитектуре «файл – сервер» (рис.8) БД
хранится на сервере, а СУБД устанавливаются
на каждой ЭВМ.
архитектуре «файл – сервер» (рис.8) БД
хранится на сервере, а СУБД устанавливаются
на каждой ЭВМ.
Рис.8. Архитектура файл – сервер
Производительность зависит от компьютера пользователя, при этом значительно загружается сеть для передачи данных.
В современных СУБД используется архитектура «клиент – сервер» (рис.9), когда БД хранится на сервере, а СУБД имеет клиентскую и серверную части.
Чтобы уменьшить еще объем передачи данных, которые должны подвергаться прикладной обработке, предлагается трехуровневая архитектура «тонкий клиент – сервер приложений – сервер БД» (рис.10). Тонкий клиент обеспечивает взаимодействие с пользователем через браузер, вся прикладная обработка выносится на сервер приложений, который обеспечивает формирование запроса к БД. Сервер БД и сервер приложений могут функционировать в различных ОС.
Р ис.
9. Клиент – серверная архитектура
ис.
9. Клиент – серверная архитектура
 Рис.
10. Трехуровневая архитектура
Рис.
10. Трехуровневая архитектура
Модели данных
В основе любой СУБД лежит определенная модель данных. Как правило, используются сетевая, иерархическая, реляционная модель или комбинация этих моделей.
Эти модели различаются в основном способами представления взаимосвязей между объектами. Старейшие системы основаны на иерархической модели данных. К ним относится, например, разработанная для больших ЭВМ СУБД «Ока». Реляционными СУБД являются DB2, Oracle, Paradox, Access, FoxPro и др. Сетевой является СУБД СЕТОР.
Иерархическая модель данных строится по принципу иерархии типов объектов, т. е. один тип объекта является главным, а остальные, находящиеся на низших уровнях иерархии,— подчиненными. Эта структура строится из узлов и ветвей. Узел представляет собой совокупность атрибутов данных, описывающих некоторый объект. Наивысший узел в иерархической древовидной структуре называется корнем. Зависимые узлы располагаются на более низких уровнях дерева. Зависимые узлы могут добавляться как в вертикальном, так и в горизонтальном направлении без всяких ограничений. Связи (соединения) между узлами уникальны, поэтому иерархическая модель данных обеспечивает только линейные пути доступа к данным, а между главными и подчиненными типами объекта устанавливается линейная взаимосвязь “один ко многим». Каждый экземпляр корневого узла образует начало записи логической БД, т. е. иерархическая БД состоит из нескольких деревьев. К главным достоинствам иерархической модели данных можно отнести простоту понимания и использования. Недостатки модели – это громоздкие структуры при сложных БД и, как правило, хранение избыточных данных, например, описание одинаковых комплектующих (гайки, болты) в разных узлах (см. рис.11).

Рис. 11. Фрагмент иерархической БД
В сетевой модели данных (рис.12) понятия главного и подчиненных объектов несколько расширены. Любой объект может быть и главным, и подчиненным (в сетевой модели главный объект обозначается термином «владелец набора», а подчиненный — термином «член набора»). Один и тот же объект может одновременно выступать и в роли владельца, и в роли члена набора. Это означает, что каждый объект может участвовать в любом числе взаимосвязей. БД состоит из нескольких областей, каждая область содержит записи. В свою очередь запись состоит из полей, а набор, который объединяет записи, может размещаться в одной или нескольких областях. Достоинство сетевой модели – простота реализации часто встречающихся в реальном мире взаимосвязей, закладываемых в БД. Основной недостаток сетевой модели состоит в сложности управления данными, в том числе и возможная потеря независимости данных при реорганизации БД.

Рис. 12. Фрагмент сетевой БД для метаданных
В реляционной модели данных (рис. 13) объекты и взаимосвязи между ними представляются с помощью таблиц. Взаимосвязи также рассматриваются в качестве объектов (таблицы связей). Каждая таблица представляет один объект. В терминологии реляционной модели таблица называется отношением. Каждый столбец в таблице является атрибутом. Значения в столбце выделяются из домена, т. е. домен – суть множества значений, которые может принимать некоторый атрибут. Строки таблицы называются кортежами.
О базе данных, построенной таким образом, говорят, что она построена в первой нормальной форме, причем для каждого атрибута всех таблиц фиксирован тип и формат данных. Соединение данных из разных таблиц обеспечивается операторами языка SQL. К достоинствам реляционной модели следует отнести простоту общения пользователя с моделью.
Р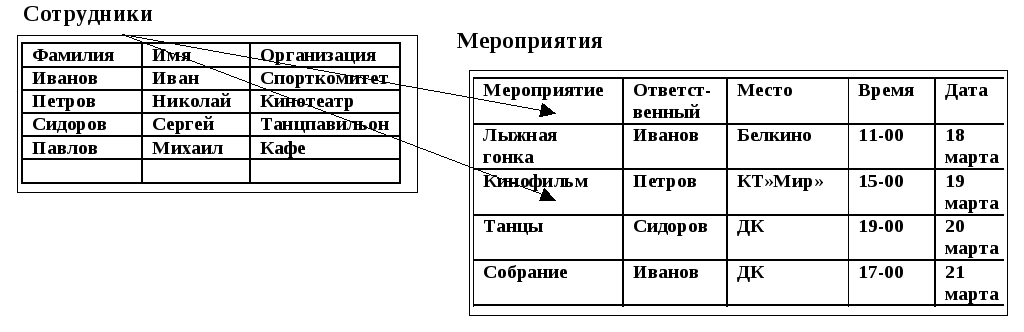 ис.
13. Отношения между таблицами
ис.
13. Отношения между таблицами
Недостаток модели – рядовые реляционные системы работают медленнее систем, базирующихся на сетевой или иерархической модели данных. Первичный ключ – это столбец, значения которого во всех строках отличаются. Он может объединять несколько столбцов. В некоторых СУБД первичный ключ может задаваться системой (ACCESS, Oracle). Связь реализуется при помощи внешнего ключа (это столбец таблицы, значения которого совпадают со значениями первичного ключа другой таблицы). Важным моментом является также использование значения NULL в таблицах реляционной БД. NULL – это отсутствующее значение, отсутствие информации в поле. Это поле обрабатывается особым образом.
Объектно – реляционные БД. Реляционные модели данных и созданные на их основе реляционные СУБД имеют ограниченный набор типов данных и хранят информацию в двумерных таблицах. Сложные структуры данных должны быть разбиты и распределены между этими таблицами. При этом логические связи между таблицами не хранятся. Новый подход к моделям данных – разрешение использования данных сложной структуры (например, графические, гипертекстовые, пространственные данные) в виде отдельных объектов, между которыми устанавливаются различного рода связи. В свою очередь эти логические связи определяются как объекты и вносятся в структуру модели. Такие модели называют объектно–ориентированными моделями данных. Эта модель используется в СУБД Oracle, Informix, PostgreSQL. Здесь применяются концепции объектно – ориентированного программирования (полиморфизм, инкапсуляция, наследование).
Постреляционная модель – это качественное и количественное расширение реляционной модели. Если в реляционных моделях используется первая нормальная форма, то в постреляционных моделях данные описываются не первой нормальной формой, не требуется определять для поля специфический тип и длину. Благодаря этому, можно задать таблицу, в которую вложены другие таблицы. Если всю информацию свести в одну большую таблицу, такая таблица неизбежно будет содержать пустые клетки или избыточные данные, при использовании нескольких таблиц потребуется выполнять весьма ресурсоемкую операцию соединения, снижая тем самым эффективность работы СУБД.
Моделью многомерной БД (рис.14) является многомерный куб, где на измерениях определены некоторые иерархии, а в клетках этого куба находятся числовые значения. Операции извлечения данных из такого куба описываются в терминах поворотов, срезов, и иерархического "схлопывания" измерений с агрегированием значений (суммирование, взятие среднего и др.). Эта схема хорошо ложится на табличную организацию данных. Наиболее известный программный продукт этого класса – это Oracle Express Server.