

Оптимизация структур данных
Правильно построенная модель БД позволяет избежать проблем со скоростью доступа к информации, а также обеспечивает возможность дальнейшего масштабирования БД и подключения дополнительных источников данных. Хорошо построенная модель данных может сделать систему быстрой, гибкой и функциональной. Критериями оптимальности модели БД являются скорость поиска, уменьшение числа связей таблиц, стандартизация структур данных. Модель БД должна содержать структуры таблиц, отражающие измерения во времени или жизненный цикл объекта хранения в БД, а также статические свойства объектов (атрибуты метаданных). Избегайте добавления новых полей в БД, иначе рано или поздно экран ввода информации будет представлять собой форму с множеством полей. А главное никто не будет заполнять все поля этой формы. Модели данных должны быть построены для физического уровня хранения данных, усвоения данных на уровне бизнес-логики и для презентационного уровня, рис.1.

Рисунок 1 - Схема уровней представления данных [12]
Физический уровень отвечает за сбор информации из используемых источников данных, их очистку, агрегацию и загрузку в БД. На проектирование физической модели БД влияют следующие параметры СУБД:
размер табличных пространств для хранения таблиц, индексов, полей BLOB;
кластеры и их параметры;
размер словаря данных, включая все хранимые процедуры, функции, триггеры, пакеты, команды SQL;
управляющие файлы;
файлы журнала работы процессов;
интенсивность потока запросов, модифицирующих данные и индексы;
файлы временных табличных пространств (для хранения временных таблиц, которые строятся, например, при выполнении group by, а также других временных объектов);
интенсивность потока запросов, инициирующих создание временных таблиц;
потоки транзакций read-write, read-only, объем модифицируемых и считываемых ими данных, характеристики параллельной работы транзакций (какие и сколько их);
количество приложений, работающих параллельно с БД;
количество соединений с БД для каждого приложения;
файлы параметров старта ядра СУБД;
загрузочные модули ядра и утилиты СУБД;
входные и выходные данные, генерируемые пользовательскими программами;
скрипты управления СУБД.
Уровень бизнес-логики преобразует данные из структур физического уровня в структуры, предназначенные для решения конкретных задач. Здесь происходит вычисление показателей и индикаторов, строятся иерархии, и для каждой предметной области связываются в схемы, используемые в ней таблицы фактов и метаданных. Правильно построенная модель бизнес-логики обеспечивает конечных пользователей полноценным для решения поставленных задач набором показателей, а также позволяет добавлять новые предметные области и описывать дополнительные объекты [2,3].
Модель бизнес-логики является самым сложным объектом БД. Модель бизнес-логики должна быстро адаптироваться под требования бизнеса, повышать в конечном итоге его успешность. Модель должна позволять оперативно создавать и изменять сотни показателей, измерений. Аналитик должен достаточно быстро выбрать список необходимых показателей и затем очень долго подбирать набор условий, которыми он хочет ограничить выборку и в разрезе которых рассчитать эти показатели. Причем сначала он использует одно условие, затем, увидев результат, накладывает дополнительное условие и т.д. Таким образом, оптимальность модели во многом зависит от того, насколько быстро аналитик сможет определить набор условий в виде списка показателей, которыми он хочет ограничиться. Для каждой задачи рекомендуется создать отдельное view-представление показателей и индикаторов, действительно необходимых для ее решения [6]. На уровне модели бизнес-логики можно проводить расчет показателей, алгоритм вычисления которых может изменяться. Такой подход позволяет избежать проблем с показателями, которые в разных случаях должны рассчитываться по-разному, а также повысить скорость и удобство работы конечного пользователя, предоставляя ему действительно необходимый для поддержки решения набор атрибутов.
Презентационный уровень содержит показатели, переведенные в понятия конкретной предметной области. На этом уровне подготовленные и рассчитанные на уровне бизнес-логики показатели проецируются в соответствующие отчеты для конечных пользователей.
Рекомендации. Создавайте стабильные и легко поддерживаемые структуры. Сведение нескольких таблиц к view-представлению означает, что большинство изменений затронет только одну таблицу. Рекомендации по использованию структур данных [1]:
храните множество используемых классификаторов в одной таблице за счет добавления нового атрибута «Идентификатор классификатора»;
используйте счетчики повторяющихся групп в иерархических структурах данных;
применяйте многомерные структуры при необходимости создания множества таблиц для родственных объектов и словари атрибутов для обозначения свойств атрибутов;
создавайте каталоги данных для организации хранения и поиска объектных файлов (документов, графических файлов, др.);
типизируйте структуры данных для временных рядов, сеточных данных, каталогов;
разрабатывайте обобщенные атрибуты данных, например, вместо создания для каждого произведенного товара своего имени атрибута (количество компьютеров, ТВ, холодильников, др.), используйте следующие атрибуты: Товар: тип, Товар: объем, Товар: единица измерений;
не детализируйте сущности, а создавайте общую концепцию и выделяйте основные сущности;
описываемые сущности храните в XML-схемах, что позволяет добавлять объекты и атрибуты без вероятности потери ранее записанных данных и без необходимости глубоко изучать предметную область;
для всех сущностей выделяйте общие поля (идентификатор, дата/время создания, дата/время редактирования, автор, в том числе поля для организации связи между сущностями и т.д.);
пользовательский интерфейс создавайте в виде синхронизированных атрибутов на основе их значений в БД.
Мониторинг работы БД
Мониторинг - это плановое наблюдение в режиме реального времени за сервером на предопределенных условиях, например, сколько времени занимает удачное выполнение важного приложения, сколько времени занимает резервное копирование или когда определенные значения производительности будут достигнуты. Мониторинг позволяет определить, какое событие вывело ошибку на монитор, установить, кто получает извещения о событиях и автоматически послать извещение, когда появляется событие с ошибкой.
Использование вычислительных ресурсов отражается занятостью ресурсов центрального процессора, оперативной, внешней и виртуальной памяти, каналов ввода-вывода, терминалов и каналов связи в виде абсолютной занятости ресурсов различных видов либо относительной величины использования ресурсов каждого вида.
Информация о поведении системы должна накапливаться в результате постоянного мониторинга работы БД [3]. Эта информация позволяет выполнять статистический анализ с целью локализации возникающих отклонений. Должен проводиться мониторинг контроля соответствия эксплуатационных параметров допустимым интервалам, лежащим между заданными пороговыми значениями. При этом положение центральной точки интервала допустимых значений может задаваться «базовой» функцией или быть константой. При выходе контролируемых параметров за пределы допустимых значений система мониторинга должна извещать персонал о возникших отклонениях. Администратор определяет для каждого хоста, какое событие заслуживает внимания (к примеру, слишком высокая нагрузка) и какая реакция должна последовать. Кроме того, в случае возникновения проблемы процесс может отправлять сообщение ответственному сотруднику по электронной почте с помощью службы немедленного обмена сообщениями или в виде SMS. Возможна также установка обработчика событий — программы, которая запускается при появлении ошибок. Если, к примеру, устанавливается, что Web-сервер больше не доступен, то система мониторинга должна самостоятельно перезапустить его.
После начальной инсталляции БД обязательно нужно произвести сбор статистики о ее работе, чтобы выяснить среднее и максимальное время загрузки сервера запросами, наиболее часто используемые данные, др. Можно установить автоматизированные предупреждения для следующих источников сообщений: протокол работы сервера БД, файл логов веб-сервера, журнал работы приложений. Главными задачами системы мониторинга БД является [4]:
обнаружение неполадок и отказов;
гибкие возможности оповещения;
автоматическое исправление неполадок;
настройка на новые (нестандартные) показатели.
Основу комплекса мониторинга составляют агенты, которые отслеживают собственно значения показателей (доступность компьютера по сети, работоспособность web-сервера, файл-сервера (nfs), уровня заряда, напряжение питания и температура UPS, работоспособность системы очередей, загрузка процессоров. Можно также отслеживать температуру процессора, скорость вращения кулера, др. Можно также написать специфичные модули для отслеживания нестандартных параметров.
В случае если значение какого-либо из атрибутов вышло за допустимые пределы, то включается механизм реагирования. Это может быть как оповещение по e-mail или через SMS, так и запуск какой-либо программы для оперативного реагирования (например, перезапуск web-сервера). Все результаты работы системы мониторинга записываются в log-файл (журнал регистрации всех значений метрик).
Так как возможны ситуации, когда допустим кратковременный выход показателя из допустимого диапазона, (например, отключение питания на 3-4 с при работающем UPS), то должна быть возможность ожидания определенного количества сбоев подряд и только после этого включается механизм реагирования. После того, как реагирование активировано, параметр отмечается как сбойный и в дальнейшем реагирование этот сбой не происходит.
Метрики, которые рекомендуется использовать для определения базовых параметров. Нельзя управлять тем, что невозможно измерить, поэтому метрики должны стать частью инструментария для управления любой ИТ-системой. Без точных метрик не смягчить последствия неблагоприятных событий. Аудит производительности сервера включает оценку производительности аппаратных средств сервера; ОС; конфигурации сервера; конфигурационных настроек БД; системы индексов; приложения и транзакций; работ с БД; запросов. Метриками для определения базовых параметров являются [4]:
число страниц чтения или записи на диск в секунду;
число байтов, проходящих по сетевому интерфейсу в секунду;
число дисковых операций чтения/записи для каждого физического диска на сервере;
время, которое процессор тратит на выполнение рабочего потока;
число индексных сканирований в секунду;
насколько вырос файл транзакций;
отношение свободного места в журнальном файле (не должен быть больше 97%);
число транзакций, подтвержденных в БД (наблюдайте за тем, когда транзакции начинают выстраиваться в очередь, это указывает на то, что дисковый ввод/вывод может быть медленным);
среднее время задержки запроса перед заполнением;
число пользовательских подключений к серверу БД;
текущее число процессов, ожидающих предоставления пространства памяти;
доступное пространство памяти (байт);
время работы диска в %;
средняя длина очереди диска;
процессорное время, % загрузки;
длина очереди процессора;
коэффициент удачного обращения в кэш буфера.
Рассмотрим более детально эти метрики.
Память (страниц/секунду). Этот счетчик измеряет число страниц в секунду, которые сбрасываются из оперативной памяти на диск, или считываются в оперативную память с диска. Если сервер показывает в среднем меньше чем 20 страниц в секунду, одной из наиболее вероятных причин этого является нехватка необходимой оперативной памяти.
Доступное пространство памяти. Когда объем доступной памяти близок к 5 Мбайт или ниже, это означает, что сервер испытывает перегрузку из-за нехватки памяти. Если это имеет место, то необходимо увеличить количество физической оперативной памяти в сервере, уменьшить нагрузку на сервер или изменить параметры настройки конфигурации памяти сервер БД соответственно.
Время работы диска в %. Этот счетчик показывает, насколько занят физический дисковый массив (не логический раздел или отдельный диск в массиве). Он обеспечивает хорошую относительную меру того, насколько заняты дисковые массивы. Как эмпирическое правило, счетчик времени диска должен показывать менее 55 %. Если показания счетчика превышают 55 % в течение непрерывных периодов (свыше 10 минут в течение 24 часов мониторинга), то сервер БД может испытывать проблемы с операциями ввода/вывода. Если наблюдается это поведение лишь изредка в течение 24 часов мониторинга, то это нормально, но если это случается часто (скажем, несколько раз час), то надо искать способы увеличить производительность операций ввода/вывода на сервере или уменьшить загрузку сервера. Некоторые способы увеличивать дисковый ввод/вывод состоят в добавлении новых дисков в массив (если это возможно), замены дисков на более быстрые, добавлении кэш-памяти на плате контроллера (если это возможно), использования различных версий RAID или установки более быстрого контроллера.
Желательно отслеживать значения счетчика средней длины очереди диска. Если это значение превышает значение два для непрерывных периодов (свыше 10 минут в течение 24 часового мониторинга) для каждого дисковода в массиве, то этот массив может оказаться узким местом производительности системы. Если это происходит изредка в течение 24 часов периода мониторинга, то можно не волноваться, но если это происходит часто, тогда надо искать способы увеличить производительность системы ввода/вывода сервера.
Загрузка процессора в %. Если общее время загрузки процессоров превышает 80 % в течение непрерывных периодов (свыше 10 минут в течение 24 часового периода мониторинга), то можно считать центральный процессор узким местом системы. Если они возникают часто, следует рассмотреть такие варианты снижения загрузки сервера, как приобретение более быстрых центральных процессоров, установку большего количества центральных процессоров, или приобретение центральных процессоров, которые имеют больший встроенный кэш.
Загруженность процессора становится под вопрос только под пиковой нагрузкой. Учитывая, что при работе БД в Интернет планировать число возможных запросов очень трудно, требуется иметь сервер со средней загрузкой не более 40% процентов. В высокопроизводительных системах загрузка процессора никогда не должна превышать 70-80%.
Установка в пять раз более мощного процессора приводит всего лишь к 20%-ному увеличению времени отклика системы на запросы пользователей. При обработке пакетных заданий основная нагрузка ложится на процессор, для интерактивных пользователей основной проблемой является диск. Установка более мощного процессора увеличивает производительность системы только в том случае, если он является ее узким местом. При правильной оптимизации системы появляется возможность поднять ее реальную производительность в десятки, сотни или даже тысячи раз [7]. Полную нагрузку системы (Пн) можно вычислить по формуле:
Пн= Nз * Lзср + Nп * Lпср,
где, Nз - число заданий,
Lзср средняя нагрузка от одного задания,
Nп - количество пользователей,
Lпср - средняя нагрузка от одного пользователяю
Снизить нагрузку можно тремя способами:
запретить пользователям выполнять некоторые действия;
рекомендовать пользователям перенести часть их работы на более спокойное время;
повысить эффективность используемых пользователями приложений.
Длина очереди процессора. Если этот показатель превышает значение 2 на один центральный процессор в течение непрерывных периодов (свыше 10 минут в течение 24 часового периода мониторинга), то вероятно это является узким звеном системы. Например, если на сервере имеется четыре центральных процессора, длина очереди процессора не должна превышать в общей сложности значение восемь. Если оба индикатора превышают рекомендованные значения в течение одних и тех же непрерывных периодов времени, можно быть уверенным, что центральный процессор является слабым местом системы.
Коэффициент удачного обращения в кэш буфера. Этот счетчик показывает, как часто СУБД обращается к буферу, а не к жесткому диску, чтобы получить данные. В приложениях OLTP этот коэффициент должен превышать 90 %, а в идеале быть выше 99 %. Если коэффициент удачного обращения в буферный кэш ниже 90 %, то следует иметь больше оперативной памяти. Если этот коэффициент лежит в диапазоне между 90 % и 99 %, то надо серьезно рассмотреть вариант покупки дополнительной оперативной памяти, так как чем ближе приближаетесь к 99 %, тем быстрее сервер БД будет работать.
Пользовательские подключения. Поскольку число пользователей влияет на его производительность, рекомендуется следить за счетчиком пользовательских подключений. Он показывает число пользовательских подключений, а не число пользователей, которые подключены к серверу БД в данный момент времени. Если показания этого счетчика превышают 255, то следует увеличить значение конфигурационного параметра «максимальное число рабочих нитей», значение по умолчанию которого равно 255.
Высокий уровень обращения на чтение и запись к файлу подкачки даже при легкой или средней транзакционной нагрузке. Эта проблема решается в источнике данных. С помощью лучших методик по нормализации данных разделите данные на наборы связанных таблиц, исходя из смысла и функциональности. Связи между таблицами необходимо реализовать с использованием декларативной ссылочной целостности, и создать соответствующие индексы. При необходимости создайте представления, которые имитируют старый формат записи. Это нужно для поддержки существующих приложений, которые запрашивают данные из БД. Одновременно следует переписать эти приложения.
При эксплуатации БД, в первую очередь, необходимы: безотказность (свойство системы на протяжении определенного времени работать без отказов) и высокая ремонтопригодность (готовность к работе после возникновения неисправности, которая определяет степень сложности исправления дефекта неисправности/ошибки в системе). На сегодняшний день не существует систем, гарантирующих 100% отказоустойчивость.
Для повышения надежности системы используется аппаратная (резервирование), программная и информационная избыточность. Отличительными преимуществами отказоустойчивых систем являются: их высокая безотказность, бесперебойность работы системы при наличии отказов и более продолжительный жизненный цикл эксплуатации. Отказоустойчивые системы помимо преимуществ имеют и ряд специфических характеристик, а именно: сложность дизайна и высокая стоимость развертывания, повышенное энергопотребление, сложность системы. Примеры систем с различными значениями вероятностей безотказной работы даны в табл.2.
Таблица 2 - Примеры систем с различными значениями вероятностей безотказной работы
|
Вероятность безотказной работы, % |
Время простоя/год |
Пример |
|
99 |
5000 минут |
Web-страница общего характера |
|
99,9 |
500 минут |
Корпоративный портал |
|
99,99 |
50 минут |
Почтовый сервер |
|
99,999 |
5 минут |
БД |
|
99,9999 |
30 секунд |
ОС |
Источник: G. Candea, «Principles of Dependable Computer Systems». Stanford University, 2003
Если сеансы связи не завершаются корректно, соединения продолжают существовать. В течение всего этого времени оперативная память и вычислительные мощности работают вхолостую. Необходимо придерживаться правила: создавать соединение как можно позже и закрывать его как можно раньше.
Иногда даже при правильно нормализованной БД все равно встречаются проблемы с производительностью. Один из основных способов увеличить производительность - это документировать, а затем автоматизировать процессы. Можно провести анализ процессов и определить те ручные процессы, которые нужно автоматизировать.
При миграции данные переписываются с одного физического местоположения на другое, чтобы освободить клиентам место для размещения новых данных. Автоматическая миграция запускается, когда превышается определенное правилом граничное значение. После этого для новых или измененных файлов создаются дополнительные метаданные (атрибуты или содержимое файла), а они сами копируются на диск или ленту. В случае метаданных речь идет о файлах (фрагментах файлов), которые не содержат данных, причем их физический размер соответствует кластеру файловой системы (от 4 до 64 Кбайт). Они обладают теми же свойствами, что и исходный файл, используются в качестве держателя места и указывают на новое физическое размещение мигрировавшего файла. Всем процессом можно управлять вручную через командную строку. Миграция в соответствии с заданными правилами позволяет перемещать данные с файловых серверов на вспомогательные устройства. Таким образом, освобождается ценное дисковое пространство на файловых серверах. Тем не менее, данные все же остаются оперативно доступными, временное окно для резервного копирования сокращается, а административные издержки снижаются.
Показатели могут быть базовыми и эталонными. Базовые значения показателей - это набор, отображающий поведение сервера и приложения в обычных условиях. Базовые параметры получается как средние по результатам нескольких замеров, выполненных в одинаковых условиях; они являются ориентирами для сравнения. Используйте среднее значение различных базовых параметров для установки обычной стандартной (по базовым параметрам) производительности. Эталонные показатели оценивают производительность системы при определенном уровне загрузки сервера, что позволяет сравнить производительность промышленного сервера при таком уровне и определить показатели сервера, насколько они выше или ниже нормы (т.е. когда сервер работает плохо).
Для контроля производительности сервера установите частоту опроса, значения для каждого показателя между значениями базовых параметров и эталонными значениями, которые показало тестирование. Например, можно установить уведомление, когда счетчик достигает 75 % значения самой высокой нагрузки, и предостерегающее сообщение, когда он проходит 90 %. Рекомендуется установить предупреждения для следующих ситуаций: ошибки, влияющие на эксплуатацию; блокировки; использование процессора; использование диска; сканирования. Пример системы мониторинга на базе Tivoli показан на рис.2.
Оптимизация технологических этапов обработки. Если в технологии заложены временные критерии обработки, то их не обойдешь оптимизацией на нижнем уровне. Можно рассматривать для оптимизации следующие временные показатели:
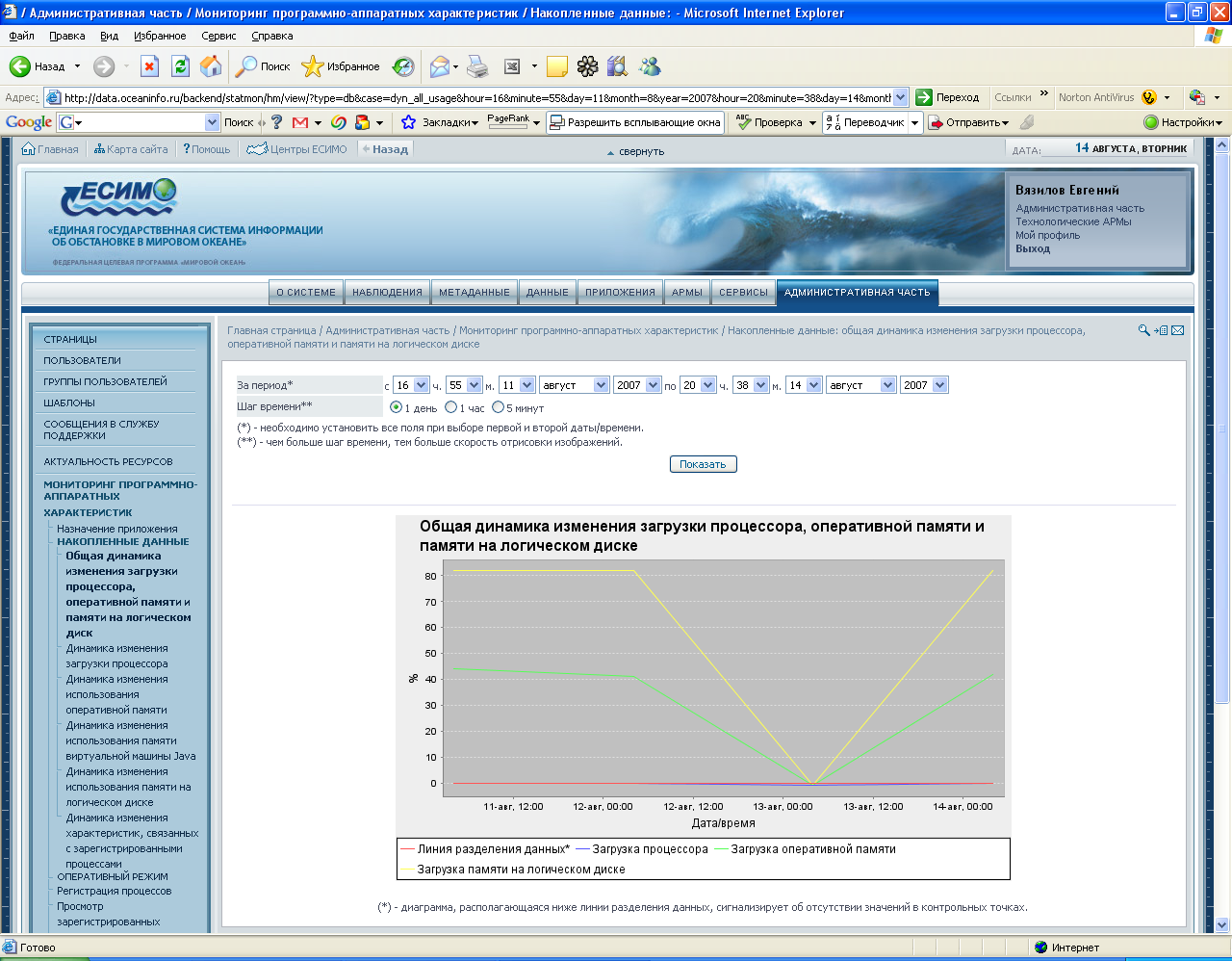
Рисунок 2 – Пример работы системы мониторинга технических характеристик портала
время получения и загрузки данных в БД (с одной стороны есть регламент доставки 20 или 30 мин после измерений, с другой, необходимо иметь статистику загрузки, т.е. знать реально через какое время данные становятся доступными);
время подготовки для визуализации на карте (создание БД, построение шейп-файлов и т.п.);
время выполнения запроса.
Для разработки модели оптимизации технологии доступа к данным надо провести анализ временных составляющих (от чего они зависят), выделить граничные условия и попытаться найти решения по уменьшению времени предобработки.
Инструменты для оптимизации работы с БД
Существует достаточно большое число инструментов для оптимизации работы БД. Инструментами, которые можно использовать для анализа производительности сети, являются:
http://cv.intellos.net – отображение активных соединений;
http://www.ethereal.com – анализатор пакетов;
http://aptraf.seul.com – загруженность сети;
http://www.mrtg.org – мониторинг сетевых узлов;
http://nagios.org, http://www.aneptun.de/linux/Nnetstat - графическое отображение активных соединений;
http://www.itee.ug.edu.au/~leonard/personal/soft-ware/#pktstat – отображение нагрузки на сеть с именами файлов.
Наиболее интересным средством являются Embarcadero DB Optimizer [http://www.interface.ru/home.asp?artId=19053] - интегрированная среда разработки с возможностями профилирования и настройки производительности кода на SQL [13]. Этот продукт позволяет разработчикам и администраторам БД быстро обнаруживать, диагностировать и оптимизировать части кода на SQL с плохой производительностью, табл.3. DB Optimizer позволяет избежать снижения производительности с помощью следующих функций: обнаружение запросов с интенсивной обработкой данных и часто выполняемых запросов, выявление определенных выражений SQL с помощью статистики запросов (например, использование процессора, операции ввода-вывода, время ожидания) и оптимизацию любых проблематичных выражений. DB Optimizer помогает администраторам БД быстро профилировать СУБД Oracle, Microsoft SQL, Sybase и DB2, чтобы легко определить и исправить ошибки в коде SQL, вызывающие падение производительности.
Таблица 3– Функции DB Optimizer
|
Возможность |
Описание |
|
Профилирование | |
|
Профилирование хранимой процедуры |
Профилирование выполнения отдельной хранимой процедуры. |
|
Использование сеансов профилирования |
Все данные и метаданные, относящиеся к сеансу профилирования, можно сохранить в архивном файле в виде единой сущности |
|
Отчеты | |
|
Диаграмма профиля |
Показывает загрузку процессора, интенсивность ввода-вывода и другую деятельность в ходе сеанса, связанную со временем ожидания |
|
Результаты статистики выполнения |
Подробная информация о коде SQL, подвергнутом профилированию, и категориях ожидания |
|
Выбор региона |
Выделение интервала времени на диаграмме профиля для моментального изменения отображаемых данных |
|
Статистика на уровне выражений SQL |
На уровне выражений языка SQL (SELECT, DELETE, UPDATE) доступны следующие характеристики: загрузка процессора, статистика времени ожидания и количество вызовов |
|
Объяснить план |
Командой Explain Plan для каждого выражения SQL можно вычислить статистику выполнения с помощью контекстного меню |
|
Настройка (только для Oracle) | |
|
Быстрые исправления |
Немедленное оповещение о проблеме в коде прямо в процессе его написания |
|
Пакетная настройка |
Настройка всех выражений манипуляции данными, хранимых процедур, всех SQL-файлов и глобальной системной области |
|
Задание настройки |
Создание и запуск заданий настройки, как для отдельного выражения, так и для пакетной настройки всех выражений SQL |
|
Генерация вариантов |
Используются преобразования и вставка указаний оптимизатору для генерации всех возможных вариантов и нахождения наилучшей альтернативы заданному выражению SQL |
|
Вставка указаний |
Настройка подмножества указаний оптимизатору, которые будут рассматриваться как вариант для вставки |
|
Генерация затрат |
Вычисление ожидаемых затрат на реализацию плана выполнения для каждого оригинального выражения и каждого сгенерированного варианта |
|
Рекомендации для индексов |
Таблица сгенерированных вариантов показывает рекомендации для индексов, которые могут улучшить производительность |
|
Текстовое сравнение вариантов |
Визуальное средство просмотра отличий помогает пользователю увидеть текстовые отличия между любыми двумя выражениями SQL |
DB Optimizer автоматически генерирует код на языке определения данных для создания и сохранения структуры и оптимального плана выполнения по результатам настройки. После того как структура сохранена в БД, выражения языка SQL из приложения будут следовать оптимизированному плану выполнения, избегая других, менее эффективных, путей исполнения. Графические результаты профилирования и ссылки на более подробные данные облегчают поиск тех выражений SQL, которые больше всего влияют на производительность. DB Optimizer позволяет профилировать и настраивать код SQL на протяжении всего процесса разработки. Это помогает исключить ситуацию, когда на стадии тестирования или сдачи в эксплуатацию обнаруживается, что БД не соответствует соглашению об уровне обслуживания. Можно также запустить профилирование всего экземпляра БД на протяжении определенного пользователем промежутка времени, а также собрать статистику времени ожидания по любым выражениям SQL, запущенным в БД.
При использовании DB Optimizer для создания кода SQL в СУБД Oracle функция PowerSQL Quick Fix немедленно обнаруживает потенциальные проблемы с производительностью. DB Optimizer разрабатывает качественный код быстрее, имена объектов дополняются автоматически, когда их начинают печатать на клавиатуре. Это обеспечивает проверку синтаксических и семантических ошибок, что, в свою очередь, облегчает поиск объектов в БД и эффективное управление SQL-проектами.
Выводы
Администраторам БД приходится бороться со сложностью исторически сформировавшихся структур данных, где представлены разные производители, платформы, приложения и стандарты. Каждый инструмент и каждая дисциплина управления пользуются собственными схемами и БД. Большую помощь оказывает возможности работы со средствами СУБД в удаленном режиме. Постоянный мониторинг работы БД позволяет выявить узкие места.
Для снижения стоимости эксплуатации БД следует обращать особое внимание на выделение наиболее активных данных. Иногда небольшие изменения, проведенные в приложении или в схеме БД, обеспечивают увеличение производительности системы на порядок. Огромную помощь в повышении надежности работы БД окажет тестирование.
Унификация процессов управления данными в гетерогенной среде, выработка единых наборов правил, применение типового инструментария и тем самым снижение расходов на администрирование данных возможно только через рассмотрение жизненного цикла объектов, сведения о которых должны отражаться в БД.
Необходимо создавать каталоги для организации хранения и поиска объектных файлов (документов, графических файлов, др.), а также для любой информации, представленной в виде сведений о каких-либо объектах. Для всех объектов выделяются общие поля типа идентификатор, дата/время создания, дата/время редактирования, автор и др., в том числе поля для организации связи между объектами и т.д. При этом необходимо использовать обобщенные атрибуты данных. При работе с атрибутами необходимо использовать обобщенные форматы полей (число, строка, список, другие). Описания атрибутов должны храниться отдельно.
Идеальная БД хорошо работает, ее эффективность высока, а производительность оптимальна. Кроме того, она обеспечивает поддержку корпоративных инициатив, а организация обладает гибкостью и располагает в схеме БД основой для развития в нужном направлении.
Разработать систему, которая хорошо справляется с любой нагрузкой, непросто (или даже невозможно), однако важно знать, с какими задачами система справляется хорошо, а с какими неудовлетворительно. Во-первых, это необходимо, чтобы дать потенциальным пользователям системы информацию о том, как предположительно будут вести себя приложения. Во-вторых, многие узкие места деградации производительности можно обойти, если о них знаете, однако, если не измерена производительность системы под различными типами нагрузки, то вообще не сможете обнаружить эти узкие места.
Список литературы