

Шаг 3. Функционирование распознавателя для цепочки (((aa)a)a) показано в таблице 3.9.
Таблица 3.9 – Алгоритм работы распознавателя цепочки (((aa)a)a)
|
Шаг |
Стек |
Входной буфер |
Действие | |
|
1 |
н |
(((aa)a)a)к |
сдвиг | |
|
2 |
н( |
((aa)a)a)к |
cдвиг | |
|
3 |
н(( |
(aa)a)a)к |
cдвиг | |
|
4 |
н((( |
aa)a)a)к |
cдвиг | |
|
5 |
н(((a |
a)a)a)к |
свертка Sa | |
|
6 |
н(((S |
a)a)a)к |
сдвиг | |
|
7 |
н(((Sa |
)a)a)к |
сдвиг | |
|
8 |
н(((Sa) |
a)a)к |
свертка RSa) | |
|
9 |
н(((R |
a)a)к |
свертка S(R | |
|
10 |
н((S |
a)a)к |
сдвиг | |
|
11 |
н((Sa |
)a)к |
сдвиг | |
|
12 |
н((Sa) |
a)к |
свертка RSa) | |
|
13 |
н((R |
a)к |
свертка S(R | |
|
14 |
н(S |
a)к |
сдвиг | |
|
15 |
н(Sa |
)к |
сдвиг | |
|
16 |
н(Sa) |
к |
свертка RSa) | |
|
17 |
н(R |
к |
свертка S(R | |
|
18 |
нS |
к |
строка принята | |
Шаг 4. Получили следующую цепочку вывода:
S(R(Sa)((Ra)((Sa)a)(((Ra)a)(((Sa)a)a)(((aa)a)a).
Восходящее дерево вывода цепочки представлено на рисунке 3.5.2
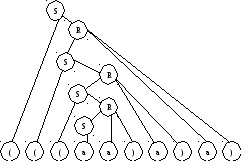
Рисунок 3.5 – Дерево вывода для цепочки (((aa)a)a)в грамматике G
3.5.1.2 Грамматика операторного предшествования
3.5.1.2.1 Определение грамматики операторного предшествования
Определение КС-грамматика G (VN, VT, P, S) называется грамматикой операторного предшествования, если выполняются следующие условия:
1) Для каждой упорядоченной пары терминальных символов выполняется не более чем одно из трех отношений предшествования:
а) а = b, если и только если существует правило A—>xaby Р или правило А->хаСbу, где a,bVT, A,C VN, x.yV*;
б) а < b, если и только если существует правило А->хаСу Р и вывод C=>*bz или вывод C=>*Dbz, где a,bVT, A,C,DVN, x,y,zV*;
в) а > b, если и только если существует правило А—>хСЬу Р и вывод C=>*za или вывод C=>*zaD, где a,bVT, A,C,DVN, x,y,zV*.
2) Различные правила в грамматике имеют разные правые части, -правила отсутствуют.
Правила грамматики операторного предшествования не могут содержать двух смежных нетерминальных символов в правой части, т.е. в грамматике операторного предшествования G(VN,VT,P,S) не может быть ни одного правила вида: А->хВСу, где A,B,CVN, x,yV* (здесь х и у — это произвольные цепочки символов, могут быть и пустыми).
3.5.1.2.2 Построение множеств Lt(a) и Rt(a)
Принцип работы распознавателя для грамматики операторного предшествования аналогичен грамматике простого предшествования, но отношения предшествования проверяются в процессе разбора только между терминальными символами.
Для грамматики данного вида на основе установленных отношений предшествования также строится матрица предшествования, но она содержит только терминальные символы грамматики.
Для построения этой матрицы удобно ввести множества крайних левых и крайних правых терминальных символов относительно нетерминального символа А – Lt(A) или Rt(A):
Lt(A)
=
{t |
![]() A=>*tz
или
A=>*tz
или
![]() A=>*Ctz },
где
tVT,
A.CVN,
zV*;
A=>*Ctz },
где
tVT,
A.CVN,
zV*;
Rt(A)=
{t
|
![]() A=>*zt
или
A=>*zt
или
![]() A=>*ztC },
где
tVT,
A,CVN,
zV*.
A=>*ztC },
где
tVT,
A,CVN,
zV*.
Тогда определения отношений операторного предшествования будут выглядеть так:
а)
а =
b,
если
![]() правило A→xaby
Р
или правило U->xaCby,
где a,bVT,
А,СVN
х,уV*;
правило A→xaby
Р
или правило U->xaCby,
где a,bVT,
А,СVN
х,уV*;
б)
а <
b,
если
![]() правилоА→хаСу
Р
и b
Lt
(C),
где a,bVT,
A,CVN,
x,yV*;
правилоА→хаСу
Р
и b
Lt
(C),
где a,bVT,
A,CVN,
x,yV*;
в)
а >
b,
если
![]() правило A→xCby
Р
и a
Rt(C),
где a,bVT,
A,CVN,
x,yV*.
правило A→xCby
Р
и a
Rt(C),
где a,bVT,
A,CVN,
x,yV*.
В данных определениях цепочки символов x,y,z могут быть и пустыми цепочками.
Для нахождения множеств Lt(A) и Rt(A)предварительно необходимо выполнить построение множеств L(A) и R(A), как это было рассмотрено ранее. Далее для построения Lt(A) и Rt(A) используется следующий алгоритм:
Шаг
1.
![]() AVN:
AVN:
Rt0(A){t
|
![]() A→ytB
или
A→yt,
tVT,
BVN,
yV*;
A→ytB
или
A→yt,
tVT,
BVN,
yV*;
Lt0(A){t
|
![]() A→Bty
или
A→ty,
tVT,
BVN,
yV*;
A→Bty
или
A→ty,
tVT,
BVN,
yV*;
Для каждого нетерминального символа А ищем все правила, содержащие А в левой части. Во множество L(A) включаем самый левый терминальный символ из правой части правил, игнорируя нетерминальные символы, а во множество R(А) - самый крайний правый терминальный символ из правой части правил. Переходим к шагу 2.
Шаг
2.
![]() AVN:
AVN:
Rti(A)
= Rti-1(A)
![]() Rti-1
(B),
Rti-1
(B),
![]() В
(R(A)
В
(R(A)
![]() VN),
VN),
Lti(А)
= Lti-1(A)
![]() Lti-1(B),
Lti-1(B),
![]() В
(L(A)
В
(L(A)
![]() VN).
VN).
Для каждого нетерминального символа А: если множество L(A) содержит нетерминальные символы грамматики А', А", ..., то его надо дополнить символами входящими в соответствующие множества L t(А’), L t(A"), ... и не входящими в L t(А). Ту же операцию надо выполнить для множеств R(A) и Rt(А).
Шаг
З. Если
![]() AVN
:
Rti(A)
AVN
:
Rti(A)
![]() Rti-1(A
или
Lti(А)
Rti-1(A
или
Lti(А)
![]() Lti-1(A),
то i:=i+1
и вернутся
к шагу
2, иначе построение закончено:
Rt(A)
= Rti(A)
и Lt(A)
= Lti(А).
Lti-1(A),
то i:=i+1
и вернутся
к шагу
2, иначе построение закончено:
Rt(A)
= Rti(A)
и Lt(A)
= Lti(А).
Если на предыдущем шаге хотя бы одно множество Rt(A) или Lt(A) для некоторого символа грамматики изменилось, то надо вернуться к шагу 2, иначе построение закончено.
Для практического
использования матрицу предшествования
дополняют символами
![]() и
и![]() ( начало и конец цепочки). Для них
определены следующие отношения
предшествования:
( начало и конец цепочки). Для них
определены следующие отношения
предшествования:
![]() <·
a,
<·
a,
![]() aVT,
если
aVT,
если
![]() S=>*ax
или
S=>*ax
или
![]() S=>*Cax,
где
S,CVN,
xV*
или
если
a
Lt(S);
S=>*Cax,
где
S,CVN,
xV*
или
если
a
Lt(S);
![]() ·> а,
·> а,
![]() aVT,
если
aVT,
если
![]() S=>*xa
или
S=>*xa
или
![]() S=>*xaC,
где S,CVN,
xV*
или если a
Rt(S).
S=>*xaC,
где S,CVN,
xV*
или если a
Rt(S).
Здесь S — целевой символ грамматики.
Матрица предшествования служит основой для работы распознавателя языка, заданного грамматикой операторного предшествования. Поскольку она содержит только терминальные символы, то, следовательно, будет иметь меньший размер, чем аналогичная матрица для грамматики простого предшествования. Следует отметить, что напрямую сравнивать матрицы двух грамматик нельзя — не всякая грамматика простого предшествования является грамматикой операторного предшествования, и наоборот.